Zero-copy?
482 views
Skip to first unread message

Sofus Mortensen
Sep 3, 2014, 10:04:17 AM9/3/14
to netm...@googlegroups.com
Hello,
Any thoughts/plan on patching NetMQ to minimize memory allocation (and thereby reducing GC) ?
/Sofus

Doron Somech
Sep 3, 2014, 10:10:00 AM9/3/14
to Sofus Mortensen, netm...@googlegroups.com
Do you experience any problems? this can be a nice idea but until now nobody had a problem.
--
You received this message because you are subscribed to the Google Groups "netmq-dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to netmq-dev+...@googlegroups.com.
To post to this group, send email to netm...@googlegroups.com.
Visit this group at http://groups.google.com/group/netmq-dev.
For more options, visit https://groups.google.com/d/optout.
Sofus Mortensen
Sep 3, 2014, 3:47:11 PM9/3/14
to netm...@googlegroups.com, sofusmo...@gmail.com
Publishing small messages non-stop results in an average 0.5 % freeze spend in GC. This is using background server GC mode on 4.5 with SustainedLowLatency mode. There seems to be occasional freezes in excess of 200 ms.
I believe this can be reduced to zero, and combined with SBE or FlatBuffers for serialization, we can create trade registration or price distribution with no GC pauses.
Sofus.

Oren Eini (Ayende Rahien)
Sep 3, 2014, 4:20:10 PM9/3/14
to Sofus Mortensen, netm...@googlegroups.com
As a note, zero copy is really important for server apps, because the cost of allocating the memory tend to be problematic.
Especially if you have very large messages.
Doron Somech
Sep 3, 2014, 5:13:29 PM9/3/14
to Oren Eini (Ayende Rahien), Sofus Mortensen, netm...@googlegroups.com
I agree regarding the zero copy, both ZeroMQ and NetMQ designed to have minimal memory allocation on the critical path.
Sofus, there is advanced feature with NetMQ to disable copy of messages, the thing is that when you send a message that message buffer is being copied to avoid a case that you change the buffer before the message is being send. However you can disable that, but you are not allowed to change buffer after disabling this feature, to disable it you can set to false CopyMessages on sockes.Options.
Sofus can you tell which objects do you see get created a lot? What is the scenario you are using? (how many messages, size of message, how many clients, which socket type)
I will try to reduce pressure on the garbage collector.
Oren Eini (Ayende Rahien)
Sep 3, 2014, 5:18:05 PM9/3/14
to Doron Somech, Sofus Mortensen, netm...@googlegroups.com
Are you doing buffer pool for the buffers used for messages?
Sofus Mortensen
Sep 4, 2014, 2:35:52 AM9/4/14
to netm...@googlegroups.com, aye...@ayende.com, sofusmo...@gmail.com
Doron, Options.CopyMessages is default set to false (did you intend that?).
I think the main source of object allocations is actually the 'new Msg' in NetMQSocket.Send.
My scenario (which is just test for now) is a Pub socket that is relentlessly pushing very small messages (< 100 bytes). If I increase the message size to 100kb, memory performance becomes really, really bad (%gc time >50)
I would like to see NetMQ evolve into a messaging system where it is possible to build server applications with no memory allocations (once the application is up and running). I am eager to help achieve this goal (if you agree).
I would like to see NetMQ evolve into a messaging system where it is possible to build server applications with no memory allocations (once the application is up and running). I am eager to help achieve this goal (if you agree).
Sofus
Doron Somech
Sep 4, 2014, 6:14:04 AM9/4/14
to Sofus Mortensen, netm...@googlegroups.com, Ayende Rahien
Sofus, I was under the impression that the default is false, if it is true I think that the feature is unneeded, or can be marked as obsolete (nobody had a problem with it).
I'm surprised with "new Msg" because it is only holding the message buffer, also I think I can make the object smaller by 16 bytes (and maybe convert it to struct), but it doesn't explain the high garbage collection you have with larger messages.
Regarding evolving NetMQ to no memory allocations, it will be great to achieve that! but you don't have to ask my permission... I'm not owning NetMQ :-) (nobody is), so yes of course please help.
Oren, very cool, didn't know that, do you know if internally it used locks? should I use one BufferManager per worker thread or entire Context? anyway I will check it out.
My thoughts are, I cannot control the creating of buffers when it come to the user (sending messages), I can recommend to use BufferManager (and when NetMQ finish with a buffer it will return it to the BufferManager), on messages arriving I can use the BufferManager, but will have to make messages disposable some how (byte array is not) also the feature should have a feature switch which will be off by default for backwards compatibility.
Doron Somech
Sep 6, 2014, 1:03:58 PM9/6/14
to netm...@googlegroups.com, sofusmo...@gmail.com, aye...@ayende.com
Sofus can you check the following branch: https://github.com/somdoron/NetMQ/tree/ZeroMemory.
Msg is now using BufferManager suggested by Oren, however the Send/Receive methods copy everything to new allocated buffer (which means you can reuse the byte array for other stuff, keeps memory allocation to zero but with copy).
If you want zero-copy as well you can work directly with Send/Receive overload the accept Msg object, to understand how to work with Msg take a look at the other overloads that use Msg overload.
Sofus, thanks for brought that up, I think it is important change for NetMQ, I eager to hear your response.
P.S - this branch doesn't include the Pub/Sub fix because it was not merged to master yet.
To unsubscribe from this group and stop receiving emails from it, send an email to netmq-dev+unsubscribe@googlegroups.com.
Doron Somech
Sep 8, 2014, 5:34:31 AM9/8/14
to netm...@googlegroups.com, sofusmo...@gmail.com, aye...@ayende.com
Oren the use of BufferManager drops NetMQ performance by around 40% percent, any suggestions? (I checked the same code with the use of BufferManager and without).
Oren Eini (Ayende Rahien)
Sep 8, 2014, 5:35:40 AM9/8/14
to Doron Somech, Sofus Mortensen, netm...@googlegroups.com
Do you have profiler output?
Doron Somech
Sep 8, 2014, 5:37:05 AM9/8/14
to Oren Eini (Ayende Rahien), Sofus Mortensen, netm...@googlegroups.com
Not yet, working on that.
Doron Somech
Sep 8, 2014, 9:39:56 AM9/8/14
to netm...@googlegroups.com, aye...@ayende.com, sofusmo...@gmail.com
Bottom line is that with profiling, NetMQ is spending around 4.5% in BufferPool methods.
I'm not sure yet why it cause 40% decrease.
Msg.Close is the method call BufferPool.Return, method the call Buffer.Take was inlined in both scenario, Following are the results:
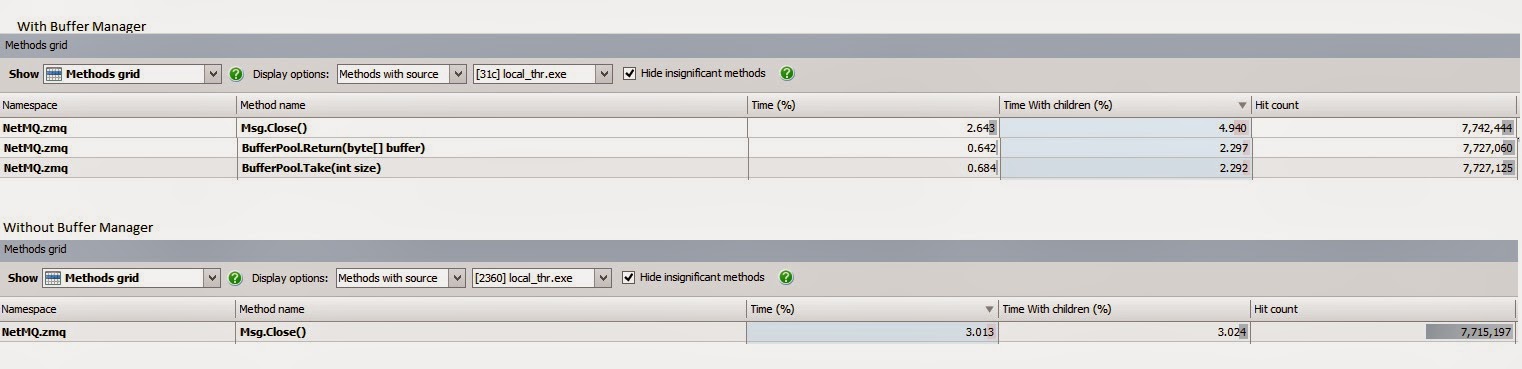
Actually without the BufferPool the performance are little better then before.
I think we have two options, make a feature switch for the Buffer Pool, users that need better memory management can use the buffer pool, users that needs the throughput can disable it.
Second option is trying to implement a better buffer pooling, not an easy task...
Thoughts?
Oren Eini (Ayende Rahien)
Sep 8, 2014, 12:06:03 PM9/8/14
to Doron Somech, netm...@googlegroups.com, Sofus Mortensen
Can you let me know the branch and the code that you are running to test this?
Doron Somech
Sep 8, 2014, 12:46:01 PM9/8/14
to Oren Eini (Ayende Rahien), netm...@googlegroups.com, Sofus Mortensen
Master branch on https://github.com/zeromq/netmq.



The BufferPool is currently in https://github.com/zeromq/netmq/blob/master/src/NetMQ/zmq/Msg.cs, when I want to disable the buffer pool I'm commenting the take and return and instead of take allocating new byte array, like this:
To test Build the entire solution and run local_thr and remote_thr (local_thr first), in release mode you should see the different between with the buffer pool and without. To run the local_thr and remote_thr navigate to the exe location (preferably release mode) and run the following:
for local_thr run:
local_thr.exe tcp://127.0.0.1:4713 10 10000000
for remote_thr run:
remote_thr.exe tcp://127.0.0.1:4713 10 10000000
For example on my laptop, with buffer pool:
and without:
You can play with message size (the parameter after the address).
Oren Eini (Ayende Rahien)
Sep 8, 2014, 4:37:42 PM9/8/14
to Doron Somech, netm...@googlegroups.com, Sofus Mortensen
On my machine, with buffer pool:
message size: 10 [B]
message count: 10,000,000
mean throughput: 1,904,399.16 [msg/s]
mean throughput: 152.35 [Mb/s]
Without:
message size: 10 [B]
message count: 10,000,000
mean throughput: 3,037,667.07 [msg/s]
mean throughput: 243.01 [Mb/s]
That was interesting, then I realized that the actual buffer sizes were minuscule.
With 10 bytes, there isn't really anything that the GC needs to do, especially if the buffers are short lived.
I then decided to run this with a 2KB messages and 1 million messages.
Without:
message size: 2,048 [B]
message count: 1,000,000
mean throughput: 112,803.16 [msg/s]
mean throughput: 1,848.17 [Mb/s]
With:
message size: 2,048 [B]
message count: 1,000,000
mean throughput: 111,831.8 [msg/s]
mean throughput: 1,832.25 [Mb/s]
So now we are looking at effective parity.
I then tried it with 8,500 bytes.
With buffer pool:
message size: 8,500 [B]
message count: 1,000,000
mean throughput: 26,215.76 [msg/s]
mean throughput: 1,782.67 [Mb/s]
Without buffer pool:
message size: 8,500 [B]
message count: 1,000,000
mean throughput: 26,735.11 [msg/s]
mean throughput: 1,817.99 [Mb/s]
Then I realized, what you are actually doing is pretty basic stuff, with a single buffer checked out at any given time.
And given that pattern, I decided to write a truly stupid buffer manager, just to see if that would work:
public static class BufferPool
{
[ThreadStatic] private static byte[] _buffer;
public static byte[] Take(int size)
{
var buffer = _buffer;
if (buffer == null)
{
return new byte[size];
}
if (buffer.Length < size)
return new byte[size];
_buffer = null;
return buffer;
}
public static void Return(byte[] buffer)
{
if (_buffer == null)
{
_buffer = buffer;
return;
}
if (buffer.Length > _buffer.Length)
{
_buffer = buffer;
return;
}
}
}
With it:
message size: 8,500 [B]
message count: 1,000,000
mean throughput: 28,314.17 [msg/s]
mean throughput: 1,925.36 [Mb/s]
message size: 2,048 [B]
message count: 1,000,000
mean throughput: 115,207.37 [msg/s]
mean throughput: 1,887.56 [Mb/s]
message size: 10 [B]
message count: 10,000,000
mean throughput: 2,912,904.17 [msg/s]
mean throughput: 233.03 [Mb/s]
What this looks like is that for small buffer sizes, it doesn't matter, probably because the GC can just allocate them fast enough that adding any complexity along that path is meaningless.
But when we start talking about larger messages, it really matters.
I tried it with 256Kb buffer, where it really matters (LOH allocations).
With my silly buffering code:
message size: 262,144 [B]
message count: 10,000
mean throughput: 1,857.36 [msg/s]
mean throughput: 3,895.16 [Mb/s]
Without the buffering code:
message size: 262,144 [B]
message count: 10,000
mean throughput: 1,737.62 [msg/s]
mean throughput: 3,644.05 [Mb/s]
Now, note that you test is actually doing a single thread send.
I tried doing the send from 10 threads:
var tasks = new List<Task>();
for (int h = 0; h < 10; h++)
{
tasks.Add(Task.Factory.StartNew(() =>
{
var pushSocket = ZMQ.Socket(context, ZmqSocketType.Push);
pushSocket.Connect(connectTo);
for (int i = 0; i != messageCount / 10; i++)
{
var message = new Msg();
message.InitPool(messageSize);
pushSocket.Send(ref message, SendReceiveOptions.None);
message.Close();
}
pushSocket.Close();
}));
}
Task.WaitAll(tasks.ToArray());
That resulted in (without buffering):
message size: 262,144 [B]
message count: 10,000
mean throughput: 465.59 [msg/s]
mean throughput: 976.42 [Mb/s]
With silly buffering:
message size: 262,144 [B]
message count: 10,000
mean throughput: 1,048.44 [msg/s]
mean throughput: 2,198.73 [Mb/s]
With BufferManager:
message size: 262,144 [B]
message count: 10,000
mean throughput: 2,700.51 [msg/s]
mean throughput: 5,663.39 [Mb/s]
So here we are actually able to take advantage of the buffering, by reusing buffering. When we are running in single threaded mode, you don't see that at all.
But when you are looking at the multi threaded scenario, the results are far more dramatic.
I am not an expert in NetMQ actual usage scenarios, but I think that this usage scenario would be far more common (multiple concurrent sockets in a process) than a single socket running a single thread.
thoughts?

tobi-tobsen
Sep 9, 2014, 1:39:07 AM9/9/14
to netm...@googlegroups.com
My first thought: the zmq throughput perf test should allow multithreaded usage to test stuff like this.
Second thought: Imo, both use cases (multithreaded/ and single threaded usage of zmq) are valid: using one sending or receiving thread is especially common for pair sockets.
Is it worth the troubles to differentiate between sockets or threading usage or add a setting for this?
Also I wonder if the buffer makes a difference with smaller messages and multiple threads? Theoretically it should but haven't measured yet...
Doron Somech
Sep 9, 2014, 3:28:19 AM9/9/14
to netm...@googlegroups.com
Very interesting!
Regarding the multithread, I'm not sure if it is the multithread or server that handling multiple clients (which is very common).
Another question is what should be the maximum buffer size and maximum pool size? I think there no one rule here and different scenarios need different configuration.
With that I think buffer pooling can help, maybe not in all scenarios, but it can help. I think we should have three options:
- Without Buffer Pool
- With Buffer Pool and ability to configure the parameters
- With custom buffer pool (for example, not using buffer pool for small messages and only for big messages)
I think the without buffer pool should be the default option because this is what users know, and it should be conscious decision to use buffer pooling.
The only issue (which I think we can live with) is that configuring the buffer pool is cross NetMQContext and is for entire usages of NetMQ.

Rei Roldan
Sep 9, 2014, 4:03:50 AM9/9/14
to netm...@googlegroups.com, somd...@gmail.com, sofusmo...@gmail.com
Oren, unlike standard socket programming zmq applications don't typically use multiple sockets on multiple threads. They can, but it's not the usual use case, it's the kind of thing zmq tries to avoid in the first place ;)
Sofus Mortensen
Sep 9, 2014, 4:20:02 AM9/9/14
to netm...@googlegroups.com
I have attached my results (from my laptop, not particular fast). I wrote a small buffer manager, thread-safe and lock-free. For very small messages, it is hard to outperform GC.
I will look into latency numbers next. I suspect GC might incur bad tail latencies.
/Sofus
GC:
message size: 1 [B]
message count: 100000000
mean throughput: 2182500.709 [msg/s]
mean throughput: 17.460 [Mb/s]
BufferManager:
message size: 1 [B]
message count: 100000000
mean throughput: 1340788.115 [msg/s]
mean throughput: 10.726 [Mb/s]
Custom:
message size: 1 [B]
message count: 100000000
mean throughput: 2037614.361 [msg/s]
mean throughput: 16.301 [Mb/s]
GC:
message size: 10000 [B]
message count: 100000
mean throughput: 3700.278 [msg/s]
mean throughput: 296.022 [Mb/s]
BufferManager:
message size: 10000 [B]
message count: 100000
mean throughput: 3652.701 [msg/s]
mean throughput: 292.216 [Mb/s]
Custom:
message size: 10000 [B]
message count: 100000
mean throughput: 3939.645 [msg/s]
mean throughput: 315.172 [Mb/s]
Doron Somech
Sep 9, 2014, 4:57:56 AM9/9/14
to netm...@googlegroups.com
What do you think https://github.com/somdoron/netmq/blob/CustomBufferPool/src/NetMQ/zmq/BufferPool.cs?
I think it is the simplest approach, we can later add more types of buffers for different scenarios
Oren Eini (Ayende Rahien)
Sep 9, 2014, 5:43:38 AM9/9/14
to Rei Roldan, netm...@googlegroups.com, Doron Somech, Sofus Mortensen
Sure they do.
Consider the case that we have a front end client, and we want to use netmq to send/receive messages from our backend, how would that work?
A socket is single threaded, so you _have_ to use multiple sockets.
You might not be explicitly doing threading, but you are certainly using multiple threads.
Also, on the server end, if processing a message is going to take time, you are certainly going to have multiple threads doing it.
Oren Eini (Ayende Rahien)
Sep 9, 2014, 5:46:38 AM9/9/14
to Doron Somech, netm...@googlegroups.com
* I would do it on a _context_, not statically
* I think a better policy would be to have buffer pool for large than X size, and just new up buffers for very small messages.
Personally, I dislike defaults that trips you, or "expert configuration mode", and this feels like something like that.
* Do you have any idea about common message sizes?
Note that for my own use cases, the expected message size is 4 - 800 Kbs, and multiple MB is very probably as well.
In those scenarios, buffering really help
--
Doron Somech
Sep 9, 2014, 5:59:27 AM9/9/14
to Oren Eini (Ayende Rahien), netm...@googlegroups.com
I agree regarding the expert mode, however I don't think we can find a common group here? what about windows phones or tablets, which cannot allocate a lot of memory?
Also you are afraid from a lot of time taking to allocate a large buffers, so you don't want buffer pool for small messages, my scenario is that I have a lot of small messages and I don't want the GC to kick in and take 200MS in the middle of the unemployment report, so I would give up the throughput for less GC time.
Regarding making the Buffer Pool per for context, I think it's better as well, however then we will have ugly syntax to allocate a message, something like context.NewMsg(ref msg), because msg is a struct.
Rei Roldan
Sep 9, 2014, 5:59:33 AM9/9/14
to netm...@googlegroups.com, raro...@gmail.com, somd...@gmail.com, sofusmo...@gmail.com
The way you would design that Oren is you would have a receive socket for the server on one thread and dealer socket where "workers" would connect and receive the requests. Take for example RavenDB, I was playing around with the indexing parts so that indexing could be distributed in a round robin fashion to index workers a sink would later store the results in the same way Raven does it. The details of what it looks like are here: http://zguide.zeromq.org/page:all#Divide-and-Conquer
What I am trying to get at is, zmq tries to eliminate the need for doing traditional multithreading using a messaging approach.
Oren Eini (Ayende Rahien)
Sep 9, 2014, 6:03:03 AM9/9/14
to Doron Somech, netm...@googlegroups.com
Or,
msg.InitPool(ctx, size):
No?
Doron Somech
Sep 9, 2014, 6:14:56 AM9/9/14
to Oren Eini (Ayende Rahien), netm...@googlegroups.com
yes, you are right. Cool :-)
Sofus Mortensen
Sep 9, 2014, 6:45:25 AM9/9/14
to netm...@googlegroups.com, somd...@gmail.com
Actually I disagree about the small messages vs large messages.
A low latency critical system would use relatively small messages, and I strongly suspect GC'ing will cause bad tail latencies. If you are using large messages, then you are not low latency to begin with and don't worry about gc.
/Sofus
Oren Eini (Ayende Rahien)
Sep 9, 2014, 6:48:06 AM9/9/14
to Sofus Mortensen, netm...@googlegroups.com, Doron Somech
The key here is that when you do a lot of small messages, the GC can just dump the entire generation 0 heaps out and reuse it.
When you do large messages, that sits on the LOH, and that is a much more costly thing.
Doron Somech
Sep 9, 2014, 6:54:52 AM9/9/14
to Oren Eini (Ayende Rahien), Sofus Mortensen, netm...@googlegroups.com
But it can takes time, in trading systems you want to limit the GC to almost zero, even generation 0.
Oren Eini (Ayende Rahien)
Sep 9, 2014, 7:00:11 AM9/9/14
to Doron Somech, Sofus Mortensen, netm...@googlegroups.com
Sure, that is why you use buffering system.
Even in the case that it slows you down some, it usually gives you _consistent_ performance, which is more important.
Sofus Mortensen
Sep 9, 2014, 7:03:48 AM9/9/14
to netm...@googlegroups.com, somd...@gmail.com, sofusmo...@gmail.com
My goal is to be able to receive and dispatch messages without any GC, even gen 0. SBE can do serialization without GC.
I believe we should be able to roll out our own buffer manager with performance on par with new. Mine's only 7% off for the small messages.
/Sofus
Oren Eini (Ayende Rahien)
Sep 9, 2014, 7:04:59 AM9/9/14
to Sofus Mortensen, netm...@googlegroups.com, Doron Somech
SBE?
Oren Eini (Ayende Rahien)
Sep 9, 2014, 7:06:56 AM9/9/14
to Sofus Mortensen, netm...@googlegroups.com, Doron Somech
BTW, I certainly agree on buffering being a good thing to have in general.
Sofus Mortensen
Sep 9, 2014, 7:17:52 AM9/9/14
to netm...@googlegroups.com, sofusmo...@gmail.com, somd...@gmail.com
Doron Somech
Sep 9, 2014, 8:37:09 AM9/9/14
to Sofus Mortensen, netm...@googlegroups.com
Ok, so I'm offering again the solution that by default the GC will be used, user can set BufferPool with parameters or create custom buffer pool.
Sofus when you have a good implementation for buffer pooling send a pull request, we might change NetMQ to use that by default or recommended buffer pooling.
The only issue left is that implementing BufferPooling in the context is a little complicated because the context has to be passed around all the time.
Rei Roldan
Sep 9, 2014, 8:42:53 AM9/9/14
to netm...@googlegroups.com, sofusmo...@gmail.com
There is still one thing I don't understand, the socket send/receive methods both take the message parameter by reference, isn't the whole buffering infrastructure outside the scope of zmq to begin with?
Doron Somech
Sep 12, 2014, 2:51:24 AM9/12/14
to Rei Roldan, netm...@googlegroups.com, Sofus Mortensen
Actually the buffering is something that kind of exist in zeromq as well, I ported the way zeromq is managing to zeromq, the thing is that in zeromq you need to know when you can release the buffer, so the Msg object is reference counted, everytime you make a copy of the Msg you increase the counter, when the counter is zero you free the buffer, we do the same, except when the counter is zero we return the buffer to the pool
Reply all
Reply to author
Forward
0 new messages