
Joseph Watson
Dear all,
I am a first-time poster. Apologies for any errors, and please let me know if I need to change the format of this message including code images.
I am attempting to mimic a cross-section regression model in lavaan, but with a latent dependant variable formed of three manifest variables. (No more manifest variables are available for the latent.) The key purpose of the initial regression model/lavaan model is to investigate the impact on maths outcomes/ability of an intervention (represented by the variable h1708_binary) amongst approx. 25,000 6-11 year olds in Tanzania. The regression model is produced as follows, with h1705_binary (a binary maths outcome variable) being predicted by binary outcome measures for Kiswahili (h1701_binary), English (h1703_binary) and other independent variables:
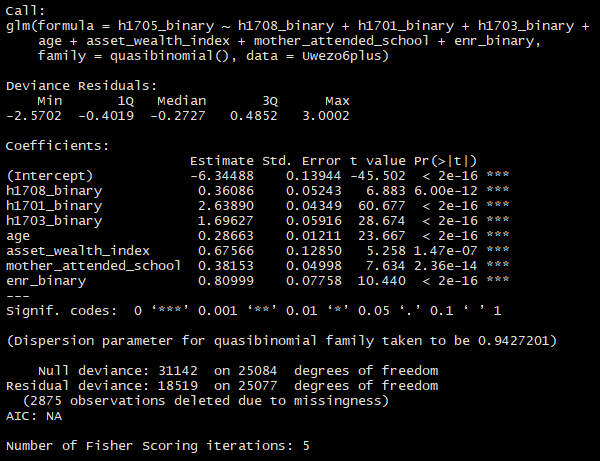
logisticmodel <- glm(h1705_binary ~ h1708_binary + h1701_binary + h1703_binary + age + asset_wealth_index + mother_attended_school + enr_binary, family = quasibinomial(), data = Uwezo6plus)
Results are below if helpful.
In the lavaan model, I essentially expand my dependent variable to become a latent variable formed of one 5-level (1-6) (h1705) and two binary (0-1) (h1706_add_binary and h1706_sub_binary) ordered variables.
This maths latent on its own functions well (with a CLI and TLI of 1 and an RMSEA and SRMR of 0), in spite of a high level of correlation between the two h1706 variables. (I do not believe that I can make changes in the model as it is just specified, due to the lack of available manifest variables.)
Incorporating this maths latent in a regression model mirroring my glm model is done as follows.
maths.lbmodel <- 'maths =~ h1706_add_binary + h1706_sub_binary + h1705
maths ~ h1708_binary + h1701_binary + h1703_binary + age + asset_wealth_index + mother_attended_school + enr_binary'
maths.lbfit <- cfa(model = maths.lbmodel, data = Uwezo6plus, ordered = c("h1705", "h1706_add_binary", "h1706_sub_binary")) #fit model
Results and an image of the model are below if helpful.
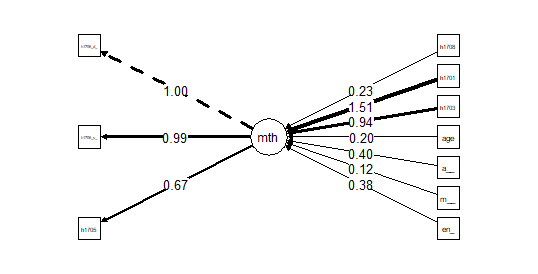
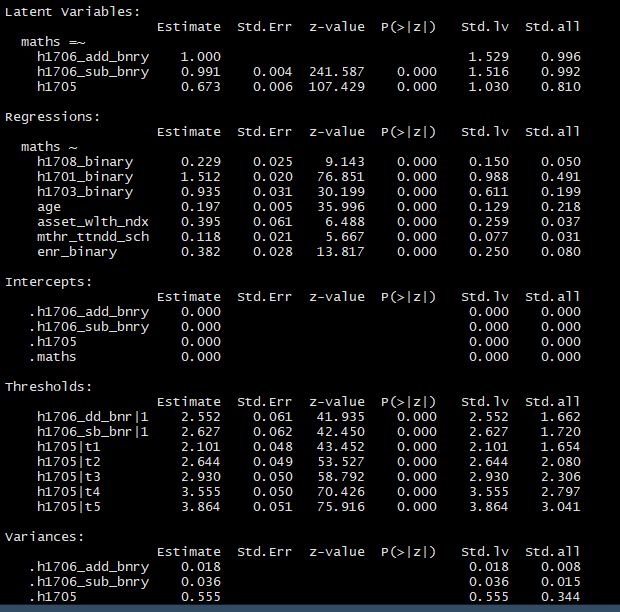
Results appear logical, although fit measures are less good for SRMR, RMSEA, CFI and TLI, which are 0.063 0.081 0.996 and 0.999 respectively. The R2 for maths is 0.56
My questions are:
1. Is using SEM in this manner to establish impact viable (and are there any working examples of SEM being used to ‘mimic’ regression in this manner, within education or any other field)?
2. Am I correct in thinking that responses to previous posts remain correct: a model with a latent variable of ordered manifest variables cannot function through lavaan.survey? Applying survey weights to the model through lavaan.survey shifts the estimator to ML. And, specifying the DWLS estimator returns multiple errors (in spite of this model functioning without survey weights). (If helpful, code is provided below.)
maths.w_lbfit <- lavaan.survey::lavaan.survey(lavaan.fit=maths.lbfit, survey.design = Uwezo6plus.design) #uses ML estimator (which ignores the ordered nature of manifest variables for 'maths')
maths.w_lbfit <- lavaan.survey::lavaan.survey(lavaan.fit=maths.lbfit, survey.design = Uwezo6plus.design, estimator = "DWLS") #specifying additional argument to alter estimator from default (ML) returns errors only
Any responses to this post would be hugely appreciated.
Joe
Post tags: ordered, DWLS, lavaan.survey, impact (could not select when posting, sorry.)

Terrence Jorgensen
1. Is using SEM in this manner to establish impact viable (and are there any working examples of SEM being used to ‘mimic’ regression in this manner, within education or any other field)?
2. Am I correct in thinking that responses to previous posts remain correct: a model with a latent variable of ordered manifest variables cannot function through lavaan.survey?
?lavaan