Duplicate Nodes
1,425 views
Skip to first unread message

Timothy Braun
Jan 20, 2012, 5:33:49 PM1/20/12
to ne...@googlegroups.com
Hey Guys,
Any suggestions for finding duplicate nodes based on a node index ie, index on username property of a node?
Also, is there any way to implement unique node constraints?
Thanks,
Tim

Peter Neubauer
Jan 21, 2012, 4:37:28 AM1/21/12
to ne...@googlegroups.com
You mean creating entries only if they exist?
That came in 1.6.M03, see
http://docs.neo4j.org/chunked/snapshot/rest-api-unique-indexes.html
and http://components.neo4j.org/neo4j/1.6.M03/apidocs/org/neo4j/graphdb/index/Index.html#putIfAbsent%28T,%20java.lang.String,%20java.lang.Object%29
Cheers,
/peter neubauer
Google: neubauer.peter
Skype: peter.neubauer
Phone: +46 704 106975
LinkedIn: http://www.linkedin.com/in/neubauer
Twitter: @peterneubauer
Tungle: tungle.me/peterneubauer
brew install neo4j && neo4j start
heroku addons:add neo4j

Aseem Kishore
Jan 27, 2013, 9:08:35 PM1/27/13
to Neo4j Discussion
+1 -- would love a suggestion for this. Thanks Rory for bringing it up.
On Sun, Jan 27, 2013 at 6:42 PM, Rory Madden <rorym...@gmail.com> wrote:
Unique indexes are great to prevent duplicates being created but is there a suggested approach for identifying duplicates across the graph.E.g. with the movie graph if you don't implement unique indexes (because movies can have the same name) and two people create the same movie with the same actors is there a way to identify the duplication?Solr has MD5Signature, Lookup3Signature, TextProfileSignature algoritms for detecting duplicates but are there any examples of people using similar algorithms with Neo4j and the Lucene instance?Thanks,Rory
--
You received this message because you are subscribed to the Google Groups "Neo4j" group.
To unsubscribe from this group, send email to neo4j+un...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.

Wes Freeman
Jan 27, 2013, 10:02:34 PM1/27/13
to ne...@googlegroups.com
I've been using somewhat hacky cypher queries for preventing duplicate creation, sometimes involving two index lookups.
This one aims to create at least one node, and sometimes two. One position node that might have already been created, and one fen node that hasn't, but should reference either a new position node or the existing one.
To the OP: You can have compound indexes--is that what you're looking for? Like "name, year", for movies. Or maybe you'd have a year node, and do something like (assume year is created already):
start movie=node:node_auto_index(name={name}), year=node:node_auto_index(year={year})
match movie-[?:made_in]->year
with count(movie) as cnt, year
where cnt = 0
create (movie {name:{name}})-[:made_in]->year;
This one aims to create at least one node, and sometimes two. One position node that might have already been created, and one fen node that hasn't, but should reference either a new position node or the existing one.
"""start pos=node:node_auto_index(pos={pos})with count(pos) as existsposwhere existspos = 0create pos={pos:{pos}}with count(1) as dummystart pos=node:node_auto_index(pos={pos})create unique (pos)<-[:position]-(fen {fen:{fen}})set fen.score={score}"""
I didn't spend too much time trying to optimize this, so there might be a better way. It's certainly not the bottleneck of my program at the moment.
To the OP: You can have compound indexes--is that what you're looking for? Like "name, year", for movies. Or maybe you'd have a year node, and do something like (assume year is created already):
start movie=node:node_auto_index(name={name}), year=node:node_auto_index(year={year})
match movie-[?:made_in]->year
with count(movie) as cnt, year
where cnt = 0
create (movie {name:{name}})-[:made_in]->year;
I guess it depends on what kind of data you're trying to prevent duplicates for. The goal of those Solr ones are mainly for textual data. Or maybe you're storing text in Neo?
Wes
To unsubscribe from this group and stop receiving emails from it, send an email to neo4j+un...@googlegroups.com.

Michael Hunger
Jan 28, 2013, 2:36:38 AM1/28/13
to ne...@googlegroups.com
There is no automatic way of doing this in Neo4j.
Usually that's a concern handled in application level code.
You could for instance write a cypher statement that queries the relevant-sub-graph of the node, returns the identifying properties.
Then hash the result rows and set them as a property on your aggregate-root node for future comparison. Might even be indexed.
(Instead of hashing they could also be concatinated in a sensible way (e.g. path/to/property:value, ...)
When inserting new data you can check for that hash and if matched deep check the subgraph with a dedicated cypher query (can all be in one query).
If the data/structure is not there, create it.
Michael
Unique indexes are great to prevent duplicates being created but is there a suggested approach for identifying duplicates across the graph.E.g. with the movie graph if you don't implement unique indexes (because movies can have the same name) and two people create the same movie with the same actors is there a way to identify the duplication?Solr has MD5Signature, Lookup3Signature, TextProfileSignature algoritms for detecting duplicates but are there any examples of people using similar algorithms with Neo4j and the Lucene instance?Thanks,Rory
On Saturday, 21 January 2012 06:37:28 UTC-3, Peter Neubauer wrote:

Kenny Bastani
Aug 14, 2013, 12:49:53 PM8/14/13
to ne...@googlegroups.com
Hey all,
The following 3 steps will allow you to using the admin console and Cypher query to select and delete duplicate nodes by index and property.
START n=node:search("search:(\"TEXT MINING\")") // Cypher query for collecting the ids of indexed nodes containing duplicate properties
WITH n
ORDER BY id(n) DESC // Order by descending to delete the most recent duplicated record
WITH n.Key? as DuplicateKey, COUNT(n) as ColCount, COLLECT(id(n)) as ColNode
WITH DuplicateKey, ColCount, ColNode, HEAD(ColNode) as DuplicateId
WHERE ColCount > 1 AND (DuplicateKey is not null) AND (DuplicateId is not null)
WITH DuplicateKey, ColCount, ColNode, DuplicateId
ORDER BY DuplicateId
RETURN DuplicateKey, ColCount, DuplicateId // Toggle comment on/off for validating duplicate records before moving to next step (do not proceed to delete without validating)
//RETURN COLLECT(DuplicateId) as CommaSeparatedListOfIds
Example output - validation screenshot:
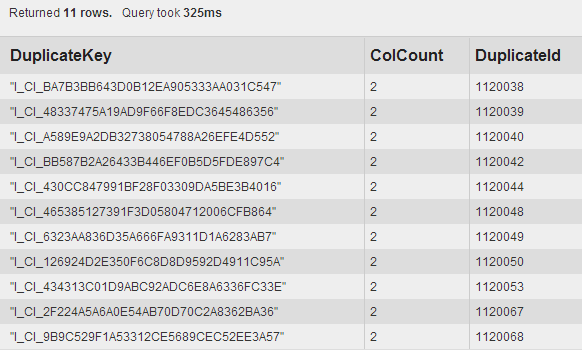
Example output - collected IDs that will be used in the next step:

STEP 2 (DELETE duplicate nodes and connected relationships by ID):
START n=node(1120038,1120039,1120040,1120042,1120044,1120048,1120049,1120050,1120053,1120067,1120068) // Replace highlighted ids with CommaSeparatedListOfIds from step 1
MATCH n-[r]-() // Delete relationships for each duplicate before deleting the node
DELETE r, n
STEP 3:
Re-run the query from the first step to make sure that the duplicate nodes were deleted
Thanks,
Kenny
Follow me on Twitter: http://www.twitter.com/kennybastani

Alx
Feb 24, 2014, 2:47:18 PM2/24/14
to ne...@googlegroups.com
Hi Kenny,
Thank you for the post. It helped me with my duplicates removal. However when I try to run Step 2 I get the following error:
Thank you for the post. It helped me with my duplicates removal. However when I try to run Step 2 I get the following error:
Invalid input 'C': expected whitespace, an unsigned integer, a parameter or '*' (line 9, column 14) "START k=node(CommaSeparatedListOfIds)"
I replaced the last sentence of Step 1 with the following:
WITH COLLECT(DuplicateId) as CommaSeparatedListOfIds
to connect to the Step 2 query.
Any ideas? Am I missing something? Thanks a lot!
Alx
Feb 24, 2014, 4:20:43 PM2/24/14
to ne...@googlegroups.com
Thanks to Wes at http://wes.skeweredrook.com/the-mythical-with-neo4js-cypher-query-language/ parsing the CommaSeparatedListOfIds above is not allowed. Instead do this:
MATCH (n)-[r]-()
WHERE id(n) IN CommaSeparatedListOfIds
DELETE r, n
Reply all
Reply to author
Forward
0 new messages