why does chenard carries errors with a reproducible aligment file?

Ingrid Schockaert
I’m testing the chenard algoritm for small
numbers, using the data for flanders from 308 municipalities, by age and sex
(308*105*2). The test is to see up to what size of municipality, chenard works
well enough to reproduce the number of emigrants by age and sex in the
alignment file.
I first wanted to establish a baseline: the “perfectly reproducible alignment file” by age and sex. I did that by running an alignment file from observed migration data. Then I took the resulting migrations by age and sex produced by the chenard algoritm and reïntroduced that in the model as the perfectly reproducible aligment file. I figured that the “number of individuals missing” should be zero. But this was not the case. From the 278181 emigrants in the alignment file (total needed), 2452 were not aligned (missing individuals). I don’t understand why; I kept the same random seed (1000) and eliminated the random element from the algoritm (is_candidate: uniform () >0.0)
Here is the code:
Houshold level:
select_int_emigrants:
- migrant_pool: FALSE
- num_persons: persons.count()
- int_migration_targets: load('migration1.csv', type=int)##migration1.csv is an alignment file produced by the chenard algoritm.
- is_candidate: uniform () >0.0 #replace by immigration_score
- migrant_pool: align_abs(num_persons, int_migration_targets, filter=is_candidate, link=persons)
- show("migrant pool", sum(migrant_pool * num_persons))
- last_int_period: if(migrant_pool, period, 0) ### boolean/global
Individual level:
migrant_pool:
- int_migrated: FALSE
- int_migrated: household.migrant_pool
dump_info:
- csv(groupby(res_id,age, gender, filter=int_migrated),
fname='migration2.csv')
Thanks in advance for any help!
Ingrid

Gaëtan de Menten
That is expected (even if counterintuitive) when you know what's inside Chenard's algorithm. The algorithm could be summarized like this: for each household,
* compute a relative need (the maximum of the household persons relative needs – i.e. how badly we need each person to fill the "bin" he belongs to),
* use that relative need as a probability of being selected
Now, in your first "pass" (when you create migration1.csv), you probably do not have the same targets than those in the second pass (where you use migration1.csv) because of the "error" (unaligned individuals) produced by the algorithm in the first pass, so the relative needs are different and thus the households being selected in the end are different even if the "raw" random numbers are the same.
Hope it helps,
Gaëtan
--
You received this message because you are subscribed to the Google Groups "liam2-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to
liam2-users...@googlegroups.com.
To post to this group, send email to
liam2...@googlegroups.com.
Visit this group at https://groups.google.com/group/liam2-users.
Disclaimer: This e-mail may contain confidential information which is intended only for the use of the recipient(s) named above.
If you have received this communication in error, please notify the sender immediately and delete this e-mail from your system.
Please note that e-mail messages cannot be considered as official information from the Federal Planning Bureau.
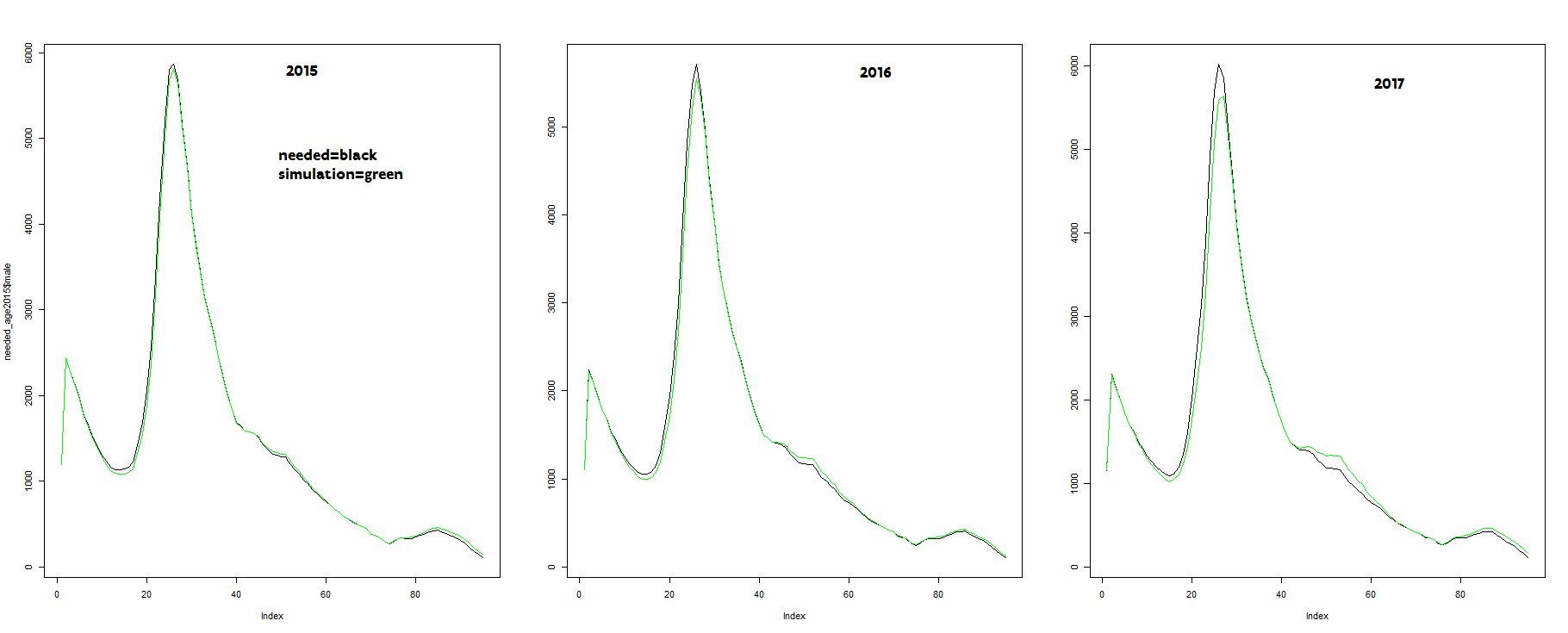
Ingrid Schockaert
-the alinged number of individuals by age (men), all municipalities confounded: black line
-the simulated number of individuals by age (men), all municipalities confounded: green line
We observe:
- a subestimated number of individuals between 15 and 30 and an overestimation of individuals between 40-60 and above 80.
- these biases increase considerably over time!
Do you have any idea why this is and what the solution might be?
{kind=link}
Gaëtan de Menten
Dear Ingrid,
I can only offer guesses. The subestimated and overestimated individuals might be due to how large (with more persons) households are selected first and I guess that in your dataset, larger households are more likely than average to contain individuals aged 40-60 and above 80, and less likely to contain individuals aged 15-50.
The growing problem might be due to either an aggravation of the above fact over time. If you plot total migrants but each period only compute new migrants, this could simply be due to a similar error in each period just accumulating over time.
Using align_abs(…, errors='carry') (which adjusts the targets automatically with the error of the last period) might help lower this problem (if you are in the second case).
Ingrid Schockaert
- household:
- select_int_emigrants:
- num_persons: persons.count()
- is_candidate: uniform () >0.0 #replace by immigration_score
- migrant_pool: align_abs(num_persons, int_migration_targets, filter=is_candidate, link=persons)
- person:
- migrant_pool:
- int_migrated: household.migrant_pool
- csv(groupby(res_id,age, gender, filter=int_migrated),
fname='simulation_{period}.csv',mode='a')
- csv(groupby(res_id, gender, filter=int_migrated),
fname='simulation_res_id_{period}.csv',mode='a')
- csv(groupby(age, gender, filter=int_migrated),
fname='simulation_age_{period}.csv',mode='a')
- csv(groupby(gender, filter=int_migrated),
fname='simulation_gender_{period}.csv',mode='a')
processes:
- person: [ageing, birth, agegroup, death]
- household: [select_int_emigrants]
- person: [migrant_pool, dump_info]
To unsubscribe from this group and stop receiving emails from it, send an email to liam2-users+unsubscribe@googlegroups.com.
To post to this group, send email to liam2...@googlegroups.com.
Visit this group at https://groups.google.com/group/liam2-users.
Disclaimer: This e-mail may contain confidential information which is intended only for the use of the recipient(s) named above.
If you have received this communication in error, please notify the sender immediately and delete this e-mail from your system.
Please note that e-mail messages cannot be considered as official information from the Federal Planning Bureau.
--
You received this message because you are subscribed to a topic in the Google Groups "liam2-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/liam2-users/m1Iq7DPxCzk/unsubscribe.
To unsubscribe from this group and all its topics, send an email to liam2-users+unsubscribe@googlegroups.com.
Ingrid Schockaert
- num_persons: persons.count()
- int_migration_targets: load('int_migration_targets.csv', type=int)
- is_candidate: uniform () >0.0 #replace by immigration_score
adding 4597 individuals from last period error
ERROR: operands could not be broadcast together with shapes (308,95,2) (307,95,2) (308,95,2)
when evaluating: align_abs(household.num_persons, household.int_migration_targets, errors='carry', filter=household.is_candidate, link=One2Many(persons, hh_id, person))
Regards,
Ingrid
Gaëtan de Menten
Oops. This is a bug in the errors='carry' feature: it does not support the case where the "categories" are different from the previous period. I did not think about that case when I implemented the feature and it never occurred in our own models.
Sadly, it would be extremely difficult to fix in the current stable release (0.12) because that version does not include the foundations necessary to fix this (to be able to make the correspondence between two arrays by using labels instead of positions). This should be easier to fix with the next (0.13) release but that release is far from being ready.
I don't know what your "308" axis is (municipality?) but it seems like you have one less in one of the periods. Maybe you could investigate why that happens. It does not seem normal and it would probably help other parts of your code to fix this anyway.
Gaëtan
--
You received this message because you are subscribed to a topic in the Google Groups "liam2-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/liam2-users/m1Iq7DPxCzk/unsubscribe.
To unsubscribe from this group and all its topics, send an email to liam2-users...@googlegroups.com.
To post to this group, send email to liam2...@googlegroups.com.
Visit this group at https://groups.google.com/group/liam2-users.
--
You received this message because you are subscribed to the Google Groups "liam2-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to
liam2-users...@googlegroups.com.
To post to this group, send email to
liam2...@googlegroups.com.
Visit this group at https://groups.google.com/group/liam2-users.