all-against-all vs one-against-all

Bettina Halwachs
Hi,
I wonder if I understood the difference between the more strict all-against-all and the one-against-all feature detection mode of LefSe correctly. Image 3 groups, no subgroups, A, B, and C. For the all-against-all I would say a feature has to be differentially abundant between all the 3 groups. Eg. Feature X is detected if it is differentially abundant in A compared to B, in A compared C, AND in B compared to C.
In contrast for one against all: Feature X is detected if it is differentially abundant in A compared to B, and A compared to C BUT NOT in B compared to C.
I'm not sure if this is really correct maybe somebody can help me to clarify the difference.
Thank you already in advance for your help.
Kind regards,
Bettina

Nicola Segata
Bettina Halwachs
Thanks a lot for your reply and for your confirmation of my hypothesis about the difference between the two LEfSe modes. However, this brings me now a little bit in trouble because I’ve the following scenario which does not meet the described behavior.
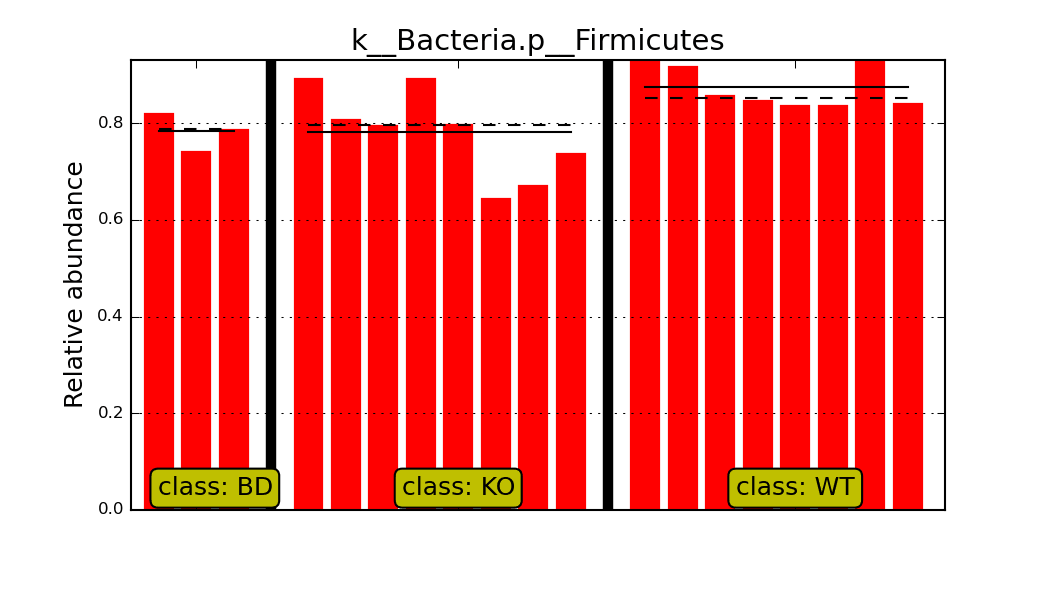
Briefly: I tried to compare the features of three different groups (no subgroups), WT, KO, and BD (Analysis performed with LEfSe on the Huttenhower galaxy server), using the all-against-all mode. Firmicutes are reported as significantly different (p-val < 0.05), with an LDA > 2.0 for WT compared to KO, and BD. Well, according to all-against-all this means that the Firmicutes are also significantly different between KO and BD, with the highest abundance in WT. BUT this is not supported by the pairwise LEfSe analysis of KO vs BD. Firmicutes are not detected as significantly different between KO and BD in the pairwise comparison. In addition LEfSe’s plot one feature analysis for Firmicutes resulted in very similar means/medians for and KO. Which is does not indicate for a difference between these two groups. (Hope this was not to confusing.) I’ve attached the LDA feature analysis result for the comparison of all 3 groups, the pairwise comparison of KO and BD, as well as the result of plot one feature for the Firmicutes.
I appreciate any ideas which helps us to explain/understand these results? Thanks a lot.
Don’t hesitate to contact me in case you need more details on the analysis parameters or any other additional information which may help you.
Kind regards,
Bettina

jfg
- compare X --> A
- compare X --> B
- compare X --> C
Bettina Halwachs
Thank you very much for this very detailed explanation and for the very helpful examples. This helps me a lot.
Kind regards,
Bettina

Lokesh J
Thank you for the nice explanation I have a few question thogh
1. How to select a particular group to be compared to the rest. Like in the example you gave how do you select X as a sort of reference group when using lefse on galaxy?
2. why the second scenario is considered as strict when it gives the same result as the first one (i.e compare X --> A). I was expecting that the second one is strict because a feature will be significant only if it is significantly different in all the comparisons involving X.
Like
compare X --> A - compare X --> B - compare X --> C
3. in the second scenario how could i know that a feature is significantly abundant in A only when compared to C and not when compared to B ?
jfg
- Only compare your A and C! Use a One-Against-All test, organising the subjects and classes in your original dataframe so that they appear in A) Format Data for LEfSe > Select which row to use as class: / Select which row to use as subject.
- Or do an All-Versus-All test, automatically comparing A-->B, A-->C, B-->C, etc.

{kind=link}
Samantha
Samantha