lmfit not fitting an inverse (negative amplitude) Lorentzian Cauchy Distribution in a Complex Model
373 views
Skip to first unread message

Alexandros Gloor
Aug 14, 2020, 11:35:59 AM8/14/20
to lmfit-py
Reposting as per Mark's request and including some keywords to make this easier to find for others in the future.
Dear all,
As I mentioned previously, I am trying to fit optical transmission through a material to find its optical resonant frequency. As can be seen in the data file linked below, the light has a transmittance through the material equal to 1 (100%) for most wavelengths in the parametric sweep, except for a particular range of frequencies, where the light resonates with the thickness and refractive index of the material and transmittance drops to near 0. This relationship looks like an inverse Lorentzian (or Cauchy for mathematicians) distribution, with an amplitude of -1 added onto a constant model with constant c equal to 1.
When the code posted is ran, the following report is created:
[[Model]]
(Model(constant, prefix='c_') + Model(lorentzian, prefix='l_'))
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 3
# data points = 51
# variables = 2
chi-square = 2.50914788
reduced chi-square = 0.05120710
Akaike info crit = -149.606004
Bayesian info crit = -145.742353
## Warning: uncertainties could not be estimated:
l_center: at initial value
l_sigma: at initial value
[[Variables]]
c_c: 1 (fixed)
l_amplitude: -1 (fixed)
l_center: 5.9000e+14 (init = 5.9e+14)
l_sigma: 1.00000000 (init = 1)
l_fwhm: 2.00000000 == '2.0000000*l_sigma'
l_height: -0.31830990 == '0.3183099*l_amplitude/max(2.220446049250313e-16, l_sigma)'Some values are purposefully fitted to make the fit as closely related to the theoretical ideal as possible. The most important parameter to have the library fit is l_center, the resonant frequency of the negative Lorentzian distribution, as it is desired to test the coupling strength of a cavity using said material. As you can see from the code, lmfit is just inserting the initial values, 5.9e14, instead of fitting it to the raw data provided and lmfit reports:## Warning: uncertainties could not be estimated:
That being said, the program itself does not return an error, just the library.
Please let me know if there is something I am missing here as the documentation does not offer any specific examples relevant to complex models that use inverse (negative) models.
Best,
Best,
Alexandros

Mark Dean
Aug 14, 2020, 11:59:54 AM8/14/20
to lmfi...@googlegroups.com
Dear Alexandros,
The issue is that the `l_amplitude` and `l_height` parameters have been misinterpreted.
Amplitude is the integrated area of the Lorentzian. Since x is in very large units this value is very approximately ~0.1e14 (sigma) * 1 (height).
You want to initialize all parameters to be in the correct ballpark with this in mind and then fix the height and float the amplitude.
Actually, better still is to work in units where parameters are in the vague vicinity of unity. In this case, x can be in units of Thz.
Best,
Mark
--
You received this message because you are subscribed to the Google Groups "lmfit-py" group.
To unsubscribe from this group and stop receiving emails from it, send an email to lmfit-py+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/lmfit-py/b3692d48-f0b9-4782-879e-24351d746991o%40googlegroups.com.
--------------------------------------------
Mark P. M. Dean
Brookhaven National Laboratory
Condensed Matter Physics Bldg 734
Upton NY 11973
USA
Phone: 001 631 344 7847
Email: md...@bnl.gov

Evan Groopman
Aug 14, 2020, 12:17:52 PM8/14/20
to lmfi...@googlegroups.com
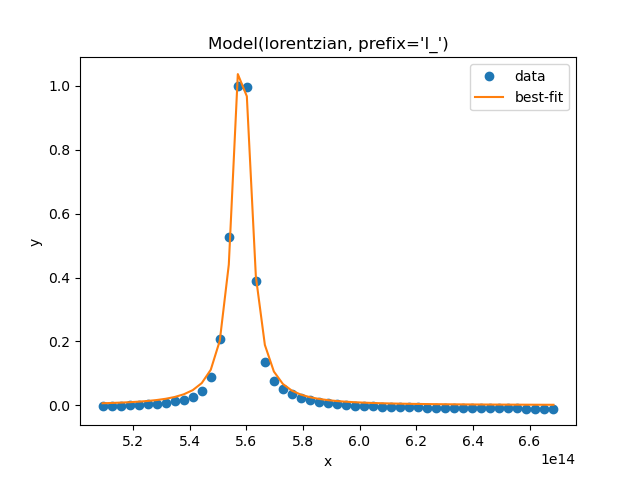
Along the lines of what Mark said, here's the simplified code and output if you rescale your x-variable:
matResF = 0 #[]
kParTemp = pd.DataFrame(matKParDict[0]).reset_index(drop=True) # temporary DF of our dictionary section
x= kParTemp['freq'].values/1E14
y= 1 - kParTemp['power'].values #you can just subtract the lorentzian from 1 for simplicity
lor = LorentzianModel(prefix='l_')
pars = lor.make_params()
pars['l_amplitude'].set(value=1)
pars['l_center'].set(value=5.6, min=5.2, max=6.6)
pars['l_sigma'].set(value=1)
model = lor
out = model.fit(y, pars, x=x)
print(out.fit_report())
out.plot_fit()
kParTemp = pd.DataFrame(matKParDict[0]).reset_index(drop=True) # temporary DF of our dictionary section
x= kParTemp['freq'].values/1E14
y= 1 - kParTemp['power'].values #you can just subtract the lorentzian from 1 for simplicity
lor = LorentzianModel(prefix='l_')
pars = lor.make_params()
pars['l_amplitude'].set(value=1)
pars['l_center'].set(value=5.6, min=5.2, max=6.6)
pars['l_sigma'].set(value=1)
model = lor
out = model.fit(y, pars, x=x)
print(out.fit_report())
out.plot_fit()
#fit report
[[Model]]
Model(lorentzian, prefix='l_')
Model(lorentzian, prefix='l_')
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 73
# data points = 51
# variables = 3
chi-square = 0.02081619
reduced chi-square = 4.3367e-04
Akaike info crit = -391.996354
Bayesian info crit = -386.200877
[[Variables]]
l_amplitude: 0.13272298 +/- 0.00253889 (1.91%) (init = 1)
l_center: 5.58473656 +/- 5.9247e-04 (0.01%) (init = 5.6)
l_sigma: 0.03484858 +/- 0.00106594 (3.06%) (init = 1)
l_fwhm: 0.06969715 +/- 0.00213188 (3.06%) == '2.0000000*l_sigma'
l_height: 1.21230315 +/- 0.02585478 (2.13%) == '0.3183099*l_amplitude/max(2.220446049250313e-16, l_sigma)'
[[Correlations]] (unreported correlations are < 0.100)
C(l_amplitude, l_sigma) = 0.724
chi-square = 0.02081619
reduced chi-square = 4.3367e-04
Akaike info crit = -391.996354
Bayesian info crit = -386.200877
[[Variables]]
l_amplitude: 0.13272298 +/- 0.00253889 (1.91%) (init = 1)
l_center: 5.58473656 +/- 5.9247e-04 (0.01%) (init = 5.6)
l_sigma: 0.03484858 +/- 0.00106594 (3.06%) (init = 1)
l_fwhm: 0.06969715 +/- 0.00213188 (3.06%) == '2.0000000*l_sigma'
l_height: 1.21230315 +/- 0.02585478 (2.13%) == '0.3183099*l_amplitude/max(2.220446049250313e-16, l_sigma)'
[[Correlations]] (unreported correlations are < 0.100)
C(l_amplitude, l_sigma) = 0.724
To view this discussion on the web visit https://groups.google.com/d/msgid/lmfit-py/CABMFFfqOJvRhLjehL0Q8u2dte7ikapP0uLFhjyeH%2BfccBeBWNQ%40mail.gmail.com.
{kind=link}
Alexandros Gloor
Aug 14, 2020, 12:21:53 PM8/14/20
to lmfi...@googlegroups.com
Oh, fascinating!
Thank you both. I tried to do y = 1 - 'power' before, but ran into a problem I am now realizing was not due to this function.
Does lmfit prefer both x and y to be in similar units of magnitude then or did I misunderstand that second point?
Cheers,
To view this discussion on the web visit https://groups.google.com/d/msgid/lmfit-py/CAJKCVKb%2BG41%2Bfuw0nBZZUsY_G7yvvs0Kkjj4Ae_JCwYXYgDxdA%40mail.gmail.com.
Evan Groopman
Aug 14, 2020, 12:34:02 PM8/14/20
to lmfi...@googlegroups.com
A bit of a misunderstanding. Here's the code without rescaling x:
kParTemp = pd.DataFrame(matKParDict[0]).reset_index(drop=True) # temporary DF of our dictionary section
x= kParTemp['freq'].values
x= kParTemp['freq'].values
y= 1 - kParTemp['power'].values
lor = LorentzianModel(prefix='l_')
pars = lor.make_params()
pars = lor.make_params()
pars['l_amplitude'].set(value=1E14)
pars['l_center'].set(value=5.6E14, min=5.2E14, max=6.6E14)
pars['l_sigma'].set(value=0.1E14)
pars['l_center'].set(value=5.6E14, min=5.2E14, max=6.6E14)
pars['l_sigma'].set(value=0.1E14)
model = lor
out = model.fit(y, pars, x=x)
print(out.fit_report())
[[Model]]
Model(lorentzian, prefix='l_')
[[Fit Statistics]]
# fitting method = leastsq
Model(lorentzian, prefix='l_')
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 45
# data points = 51
# variables = 3
chi-square = 0.02081619
reduced chi-square = 4.3367e-04
Akaike info crit = -391.996354
Bayesian info crit = -386.200877
[[Variables]]
l_amplitude: 1.3272e+13 +/- 2.5389e+11 (1.91%) (init = 1e+14)
l_center: 5.5847e+14 +/- 5.9246e+10 (0.01%) (init = 5.6e+14)
l_sigma: 3.4849e+12 +/- 1.0659e+11 (3.06%) (init = 1e+13)
l_fwhm: 6.9697e+12 +/- 2.1319e+11 (3.06%) == '2.0000000*l_sigma'
l_height: 1.21230299 +/- 0.02585463 (2.13%) == '0.3183099*l_amplitude/max(2.220446049250313e-16, l_sigma)'
l_center: 5.5847e+14 +/- 5.9246e+10 (0.01%) (init = 5.6e+14)
l_sigma: 3.4849e+12 +/- 1.0659e+11 (3.06%) (init = 1e+13)
l_fwhm: 6.9697e+12 +/- 2.1319e+11 (3.06%) == '2.0000000*l_sigma'
l_height: 1.21230299 +/- 0.02585463 (2.13%) == '0.3183099*l_amplitude/max(2.220446049250313e-16, l_sigma)'
[[Correlations]] (unreported correlations are < 0.100)
C(l_amplitude, l_sigma) = 0.724
Your problem was that you thought amplitude = height, but as mark said, height = 0.3*amplitude/sigma (as is shown in the fit_report expression). Since sigma was on the order of 1E13 - 1E14, your initial condition of amplitude = 1 made the height 1E-14 or thereabouts. Your initial condition was too far away from the final fit value, hence no fit and no uncertainties estimated. No amount of reasonable parameter exploration would change the residual when your model started with a value of ~1E-14.
Hope this helps.
- Evan
To view this discussion on the web visit https://groups.google.com/d/msgid/lmfit-py/CAASaBsR3B1cVP0szjnQiqGjQGeKWLG4u5UhFS3n-RoVTZwVBOw%40mail.gmail.com.
{kind=link}
Alexandros Gloor
Aug 14, 2020, 12:42:18 PM8/14/20
to lmfi...@googlegroups.com
I see now,
Reading back on the Lorentzian Model documentation, you are right in that I misinterpreted "height" being related to fwhm, but I see now that the two are not related.
A model based on a Lorentzian or Cauchy-Lorentz distribution function (...) with three Parameters:
amplitude, center, and sigma. In addition, parameters fwhm and height are included as constraints to report full width at half maximum and maximum peak height, respectively.Thank you!
To view this discussion on the web visit https://groups.google.com/d/msgid/lmfit-py/CAJKCVKYHg1deb4tXQ521eSgTkNL4Tsk1bfzSvtOKHzUD8Efq0A%40mail.gmail.com.
Mark Dean
Aug 14, 2020, 12:59:27 PM8/14/20
to lmfi...@googlegroups.com
Regarding the numbers, it's a good idea to work in units where x and y are all in the vague vicinity of unity. This will usually mean that the parameters will also be in the vague vicinity of unity. It will, of course, work with numbers many orders of magnitude bigger and smaller than that.
Firstly this improves the chances of the automatic guesses being reasonable. Secondly, any numerical fitting routine (including lmfit's) will be searching for how much to change the parameters to improve chi^2. If numbers are extremely large or small or the guess is very far away it will be harder for the routine to find fit the correct parameter space to converge on the fit.
This isn't a hard and fast rule, just a good idea to reduce the chance of issues. A hard and fast rule would be when numbers get too large or small for python to represent then, but this is an extreme case that usually only gets invoked when things involve exponentials.
To view this discussion on the web visit https://groups.google.com/d/msgid/lmfit-py/CAASaBsQ%2B6Udu6RNnAmhyxeRpHzTpCk_QZHEvNFrw%2BxLDoRsH4w%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages