Is case insensitive entry, posible ?
11 views
Skip to first unread message

Pierre
Apr 28, 2021, 10:45:40 AM4/28/21
to link-grammar
Hello Linas,
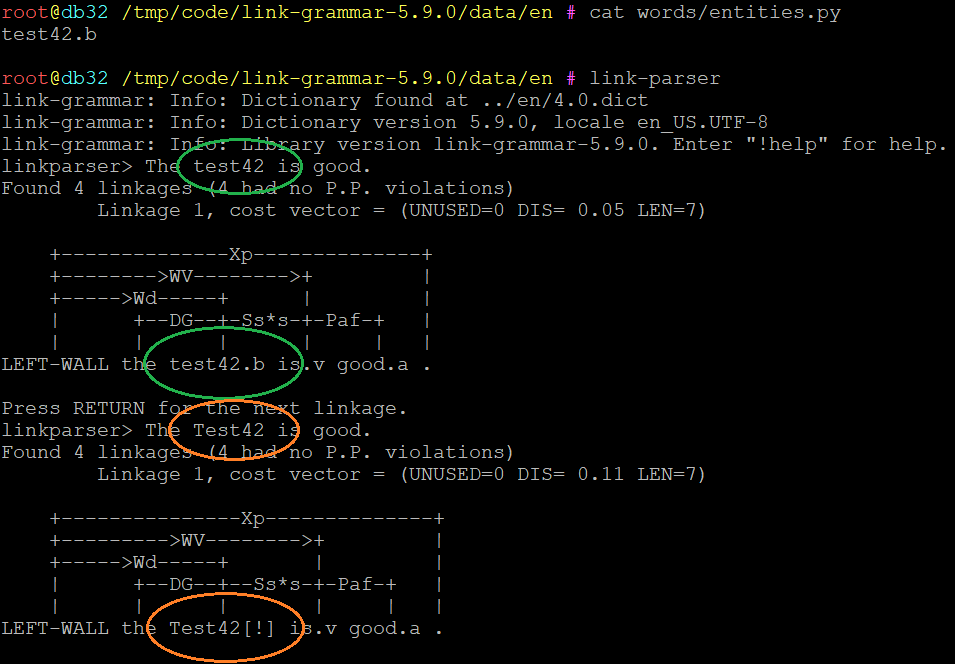
If i define "test42" (.b), then test42 is matched, but not Test42.
Is there a way to define "test42" in entry files (ex: test42.b-noncasesensitive ), so it is not case sensitive ? (so Test42 would also be matched in following example)
Thank you
py

Linas Vepstas
Apr 28, 2021, 11:43:24 AM4/28/21
to link-grammar
Salut Pierre,
No, there is nothing like this for words in the middle of sentences. Before the era of tweets, this did not make sense!
There has been a lot of effort placed into handling capitalization correctly, both at the start of sentences, and also for handling unknown words. An unknown word that is capitalized is treated as the name of something: it is not just a noun, but a named entity. An unknown word that is lower case is treated as a common noun. Erasing the distinction between these two lowers the parse quality.
-- Linas
--
You received this message because you are subscribed to the Google Groups "link-grammar" group.
To unsubscribe from this group and stop receiving emails from it, send an email to link-grammar...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/link-grammar/2344b8f3-a86e-40ec-8432-91cb84ad9703n%40googlegroups.com.
--
Patrick: Are they laughing at us?
Sponge Bob: No, Patrick, they are laughing next to us.

ami...@gmail.com
Apr 28, 2021, 4:33:04 PM4/28/21
to link-grammar
Hi Pierre,
<UNKNOWN-WORD>: /^[.,-]{4}[.,-]*$/
Note also that you can use the 4.0.regex file in order to define entities (among other things).
Here is an example, as a basic explanation of how to use this idea (you may need to refine it, and this may be a non-trivial work).
For the purpose of this example, suppose you want any word with a capital letter, that is not recognized otherwise, to be considered as an entity.
Furthermore, suppose you also want all words with an underscore in them to be considered as entities too.
To that end, define this in 4.0.regex the definition of <UNKNOWN-WORD>:
<ENTITY>: /[[:upper:]][^'’]*[^[:punct:]]$/ % Unknown words that contain an uppercase letter
<ENTITY>: /_*[^[:punct:]]$/ % Unknown words that contain an underscore
% ...<UNKNOWN-WORD>: /^[.,-]{4}[.,-]*$/
In the dictionary file add anywhere in the entity word list:
<ENTITY>
/en/words/entities.gods:
<marker-entity> or <given-names> or <directive-opener> or <directive-subject>;
(The [:punct:] stuff is for excluding word-ending punctuation so the regex would not swallow it.)
If you want that your regex entities would appear with the subscript .b, add <ENTITY>.b to the dictionary instead of just <ENTITY> (in the 4.0.regex file it should remain unsubscripted!).
You will get (I used !morphology to display the regex label):
linkparser> !morphology
Display word morphology turned on.
linkparser> This is an iPhone.
Found 8 linkages (8 had no P.P. violations)
Linkage 1, cost vector = (UNUSED=0 DIS= 2.00 LEN=6)
+------------------Xp------------------+
+----->WV----->+-----Oste----+ |
+-->Wd---+-Ss*b+ +--Ds**v--+ |
| | | | | |
LEFT-WALL this.p is.v an iPhone[!<ENTITY>] .
Press RETURN for the next linkage.
linkparser> The variable test_it is not initialized.
Found 26 linkages (26 had no P.P. violations)
Linkage 1, cost vector = (UNUSED=0 DIS= 2.05 LEN=13)
+--------------------------------Xp--------------------------------+
+------------------->WV------------------>+ |
+------------->Wd-------------+ | |
| +-----------D----------+ +-------Pa------+ |
| | +-------A------+----Ss*s---+-EBm+----EA----+ |
| | | | | | | |
LEFT-WALL the variable.a test_it[!<ENTITY>] is.v not.e initialized.v-d .
For defining really complex pattern matches, you would need to install the PCRE2 library (libpcre2-dev) and rebuild link-grammar.
To use it, see the manual of pcrepattern.
To check if the link-grammar library already uses it, do from the link-grammar source directory:
ldd link-grammar/.libs/liblink-grammar.so
and check for libpcre2-8.--
Amir
Pierre
Apr 29, 2021, 11:37:11 AM4/29/21
to link-grammar
Wow,
Thank you so much Amir for this clear and very usefull explanation.
You offer me many possiliblities doing so.
Reply all
Reply to author
Forward
0 new messages