Disruptor vs Actor scaling
2,043 views
Skip to first unread message

Rüdiger Möller
Jan 25, 2014, 11:38:43 AM1/25/14
to lmax-di...@googlegroups.com
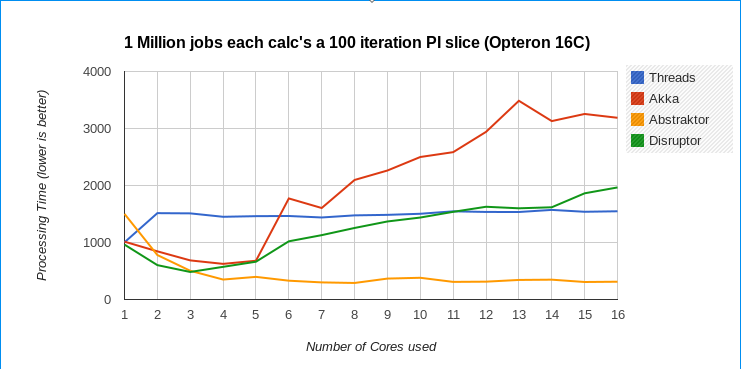
i am testing scaling behaviour of Akka vs Disruptor vs an experimental actor/CSP implementation.
Its basically a kind of diamond pattern where one producer creates PI calculation jobs (events) and a set of worker processors compute slices of PI. There is one result reclaimer adding up the output of the worker processors to get the final result.
Especially on Opteron disruptor does not scale that well (while being fastest with a low number of cores involved).
So somebody might want to check if I am doing something terribly wrong (I'd like to post results in a blog). I already modified wait strategy and size of ringbuffer with very little impact.
source is here:
https://github.com/RuedigerMoeller/abstractor/blob/master/src/test/java/de/ruedigermoeller/abstraktor/sample/DisruptorTest.java

Michael Barker
Jan 25, 2014, 3:31:32 PM1/25/14
to lmax-di...@googlegroups.com
Hi Rudiger,
There's a couple of things that jump out. Firstly you're using the WorkHandler, which started life as an example of how to get executor-like behaviour using the Disruptor. However, it is not really the original case that the Disruptor was designed for and hasn't had same level of attention to as the rest of the code.
Hopefully next week I'll have a look at an approach that may scale better.
Mike.
--
You received this message because you are subscribed to the Google Groups "Disruptor" group.
To unsubscribe from this group and stop receiving emails from it, send an email to lmax-disrupto...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.
Michael Barker
Jan 25, 2014, 5:24:26 PM1/25/14
to lmax-di...@googlegroups.com
Hi Rudiger,
Attached is an example of how I would do it with the Disruptor. Run
on my Ivy Bridge 4 Cores + HT.
Results (Disruptor2Test):
1: 376
2: 191
3: 132
4: 133
5: 120
6: 118
7: 110
8: 132
Results (ActorPiSample):
average 1 threads : 413
average 2 threads : 213
average 3 threads : 167
average 4 threads : 152
average 5 threads : 144
average 6 threads : 131
average 7 threads : 134
average 8 threads : 159
Both scale well to 7 threads. The Disruptor is using an additional
thread to handle accumulation of the sum value, therefore once we have
8 processing threads we have a total of 9 busy thread and have
exceeded our physical resources so performance starts to degrade. I
notice that the ActorPiSample has the same behaviour.
Mike.
Attached is an example of how I would do it with the Disruptor. Run
on my Ivy Bridge 4 Cores + HT.
Results (Disruptor2Test):
1: 376
2: 191
3: 132
4: 133
5: 120
6: 118
7: 110
8: 132
Results (ActorPiSample):
average 1 threads : 413
average 2 threads : 213
average 3 threads : 167
average 4 threads : 152
average 5 threads : 144
average 6 threads : 131
average 7 threads : 134
average 8 threads : 159
Both scale well to 7 threads. The Disruptor is using an additional
thread to handle accumulation of the sum value, therefore once we have
8 processing threads we have a total of 9 busy thread and have
exceeded our physical resources so performance starts to degrade. I
notice that the ActorPiSample has the same behaviour.
Mike.
Rüdiger Möller
Jan 26, 2014, 8:38:20 AM1/26/14
to lmax-di...@googlegroups.com
test
Rüdiger Möller
Jan 26, 2014, 8:47:00 AM1/26/14
to lmax-di...@googlegroups.com
Damn .. probably lost my post (javascript - hi tech at work).
Thanks for your quick response, Mike :) !
Note I am primary investigating the
int numSlice = 1000000;
int numIter = 100;
case, as with 100k, 1000 iter the bench is dominated by computation time.
This looks much better (see attachments), however the Disruptor2 test starts "descaling" at >9 cores (Hardware is dual socket opteron overall 16 cores+16HW Threads @ 2.1Ghz). I know from former tests that Intel is much more resilent against cross socket/core traffic, however the cheaper Opteron outperforms overall if programmed accordingly.
My explanation would be, that the disruptor has to share the whole Pi-Job across cores/sockets in order to reclaim results, while the Abstraktor sample just copies+enqueues the double result only.
Would you agree on that explanation ?
I'll try to add a second disruptor for result reclaiming only.
kind regards,
Rüdiger
Thanks for your quick response, Mike :) !
Note I am primary investigating the
int numSlice = 1000000;
int numIter = 100;
case, as with 100k, 1000 iter the bench is dominated by computation time.
This looks much better (see attachments), however the Disruptor2 test starts "descaling" at >9 cores (Hardware is dual socket opteron overall 16 cores+16HW Threads @ 2.1Ghz). I know from former tests that Intel is much more resilent against cross socket/core traffic, however the cheaper Opteron outperforms overall if programmed accordingly.
My explanation would be, that the disruptor has to share the whole Pi-Job across cores/sockets in order to reclaim results, while the Abstraktor sample just copies+enqueues the double result only.
Would you agree on that explanation ?
I'll try to add a second disruptor for result reclaiming only.
kind regards,
Rüdiger
{kind=link}
{kind=link}
{kind=link}
Michael Barker
Jan 26, 2014, 8:09:20 PM1/26/14
to lmax-di...@googlegroups.com
I'm not sure what the cause of the degradation at 9 cores could be, it
would be something to do with having to move data across sockets,
there also could be some false sharing involved. Perf stat might give
more information.
I haven't really looked at the Abstraktor in detail enough yet to
understand the difference, however I can think of some possible
optimisations to the disruptor implementation. For example it is
possible to change the Disruptor's backing data store with something
that is more cache friendly.
If I was passing the result out from each of the handlers using the
Disruptor, then I'd probably have a small disruptor per handler and
have a single thread polling multiple ring buffers. The is not
particularly well supported in the Disruptor, yet, but is the next
major change I'm looking at. If you have a single Disruptor for the
results you will probably introduce contention. One other
optimisation is if you are taking this approach you don't need to
publish the current sum on every message in, only if the endOfBatch
flag is true. Each event handler could cache the sum value and
publish once the batch is finished.
Mike.
would be something to do with having to move data across sockets,
there also could be some false sharing involved. Perf stat might give
more information.
I haven't really looked at the Abstraktor in detail enough yet to
understand the difference, however I can think of some possible
optimisations to the disruptor implementation. For example it is
possible to change the Disruptor's backing data store with something
that is more cache friendly.
If I was passing the result out from each of the handlers using the
Disruptor, then I'd probably have a small disruptor per handler and
have a single thread polling multiple ring buffers. The is not
particularly well supported in the Disruptor, yet, but is the next
major change I'm looking at. If you have a single Disruptor for the
results you will probably introduce contention. One other
optimisation is if you are taking this approach you don't need to
publish the current sum on every message in, only if the endOfBatch
flag is true. Each event handler could cache the sum value and
publish once the batch is finished.
Mike.
Rüdiger Möller
Jan 27, 2014, 7:40:59 PM1/27/14
to lmax-di...@googlegroups.com
I'm not sure what the cause of the degradation at 9 cores could be, it
would be something to do with having to move data across sockets,
there also could be some false sharing involved. Perf stat might give
more information.
I haven't really looked at the Abstraktor in detail enough yet to
understand the difference, however I can think of some possible
optimisations to the disruptor implementation. For example it is
possible to change the Disruptor's backing data store with something
that is more cache friendly.
Abstractor is just a playground. Reason for less contention is probaby:
Queue[] queue = {
new MpscConcurrentQueue<CallEntry>(QS), null,
new MpscConcurrentQueue<CallEntry>(QS), null,
new MpscConcurrentQueue<CallEntry>(QS), null,
new MpscConcurrentQueue<CallEntry>(QS), null,
};
Each thread gets a fixed index from 0..4 so i spread adding thread amongst queues. Drawback is an overall performance hit, because if have to poll 4 queues. Using this pattern as a general optimization is obviously not a good idea, but there are many use cases where this actually gives an advantage on >3 cores.
If I was passing the result out from each of the handlers using the
Disruptor, then I'd probably have a small disruptor per handler and
have a single thread polling multiple ring buffers.
see above ..
The is not
particularly well supported in the Disruptor, yet, but is the next
major change I'm looking at. If you have a single Disruptor for the
results you will probably introduce contention.
I tried. You are describing exactly what happened. Also uncontended performance was significantly worse. Best would be to use a MPSC queue instead of a disruptor to fan out results.
One other
optimisation is if you are taking this approach you don't need to
publish the current sum on every message in, only if the endOfBatch
flag is true. Each event handler could cache the sum value and
publish once the batch is finished.
was not aware of this possibility, however it would be unfair to overly optimize the diruptor, as i did not do that with the other benches .. disruptor is by far the fastest anyway :-)
I have added the intel results, see the blog entry here:
(ignore blabber at top, I use those blogs for internal training, so its pretty sketchy).
-rüdiger
Michael Barker
Jan 27, 2014, 7:49:08 PM1/27/14
to lmax-di...@googlegroups.com
>> One other
>> optimisation is if you are taking this approach you don't need to
>> publish the current sum on every message in, only if the endOfBatch
>> flag is true. Each event handler could cache the sum value and
>> publish once the batch is finished.
>
>
> was not aware of this possibility, however it would be unfair to overly
> optimize the diruptor, as i did not do that with the other benches ..
> disruptor is by far the fastest anyway :-)
Far enough. As an aside though, I am constantly surprised by how few
>> optimisation is if you are taking this approach you don't need to
>> publish the current sum on every message in, only if the endOfBatch
>> flag is true. Each event handler could cache the sum value and
>> publish once the batch is finished.
>
>
> was not aware of this possibility, however it would be unfair to overly
> optimize the diruptor, as i did not do that with the other benches ..
> disruptor is by far the fastest anyway :-)
many event/csp/actor/message-passing frameworks ignore or don't
consider smart-batching as a first class concept.
Mike.
Rüdiger Möller
Jan 27, 2014, 8:14:49 PM1/27/14
to lmax-di...@googlegroups.com
Also applicable to network messaging. One can get away with real bad queue implementation as long each Q slot contains some 100 messages. It does'n even affect latency that hard if done right (load dependent).
BTW are you located overseas or just a night walker ?
Michael Barker
Jan 27, 2014, 8:20:36 PM1/27/14
to lmax-di...@googlegroups.com
> Also applicable to network messaging. One can get away with real bad queue
> implementation as long each Q slot contains some 100 messages. It does'n
> even affect latency that hard if done right (load dependent).
> BTW are you located overseas or just a night walker ?
Auckland, NZ.
> implementation as long each Q slot contains some 100 messages. It does'n
> even affect latency that hard if done right (load dependent).
> BTW are you located overseas or just a night walker ?
Reply all
Reply to author
Forward
0 new messages