NeuCLIR1 Document Collection

Dawn Lawrie
Hello!
NeuCLIR 2022 has released its document collection. Topics will be released in the second half of June. Below we have compiled information about the document collection. This information is also accessible here.
The NeuCLIR1 document collection is available for download by those registered for TREC 2022 at https://trec.nist.gov/act_part/tracks2022.html. The document collection consists of documents in three languages: Chinese, Persian, and Russian, drawn from the Common Crawl news collection. They were obtained by Common Crawl between August 1, 2016 and July 31, 2021; most of the documents were published within this five year window. Text was extracted from each source webpage using the Python utility newspaper. The collection is distributed as JSONL – a list of JSON objects representing each document, one per line. Each document JSON structure consists of the following fields:
- id: document ID assigned by Common Crawl
- cc_file: raw Common Crawl document
- time: time of publication, or null
- title: article headline or title
- text: article body
- url: address of the source Webpage
To ascertain the language of each document, its title and text were independently run through two automatic language identification tools, cld3 and VaLID. Documents where the tools agreed on the language, or where one of the tools agreed the language recorded in the webpage metadata, were included in the collection; all others were removed. All documents greater than 24,000 characters (approximately 10 pages of text) were also removed, as were Chinese documents containing 75 or fewer characters, Persian documents containing 100 or fewer characters, and Russian documents containing 200 or fewer characters.
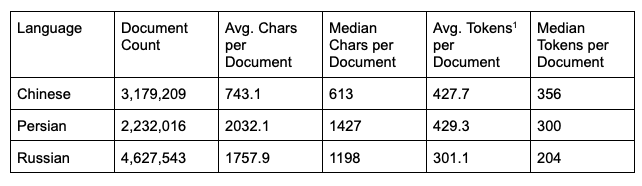
Each collection was limited to 5 million documents. After removing duplicates, the Russian collection was significantly above this threshold. Therefore, we used Scikit-learn's implementation of random sample without replacement to downsample the collection. Final collection statistics are as follows:

John M. Conroy

Samy Ateia
I only indexed 4,627,347 unique IDs from the Russian collection even though the JSONL file has 4,627,542 lines. The other collections match.
Samy Ateia
Dawn J. Lawrie
--
You received this message because you are subscribed to the Google Groups "neuclir-participants" group.
To unsubscribe from this group and stop receiving emails from it, send an email to neuclir-particip...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/neuclir-participants/6e4867db-a44e-4ab8-83ac-5d79c2d6cc8fn%40googlegroups.com.
Dawn J. Lawrie Ph.D.
Senior Research Scientist
Human Language Technology Center of Excellence
Johns Hopkins University
810 Wyman Park Drive
Baltimore, MD 21211
law...@jhu.edu
https://hltcoe.jhu.edu/faculty/dawn-lawrie/
John M. Conroy
John M. Conroy
ASAP: TREC Registration: https://ir.nist.gov/trecsubmit.open/application.html
Already: Document collection available for download (including translations of the documents into English)
June 22, 2022: Topics released with human translations of English topics into document languages
June 24, 2022: Machine translations and runs for reranking
October 2022: Relevance judgements and individual evaluation scores released
Late October 2022: Initial system description papers due
- For Chinese, documents have been distributed as they were written in either Simplified or Traditional Chinese. Likewise, some human translations of topics will be in Traditional Chinese, while others are in Simplified Chinese.
- We have released a script to convert between Traditional and Simplified, which works well except for some named entities.
- Topics will be released in a json format
- Runs for reranking will index translated documents and produce a ranking with BM25. These runs will be released in the TREC submission format.