An exhaustive generator for the mmsolitaire project
154 views
Skip to first unread message

Samiro Discher
Feb 23, 2023, 12:53:45 AM2/23/23
to Metamath
I have just published the code of my pmGenerator tool and released a first version.
It is performance-oriented, implemented in C++, and using Intel's oneTBB for multithread-capable data structures.
The tool uses a command-line interface with different commands capable to parse and generate variants of
pmproofs.txt.
It is meant to generate sets of condensed detachment proofs (called "D-proofs"
from now on) for all attainable conclusions of D-proofs up to a certain length, and then
to generate an improved version of that database of
shortest
known D-proofs (whose theorems originate from Principia Mathematica).
As I have previously explained in another thread, there are files dProof<n>.txt generated for sets that have filtered out proofs of conclusions for which there are more general variants proven in lower or equal amounts of steps, and
dProof<n>-unfiltered<m>+.txt for collections where this kind of filtering was disabled for proofs of length m and higher (which to generate are much more time efficient but less space
efficient).
The project's README contains a table with links to some of these data files that were already generated.
If you've got a really strong computer (preferably with a lot of RAM), you might be able to generate the next higher sets based on the current files and possibly find some new shortest known proofs. Subproofs of lengths up to 33 have been searched exhaustively, as indicated by the currently greatest linked file dProofs33-unfiltered31+.txt, which alone has a size of 8349023875 bytes, containing 45774890 pairs of D-proofs (each of length 33) with their conclusions.
Some changes since I posted in the other thread:
- Data files can now contain conclusions, so the D-proofs do not have to be reparsed while loading (which took a rather long time for the bigger files).
- Conclusions are no longer stored as tree structures, but (just like in files) as strings in a prefix notation, where variables are numbered 0, 1, 2,... by order off occurence, consecutive variabes are separated by '.', and operators are given according to Łukasiewicz-style Polish notation. For example the formula ( -. ph -> ph ) would be represented by CN0.0.
Operating on mere strings improved space efficiency of the tool to essentially what is optimally possible. Fortunately, there are very fast methods (such as abstraction checks) to operate on formulas in prefix notation, such that this did not introduce any penalty on performance at all (but in the contrary since memory is slow).
Note that, however, the D-proof parser still uses tree structures for performance reasons (since a substitution to multiple variables
–
which are links to the same node
–
then is just a single node assignment).
Notably, only shared memory parallelism is supported. After I fiddled around with MPI to make it usable on supercomputers, I noticed that this problem isn't, in a way, "friendly" for distributed memory parallelism:
- Using shared memory, we're already in a realm where hundreds of GiBs of RAM are required to generate the next greater D-proof collection (dProof35) without page faults.
- Modern supercomputers have many nodes, but not every such node has huge amounts of memory, so
loading the full collections on every node is not an option.
- When using
distributed memory to circumvent the memory problem, i.e. distributing the database across all nodes, an insertion of a single D-proof would require the proof (and its conclusion) to be sent in a (worstcase: full) loop across utilized nodes.
Due to the already billions
(+ exponentially
growing)
of tests, this would
overuse the network and thereby probably be terribly slow. (I might be lacking a good idea here, though.)
There is also an
exemplary
command to extract some plot data from the collections.
I noticed, for example, that most conclusions of short proofs have odd symbolic lengths (which are the amounts of nodes in their syntax trees):
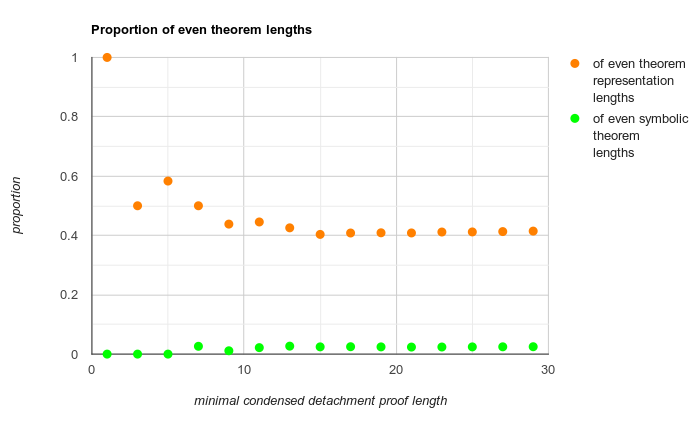
And here is some actual plot data concerning symbolic theorem lengths visualized..
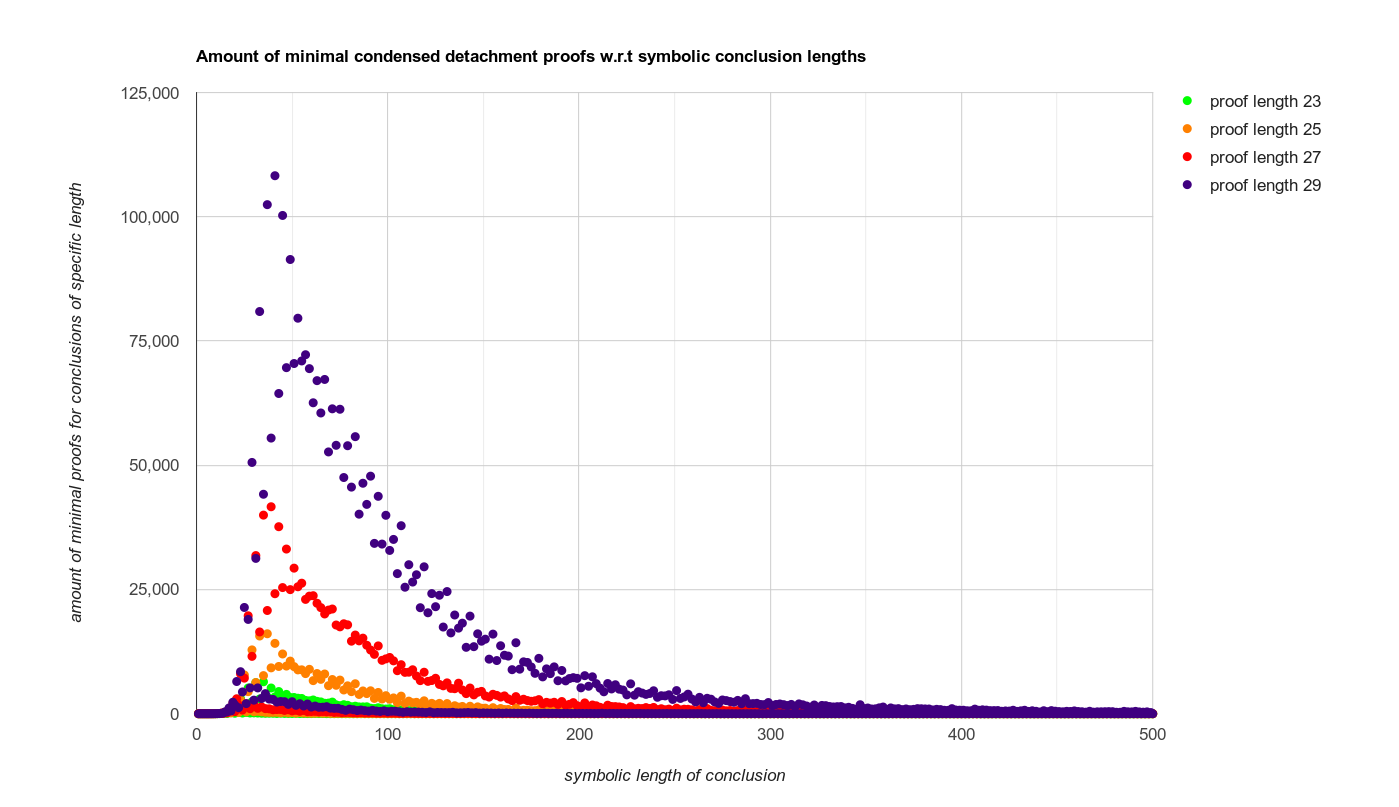
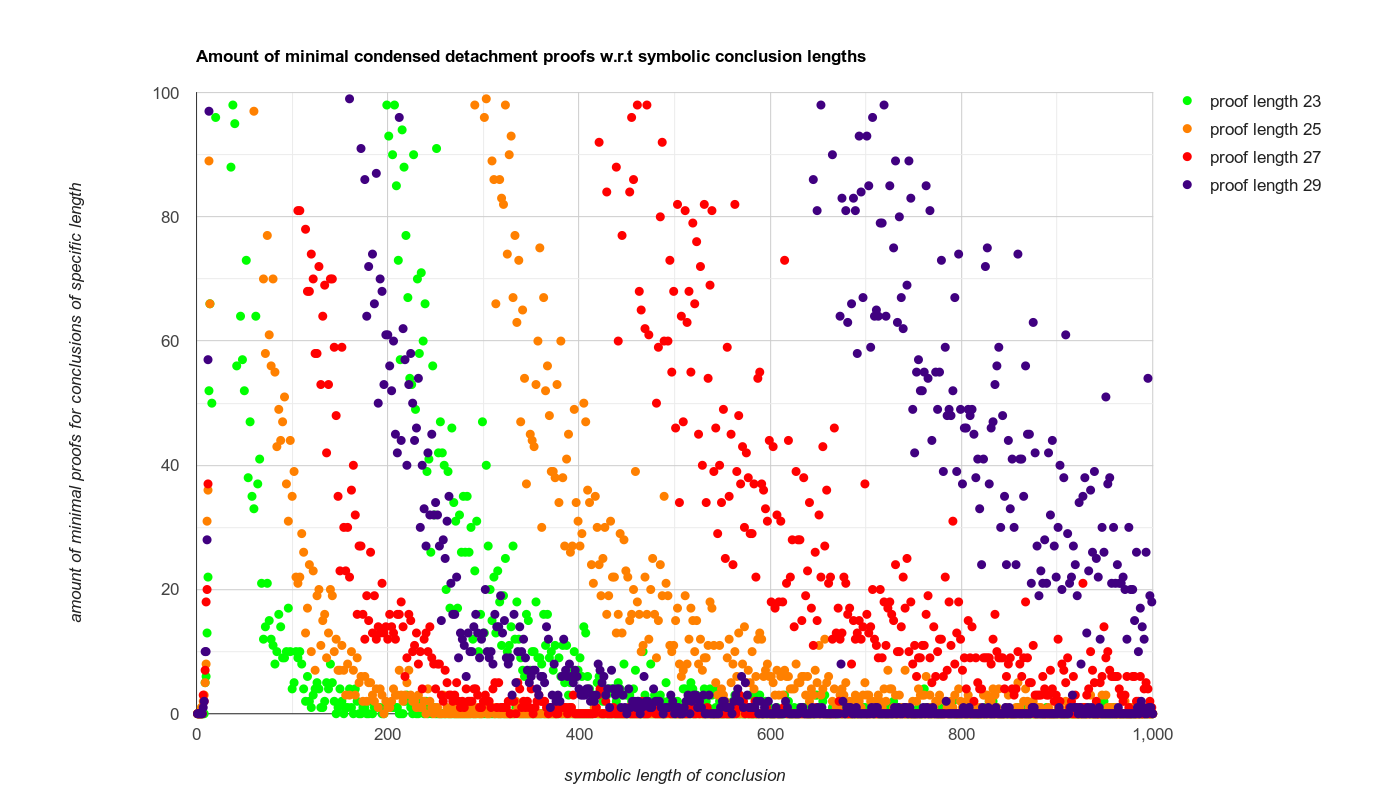
.. which can be "zoomed in" by only showing data within certain bounds:
I hope some will find this tool useful or at least nice to play around with.
As far as I know, it is the first program capable of composing pmproofs.txt, and the fastest one to parse it.
If you have any questions, please do not hesitate to ask.
— Samiro Discher
Samiro Discher
Feb 24, 2023, 6:38:01 PM2/24/23
to Metamath
Small update:
I fixed an issue where
the output wasn't shown on a Windows Command Prompt (CMD), by using different linker flags. CMD still isn't capable to print UTF-8 encoded special caracters, and I won't fix that, but there are better alternatives to CMD (as mentioned in the release notes).
The new binaries are now published as a new minor release.
Some more changes:
- Update to most recent
dependencies
(Boost 1.81.0 and oneTBB 2021.8.0-1)
- Avoid huge string acquisition during generator file conversion (in hopes to avoid a bug on
Windows
where sometimes huge files were written incompletely)
- Update README
In case you are looking for the heart of the proof collection generator (which also contains exemplary measurements in the comments), here you go.
And here is the schema check over formula strings, look for "polishnotation" (case-insensitive) to find more optimized formula handling.
PS: In my last post, instead of
> since a substitution to multiple variables – which are links to the same node – then is just a single node assignment
I meant to say:
> since a substitution to multiple occurences of the same variable – which are links to the same node – then is just a single node assignment
> since a substitution to multiple occurences of the same variable – which are links to the same node – then is just a single node assignment
I forgot to mention initially that I
very much
appreciate if you can bring any bugs or issues to my attention. :-)
— Samiro Discher
Samiro Discher
May 6, 2023, 7:53:34 PM5/6/23
to Metamath
I released a new version of pmGenerator which is capable of distributed computing via MPI for filtering generated proof sets. As previously announced.
You can find some information on that in the readme.
This completes all core features of the tool. If you find any bugs, please submit an issue.
You can find some information on that in the readme.
This completes all core features of the tool. If you find any bugs, please submit an issue.
Reply all
Reply to author
Forward
0 new messages