Questions about debrief codes in quiat9.js

Daniel Cheong
fb_slight_Att1WithCatA_Att2WithCatB : 'Your responses suggested a slight automatic preference for categoryB over categoryA.',
fb_equal_CatAvsCatB : 'Your responses suggested no automatic preference between categoryA and categoryB.',
tooFast: 'There were too many fast trials to determine a result.',
notEnough: 'There were not enough trials to determine a result.'
};

Yoav Bar-Anan
Hi Daniel,
I’ll try to answer all of your questions below:
On Wed, Nov 16, 2022 at 6:08 AM Daniel Cheong <dannyc...@gmail.com> wrote:
Hello,I have a few questions about the debrief page in this script: https://cdn.jsdelivr.net/gh/baranan/minno-tasks@0.*/IAT/qualtrics/quiat9.js1. The codes below for the debrief page only show preference for categoryB over categoryA.a. What about the preference for categoryA over categoryB? In other words, does the result always show a one-way preference?
Yoav: According to the comment in that file “categoryA is the name of the category that is found to be associated with attribute1, and categoryB is the name of the category that is found to be associated with attribute2.”
You can see in the file that by default attribute1 is “Bad words” and attribute2 is “Good words”.
That is why the feedback messages that you see below refer to a preference for categoryB (whichever category was more strongly associated with attribute2) over categoryA (whichever category was more strongly associated with attribute1). In other words, there cannot be a preference for categoryA because categoryA is defined as the one more associated with attribute1, which is, by default, “Bad words”. If you change attribute1 and attribute2, you might need to change the text (e.g., “Your responses suggested a stronger association of categoryA with attribute1 and categoryB with attribute2 than the opposite”).
b. Also, what are the ranges of difference in reaction time for the result to be computed as strong, moderate or slight preference?fb_strong_Att1WithCatA_Att2WithCatB : 'Your responses suggested a strong automatic preference for categoryB over categoryA.',fb_moderate_Att1WithCatA_Att2WithCatB : 'Your responses suggested a moderate automatic preference for categoryB over categoryA.'fb_slight_Att1WithCatA_Att2WithCatB : 'Your responses suggested a slight automatic preference for categoryB over categoryA.',fb_equal_CatAvsCatB : 'Your responses suggested no automatic preference between categoryA and categoryB.',
YBA: To find out, I searched for the text “moderate” in the code, and this is the relevant code:
var messageDef = [
{ cut:'-0.65', message : getFB(piCurrent.fb_strong_Att1WithCatA_Att2WithCatB, cat1.name, cat2.name) },
{ cut:'-0.35', message : getFB(piCurrent.fb_moderate_Att1WithCatA_Att2WithCatB, cat1.name, cat2.name) },
{ cut:'-0.15', message : getFB(piCurrent.fb_slight_Att1WithCatA_Att2WithCatB, cat1.name, cat2.name) },
{ cut:'0.15', message : getFB(piCurrent.fb_equal_CatAvsCatB, cat1.name, cat2.name) },
{ cut:'0.35', message : getFB(piCurrent.fb_slight_Att1WithCatA_Att2WithCatB, cat2.name, cat1.name) },
{ cut:'0.65', message : getFB(piCurrent.fb_moderate_Att1WithCatA_Att2WithCatB, cat2.name, cat1.name) },
{ cut:'5', message : getFB(piCurrent.fb_strong_Att1WithCatA_Att2WithCatB, cat2.name, cat1.name) }
This refers to the D score computed by the extension. So, above 0.65 is strong, between .35 and .65 is moderate, and so on.
This would be a good place to paste one of the comments in the extension about the debriefing:
We do not recommend showing participants their results. The IAT is a typical psychological measure so it is not very accurate.
In Project Implicit's website, you can see that we added much text to explain that there is still much unknown about the meaning of these results.
We strongly recommend that you provide all these details in the debriefing of the experiment.It would also be a good time to mention that we do not recommend using the IAT D score provided by the program in data analysis. We strongly recommend computing the IAT D score on your own.2. What is the basis for the error messages below?
a. How many errors will result in the manyErrors message?
b. What is the RT that is considered to be too fast?
c. How many trials should be considered to be enough to determine a result?//Error messages in the feedbackmanyErrors: 'There were too many errors made to determine a result.',
tooFast: 'There were too many fast trials to determine a result.',
notEnough: 'There were not enough trials to determine a result.'
};
Daniel Cheong
Daniel Cheong
Yoav Bar-Anan
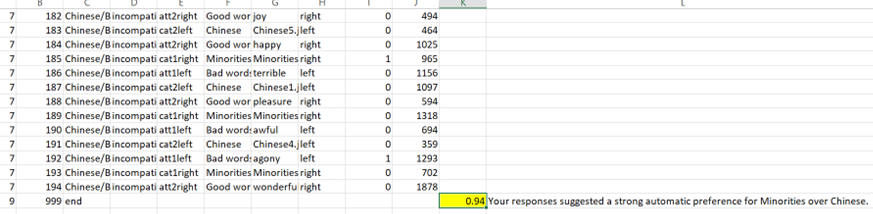
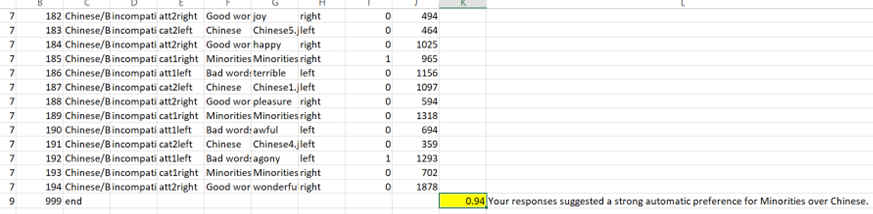
Hi Yoav,Thank you for your help previously! I managed to run my custom IAT on Qualtrics. I have a couple of questions about the results:- How is the d score computed (0.94s in the example below) in the dataset that I downloaded and formatted from Qualtrics?
- Is it possible to change the codes in the script to compute specific blocks that we want? For example, omitting or including blocks 3 and 6 in the computation of the d score. If so, which part of the script can I find it?