[llvm-dev] [RFC] Machine Function Splitter - Split out cold blocks from machine functions using profile data

Snehasish Kumar via llvm-dev
Greetings,
We present “Machine Function Splitter”, a codegen optimization pass which splits functions into hot and cold parts. This pass leverages the basic block sections feature recently introduced in LLVM from the Propeller project. The pass targets functions with profile coverage, identifies cold blocks and moves them to a separate section. The linker groups all cold blocks across functions together, decreasing fragmentation and improving icache and itlb utilization. Our experiments show >2% performance improvement on clang bootstrap, ~1% improvement on Google workloads and 1.6% mean performance improvement on SPEC IntRate 2017.
Motivation
Recent work at Google has shown that aggressive, profile-driven inlining for performance has led to significant code bloat and icache fragmentation (AsmDB - Ayers et al ‘2019). We find that most functions 5 KiB or larger have inlined children more than 10 layers deep bringing in exponentially more code at each inline level, not all of which is necessarily hot. Generally, in roughly half of even the hottest functions, more than 50% of the code bytes are never executed, but likely to be in the cache.
Function splitting is a well known compiler transformation primarily targeting improved code locality to improve performance. LLVM has a middle-end, target agnostic hot cold splitting pass as well as a partial inlining pass which performs similar transformations, as noted by the authors in a recent email thread. However, due to the timing of the respective passes as well as the code extraction techniques employed, the overall gains on large, complex applications leave headroom for improvement. By deferring function splitting to the codegen phase we can maximize the opportunity to remove cold code as well as refine the code extraction technique. Furthermore, by performing function splitting very late, earlier passes can perform more aggressive optimizations.
Implementation
We propose a new machine function splitting pass which leverages the basic block sections feature to split functions without the caveats of code extraction in the middle-end. The pass uses profile information to identify cold basic blocks very late in LLVM CodeGen, after regalloc and all other machine passes have executed. This allows our implementation to be precise in its assessment of cold regions while maximizing opportunity.
Each function is split into two parts. The hot cluster includes the function entry and all blocks which are not cold. All the cold blocks are grouped together as a Cold Section cluster. With basic block sections, the cold blocks are assigned appropriate debug and call frame information and emitted as part of the .text.unlikely section. Unlike Propeller, which is presently the main user of the basic block sections feature, this pass does not require an additional round of profiling and uses existing instrumentation based FDO or CSFDO profile information.
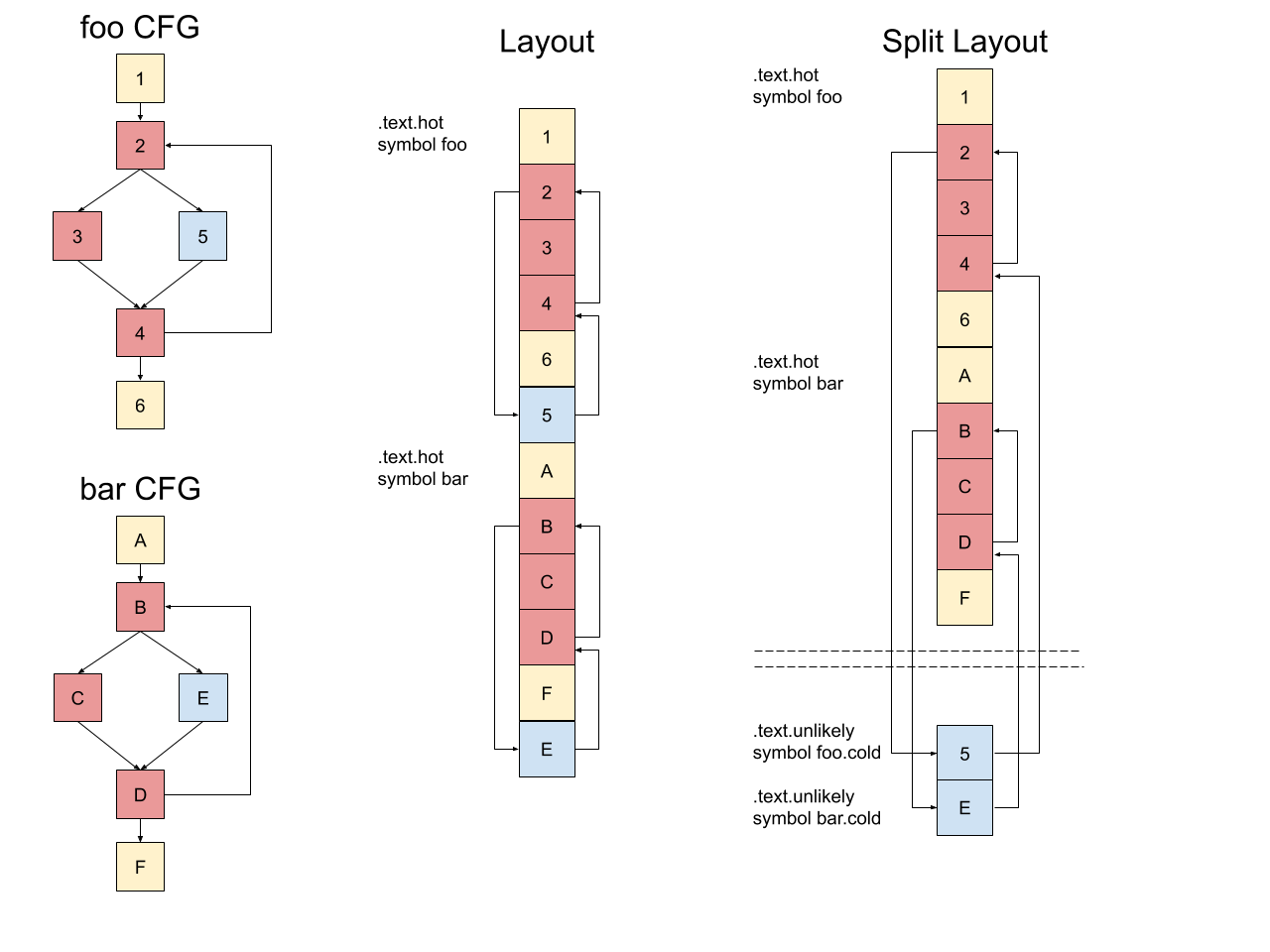
In the illustration above, the functions foo and bar contain a cold block each, index 5 and E respectively. We show a possible layout for these functions which optimizes for fall throughs. Note that all the blocks are kept in a contiguous region described by the symbols foo and bar. Using the machine function splitter, the cold blocks (5 and E) are moved to a separate section. These blocks can then be grouped along with other cold blocks (and functions) in a separate output section in the final binary. The key highlights of this approach are:
Profile driven, profile type agnostic approach.
Cold basic blocks are split out using jumps.
No additional instructions are added to the function for setup/teardown.
Runs as the last step before emitting assembly, no analysis/optimizations are hindered.
Exceptions
All eh pads are grouped together regardless of their coldness and are part of the original function. There are outstanding issues with splitting eh pads if they reside in separate sections in the binary. This remains as part of future work.
DebugInfo and CFI
Debug information and CFI directives are updated and kept consistent by the underlying basic block sections framework. Support added in the following patches
DebugInfo (https://reviews.llvm.org/D78851)
Distinction between Machine Function Splitter and Propeller
Full Propeller optimizations include function splitting and layout optimizations, however it requires an additional round of profiling using perf on top of the peak (FDO/CSFDO + ThinLTO) binary. In this work we experiment with applying function splitting using the instrumented profile in the build instead of adding an additional round of profiling.
Split Binary Characteristics
Binaries produced by the compiler with function splitting enabled contain additional symbols. A function which has been split into a hot and cold part is non-contiguous. The symbol table entry for the hot part retains the symbol name of the original function with type FUNC. The symbol for the cold part contains a “.cold” suffix attached to the original symbol name, the type is not set for this symbol. Using a suffix has been the norm for such optimizations e.g. -hot-cold-split in LLVM and the prior GCC implementation detailed earlier. We expect standardized tooling to handle split functions appropriately, e.g demangling works as expected --
Contrast with HotColdSplit (HCS)
Function splitting in the middle-end in LLVM employs extraction of cold single-entry-single-exit (SESE) regions into separate functions. In general, the pass has been found to be impactful in reducing code size by deduplication of cold regions; however our experiments show it does not improve performance of large workloads.
The key differences are:
Extraction methodology and tradeoffs
HCS extracts cold code from SESE regions using a function call. This may incur a spill and fill of caller registers along with additional setup and teardown if live values modified in the cold region need to be communicated back to the original function. This has a couple of implications
The “residue” of each extracted region is non-trivial and there is a tradeoff between the amount of code that needs to be cold before it is profitable to extract. Thus the cost of mischaracterization is high.
Since each SESE region is extracted separately the net reduction in code size of the original function is less.
In contrast, the machine function splitter extracts cold code into a separate section. Control is transferred to cold code via jumps. More often than not these jumps may already exist as part of the original layout thus incurring no additional cost. No additional instructions are inserted to accommodate splitting. Finally, no additional setup/teardown is necessary for live values modified in cold regions.
Pass timing and interaction with other optimizations
The HCS pass is run on the IR in the optimizer. This allows it to be target agnostic and allow later stages to merge identical code if necessary. However, there are some drawbacks to this approach. In particular,
Splitting early may miss opportunities introduced by later passes such as library call inlining and CFG simplification resulting from a combination of optimizations. Furthermore, this may not play well with optimization passes such as MachineOutliner.
Synergistic optimizations are harder to reason about due to the pass timing. For example, inlining can be more aggressive if any cold code introduced is trimmed.
In contrast, the machine function splitter runs as the last step in codegen. This ensures that the opportunity for splitting is maximised without hindering existing analyses and synergistic decisions can be made in earlier optimization passes. We rely on accurate profile count propagation across optimizations to maximise opportunities. This works particularly well for instrumented profiles while improving the pass for sampled profiles is ongoing work.
We have provided a contrived example in the Appendix which demonstrates the code generated for both approaches. The key differences are highlighted inline.
Evaluation
In this section, we present an in-depth evaluation of the impact on clang bootstrap and summary results for two google internal workloads, Search1 and Search2 as well overall results on the SPECInt 2017 benchmarks. All experiments are conducted on Intel Skylake based systems unless otherwise noted. Profile guided optimizations using instrumented profiles are enabled for all builds.
clang-bootstrap
We pick 500 compiler invocations from a bootstrap build of clang and then evaluate the performance of a PGO+ThinLTO optimized version with that of PGO+ThinLTO+Split compiler. For the latter, the final optimized build includes the machine function splitter.
Results:
We observe a mean 2.33% improvement in end to end runtime. The improvements in runtime are driven by reduction in icache and TLB miss rates. The table below summarizes our experiment, each data point is averaged over multiple iterations. The observed variation for each metric is < 1%.
In this experiment, the function splitting pass moved cold code from ~30K functions in .text and .text.hot. We present a comparison of the binary contents using bloaty
FILE SIZE VM SIZE
-------------- --------------
+23% +8.26Mi +23% +8.26Mi .text.unlikely
+6.5% +761Ki [ = ] 0 .strtab
+4.8% +247Ki +4.8% +247Ki .eh_frame
+6.1% +193Ki [ = ] 0 .symtab
+8.5% +63.1Ki +8.5% +63.1Ki .eh_frame_hdr
+0.3% +31.3Ki +0.3% +31.3Ki .rodata
+0.4% +3 [ = ] 0 [Unmapped]
-0.3% -8 -0.3% -8 .init_array
[ = ] 0 -33.3% -8 [LOAD #4 [RW]]
[ = ] 0 -0.2% -416 .bss
-57.1% -4.04Mi -57.1% -4.04Mi .text.hot
-48.4% -4.13Mi -48.4% -4.13Mi .text
+1.6% +1.35Mi +0.6% +430Ki TOTAL
We see that 48% and 57% of code in .text and .text.hot respectively was moved to the .text.unlikely section. We also note a small increase in overall binary size due to the following reasons:
Some additional jump instructions may be inserted.
Small increase in associated metadata, e.g. debug information.
Additional symbols of type foo.cold for cold parts.
Alignment requirements for both original and split function parts.
Comparison with HotColdSplit
For the clang-bootstrap benchmark we also compared the performance of the hot-cold-split pass with split-machine-functions. We summarize the results for performance and the characteristics of the binary built by each pass in the table below. Each metric is presented as change vs the baseline, an FDO optimized build of clang.
Note that the increase in overall binary size increase for HCS is due to the increase in .eh_frame (+61% +3.03Mi). HCS extracts each cold SESE region as a separate function whereas the machine function splitter extracts the cold code as a single region thus incurring a constant overhead per function.
Google workloads
We evaluated the impact of function splitting on a couple of search workloads, Search1 and Search2. A key difference with respect to the clang experiment above is the use of huge pages for code. Overall, we find that on Intel Skylake the key benefit is from reduction of iTLB misses whereas on AMD the key benefit is from the reduction of icache misses. This is due to the fewer iTLB entries available for hugepages on Intel architectures. We find that overall throughput for Search1 and Search2 improve between 0.8% to 1.2%; a significant improvement on these benchmarks. The workloads are built with FDO and CSFDO respectively. On Intel Skylake, iTLB misses reduce by 16% to 35%, sTLB misses reduce by 62% to 67%. On AMD, L1 icache misses improve by 1.2% to 2.6% whereas L2 instruction misses improve by 4.8% to 5.1%.
Comparison with HotColdSplit
An evaluation of the hot-cold-split pass did not yield performance improvements on google workloads.
SPECInt 2017
We evaluated the impact of the machine function splitter on SPECInt 2017 using the int rate metrics. Overall, we found a 1.6% geomean intrate improvement for the benchmarks where performance improved (500.perlbench_r, 502.gcc_r, 505.mcf_r, 520.omnetpp_r). For the benchmarks that didn’t improve performance, the average degradation was 0.6% (523.xalancbmk_r, 525.x264_r, 531.deepsjeng_r, 541.leela_r).
We note that the instruction footprint of SPEC workloads are smaller than most modern workloads and our work is primarily focused on reducing the footprint to improve performance. These experiments were performed on Intel Haswell machines.
Appendix
Example to illustrate hot-cold-split and split-machine-functions
Input IR
```
@i = external global i32, align 4
define i32 @foo(i32 %0, i32 %1) nounwind !prof !1 {
%3 = icmp eq i32 %0, 0
br i1 %3, label %6, label %4, !prof !2
4: ; preds = %2
%5 = call i32 @L1()
br label %9
6: ; preds = %2
%7 = call i32 @R1()
%8 = add nsw i32 %1, 1
br label %9
9: ; preds = %6, %4
%10 = phi i32 [ %1, %4 ], [ %8, %6 ]
%11 = load i32, i32* @i, align 4
%12 = add nsw i32 %10, %11
store i32 %12, i32* @i, align 4
ret i32 %12
}
declare i32 @L1()
declare i32 @R1() cold nounwind
!1 = !{!"function_entry_count", i64 7}
!2 = !{!"branch_weights", i32 0, i32 7}
```
Code generated by Machine Function Splitter
$ llc < example.ll -mtriple=x86_64-unknown-linux-gnu -split-machine-functions
```
.text
.file "<stdin>"
.globl foo # -- Begin function foo
.p2align 4, 0x90
.type foo,@function
foo: # @foo
# %bb.0:
pushq %rbx
movl %esi, %ebx
testl %edi, %edi
je foo.cold # Jump to cold code
# %bb.1:
callq L1
.LBB0_2:
addl i(%rip), %ebx
movl %ebx, i(%rip)
movl %ebx, %eax
popq %rbx
retq
.section .text.unlikely.foo,"ax",@progbits
foo.cold:
callq R1
incl %ebx # Directly increment value
jmp .LBB0_2
.LBB_END0_3:
.size foo.cold, .LBB_END0_3-foo.cold
.text
.Lfunc_end0:
.size foo, .Lfunc_end0-foo
# -- End function
.section ".note.GNU-stack","",@progbits
```
Code generated by Hot Cold Split
$ clang -c -O2 -S -mllvm --hot-cold-split -mllvm --hotcoldsplit-threshold=0 -x ir example.ll
```
.text
.file "example.ll"
.globl foo # -- Begin function foo
.p2align 4, 0x90
.type foo,@function
foo: # @foo
# %bb.0:
pushq %rbx
subq $16, %rsp
movl %esi, %ebx
testl %edi, %edi
jne .LBB0_1
# %bb.2: # Residue block in original function
leaq 12(%rsp), %rsi
movl %ebx, %edi # Pass param to increment
callq foo.cold.1 # Call to cold code
movl 12(%rsp), %ebx # Fill incremented value from stack
.LBB0_3:
addl i(%rip), %ebx
movl %ebx, i(%rip)
movl %ebx, %eax
addq $16, %rsp
popq %rbx
retq
.LBB0_1:
callq L1
jmp .LBB0_3
.Lfunc_end0:
.size foo, .Lfunc_end0-foo
# -- End function
.p2align 4, 0x90 # -- Begin function foo.cold.1
.type foo.cold.1,@function
foo.cold.1: # @foo.cold.1
# %bb.0: # %newFuncRoot
pushq %rbp
pushq %rbx
pushq %rax
movq %rsi, %rbx
movl %edi, %ebp
callq R1
incl %ebp
movl %ebp, (%rbx)
addq $8, %rsp
popq %rbx
popq %rbp
retq
.Lfunc_end1:
.size foo.cold.1, .Lfunc_end1-foo.cold.1
# -- End function
.cg_profile foo, L1, 0
.cg_profile foo, foo.cold.1, 7
.section ".note.GNU-stack","",@progbits
.addrsig
.addrsig_sym foo.cold.1
```
aditya kumar via llvm-dev
Because the inliner can be too aggressive at times and can negatively affect icache-miss etc, HCS can be integrated with inliner to assist in partial inlining (For example: split the callee before inlining). Rodrigo (@rcorcs) has some ideas around that and we've been exploring that as part of GSoC project.Xinliang David Li via llvm-dev
Glad to hear that there is an interest in a function splitting pass. There are advantages to splitting functions at different stages as you've already noted.
- Having a target independent function splitting scales well to LTO, ThinLTO, supporting multiple architectures and offers ease of maintenance.- While HCS+merge-function helps significantly reduce the codesize, in many cases the outlined functions tend to have identical function bodies (e.g., assert-fail etc); they can be deduplicated by linker with careful function naming. This reduces code-size regardless of function merging and across the entire program. This technique should also help Machine Function splitter in some cases but at some cost to the link time.
- It will be difficult to reduce argument setup and restore code in the HCS except in some cases like tail call, internal function calls, non-returning function calls etc. Having frame setup however should help with debugging IMO.> Recent work at Google has shown that aggressive, profile-driven inlining for performance has led to significant code bloat and icache fragmentationBecause the inliner can be too aggressive at times and can negatively affect icache-miss etc, HCS can be integrated with inliner to assist in partial inlining (For example: split the callee before inlining). Rodrigo (@rcorcs) has some ideas around that and we've been exploring that as part of GSoC project.
We've performance numbers from Firefox which shows ~5% performance improvement with HCS (cc: Ruijie @rjf). Vedant also reported performance numbers across iOS and Swift benchmarks in the past. I could find (https://github.com/apple/swift/pull/21016) which reported decent performance improvement in core ios Frameworks.
That said we have been working on improving the cost model which I think will help alleviate many of the limitations that we typically don't have in a Machine Splitting optimization. I'd like to hear your ideas on how the cost model can be improved.
> In contrast, the machine function splitter extracts cold code into a separate section.HCS also adds a section prefix to all the cold functions. It is possible that the cold functions are still in the same section as the hot one depending on the linker. Ruijie has a patch to move all the cold functions to a separate section, we are still evaluating the results (https://github.com/ruijiefang/llvm-hcs/commit/4966997e135050c99b4adc0aa971242af99ba832). In case it is not difficult to rerun the experiments, it'll help to see the numbers with the llvm-trunk and this patch from @rjf.> Furthermore, this may not play well with optimization passes such as MachineOutliner.Can you share an example where HCS and Machine Outliner don't play well together?
> Synergistic optimizations are harder to reason about due to the pass timing. For example, inlining can be more aggressive if any cold code introduced is trimmed.How does this regress workloads if we have profile information and cold portions of a callee is outlined? Does the inliner always regress workloads we are evaluating?
PS: One correction I'd like to make is HCS splits SEME regions (Thanks to Vedant). In case some SEME aren't getting outlined, there are CFG transformations to make them friendly to HCS. I'd love to see such an example, as that'd motivate some of the future work.
Snehasish Kumar via llvm-dev
On Tue, Aug 4, 2020 at 10:51 PM aditya kumar <hira...@gmail.com> wrote:Glad to hear that there is an interest in a function splitting pass. There are advantages to splitting functions at different stages as you've already noted.Right -- with slightly different objectives. Machine Function Splitting Pass's main focus is on performance improvement.- Having a target independent function splitting scales well to LTO, ThinLTO, supporting multiple architectures and offers ease of maintenance.- While HCS+merge-function helps significantly reduce the codesize, in many cases the outlined functions tend to have identical function bodies (e.g., assert-fail etc); they can be deduplicated by linker with careful function naming. This reduces code-size regardless of function merging and across the entire program. This technique should also help Machine Function splitter in some cases but at some cost to the link time.yes -- I think this can also be achieved with the partial inlining pass.- It will be difficult to reduce argument setup and restore code in the HCS except in some cases like tail call, internal function calls, non-returning function calls etc. Having frame setup however should help with debugging IMO.
> Recent work at Google has shown that aggressive, profile-driven inlining for performance has led to significant code bloat and icache fragmentationBecause the inliner can be too aggressive at times and can negatively affect icache-miss etc, HCS can be integrated with inliner to assist in partial inlining (For example: split the callee before inlining). Rodrigo (@rcorcs) has some ideas around that and we've been exploring that as part of GSoC project.The Inliner can also be hindered without splitting. Partial inlining can help a little, but it can be limited because many of the outlining opportunities are only exposed after inlining (in inline instances). Making inliner Machine Splitting or HCS aware is the way to go. Machine Function splitting has an advantage here as it does not need sophisticated analysis to figure out what part of code can and can not be split out post inlining.We've performance numbers from Firefox which shows ~5% performance improvement with HCS (cc: Ruijie @rjf). Vedant also reported performance numbers across iOS and Swift benchmarks in the past. I could find (https://github.com/apple/swift/pull/21016) which reported decent performance improvement in core ios Frameworks.Nice. If possible, the same performance tests can be done for Machine Splitting once the patch is posted :)That said we have been working on improving the cost model which I think will help alleviate many of the limitations that we typically don't have in a Machine Splitting optimization. I'd like to hear your ideas on how the cost model can be improved.The partial inliner pass has introduced many cost analysis using profile data. I think HCS should probably share those code (as utilities) as the nature of the transformation is similar. Cost model can sometimes be quite tricky though -- it is hard to compare the cost with the actual benefit brought by the splitting. The beauty of machine splitting is that it does not depend on sophisticated cost/benefit model.
> In contrast, the machine function splitter extracts cold code into a separate section.HCS also adds a section prefix to all the cold functions. It is possible that the cold functions are still in the same section as the hot one depending on the linker. Ruijie has a patch to move all the cold functions to a separate section, we are still evaluating the results (https://github.com/ruijiefang/llvm-hcs/commit/4966997e135050c99b4adc0aa971242af99ba832). In case it is not difficult to rerun the experiments, it'll help to see the numbers with the llvm-trunk and this patch from @rjf.> Furthermore, this may not play well with optimization passes such as MachineOutliner.Can you share an example where HCS and Machine Outliner don't play well together?One thing I can think of is that Machine Outliner is based on code pattern, while HCS also looks at hotness. The inconsistency can lead to missing opportunities in machine outliner ?> Synergistic optimizations are harder to reason about due to the pass timing. For example, inlining can be more aggressive if any cold code introduced is trimmed.How does this regress workloads if we have profile information and cold portions of a callee is outlined? Does the inliner always regress workloads we are evaluating?Currently inliner only looks at static code size (as cost). We are working on improving it.PS: One correction I'd like to make is HCS splits SEME regions (Thanks to Vedant). In case some SEME aren't getting outlined, there are CFG transformations to make them friendly to HCS. I'd love to see such an example, as that'd motivate some of the future work.
aditya kumar via llvm-dev
On Tue, Aug 4, 2020 at 10:51 PM aditya kumar <hira...@gmail.com> wrote:Glad to hear that there is an interest in a function splitting pass. There are advantages to splitting functions at different stages as you've already noted.Right -- with slightly different objectives. Machine Function Splitting Pass's main focus is on performance improvement.
- Having a target independent function splitting scales well to LTO, ThinLTO, supporting multiple architectures and offers ease of maintenance.- While HCS+merge-function helps significantly reduce the codesize, in many cases the outlined functions tend to have identical function bodies (e.g., assert-fail etc); they can be deduplicated by linker with careful function naming. This reduces code-size regardless of function merging and across the entire program. This technique should also help Machine Function splitter in some cases but at some cost to the link time.yes -- I think this can also be achieved with the partial inlining pass.
- It will be difficult to reduce argument setup and restore code in the HCS except in some cases like tail call, internal function calls, non-returning function calls etc. Having frame setup however should help with debugging IMO.> Recent work at Google has shown that aggressive, profile-driven inlining for performance has led to significant code bloat and icache fragmentationBecause the inliner can be too aggressive at times and can negatively affect icache-miss etc, HCS can be integrated with inliner to assist in partial inlining (For example: split the callee before inlining). Rodrigo (@rcorcs) has some ideas around that and we've been exploring that as part of GSoC project.The Inliner can also be hindered without splitting. Partial inlining can help a little, but it can be limited because many of the outlining opportunities are only exposed after inlining (in inline instances). Making inliner Machine Splitting or HCS aware is the way to go. Machine Function splitting has an advantage here as it does not need sophisticated analysis to figure out what part of code can and can not be split out post inlining.We've performance numbers from Firefox which shows ~5% performance improvement with HCS (cc: Ruijie @rjf). Vedant also reported performance numbers across iOS and Swift benchmarks in the past. I could find (https://github.com/apple/swift/pull/21016) which reported decent performance improvement in core ios Frameworks.Nice. If possible, the same performance tests can be done for Machine Splitting once the patch is posted :)That said we have been working on improving the cost model which I think will help alleviate many of the limitations that we typically don't have in a Machine Splitting optimization. I'd like to hear your ideas on how the cost model can be improved.The partial inliner pass has introduced many cost analysis using profile data. I think HCS should probably share those code (as utilities) as the nature of the transformation is similar. Cost model can sometimes be quite tricky though -- it is hard to compare the cost with the actual benefit brought by the splitting. The beauty of machine splitting is that it does not depend on sophisticated cost/benefit model.> In contrast, the machine function splitter extracts cold code into a separate section.HCS also adds a section prefix to all the cold functions. It is possible that the cold functions are still in the same section as the hot one depending on the linker. Ruijie has a patch to move all the cold functions to a separate section, we are still evaluating the results (https://github.com/ruijiefang/llvm-hcs/commit/4966997e135050c99b4adc0aa971242af99ba832). In case it is not difficult to rerun the experiments, it'll help to see the numbers with the llvm-trunk and this patch from @rjf.> Furthermore, this may not play well with optimization passes such as MachineOutliner.Can you share an example where HCS and Machine Outliner don't play well together?One thing I can think of is that Machine Outliner is based on code pattern, while HCS also looks at hotness. The inconsistency can lead to missing opportunities in machine outliner ?
> Synergistic optimizations are harder to reason about due to the pass timing. For example, inlining can be more aggressive if any cold code introduced is trimmed.How does this regress workloads if we have profile information and cold portions of a callee is outlined? Does the inliner always regress workloads we are evaluating?Currently inliner only looks at static code size (as cost). We are working on improving it.
PS: One correction I'd like to make is HCS splits SEME regions (Thanks to Vedant). In case some SEME aren't getting outlined, there are CFG transformations to make them friendly to HCS. I'd love to see such an example, as that'd motivate some of the future work.It is common to see multiple entry cold regions post inlining. After block layout, we may see long chains of cold blocks with many blocks in the chain being jump targets (from hot regions). If there are multiple blocks exiting the cold region, we get multiple exits case.
thanks,David
On Tue, Aug 4, 2020 at 5:31 PM Snehasish Kumar <sneha...@google.com> wrote:
Greetings,
We present “Machine Function Splitter”, a codegen optimization pass which splits functions into hot and cold parts. This pass leverages the basic block sections feature recently introduced in LLVM from the Propeller project. The pass targets functions with profile coverage, identifies cold blocks and moves them to a separate section. The linker groups all cold blocks across functions together, decreasing fragmentation and improving icache and itlb utilization. Our experiments show >2% performance improvement on clang bootstrap, ~1% improvement on Google workloads and 1.6% mean performance improvement on SPEC IntRate 2017.
Motivation
Recent work at Google has shown that aggressive, profile-driven inlining for performance has led to significant code bloat and icache fragmentation (AsmDB - Ayers et al ‘2019). We find that most functions 5 KiB or larger have inlined children more than 10 layers deep bringing in exponentially more code at each inline level, not all of which is necessarily hot. Generally, in roughly half of even the hottest functions, more than 50% of the code bytes are never executed, but likely to be in the cache.
Function splitting is a well known compiler transformation primarily targeting improved code locality to improve performance. LLVM has a middle-end, target agnostic hot cold splitting pass as well as a partial inlining pass which performs similar transformations, as noted by the authors in a recent email thread. However, due to the timing of the respective passes as well as the code extraction techniques employed, the overall gains on large, complex applications leave headroom for improvement. By deferring function splitting to the codegen phase we can maximize the opportunity to remove cold code as well as refine the code extraction technique. Furthermore, by performing function splitting very late, earlier passes can perform more aggressive optimizations.
Implementation
We propose a new machine function splitting pass which leverages the basic block sections feature to split functions without the caveats of code extraction in the middle-end. The pass uses profile information to identify cold basic blocks very late in LLVM CodeGen, after regalloc and all other machine passes have executed. This allows our implementation to be precise in its assessment of cold regions while maximizing opportunity.
Each function is split into two parts. The hot cluster includes the function entry and all blocks which are not cold. All the cold blocks are grouped together as a Cold Section cluster. With basic block sections, the cold blocks are assigned appropriate debug and call frame information and emitted as part of the .text.unlikely section. Unlike Propeller, which is presently the main user of the basic block sections feature, this pass does not require an additional round of profiling and uses existing instrumentation based FDO or CSFDO profile information.
Wenlei He via llvm-dev
Cool stuff – nice to see a late splitting pass in LLVM.
> Full Propeller optimizations include function splitting and layout optimizations, however it requires an additional round of profiling using perf on top of the peak (FDO/CSFDO + ThinLTO) binary. In this work we experiment with applying function splitting using the instrumented profile in the build instead of adding an additional round of profiling.
I’d expect propeller or BOLT to be more effective at doing this due to better post-inline profile. Of course the usability advantage of not needing a separate profile is very practical, but just wondering did you see profile quality getting in the way here?
> uses existing instrumentation based FDO or CSFDO profile information.
Similarly, with instrumentation FDO alone, the post-inline profile may not be accurate, so for this splitting, is it more effective when used with CSFDO? Was the evaluation result from FDO or CSFDO?
Also wondering does this work with Sample FDO, and do you have numbers that you can share when used with Sample FDO?
Thanks,
Wenlei
From: llvm-dev <llvm-dev...@lists.llvm.org> on behalf of Snehasish Kumar via llvm-dev <llvm...@lists.llvm.org>
Reply-To: Snehasish Kumar <sneha...@google.com>
Date: Tuesday, August 4, 2020 at 5:41 PM
To: llvm-dev <llvm...@lists.llvm.org>, David Li <dav...@google.com>, Eric Christopher <echr...@google.com>, Sriraman Tallam <tmsr...@google.com>, aditya kumar <hira...@gmail.com>, "efri...@codeaurora.org" <efri...@codeaurora.org>
Subject: [llvm-dev] [RFC] Machine Function Splitter - Split out cold blocks from machine functions using profile data
Greetings,
We present “Machine Function Splitter”, a codegen optimization pass which splits functions into hot and cold parts. This pass leverages the basic block sections feature recently introduced in LLVM from the Propeller project. The pass targets functions with profile coverage, identifies cold blocks and moves them to a separate section. The linker groups all cold blocks across functions together, decreasing fragmentation and improving icache and itlb utilization. Our experiments show >2% performance improvement on clang bootstrap, ~1% improvement on Google workloads and 1.6% mean performance improvement on SPEC IntRate 2017.
Motivation
Recent work at Google has shown that aggressive, profile-driven inlining for performance has led to significant code bloat and icache fragmentation (AsmDB - Ayers et al ‘2019). We find that most functions 5 KiB or larger have inlined children more than 10 layers deep bringing in exponentially more code at each inline level, not all of which is necessarily hot. Generally, in roughly half of even the hottest functions, more than 50% of the code bytes are never executed, but likely to be in the cache.
Function splitting is a well known compiler transformation primarily targeting improved code locality to improve performance. LLVM has a middle-end, target agnostic hot cold splitting pass as well as a partial inlining pass which performs similar transformations, as noted by the authors in a recent email thread. However, due to the timing of the respective passes as well as the code extraction techniques employed, the overall gains on large, complex applications leave headroom for improvement. By deferring function splitting to the codegen phase we can maximize the opportunity to remove cold code as well as refine the code extraction technique. Furthermore, by performing function splitting very late, earlier passes can perform more aggressive optimizations.
Implementation
We propose a new machine function splitting pass which leverages the basic block sections feature to split functions without the caveats of code extraction in the middle-end. The pass uses profile information to identify cold basic blocks very late in LLVM CodeGen, after regalloc and all other machine passes have executed. This allows our implementation to be precise in its assessment of cold regions while maximizing opportunity.
Each function is split into two parts. The hot cluster includes the function entry and all blocks which are not cold. All the cold blocks are grouped together as a Cold Section cluster. With basic block sections, the cold blocks are assigned appropriate debug and call frame information and emitted as part of the .text.unlikely section. Unlike Propeller, which is presently the main user of the basic block sections feature, this pass does not require an additional round of profiling and uses existing instrumentation based FDO or CSFDO profile information.

Snehasish Kumar via llvm-dev
Cool stuff – nice to see a late splitting pass in LLVM.
> Full Propeller optimizations include function splitting and layout optimizations, however it requires an additional round of profiling using perf on top of the peak (FDO/CSFDO + ThinLTO) binary. In this work we experiment with applying function splitting using the instrumented profile in the build instead of adding an additional round of profiling.
I’d expect propeller or BOLT to be more effective at doing this due to better post-inline profile. Of course the usability advantage of not needing a separate profile is very practical, but just wondering did you see profile quality getting in the way here?
> uses existing instrumentation based FDO or CSFDO profile information.
Similarly, with instrumentation FDO alone, the post-inline profile may not be accurate, so for this splitting, is it more effective when used with CSFDO? Was the evaluation result from FDO or CSFDO?
Also wondering does this work with Sample FDO, and do you have numbers that you can share when used with Sample FDO?
Thanks,
Wenlei
Xinliang David Li via llvm-dev
Hi Wenlei,Thanks for your interest :)On Fri, Aug 7, 2020 at 12:40 AM Wenlei He <wen...@fb.com> wrote:Cool stuff – nice to see a late splitting pass in LLVM.
> Full Propeller optimizations include function splitting and layout optimizations, however it requires an additional round of profiling using perf on top of the peak (FDO/CSFDO + ThinLTO) binary. In this work we experiment with applying function splitting using the instrumented profile in the build instead of adding an additional round of profiling.
I’d expect propeller or BOLT to be more effective at doing this due to better post-inline profile. Of course the usability advantage of not needing a separate profile is very practical, but just wondering did you see profile quality getting in the way here?
Yes, currently the pass is quite sensitive to profile quality. For e.g, the current default is to split only blocks with zero profile count. Using a binary choice is more effective than a count based threshold.
Snehasish Kumar via llvm-dev
>Exceptions
>All eh pads are grouped together regardless of their coldness and are part of the original function. There are outstanding issues with splitting eh pads if they reside in separate sections in the binary. This remains as part of future work.
Can you elaborate more on the outstanding issues with splitting eh pads?
From my dip into the unwind map in gcc_except_table the current encoding to landing pads using function-start relative offsets doesn’t extend well to moving the pads somewhere else. Are there additional issues with splitting specific pads out?
Best,
Modi
Modi Mo via llvm-dev
Thanks for the link!
Looks like the flexibility to define landing pad start (LPStart) is already built into the EH metadata format. Taking advantage of that should allow ehpads to go anywhere they please.
I’m looking at the runtime support and while gxx_personality_v0 (The C++ handler) does read LPStart gcc_personality_v0 (The C handler) purposefully ignores it. Pads in C can be generated due to “__attribute__((cleanup(func)))”. If C code is a candidate for these transforms this probably needs to be fixed up.
Modi Mo via llvm-dev
>Exceptions
>All eh pads are grouped together regardless of their coldness and are part of the original function. There are outstanding issues with splitting eh pads if they reside in separate sections in the binary. This remains as part of future work.
Can you elaborate more on the outstanding issues with splitting eh pads?
From my dip into the unwind map in gcc_except_table the current encoding to landing pads using function-start relative offsets doesn’t extend well to moving the pads somewhere else. Are there additional issues with splitting specific pads out?
Best,
Modi
Wenlei He via llvm-dev
Thanks for pointer to https://reviews.llvm.org/D73739. Large part of that patch of involves coping with the dis-contiguity resulted from BB section, so EH table need to be broken up. If we want EH pad splitting to work with regular function (without BB section), it looks to me that the flexibility from explicit LPStart, plus the change to deal with zero offset landing pad should be enough?
We’re looking into separating out EH pads too as Modi pointed out, even without profile data.
Thanks,
Wenlei
Jessica Paquette via llvm-dev
> In contrast, the machine function splitter extracts cold code into a separate section.HCS also adds a section prefix to all the cold functions. It is possible that the cold functions are still in the same section as the hot one depending on the linker. Ruijie has a patch to move all the cold functions to a separate section, we are still evaluating the results (https://github.com/ruijiefang/llvm-hcs/commit/4966997e135050c99b4adc0aa971242af99ba832). In case it is not difficult to rerun the experiments, it'll help to see the numbers with the llvm-trunk and this patch from @rjf.> Furthermore, this may not play well with optimization passes such as MachineOutliner.Can you share an example where HCS and Machine Outliner don't play well together?One thing I can think of is that Machine Outliner is based on code pattern, while HCS also looks at hotness. The inconsistency can lead to missing opportunities in machine outliner ?
Philip Reames via llvm-dev
Thank you for the nice writeup.
This sounds like a useful thing to have in tree. As you point
out, there are obvious tradeoffs between the IR level and late
codegen approaches. There's always going to be cases where one
wins and one looses. Having both in tree, and tuning heuristics
to focus on the complement wins seems like a very reasonable
approach.
As an aside, one interesting idea on the IR level would be to
explore cases where we can specifically split cold suffixes (that
is, paths not rejoining hot paths before function return). We
have musttail support (for the branch lowering), and should be
able to adjust the calling convention for the call if it ends up
with one caller. This might address some of the challenges with
IR level splitting.
Philip
_______________________________________________ LLVM Developers mailing list llvm...@lists.llvm.org https://lists.llvm.org/cgi-bin/mailman/listinfo/llvm-dev
aditya kumar via llvm-dev
aditya kumar via llvm-dev
Snehasish Kumar via llvm-dev
> Just chiming in about the outliner stuff. (In general, I think it's desirable to have multiple options for how early/late a pass runs.)I'm wondering if MachineOutliner can be augmented to add MachineFunctionSplitter functionalities as well. If the analysis part of MachineOutliner can allow single basic block outlining with some cost models.
Sriraman Tallam via llvm-dev
On Wed, Aug 12, 2020 at 10:24 AM aditya kumar <hira...@gmail.com> wrote:> Just chiming in about the outliner stuff. (In general, I think it's desirable to have multiple options for how early/late a pass runs.)I'm wondering if MachineOutliner can be augmented to add MachineFunctionSplitter functionalities as well. If the analysis part of MachineOutliner can allow single basic block outlining with some cost models.The MachineOutliner and MachineFunctionSplitter target orthogonal use cases. Namely, the MachineOutliner optimizes for binary size while the MachineFunctionSplitter optimizes for performance. Attempting to reconcile the differences to fully address the opportunity along both dimensions doesn't seem like a fruitful goal. Furthermore, the key to better performance is not only the timing of the MachineFunctionSplitter pass but also the extraction methodology, i.e. using basic block sections. Basic blocks sections is a nascent feature and needs more widespread use and rigorous testing before being incorporated with a mature, more widely used pass. Today, we only use basic block sections for x86 ELF targets.
There is an interesting follow on though -- can we use basicblock sections as the extraction methodology in MachineOutliner, thus lowering the overhead of outlining? This is something we can revisit once basic block sections is more mature.
Aditya KumarCompiler Engineer
Vedant Kumar via llvm-dev
Thanks for sharing this great write-up.
In past experiments, I found that splitting at the IR level (vs. at the codegen level) has a few drawbacks. You've discussed these, but just to recap:
- IR-level splitting is necessarily more conservative. This is to avoid inadvertently increasing code size in the original function due to the cost of materializing inputs/outputs to the cold callee (you refer to this as 'residue'). (As Aditya pointed out, some of the work re: splitting penalty hasn't been upstreamed yet -- I'll try to dust this off.)
- It cannot split out @eh.typeid.for intrinsics, a common feature in exception handling code (llvm.org/PR39545).
- It must be run very late in the pipeline. Splitting either before inlining, or shortly after, appears to regress performance across spec variants (with/without pgo, see D58258).
It's exciting to see this work, as it can side-step the first two issues. I'm not sure whether this is on your radar, but we do see some benefit from having the machine outliner run after IR-level splitting. I have not done a study of how this compares with partial inlining + late splitting, that could be interesting future work.
I haven't kept up to date on the work done to support basic block sections in debug info. I'll note that it was a challenge to fix up debug info after IR-level splitting (ultimately this was handled in D72795). I'm not sure whether any of that is transferable, but feel free to cc me on reviews if you think it is.
vedant
> On Aug 4, 2020, at 5:31 PM, Snehasish Kumar via llvm-dev <llvm...@lists.llvm.org> wrote:
>
> Greetings,
> We present “Machine Function Splitter”, a codegen optimization pass which splits functions into hot and cold parts. This pass leverages the basic block sections feature recently introduced in LLVM from the Propeller project. The pass targets functions with profile coverage, identifies cold blocks and moves them to a separate section. The linker groups all cold blocks across functions together, decreasing fragmentation and improving icache and itlb utilization. Our experiments show >2% performance improvement on clang bootstrap, ~1% improvement on Google workloads and 1.6% mean performance improvement on SPEC IntRate 2017.
> Motivation
> Recent work at Google has shown that aggressive, profile-driven inlining for performance has led to significant code bloat and icache fragmentation (AsmDB - Ayers et al ‘2019). We find that most functions 5 KiB or larger have inlined children more than 10 layers deep bringing in exponentially more code at each inline level, not all of which is necessarily hot. Generally, in roughly half of even the hottest functions, more than 50% of the code bytes are never executed, but likely to be in the cache.
>
> Function splitting is a well known compiler transformation primarily targeting improved code locality to improve performance. LLVM has a middle-end, target agnostic hot cold splitting pass as well as a partial inlining pass which performs similar transformations, as noted by the authors in a recent email thread. However, due to the timing of the respective passes as well as the code extraction techniques employed, the overall gains on large, complex applications leave headroom for improvement. By deferring function splitting to the codegen phase we can maximize the opportunity to remove cold code as well as refine the code extraction technique. Furthermore, by performing function splitting very late, earlier passes can perform more aggressive optimizations.
> Implementation
> We propose a new machine function splitting pass which leverages the basic block sections feature to split functions without the caveats of code extraction in the middle-end. The pass uses profile information to identify cold basic blocks very late in LLVM CodeGen, after regalloc and all other machine passes have executed. This allows our implementation to be precise in its assessment of cold regions while maximizing opportunity.
>
> Each function is split into two parts. The hot cluster includes the function entry and all blocks which are not cold. All the cold blocks are grouped together as a Cold Section cluster. With basic block sections, the cold blocks are assigned appropriate debug and call frame information and emitted as part of the .text.unlikely section. Unlike Propeller, which is presently the main user of the basic block sections feature, this pass does not require an additional round of profiling and uses existing instrumentation based FDO or CSFDO profile information.
>
Snehasish Kumar via llvm-dev
Hi Snehasish,
Thanks for sharing this great write-up.
In past experiments, I found that splitting at the IR level (vs. at the codegen level) has a few drawbacks. You've discussed these, but just to recap:
- IR-level splitting is necessarily more conservative. This is to avoid inadvertently increasing code size in the original function due to the cost of materializing inputs/outputs to the cold callee (you refer to this as 'residue'). (As Aditya pointed out, some of the work re: splitting penalty hasn't been upstreamed yet -- I'll try to dust this off.)
- It cannot split out @eh.typeid.for intrinsics, a common feature in exception handling code (llvm.org/PR39545).
- It must be run very late in the pipeline. Splitting either before inlining, or shortly after, appears to regress performance across spec variants (with/without pgo, see D58258).
It's exciting to see this work, as it can side-step the first two issues. I'm not sure whether this is on your radar, but we do see some benefit from having the machine outliner run after IR-level splitting. I have not done a study of how this compares with partial inlining + late splitting, that could be interesting future work.
I haven't kept up to date on the work done to support basic block sections in debug info. I'll note that it was a challenge to fix up debug info after IR-level splitting (ultimately this was handled in D72795). I'm not sure whether any of that is transferable, but feel free to cc me on reviews if you think it is.
vedant
Vedant Kumar via llvm-dev
On Aug 14, 2020, at 4:25 PM, Snehasish Kumar <sneha...@google.com> wrote:On Fri, Aug 14, 2020 at 2:22 PM Vedant Kumar <vedant...@apple.com> wrote:Hi Snehasish,
Thanks for sharing this great write-up.
In past experiments, I found that splitting at the IR level (vs. at the codegen level) has a few drawbacks. You've discussed these, but just to recap:
- IR-level splitting is necessarily more conservative. This is to avoid inadvertently increasing code size in the original function due to the cost of materializing inputs/outputs to the cold callee (you refer to this as 'residue'). (As Aditya pointed out, some of the work re: splitting penalty hasn't been upstreamed yet -- I'll try to dust this off.)
- It cannot split out @eh.typeid.for intrinsics, a common feature in exception handling code (llvm.org/PR39545).
- It must be run very late in the pipeline. Splitting either before inlining, or shortly after, appears to regress performance across spec variants (with/without pgo, see D58258).
It's exciting to see this work, as it can side-step the first two issues. I'm not sure whether this is on your radar, but we do see some benefit from having the machine outliner run after IR-level splitting. I have not done a study of how this compares with partial inlining + late splitting, that could be interesting future work.That's an interesting idea. Can you share more details about the benefit - is this a performance improvement you observe or better code size? Also what benchmarks was this observed on?