[혼공머신] k-평균 질문
28 views
Skip to first unread message

Jaeseok Lee
Apr 17, 2022, 4:59:55 AM4/17/22
to 머신러닝/딥러닝 도서 Q&A
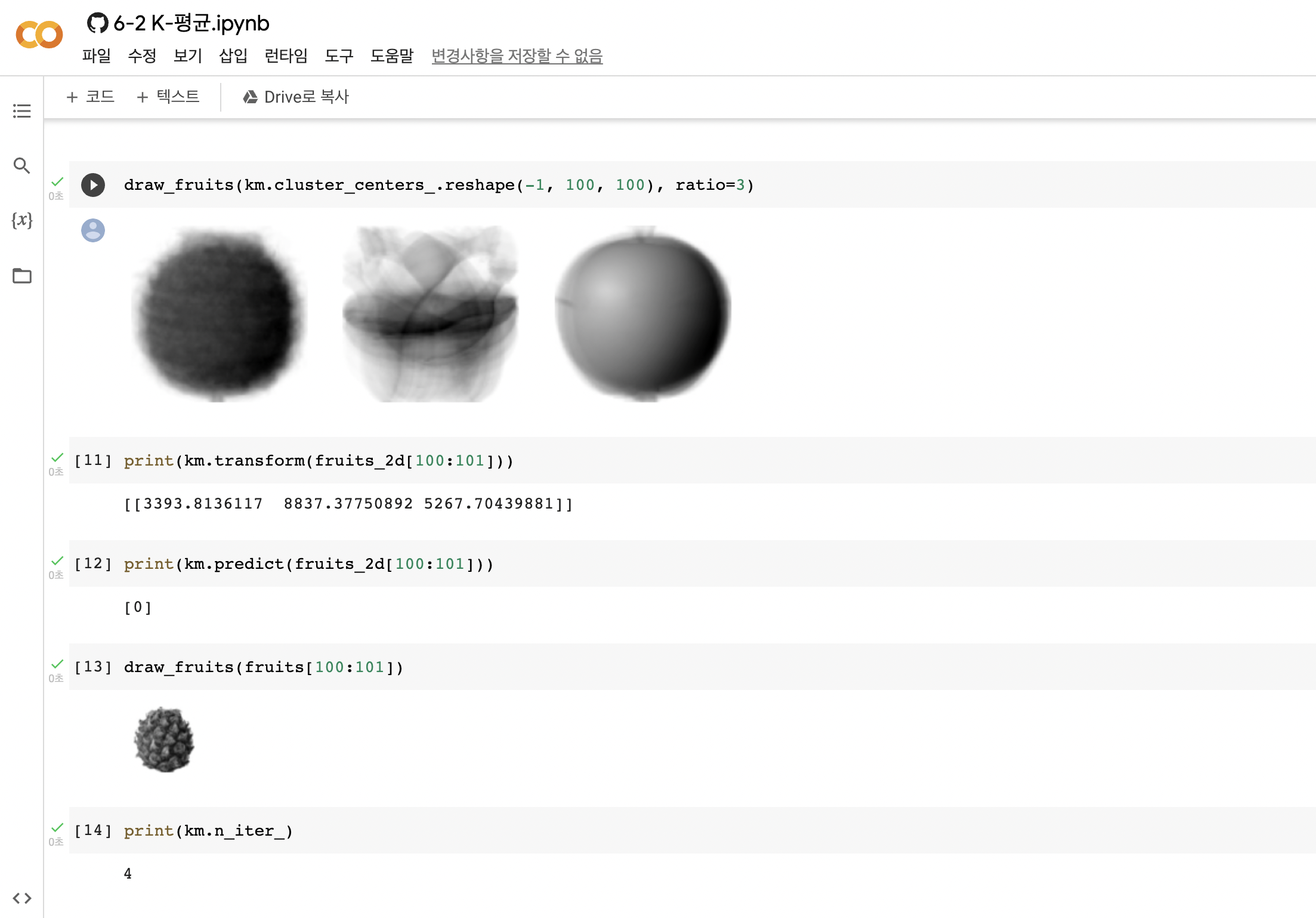
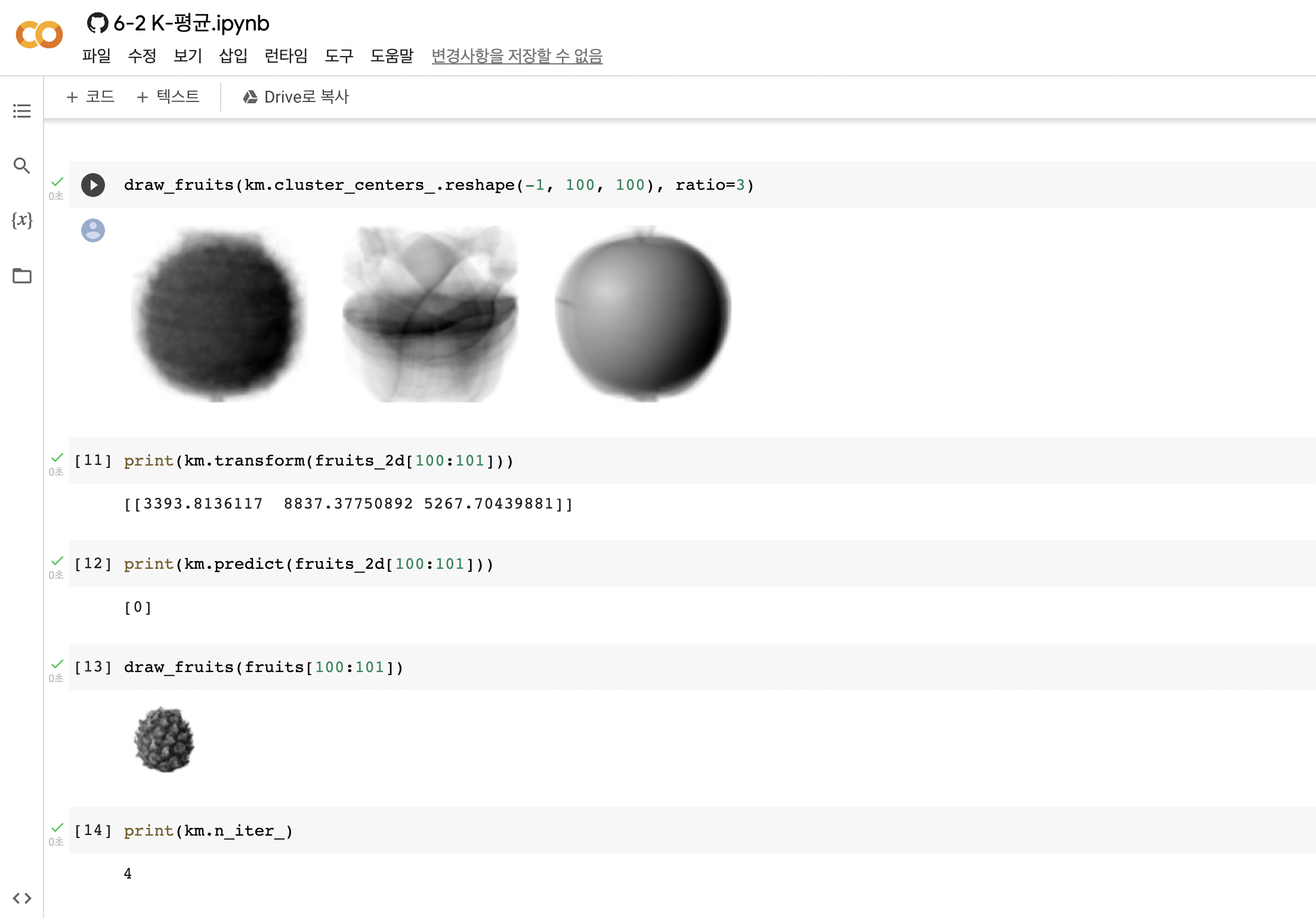
6-2절 k-평균에 쓰이는 데이터들의 레이블이 뒤집힌거 같아 여쭤봅니다.
그리고 책에 쓰여있는 n_iter값은 3이라고 나오고 그 아래 그래프에서 최적의 k=3이라는 점에서 이해가 됩니다. 하지만, 실제로 코딩을 해보니 n_inter값이 4가 나오는데 왜 그렇게 나오는건지, 또 엘보우 지점(최적의 클러스터 개수)를 더 명확하게 하기 위해서는 어떤 점을 개선해야하는 것인지 궁금합니다.

Haesun Park
Apr 17, 2022, 11:13:20 AM4/17/22
to Jaeseok Lee, 머신러닝/딥러닝 도서 Q&A
안녕하세요. 박해선입니다.
군집 알고리즘의 레이블 값 자체는 의미가 없으며 순서가 바뀌어 나올 수 있습니다.
306페이지 맨 처음 문단을 참고하세요.
라이브러리가 업데이트 됨에 따라 알고리즘의 수행 결과가 달라질 수 있습니다.
정확도나 군집 결과, 반복 횟수 등이 모두 여기에 해당됩니다.
감사합니다!
2022년 4월 17일 (일) 오후 5:59, Jaeseok Lee <jaese...@gmail.com>님이 작성:
6-2절 k-평균에 쓰이는 데이터들의 레이블이 뒤집힌거 같아 여쭤봅니다.그리고 책에 쓰여있는 n_iter값은 3이라고 나오고 그 아래 그래프에서 최적의 k=3이라는 점에서 이해가 됩니다. 하지만, 실제로 코딩을 해보니 n_inter값이 4가 나오는데 왜 그렇게 나오는건지, 또 엘보우 지점(최적의 클러스터 개수)를 더 명확하게 하기 위해서는 어떤 점을 개선해야하는 것인지 궁금합니다.
--
이 메일은 Google 그룹스 '머신러닝/딥러닝 도서 Q&A' 그룹에 가입한 분들에게 전송되는 메시지입니다.
이 그룹에서 탈퇴하고 더 이상 이메일을 받지 않으려면 ml-dl-book-qn...@googlegroups.com에 이메일을 보내세요.
웹에서 이 토론을 보려면 https://groups.google.com/d/msgid/ml-dl-book-qna/333a1dd7-5b89-40af-b6ce-71834b8a4e92n%40googlegroups.com을(를) 방문하세요.
Reply all
Reply to author
Forward
0 new messages