UKWA pywb working okay with Memento gateways?
110 views
Skip to first unread message

Andy J
Nov 20, 2018, 11:47:17 AM11/20/18
to Memento Development
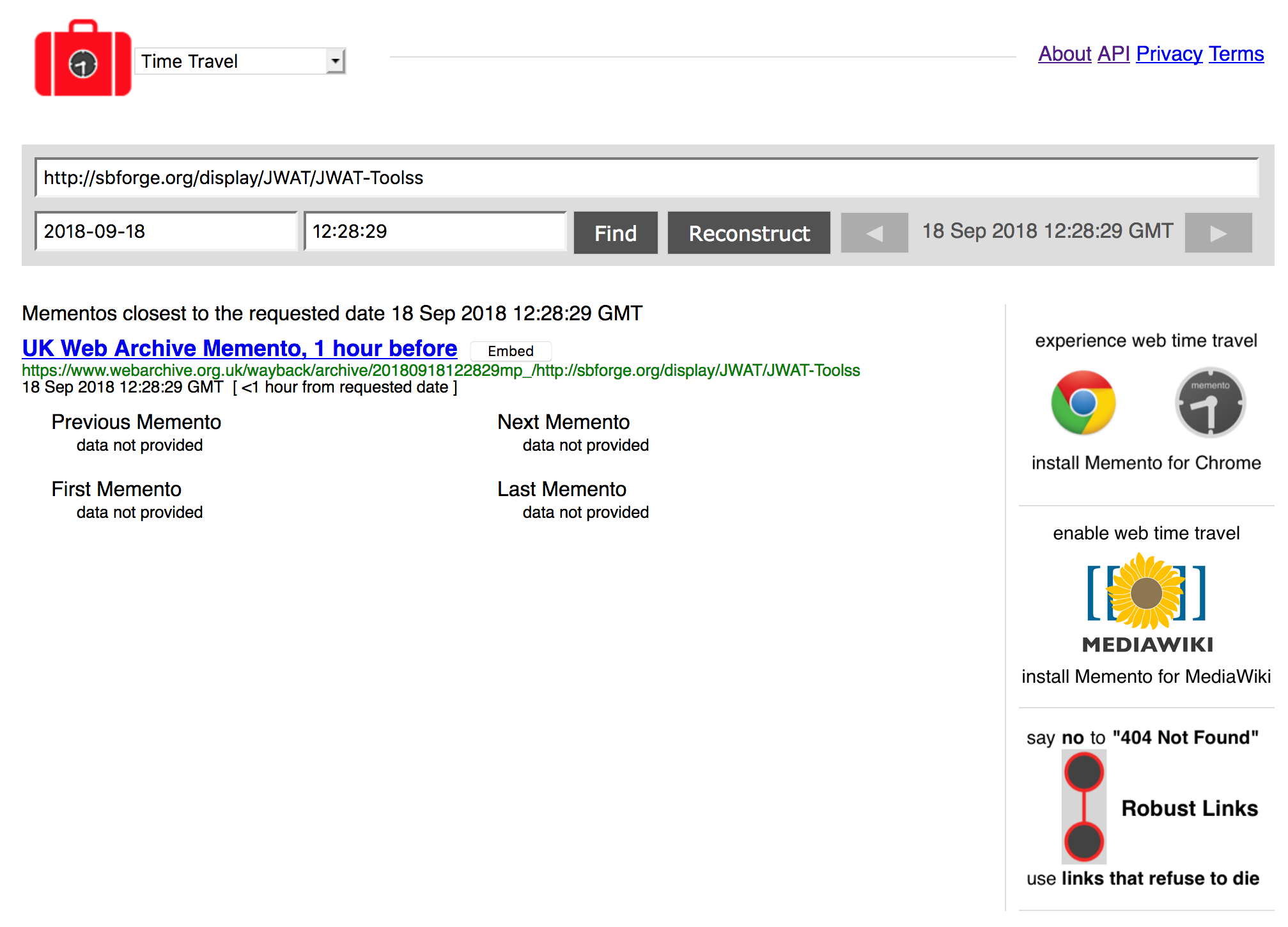
Since switching our playback service to pywb, we've noticed occasional issues on http://timetravel.mementoweb.org where things not held in our collection get reported as being present. An example is reported with screenshots here: https://github.com/ukwa/w3act/issues/597
Upon reloading the query, the link to UKWA disappears. http://timetravel.mementoweb.org/list/20131006095304/https://www.irishtimes.com/business/technology/net-results-lax-archival-law-allows-digital-black-hole-1.2644166
Is there a problem with our Memento implementation that is confusing aggregators?
Thanks,
Andy

Sawood Alam
Nov 20, 2018, 12:00:25 PM11/20/18
to memen...@googlegroups.com
I don't see this happening in MemGator, which does not utilize caching or predictions yet. So, I think it is less likely something to do with potential problematic Memento implementation in PyWB. Could it be a possibility that LANL's aggregator is yielding some false positives or the resource might have been available before that was cached?
Best,
--
Sawood Alam
Department of Computer Science
Old Dominion University
Norfolk VA 23529
--
---
You received this message because you are subscribed to the Google Groups "Memento Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to memento-dev...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Martin Klein
Nov 20, 2018, 2:53:15 PM11/20/18
to memen...@googlegroups.com
Hi Andy,
I believe I can explain what is happening. We have a cache system in place that holds timemap information of requested URIs. Each request against the TT service will be served from cache, if a) the URI is indeed cached (cache hit) and b) the cached info is fresh and not stale. Currently, our cache considers data for a URI fresh for 30 days and after that considers the data for that URI as stale and treats requests for that URI as a cache miss.
A request sent with the "Cache-Control" header and the value "no-cache" will bypass the cache. Practically, this is the same behavior as hitting "shift reload" in your browser.
I assume this is what happened:
- The first request returned results from cache, including the UKWA Memento that was no longer available.
- There is/was only one Memento of this URI-R in the UKWA and hence no links to the previous, next, first, and last Memento were included
- Your following request was sent as "no-cache" via "shift reload" and hence bypassed the cache and returned updated information delivered via the Memento aggregator (without any machine learning process)
- This
updated information was written into the cache and hence consecutive
requests are served from cache (for the next 30 days)
FYI #1
In case of a cache miss, our machine learning process kicks in and provides results from archives that were predicted to have Mementos for the requested URI-R. As a secondary (but more or less immediate) process, the timemap info for the requested URI is gathered and once done, written into the cache. The cache now holds the up-to-date information about the URI, which may differ from what the machine learning predicted.
In case of a cache miss, our machine learning process kicks in and provides results from archives that were predicted to have Mementos for the requested URI-R. As a secondary (but more or less immediate) process, the timemap info for the requested URI is gathered and once done, written into the cache. The cache now holds the up-to-date information about the URI, which may differ from what the machine learning predicted.
FYI #2
A
request sent with the "Cache-Control" header and the value
"only-if-cached" will only get a response from cache, so only if the URI
is cached (and not stale), and will return a 504 response code
otherwise and hence not involve the machine learning process.
I hope this helps!
cheers
M

Michael Nelson
Nov 20, 2018, 2:58:15 PM11/20/18
to memen...@googlegroups.com
Hi Andy,
I like this explanation better:
timetravel.mementoweb.org is telling you what your archive *should* have.
please update your holdings accordingly.
;-)
Michael
Michael L. Nelson m...@cs.odu.edu http://www.cs.odu.edu/~mln/
Dept of Computer Science, Old Dominion University, Norfolk VA 23529
+1 757 683 6393 +1 757 683 4900 (f)
Andy J
Nov 21, 2018, 5:53:35 AM11/21/18
to Memento Development
TBH, I think this false-positive behaviour leads to a poor user experience, and due to the way the user flow works, will tend to lead to users 'blaming' the archives unfairly (as happened [here](https://github.com/ukwa/w3act/issues/597)). I imagine you are recording the false-positive rate, so you should be able to find out how often this happens and whether if affects some archives more than others?
One option would be clearer visual signalling. Speculative results are not formatted any differently to confirmed results, which means this significant change in behaviour of the timetravel service is not being indicated to users.
An second option would be for us to start sharing Bloom filters that summarise our holdings so the false-positive rate can be controlled more effectively. See https://github.com/ukwa/ukwa-manage/issues/41
Best,
Andy Jackson

Herbert Van de Sompel
Nov 21, 2018, 7:12:20 AM11/21/18
to memen...@googlegroups.com, Herbert Van de Sompel
On Wed, Nov 21, 2018 at 11:53 AM Andy J <anja...@gmail.com> wrote:
TBH, I think this false-positive behaviour leads to a poor user experience,
As you know, the false-positives (and false-negatives) are a consequence of a query routing approach that uses a binary classifiers trained per archive. Each classifiers is trained on the basis of the TimeTravel service cache. The approach was introduced to avoid an even worse user experience, i.e. having the user wait in real time until 20+ web archives have responded to a Memento request. Thanks to the classifiers, the response times remain within a range that users are willing to cope with because (way) less than 20+ archives are effectively polled in real-time.
Having said that, I agree that especially false-positives can be frustrating for both the user and the archive that the user was redirected to. A few ideas:
- I like your suggestion of distinguishing speculative results (both false-positive and false-negative?) in search results.
- Since false-positives seem more frustrating than false-negatives, classifiers could be trained to reduce the percentage of false-positives. One would need to see how that affects the reduction in the number of archives that are being queried.
- In order to achieve "correct" results, some information that appropriately summarizes each archive would have to be accessible to the timetravel service (and other aggregators). Bloom filters would indeed be a way to go and we actually briefly looked into such an approach when working on the machine learning solution. The issue with this approach is obviously that web archives would need to devise/maintain additional infrastructure. Maybe those that get really concerned about the false-positives would be willing to go there. The timetravel service could obviously deal with a hybrid situation, i.e. leveraging classifiers based on the cache for some archives and using summaries for others.
I frankly agree with Andy that this topic deserves some discussion.
Cheers
Herbert
Sawood Alam
Nov 21, 2018, 11:41:02 AM11/21/18
to memen...@googlegroups.com
This is a problem space I am working on as my PhD thesis. The IIPC-funded Archive Profiling work we did at ODU in collaboration with LANL has an aspect of profile dissemination for which we proposed a few approaches in our final report.
Currently I am working on a document to streamline a way to advertise archival holdings which will serve a similar purpose that Bloom filters can, but in a more expressive way. I am planning to publish the document for comments on GitHub this week and a more detailed report will be published as a tech report while I am also working on a JCDL submission.
--
Sawood Alam
Department of Computer Science
Old Dominion University
Norfolk VA 23529
Sawood Alam
Nov 27, 2018, 10:58:45 PM11/27/18
to memen...@googlegroups.com
Hi all,
I have published an in-progress draft of a generic unified key-value store format and described how it can be used in a number of web archiving related applications. I have included a handful of examples to illustrate variations of Archive Profiles (calling it MementoMap). Other use cases are yet to be described. Please feel free to create issue tickets in the repo to provide feedback and discuss any changes.
Best,
--
Sawood Alam
Department of Computer Science
Old Dominion University
Norfolk VA 23529

Nick Ruest
Jan 15, 2019, 6:36:11 AM1/15/19
to memen...@googlegroups.com
Hi all,
I'm getting hit with the false Mementos now in Warclight.
I have a helper method that queries the Time Travel API, and it is now
returning false positives causing tests to fail[1]. The test has started
failing because I'm getting a result back from the Time Travel API that
I never got before. It was for a URL that never existed, so cannot have
been captured. So, it would have never been indexed. But, the Time
Travel API is returning two results[2]. If you curl those two results,
you'll run into the issue Andy originally raised, the UKWA's PyWb
instance returns a 404[3].
The test is failing multiple times in the test run, for restarts of the
test run, and locally run tests. There are also multiple Mementos of the
URI-R.
As for poor user experience, I completely agree with Andy here. I
initially did blame UKWA, and contacted Andy about the issue. He
reminded me of this thread. So, what can be done to correct this
behaviour if it is cascading out to other applications?
-nruest
[1] https://travis-ci.org/archivesunleashed/warclight/jobs/479548445#L1975
[2]
https://gist.github.com/ruebot/875c04391fbff333cd7c61ef30c66a17#file-time-travel-api-false-positives
[3]
https://gist.github.com/ruebot/875c04391fbff333cd7c61ef30c66a17#file-ukwa-pywb-queries
> <mailto:memento-dev...@googlegroups.com>.
I'm getting hit with the false Mementos now in Warclight.
I have a helper method that queries the Time Travel API, and it is now
returning false positives causing tests to fail[1]. The test has started
failing because I'm getting a result back from the Time Travel API that
I never got before. It was for a URL that never existed, so cannot have
been captured. So, it would have never been indexed. But, the Time
Travel API is returning two results[2]. If you curl those two results,
you'll run into the issue Andy originally raised, the UKWA's PyWb
instance returns a 404[3].
The test is failing multiple times in the test run, for restarts of the
test run, and locally run tests. There are also multiple Mementos of the
URI-R.
As for poor user experience, I completely agree with Andy here. I
initially did blame UKWA, and contacted Andy about the issue. He
reminded me of this thread. So, what can be done to correct this
behaviour if it is cascading out to other applications?
-nruest
[1] https://travis-ci.org/archivesunleashed/warclight/jobs/479548445#L1975
[2]
https://gist.github.com/ruebot/875c04391fbff333cd7c61ef30c66a17#file-time-travel-api-false-positives
[3]
https://gist.github.com/ruebot/875c04391fbff333cd7c61ef30c66a17#file-ukwa-pywb-queries
> Screen Shot 2018-11-21 at 10.44.48.png
>
>
>
> An second option would be for us to start sharing Bloom filters that
> summarise our holdings so the false-positive rate can be controlled
> more effectively. See https://github.com/ukwa/ukwa-manage/issues/41
>
> Best,
> Andy Jackson
>
> On Wednesday, 21 November 2018 06:58:15 UTC+11, Michael Nelson wrote:
>
>
> Hi Andy,
>
> I like this explanation better:
>
> timetravel.mementoweb.org <http://timetravel.mementoweb.org> is
>
>
>
> An second option would be for us to start sharing Bloom filters that
> summarise our holdings so the false-positive rate can be controlled
> more effectively. See https://github.com/ukwa/ukwa-manage/issues/41
>
> Best,
> Andy Jackson
>
> On Wednesday, 21 November 2018 06:58:15 UTC+11, Michael Nelson wrote:
>
>
> Hi Andy,
>
> I like this explanation better:
>
> For more options, visit https://groups.google.com/d/optout.
>
>
>
> --
> Herbert Van de Sompel
> https://hvdsomp.info/
> https://orcid.org/0000-0002-0715-6126
> ==
>
>
>
>
> --
> Herbert Van de Sompel
> https://hvdsomp.info/
> https://orcid.org/0000-0002-0715-6126
> ==
>
> --
>
> ---
> You received this message because you are subscribed to the Google
> Groups "Memento Development" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to memento-dev...@googlegroups.com
> <mailto:memento-dev...@googlegroups.com>.
>
> ---
> You received this message because you are subscribed to the Google
> Groups "Memento Development" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to memento-dev...@googlegroups.com
Herbert Van de Sompel
Jan 15, 2019, 6:45:23 AM1/15/19
to memen...@googlegroups.com, Herbert Van de Sompel
hi Nick,
I think it was explained why this behavior occurs, i.e. to minimize the waiting time for interactive (portal) users, classifiers trained per web archive decide whether or not it is worthwhile to check a certain URL for Mementos. The use of classifiers results in false positives and false negatives. Clearly, you are getting false positives.
As I indicated in a previous mail, an option could be to train the classifiers to minimize false positives because those seem to be the most frustrating.
Another idea would be to introduce the ability to use the TimeTravel API with or without the classifiers. Obviously, use without would result in longer response times (all archives would be checked) but maybe that's not an issue for machine use.
Anyhow, just my 2 cents. I trust the LANL Team will have more ideas.
Cheers
Herbert
==================
Herbert Van de Sompel
Chief Innovation Officer
DANS
+31 6 22 83 93 15
Sawood Alam
Jan 15, 2019, 7:44:43 AM1/15/19
to memento-dev, Herbert Van de Sompel
Nick,
If you can afford to avoid optimizations LANL has done to greatly improve the response time and willing to run your own aggregator instance with Warclight then you can give MemGator [1] a try, which currently does not return any false positives or false negatives. For the most part it will be a drop in replacement as far as the API is concerned while you can also customize sources to aggregate from.
Alternatively, if LANL's aggregator service can introduce a way to bypass classifier and caches, perhaps by using some request headers then it would be great for machine usage.
Best,
--
Sawood Alam
Department of Computer Science
Old Dominion University
Norfolk VA 23529
Martin Klein
Jan 15, 2019, 6:19:21 PM1/15/19
to memen...@googlegroups.com
Hi Nick,
We are investigating the issue and I have pinged Andy with our initial findings. I will report back as soon as I know. It might be as simple as our TimeTravel service pinging a dated TimeGate URI of the UKWA.I hope this makes sense and I can report back soon with more info.
Andy J
Jan 16, 2019, 10:29:36 AM1/16/19
to Memento Development
Thanks all - this looks like a bug in our pywb setup! https://github.com/ukwa/ukwa-pywb/issues/37
Andy
> <mailto:memento-dev+unsub...@googlegroups.com>.
> For more options, visit https://groups.google.com/d/optout.
>
>
>
> --
> Herbert Van de Sompel
> https://hvdsomp.info/
> https://orcid.org/0000-0002-0715-6126
> ==
>
> --
>
> ---
> You received this message because you are subscribed to the Google
> Groups "Memento Development" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to memento-dev...@googlegroups.com
> <mailto:memento-dev+unsub...@googlegroups.com>.
Andy J
Feb 15, 2019, 4:25:50 PM2/15/19
to Memento Development
Thanks helping us resolve this. We've just rolled out a new UKWA pywb release which we believe resolves this issue.
Best,
Andy Jackson
Reply all
Reply to author
Forward
0 new messages