
Joseph Watson
Dear all,
In attempting to use SEM as part of an impact evaluation process, I found that my model gives differing results (for unstandardised regression estimates and p-values) depending on the position in which manifest variables are stated. (Std.all and std.lv results remain constant.)
A previous forum post (https://groups.google.com/forum/#!topic/lavaan/aI6dXkbStaQ) states that "You should use unstandardized coefficients for making inferences about a null hypothesis, and use standardized coefficients as a standardized measure of effect size".
So, as using unstandardized coefficients (and their associated p-values) for making inferences about a null hypothesis is dependent on the order in which manifest variables are stated within lavaan, is there a rule as to the order in which they should be stated? (e.g., should you state the manifest variable with the highest Std.all loading onto its latent variable first)?
Thank you so much again, and huge apologies if I have missed this in lavaan help.
Joe

Edward Rigdon
--
You received this message because you are subscribed to the Google Groups "lavaan" group.
To unsubscribe from this group and stop receiving emails from it, send an email to lavaan+un...@googlegroups.com.
To post to this group, send email to lav...@googlegroups.com.
Visit this group at https://groups.google.com/group/lavaan.
For more options, visit https://groups.google.com/d/optout.
Joseph Watson
Of course -
Evidence of the problem and my model specification is provided below:
'exp' manifest variables ordered one way (1)

'exp' manifest variables ordered another way (2)
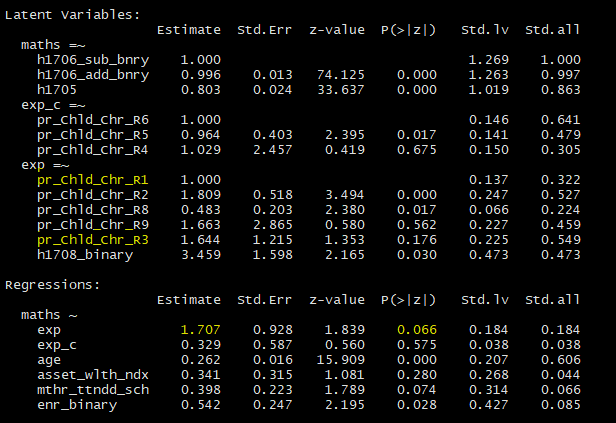
This shows how changing the order of manifest variables within the latent, 'exp', alters undstandardised regression coefficients and (more importantly) p-values. Std.all remains the same.
The first image was produced using the following model:
maths.pri_model <- 'maths =~ h1706_sub_binary + h1706_add_binary + h1705
exp_c =~ pri_Child_Char_Rec6 + pri_Child_Char_Rec5 + pri_Child_Char_Rec4
exp =~ pri_Child_Char_Rec3 + pri_Child_Char_Rec2 + pri_Child_Char_Rec8 + pri_Child_Char_Rec9 + pri_Child_Char_Rec1 + h1708_binary
maths ~ exp + exp_c + age + asset_wealth_index + mother_attended_school + enr_binary'
maths.prifit <- cfa(model = maths.pri_model, data = Uwezo6plus_primary, ordered = c("h1705", "h1706_add_binary", "h1706_sub_binary", "h1708_binary"))
summary(maths.prifit, standardized = T, fit.measures = T)
Thanks again