Improving MCMC convergence

Manushi Welandawe

Chris Paciorek
In general, a few of the tools that NIMBLE provides to help with this are:
1) trying different samplers for one or more nodes (e.g., switching
from random walk Metropolis ("RW") samplers to slice samplers or using
the RW sampler on the log scale). See Sec 7.2 of the NIMBLE manual.
2) if the node (i.e. ,parameter) is highly correlated with one or more
other nodes, blocking nodes together, e.g., with the RW_block sampler.
There's a bit of an example
in Section 2.6 of the manual or see the "Customizing an MCMC" and
"Building a generalized linear mixed model" examples at
https://r-nimble.org/examples.
3) writing your own customized sampler (if you have some idea of how
to make better proposals for the slow-mixing parameter). See Sec 15.5
of the manual.
4) In some cases, finding better starting values for the MCMC can help.
5) Sometimes reparameterizing the model helps, though that is not
explicitly something that is part of NIMBLE.
Other users might weigh in with strategies that they've used.
> You received this message because you are subscribed to the Google Groups "nimble-users" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to nimble-users...@googlegroups.com.
> To post to this group, send email to nimble...@googlegroups.com.
> To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/47b14d0b-9f8d-495f-8804-27c5ead79656%40googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.

Perry de Valpine
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/CAG%3DM9LoUHOxgWgzj_veAVTzN8UNME2Dk5qt0qJj9E9eDPEwMHw%40mail.gmail.com.

Quresh Latif

fbud...@gmail.com
Daniel Turek
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/1f82dde1-b749-475e-8336-419f9a2d1d03n%40googlegroups.com.
Quresh Latif
Quresh Latif
TuningHistory <- list()
for(i in 1:length(conf$getSamplers())) {
name <- conf$getSamplers()[[i]]$target
scl <- Cmcmc$samplerFunctions$contentsList[[i]]$getScaleHistory()
acpt <- Cmcmc$samplerFunctions$contentsList[[i]]$getAcceptanceHistory()
TuningHistory <- c(TuningHistory, cbind(Scale = scl, Acceptance = acpt))
names(TuningHistory)[i] <- name
}

Daniel Turek
grepl('^RW', sampler_names)
Daniel
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/42f2582e-f3d3-41fa-b99d-d0c55648b118n%40googlegroups.com.
Quresh Latif
Awesome, thanks! Did this:
TuningHistory <- list()
for(i in 1:length(ind.RW)) {
name <- conf$getSamplers()[[ind.RW[i]]]$target
if(length(name) > 1) name <- stringr::str_c(name, collapse = ", ")
scl <- Cmcmc$samplerFunctions$contentsList[[ind.RW[i]]]$getScaleHistory()
acpt <- Cmcmc$samplerFunctions$contentsList[[ind.RW[i]]]$getAcceptanceHistory()
TuningHistory[[i]] <- cbind(Scale = scl, Acceptance = acpt)
names(TuningHistory)[i] <- name
}
Quresh S. Latif
Research Scientist
Bird Conservancy of the Rockies
Phone: (970) 482-1707 ext. 15
www.birdconservancy.org
A few years later Kiona Ogle published this paper which talks about the same issue: https://link.edgepilot.com/s/efc1736c/PwohvTg3fkOSUdnUeb-sFw?u=https://esajournals.onlinelibrary.wiley.com/doi/full/10.1002/eap.2159.
Maybe just something to check for in your covariates, if it's relevant for your type of hierarchical model.
-Franny
On Thursday, January 19, 2023 at 6:38:21 PM UTC-5 quresh...@birdconservancy.org wrote:
Is it typical for the intercept and covariate parameters for a given demographic parameter to be correlated and therefore good candidates for trying a RW_block sampler to sample them together?
I have an exponential growth parameter, r, in a population model that I am relating with covariates using a log link function:
log(r[g, (t-1)]) <- delta0 + inprod(deltaVec[1:n.Xdelta], Xdelta.array[g, t, 1:n.Xdelta]), where g indexes site and t indexes year.
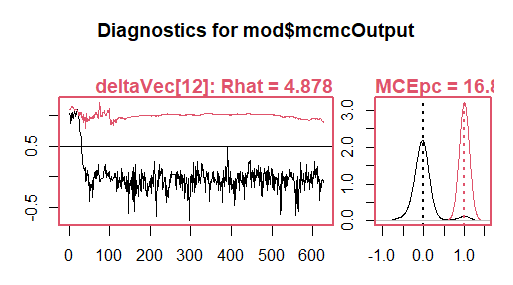
I've got a couple traceplot (after applying some burnin and thinning) shown in the attached images, one for the intercept (delta0) and the other for the 12th covariate (delta12). The traceplots for the other covariate parameters look similar where the black chain looks to be mixing reasonably well but the red one is struggling. Considering these, does it seem like the log-linear regression parameters for r are likely correlated and would benefit from an RW_block sampler?
Also, I am currently using adaptation. I'm wondering if there's a way to record the tuning values ('scale' in the configureMCMC function?) or if that is automatically recorded somewhere. If so, would it help to identify what scale has arrived at for the black chain and then fix it to that value from the beginning for both chains? Along with that, is it possible to set 'scale' to different values for different parameters, or somehow tune the samplers for different parameters differently?
I am still working through the section of the user manual on this, so apologies for taking up space here if this is all spelled out there.
On Friday, March 1, 2019 at 9:47:36 AM UTC-7 pdevalpine wrote:
I'll add some strategies to what Chris wrote.
Sometimes the list of samplers operating on a model represents misplaced computational costs. A categorical sampler for a node with many categories can be inefficient, and that node may not be a limitation on mixing, so it can work well to use a faster sampler. Sometimes multiple nodes share identical or nearly identical dependencies (other nodes that depend on them). This means that the same computational effort is involved in sampling them, and for this reason it can make sense to sample them jointly, such as with RW_block. Sometimes we can identify parts of a model that can be re-written using nimbleFunctions to provide new functions or distributions in the model. New functions can combine multiple steps into single steps, reducing the size of the model, which can improve efficiency. New distributions can be useful to analytically sum or integrate over latent states when it is simple to do so. The zero-inflated Poisson example on our web site is a simple case. More complicated cases of doing this for capture-recapture and hidden Markov models are given in Turek et al. (2016; Environ Ecol Stat (2016) 23: 549. https://link.edgepilot.com/s/53661c95/X7avF18thkyInmDB4XXrbA?u=https://doi.org/10.1007/s10651-016-0353-z). Sometimes changing the parameterization of a model (e.g. from non-centered to centered random effects) or centering explanatory variables can lead to improved mixing.
-Perry
On Thu, Feb 28, 2019 at 6:20 PM Chris Paciorek <christophe...@gmail.com> wrote:
Hi Manushi,
In general, a few of the tools that NIMBLE provides to help with this are:
1) trying different samplers for one or more nodes (e.g., switching
from random walk Metropolis ("RW") samplers to slice samplers or using
the RW sampler on the log scale). See Sec 7.2 of the NIMBLE manual.
2) if the node (i.e. ,parameter) is highly correlated with one or more
other nodes, blocking nodes together, e.g., with the RW_block sampler.
There's a bit of an example
in Section 2.6 of the manual or see the "Customizing an MCMC" and
"Building a generalized linear mixed model" examples at
3) writing your own customized sampler (if you have some idea of how
to make better proposals for the slow-mixing parameter). See Sec 15.5
of the manual.
4) In some cases, finding better starting values for the MCMC can help.
5) Sometimes reparameterizing the model helps, though that is not
explicitly something that is part of NIMBLE.
Other users might weigh in with strategies that they've used.
On Thu, Feb 28, 2019 at 6:55 AM Manushi Welandawe <man...@my.uri.edu> wrote:
>
> Hi All,
>
> I would like to know the techniques that I can use in nimble to improve the convergence of the MCMC samples.
>
> Thank you
>
> Best,
> Manushi
>
> --
> You received this message because you are subscribed to the Google Groups "nimble-users" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to nimble-users...@googlegroups.com.
> To post to this group, send email to nimble...@googlegroups.com.
> To view this discussion on the web visit https://link.edgepilot.com/s/6e16ae93/GlaxOBJc2kyrZ2rsZcCx6w?u=https://groups.google.com/d/msgid/nimble-users/47b14d0b-9f8d-495f-8804-27c5ead79656%2540googlegroups.com.
> For more options, visit https://link.edgepilot.com/s/56c95ab3/RfqM9kZKyk6Pmuy7AjfBgg?u=https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "nimble-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to nimble-users...@googlegroups.com.
To post to this group, send email to nimble...@googlegroups.com.
To view this discussion on the web visit https://link.edgepilot.com/s/af2455a8/3tYV9KR8mku640FzaR4JAA?u=https://groups.google.com/d/msgid/nimble-users/CAG%253DM9LoUHOxgWgzj_veAVTzN8UNME2Dk5qt0qJj9E9eDPEwMHw%2540mail.gmail.com.
For more options, visit https://link.edgepilot.com/s/56c95ab3/RfqM9kZKyk6Pmuy7AjfBgg?u=https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "nimble-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to nimble-users...@googlegroups.com.
To view this discussion on the web visit https://link.edgepilot.com/s/cff8491b/PIxdRSzsm0W_MxHymRDI3w?u=https://groups.google.com/d/msgid/nimble-users/1f82dde1-b749-475e-8336-419f9a2d1d03n%2540googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "nimble-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to nimble-users...@googlegroups.com.
To view this discussion on the web visit https://link.edgepilot.com/s/4c54d401/3B_gF13KvEy6v874tAS15w?u=https://groups.google.com/d/msgid/nimble-users/42f2582e-f3d3-41fa-b99d-d0c55648b118n%2540googlegroups.com.
Quresh Latif
Daniel Turek
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/fb09d55d-d364-4ae9-9419-9a3cf02df462n%40googlegroups.com.

{kind=link}
{kind=link}
Qing Zhao
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/CAKbe0hpMmKapjLHLVG3fDqEoygx1Umn5duV8V%3DTaoA17GGzUKw%40mail.gmail.com.
Daniel Turek
Daniel
Qing Zhao
Quresh Latif
Daniel Turek
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/a8d249fe-248a-4ac0-afa5-82d5615cfb38n%40googlegroups.com.
Quresh Latif
OK, thanks. How do we disable the limit of 10 dimensions for saving proposal covariance histories?
Also, any suggestions on how to go about identifying reasonable proposal covariances? All I can think of doing is running the model for a short bit and then saving the proposal covariances, but then I’m not sure I’m doing anything more than the automated algorithm for determining the covariance. Are there any good references you can suggest that describe approaches for tuning block samplers?
Quresh S. Latif
Research Scientist
Bird Conservancy of the Rockies
Phone: (970) 482-1707 ext. 15
www.birdconservancy.org
From: Daniel Turek <danie...@gmail.com>
Sent: Tuesday, June 20, 2023 6:45 PM
To: Quresh Latif <quresh...@birdconservancy.org>
Cc: nimble-users <nimble...@googlegroups.com>
Subject: Re: Improving MCMC convergence
Quresh, thanks for the message, and it's great that you're digging into these aspects of the samplers. Just a few comments.
To view this discussion on the web visit https://link.edgepilot.com/s/29117821/lQla8AEkUU247Z5ZaFEsUg?u=https://groups.google.com/d/msgid/nimble-users/fb09d55d-d364-4ae9-9419-9a3cf02df462n%2540googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "nimble-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to nimble-users...@googlegroups.com.
To view this discussion on the web visit https://link.edgepilot.com/s/56555f10/pRPsVYda00al2j7oQPu36g?u=https://groups.google.com/d/msgid/nimble-users/a8d249fe-248a-4ac0-afa5-82d5615cfb38n%2540googlegroups.com.
Daniel Turek
name = 'sampler_RW_block2',
contains = sampler_BASE,
setup = function(model, mvSaved, target, control) {
## control list extraction
adaptive <- extractControlElement(control, 'adaptive', TRUE)
adaptScaleOnly <- extractControlElement(control, 'adaptScaleOnly', FALSE)
adaptInterval <- extractControlElement(control, 'adaptInterval', 200)
adaptFactorExponent <- extractControlElement(control, 'adaptFactorExponent', 0.8)
scale <- extractControlElement(control, 'scale', 1)
propCov <- extractControlElement(control, 'propCov', 'identity')
tries <- extractControlElement(control, 'tries', 1)
## node list generation
targetAsScalar <- model$expandNodeNames(target, returnScalarComponents = TRUE)
ccList <- mcmc_determineCalcAndCopyNodes(model, target)
calcNodes <- ccList$calcNodes; copyNodesDeterm <- ccList$copyNodesDeterm; copyNodesStoch <- ccList$copyNodesStoch # not used: calcNodesNoSelf
finalTargetIndex <- max(match(model$expandNodeNames(target), calcNodes))
if(!is.integer(finalTargetIndex) | length(finalTargetIndex) != 1 | is.na(finalTargetIndex[1])) stop('problem with target node in RW_block sampler')
calcNodesProposalStage <- calcNodes[1:finalTargetIndex]
calcNodesDepStage <- calcNodes[-(1:finalTargetIndex)]
## numeric value generation
scaleOriginal <- scale
timesRan <- 0
timesAccepted <- 0
timesAdapted <- 0
d <- length(targetAsScalar)
scaleHistory <- c(0, 0) ## scaleHistory
acceptanceHistory <- c(0, 0) ## scaleHistory
propCovHistory <- array(0, c(2,d,d)) ## scaleHistory
saveMCMChistory <- if(nimbleOptions('MCMCsaveHistory')) TRUE else FALSE
if(is.character(propCov) && propCov == 'identity') propCov <- diag(d)
propCovOriginal <- propCov
chol_propCov <- chol(propCov)
chol_propCov_scale <- scale * chol_propCov
empirSamp <- matrix(0, nrow=adaptInterval, ncol=d)
## nested function and function list definitions
targetNodesAsScalar <- model$expandNodeNames(target, returnScalarComponents = TRUE)
my_calcAdaptationFactor <- calcAdaptationFactor(d, adaptFactorExponent)
## checks
if(!inherits(propCov, 'matrix')) stop('propCov must be a matrix\n')
if(!inherits(propCov[1,1], 'numeric')) stop('propCov matrix must be numeric\n')
if(!all(dim(propCov) == d)) stop('propCov matrix must have dimension ', d, 'x', d, '\n')
if(!isSymmetric(propCov)) stop('propCov matrix must be symmetric')
},
run = function() {
for(i in 1:tries) {
propValueVector <- generateProposalVector()
values(model, targetNodesAsScalar) <<- propValueVector
lpD <- model$calculateDiff(calcNodesProposalStage)
if(lpD == -Inf) {
jump <- FALSE
nimCopy(from = mvSaved, to = model, row = 1, nodes = calcNodesProposalStage, logProb = TRUE)
} else {
lpD <- lpD + model$calculateDiff(calcNodesDepStage)
jump <- decide(lpD)
if(jump) {
##model$calculate(calcNodesPPomitted)
nimCopy(from = model, to = mvSaved, row = 1, nodes = calcNodesProposalStage, logProb = TRUE)
nimCopy(from = model, to = mvSaved, row = 1, nodes = copyNodesDeterm, logProb = FALSE)
nimCopy(from = model, to = mvSaved, row = 1, nodes = copyNodesStoch, logProbOnly = TRUE)
} else {
nimCopy(from = mvSaved, to = model, row = 1, nodes = calcNodesProposalStage, logProb = TRUE)
nimCopy(from = mvSaved, to = model, row = 1, nodes = copyNodesDeterm, logProb = FALSE)
nimCopy(from = mvSaved, to = model, row = 1, nodes = copyNodesStoch, logProbOnly = TRUE)
}
}
if(adaptive) adaptiveProcedure(jump)
}
},
methods = list(
generateProposalVector = function() {
propValueVector <- rmnorm_chol(1, values(model,target), chol_propCov_scale, 0) ## last argument specifies prec_param = FALSE
returnType(double(1))
return(propValueVector)
},
adaptiveProcedure = function(jump = logical()) {
timesRan <<- timesRan + 1
if(jump) timesAccepted <<- timesAccepted + 1
if(!adaptScaleOnly) empirSamp[timesRan, 1:d] <<- values(model, target)
if(timesRan %% adaptInterval == 0) {
acceptanceRate <- timesAccepted / timesRan
timesAdapted <<- timesAdapted + 1
if(saveMCMChistory) {
setSize(scaleHistory, timesAdapted) ## scaleHistory
scaleHistory[timesAdapted] <<- scale ## scaleHistory
setSize(acceptanceHistory, timesAdapted) ## scaleHistory
acceptanceHistory[timesAdapted] <<- acceptanceRate ## scaleHistory
propCovTemp <- propCovHistory ## scaleHistory
setSize(propCovHistory, timesAdapted, d, d) ## scaleHistory
if(timesAdapted > 1) ## scaleHistory
for(iTA in 1:(timesAdapted-1)) ## scaleHistory
propCovHistory[iTA, 1:d, 1:d] <<- propCovTemp[iTA, 1:d, 1:d] ## scaleHistory
propCovHistory[timesAdapted, 1:d, 1:d] <<- propCov[1:d, 1:d] ## scaleHistory
}
adaptFactor <- my_calcAdaptationFactor$run(acceptanceRate)
scale <<- scale * adaptFactor
## calculate empirical covariance, and adapt proposal covariance
if(!adaptScaleOnly) {
gamma1 <- my_calcAdaptationFactor$getGamma1()
for(i in 1:d) empirSamp[, i] <<- empirSamp[, i] - mean(empirSamp[, i])
empirCov <- (t(empirSamp) %*% empirSamp) / (timesRan-1)
propCov <<- propCov + gamma1 * (empirCov - propCov)
chol_propCov <<- chol(propCov)
}
chol_propCov_scale <<- chol_propCov * scale
timesRan <<- 0
timesAccepted <<- 0
}
},
setScale = function(newScale = double()) {
scale <<- newScale
scaleOriginal <<- newScale
chol_propCov_scale <<- chol_propCov * scale
},
setPropCov = function(newPropCov = double(2)) {
propCov <<- newPropCov
propCovOriginal <<- newPropCov
chol_propCov <<- chol(propCov)
chol_propCov_scale <<- chol_propCov * scale
},
getScaleHistory = function() { ## scaleHistory
if(!saveMCMChistory) print("Please set 'nimbleOptions(MCMCsaveHistory = TRUE)' before building the MCMC.")
returnType(double(1))
return(scaleHistory)
},
getAcceptanceHistory = function() { ## scaleHistory
returnType(double(1))
if(!saveMCMChistory) print("Please set 'nimbleOptions(MCMCsaveHistory = TRUE)' before building the MCMC.")
return(acceptanceHistory)
},
getPropCovHistory = function() { ## scaleHistory
if(!saveMCMChistory) print("Please set 'nimbleOptions(MCMCsaveHistory = TRUE)' before building the MCMC and note that to reduce memory use we only save the proposal covariance history for parameter vectors of length infinity or less.")
returnType(double(3))
return(propCovHistory)
},
reset = function() {
scale <<- scaleOriginal
propCov <<- propCovOriginal
chol_propCov <<- chol(propCov)
chol_propCov_scale <<- chol_propCov * scale
timesRan <<- 0
timesAccepted <<- 0
timesAdapted <<- 0
if(saveMCMChistory) {
scaleHistory <<- c(0, 0) ## scaleHistory
acceptanceHistory <<- c(0, 0)
propCovHistory <<- nimArray(0, dim = c(2,d,d))
}
my_calcAdaptationFactor$reset()
}
)
)
Quresh Latif
Awesome, thank you!
I imagine you might be dreading this question, but would it make sense to have an option built in to toggle the d<=10 limit off, possibly along with a warning that this should only be toggled off for small preliminary runs to avoid overloading memory? Totally understandable if this level of customization is outside the scope of your development plan for NIMBLE, considering that you allow for users to supply their own samplers.
Quresh S. Latif
Research Scientist
Bird Conservancy of the Rockies
Phone: (970) 482-1707 ext. 15
www.birdconservancy.org
From: Daniel Turek <danie...@gmail.com>
Sent: Wednesday, June 21, 2023 12:00 PM
To: Quresh Latif <quresh...@birdconservancy.org>
Cc: nimble-users <nimble...@googlegroups.com>
Subject: Re: Improving MCMC convergence
Although somewhat crude, the most straightforward approach is to copy the sampler code (copied directly from line 324 of MCMC_samplers.R), remove this check that d<=10, and define a new sampler (below called sampler_RW_block2). Then, using conf$removeSamplers() and conf$addSampler(), use this custom sampler_RW_block2 in place of the original RW_block samplers.