las to Oracle Spatial
271 views
Skip to first unread message

Monika Pencierzyńska
Feb 22, 2015, 8:44:51 AM2/22/15
to last...@googlegroups.com
Hi,
I'm looking for a good and efficient solution to load las data to Oracle Spatial. I need it to do my thesis about processing big spatial data in Oracle Spatial.
Thank you for any advice!
Regards,
Monika
I'm looking for a good and efficient solution to load las data to Oracle Spatial. I need it to do my thesis about processing big spatial data in Oracle Spatial.
Thank you for any advice!
Regards,
Monika

Oscar Martinez Rubi - BK
Feb 22, 2015, 4:27:53 PM2/22/15
to last...@googlegroups.com
Hi,
There are different ways to load point clod data in oracle.
PDAL has a plugin for that purpose that will create kdtree-like blocks independently for each file. But i am not managing to make it work (see pdal mail list)
Then oracle also has native ways to load point clouds with external tables. See the reports in pointclouds.nl or our recent paper in computer and graphics (http://www.sciencedirect.com/science/article/pii/S0097849315000084) for more info on those methods.
Two methods exist within oracle: rtree-like and hilbert blocking.
What amount of pointcloud you want to load?
Regards
O.
Enviado de Samsung Mobile
-------- Mensaje original --------
De: Monika Pencierzyńska
Fecha:22/02/2015 14:54 (GMT+01:00)
Para: last...@googlegroups.com
Asunto: [LAStools] las to Oracle Spatial
--
Download LAStools at
http://lastools.org
http://rapidlasso.com
Be social with LAStools at
http://facebook.com/LAStools
http://twitter.com/LAStools
http://linkedin.com/groups/LAStools-4408378
Manage your settings at
http://groups.google.com/group/lastools/subscribe
Download LAStools at
http://lastools.org
http://rapidlasso.com
Be social with LAStools at
http://facebook.com/LAStools
http://twitter.com/LAStools
http://linkedin.com/groups/LAStools-4408378
Manage your settings at
http://groups.google.com/group/lastools/subscribe

Albert Godfrind
Feb 23, 2015, 4:46:47 AM2/23/15
to last...@googlegroups.com
Monika
I will add to Oscar’s response by saying that there are actually two ways to store point clouds in an Oracle database:
1) The blocked structure that Oscar describes. In this, the point cloud is broken down into blocks that each contain a set number of points. The distribution of points into the blocks can use a choice of techniques (rtree or hilbert like Oscar explained). Loading needs specific tools and processes (PDAL). Specific functions (stored procedures) allow you to clip out various sections of a point cloud for detailed analysis.
2) The flat-table structure: in this, the points are stored in simple relational tables where each tuple is a point with all its attributes. The table structure is much simpler - being plainly relational. But it is really best used on our engineered systems platforms (i.e. Exadata, a database machine). It comes with intelligent storage that provides index-less filtering at the storage-block level together with columnar-compression that massively reduces storage costs.
To test any of this, you should use the latest Oracle database release (12c). On the Oracle technology web site (otn.oracle.com) you will find ready-for use virtual machines with everything pre-installed.
Albert
--

Albert Godfrind | Geospatial technologies | Tel: +33 4 93 00 80 67 | Mobile: +33 6 09 97 27 23 | Skype: albert-godfrind
Oracle Server Technologies
400 Av. Roumanille, BP 309 | 06906 Sophia Antipolis cedex | France
Everything you ever wanted to know about Oracle Spatial
Albert Godfrind | Geospatial technologies | Tel: +33 4 93 00 80 67 | Mobile: +33 6 09 97 27 23 | Skype: albert-godfrind
Oracle Server Technologies
400 Av. Roumanille, BP 309 | 06906 Sophia Antipolis cedex | France
Everything you ever wanted to know about Oracle Spatial
Monika Pencierzyńska
Feb 23, 2015, 4:50:08 AM2/23/15
to last...@googlegroups.com, o.marti...@tudelft.nl
Thank you for an answer. I have files that have about 80GB. My goal is to load it to Oracle and do some analysis on this data - check time of processing, querying, do some optimization, etc. I will check the solutions you proposed.
Regards,
Monika

Martin Isenburg
Feb 28, 2015, 8:57:08 PM2/28/15
to LAStools - efficient command line tools for LIDAR processing
Hello,
for a typical read-only LiDAR database that responds to user queries
that are square, rectangular or circular area-of-interest queries in
the XY plane you should include a comparison with LAStools in your
studies. Move the entire 80 GB of LiDAR (tiles?) either as
uncompressed LAS or as compressed LAZ into one folder and then run
either
lasindex -i folder\*.las -cores 4
or
lasindex -i folder\*.laz -cores 4
now you have a simple file-based read-only data base that can be queried with
las2las -i folder\*.las -merged ^
-inside 627980 5402870 628050 5403020 ^
-o result1.laz
las2las -i folder\*.laz -merged ^
-inside_tile 627750 5402750 500 ^
-o result1.laz
Or even better via a front-end like Hugo Ledoux from TU Delft did it:
http://3dsm.bk.tudelft.nl/matahn
who uses open-layer, a Python-based server (Flask) and PostGIS to
store the tiles' boundaries and all the metadata. If you have such a
setup then you can let PostGIS do the intersection of tile boundaries
with area-of-interest query and hand only a '-lof list_of_files.txt'
to las2las as input that contains a list of those LiDAR file names
that are actually overlapping the query area ...
For such applications the speed and simplicity in setup, the high
storage efficiency, the excellent performance, and the price (you can
use all open source components) make it an interesting "minimal effort
spatial database" to compare Oracle with as done in the aforementioned
article by Oscar Martinez and team.
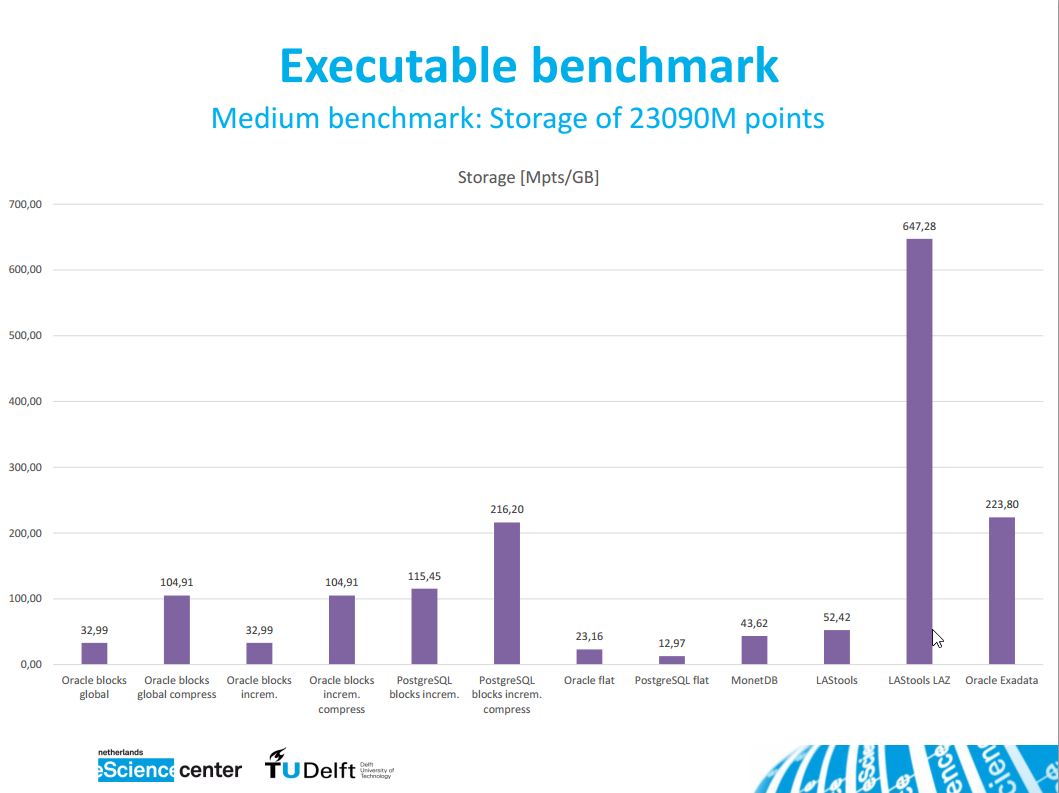
Below three of his SPAR/ELMF presentation slides that highlight the
performance results for the simple database case I describe above.
Regards,
Martin @rapidlasso
for a typical read-only LiDAR database that responds to user queries
that are square, rectangular or circular area-of-interest queries in
the XY plane you should include a comparison with LAStools in your
studies. Move the entire 80 GB of LiDAR (tiles?) either as
uncompressed LAS or as compressed LAZ into one folder and then run
either
lasindex -i folder\*.las -cores 4
or
lasindex -i folder\*.laz -cores 4
now you have a simple file-based read-only data base that can be queried with
las2las -i folder\*.las -merged ^
-inside 627980 5402870 628050 5403020 ^
-o result1.laz
las2las -i folder\*.laz -merged ^
-inside_tile 627750 5402750 500 ^
-o result1.laz
Or even better via a front-end like Hugo Ledoux from TU Delft did it:
http://3dsm.bk.tudelft.nl/matahn
who uses open-layer, a Python-based server (Flask) and PostGIS to
store the tiles' boundaries and all the metadata. If you have such a
setup then you can let PostGIS do the intersection of tile boundaries
with area-of-interest query and hand only a '-lof list_of_files.txt'
to las2las as input that contains a list of those LiDAR file names
that are actually overlapping the query area ...
For such applications the speed and simplicity in setup, the high
storage efficiency, the excellent performance, and the price (you can
use all open source components) make it an interesting "minimal effort
spatial database" to compare Oracle with as done in the aforementioned
article by Oscar Martinez and team.
Below three of his SPAR/ELMF presentation slides that highlight the
performance results for the simple database case I describe above.
Regards,
Martin @rapidlasso
{kind=link}
{kind=link}
{kind=link}
Oscar Martinez Rubi - BK
Mar 1, 2015, 5:03:37 AM3/1/15
to last...@googlegroups.com
Hi,
We have made available all the scripts to load data in Oracle, Postgres, MonetDb and LASTools in
For the procedure described by Martin you can use the LASTools loader in there which uses lassort (very recommended for best performance) and lasindex all in parallel and also takes cares of adding the tiles boundaries in Postgis db). For that part of
the code look at:
In that repo there are also the loading procedures for the other dbs that we explored (for oracle the pdal loader is still giving me some issues so it is not yet there).
Regards
O.
Enviado de Samsung Mobile
-------- Mensaje original --------
De: Martin Isenburg
Fecha:01/03/2015 02:57 (GMT+01:00)
Para: LAStools - efficient command line tools for LIDAR processing
Asunto: Re: [LAStools] las to Oracle Spatial
Martin Isenburg
Mar 1, 2015, 5:09:31 AM3/1/15
to LAStools - efficient command line tools for LIDAR processing
Great!!!
But I immediately noticed one serious bug: the capitalization of LAStools is wrong ... (-:
Martin
Reply all
Reply to author
Forward
0 new messages