Working with 2D arrays in the dataframe of lyse

Fabian Lenz
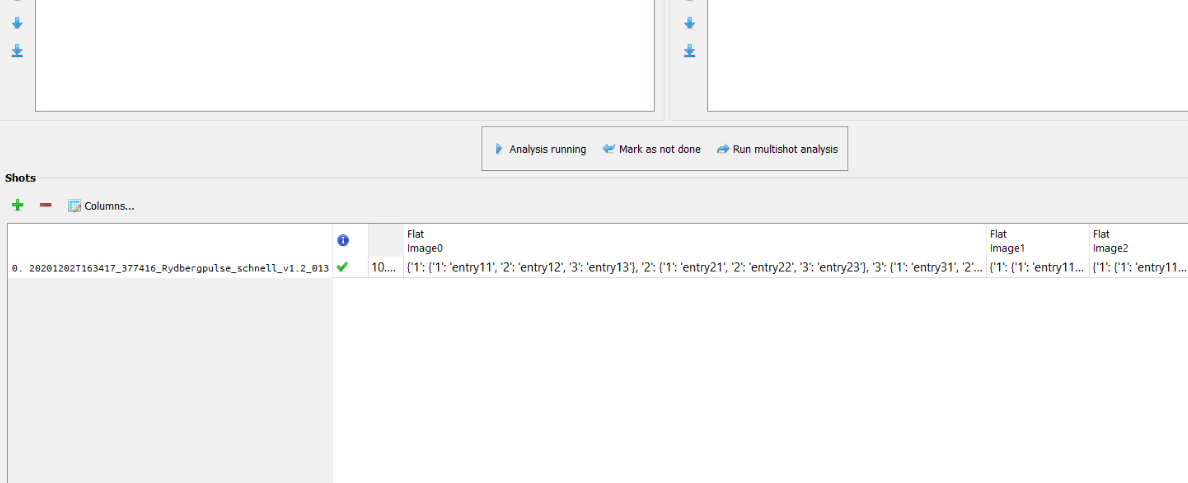
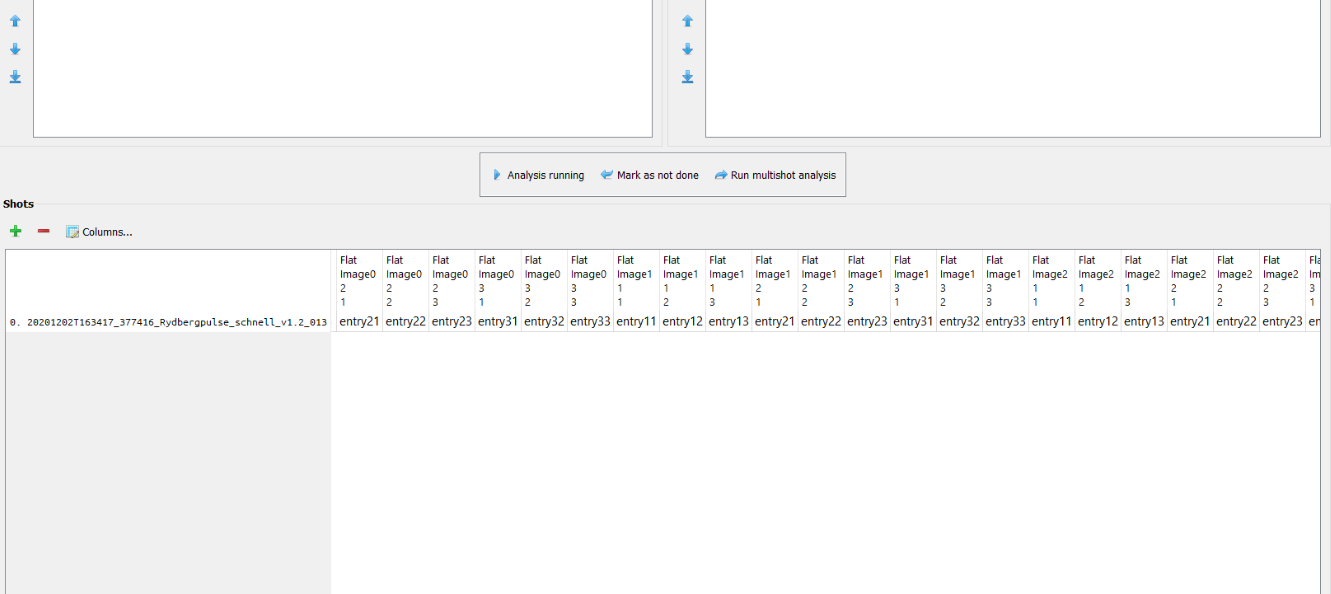
After removing the shot and re-adding it, the dataframe got generated in the form I was hoping to:

Zak V
Fabian Lenz
Hi Zak,
Thank you for your answer. While playing around a little and testing different approaches, I found that there is a routine_storage Object, an instance of the Class _RoutineStorage(Object) declared in the __init__.py of lyse, that is empty.
My approach is now to perform all time-costly computations like flattening the dataframe, filtering and grouping only once, and then saving all intermediate results to the routine_storage. When running the script again, it loads everything from the storage and skips all deselected computations.
The advantage is that small changes take only milliseconds when rerunning the routine.
The bug when saving dictionaries still consists though. For my approach in using the routine_storage this does not cause any trouble, so I am fine with that. But I guess in a future version of lyse it would be better to fix this. The cause is probably, that results from a routine do not use the methods in dataframe_utilities.py but some others in the __main__.py of lyse that must work differently.
Cheers,
Fabian