SRMSG00034: Insufficient downstream requests to emit item
58 views
Skip to first unread message

Roberto Lopez
Feb 15, 2023, 4:40:52 AM2/15/23
to Kogito development mailing list
Hi team!
I am configuring a kogito application with kafka.
I have a process that communicates through events with other processes through messages.
When performing load tests, one of the processes seems to not support the default configuration and throws the exception:
SRMSG00034: Insufficient downstream requests to issue item
I understand that this is because I need to configure something to extend the Kafka buffer but I don't know exactly how to do it with koguito/quarkus.
Could you tell me what parameter I need to put in the application.properties to configure the overflow strategy or similar?
Thank you very much in advance!
I am configuring a kogito application with kafka.
I have a process that communicates through events with other processes through messages.
When performing load tests, one of the processes seems to not support the default configuration and throws the exception:
SRMSG00034: Insufficient downstream requests to issue item
I understand that this is because I need to configure something to extend the Kafka buffer but I don't know exactly how to do it with koguito/quarkus.
Could you tell me what parameter I need to put in the application.properties to configure the overflow strategy or similar?
Thank you very much in advance!

Francisco Javier Tirado Sarti
Feb 15, 2023, 6:21:42 AM2/15/23
to kogito-de...@googlegroups.com
Hi Roberto,
As explained here https://quarkus.io/blog/reactive-messaging-emitter/, the emitter buffer is overloaded. That happens when the emitter emits at a ratio much faster than the consumer.
So, the first question is if in your scenario Kogito is both the emitter and the consumer, which will mean one process is publishing events much faster than the other process is processing them. This is interesting for us because we would like to know why the producer is much faster than the consumer.
Besides checking if there is a problem in the consumer (we need more details on that particular test to determine that) one easy solution to avoid the exception is to modify the test to produce events slowly. The alternative approach is to increase buffer size or use an unbounded buffer (this basically means more memory for the emitter process). Currently in Kogito we are not using OnOverflow annotation when generating Emitter code. I'm checking with quarkus folks if there is a channel property to specify the buffer size. I assumed, when developing the code, that there was one, but it seems there is not, so we probably need to create a JIRA to allow users to specify the size of the emitter buffer.
Thanks
--
You received this message because you are subscribed to the Google Groups "Kogito development mailing list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to kogito-developm...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/kogito-development/93635bcc-450b-4f12-aca1-23e3b8dd4bdan%40googlegroups.com.
Francisco Javier Tirado Sarti
Feb 15, 2023, 6:44:07 AM2/15/23
to kogito-de...@googlegroups.com
I forgot to add the link to the different strategies for OnOverflow. https://smallrye.io/smallrye-reactive-messaging/3.14.0/concepts/emitter/#overflow-management
Quarkus folks already confirmed that there is not alternative to OnOverflow, there are not plans to configure that behaviour through properties, so I'll be adding a JIRA to create a set of kogito specific properties to support different overflow strategies.
Something like that "kogito.addon.messaging.<inconming|outgoing>.<channelName>.onOverflow"
Roberto Lopez
Feb 15, 2023, 6:50:26 AM2/15/23
to Kogito development mailing list
Hello Francisco!
Thanks for such a quick response.
In principle these processes are all carried out with kogito. They are microprocesses that call each other through events.
In this graph I show with arrows the communication between processes. These communications are with kafka.
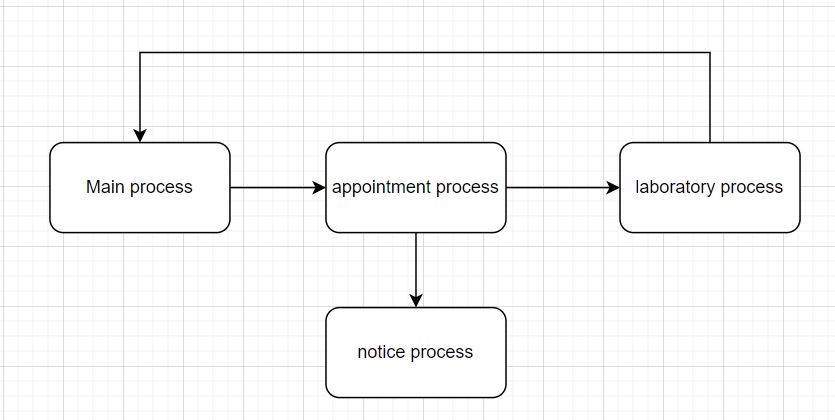
The main process is more complex and the one that receives the requests and is where the errors are jumping above all. the other processes are simpler and respond more quickly.
In the test case that I am carrying out, I am using JMeter and I am stressing the process with a lot of requests (I have attached a screenshot of the jmeter results)
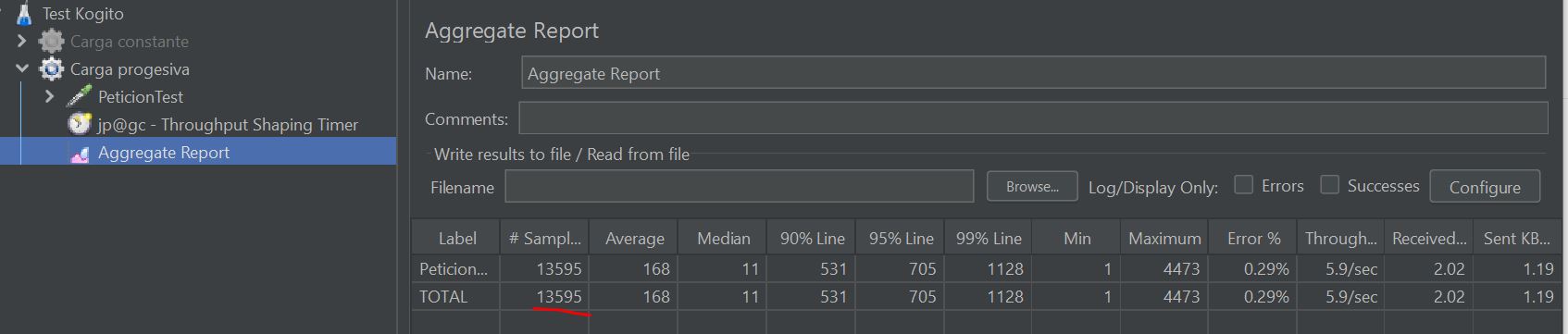
As you say, it may be happening that this main process is receiving many requests from Jmeter, on the other hand it has to send requests to other microprocesses and these in turn send requests to the main process again, which it must read and process.
So as you comment, could you tell me what limitation kogito has so far? I mean the number of kafka requests that it is capable of reading.
As you say, wouldn't it be possible to increase the buffer?
If not, what could be the solution?
Thanks for such a quick response.
In principle these processes are all carried out with kogito. They are microprocesses that call each other through events.
In this graph I show with arrows the communication between processes. These communications are with kafka.
The main process is more complex and the one that receives the requests and is where the errors are jumping above all. the other processes are simpler and respond more quickly.
In the test case that I am carrying out, I am using JMeter and I am stressing the process with a lot of requests (I have attached a screenshot of the jmeter results)
As you say, it may be happening that this main process is receiving many requests from Jmeter, on the other hand it has to send requests to other microprocesses and these in turn send requests to the main process again, which it must read and process.
So as you comment, could you tell me what limitation kogito has so far? I mean the number of kafka requests that it is capable of reading.
As you say, wouldn't it be possible to increase the buffer?
If not, what could be the solution?
Francisco Javier Tirado Sarti
Feb 15, 2023, 6:59:41 AM2/15/23
to kogito-de...@googlegroups.com
Hi Roberto,
As explained in my second message, Im opening a JIRA to allow changing overflow strategy and buffer size in Kogito through properties (Quarkus only allow use of annotation, since the emitter code is generated, you cannot directly use the annotation to configure the emitter)
The properties will be of the form
kogito.addon.messaging.<incoming|outgoing>.onOverflow.<channelName>.strategy=<OnOverflow annotation possible values for strategy>
kogito.addon.messaging.<incoming|outgoing>.onOverflow..<channelName>.size=<buffer size for buffer strategy>
Til this JIRA is implemented, you need to reduce your numbers.
To view this discussion on the web visit https://groups.google.com/d/msgid/kogito-development/1af1c47c-d0e6-40e6-8eb3-b2151aa2e5f8n%40googlegroups.com.
Roberto Lopez
Feb 15, 2023, 7:02:14 AM2/15/23
to Kogito development mailing list
Hello Francisco
If I just read it, sorry, I answered at the same time that you had answered.
okay. Well, I'm keeping an eye on this.
Thank you very much for your help!
If I just read it, sorry, I answered at the same time that you had answered.
okay. Well, I'm keeping an eye on this.
Thank you very much for your help!

mma...@redhat.com
Feb 15, 2023, 7:09:54 AM2/15/23
to kogito-de...@googlegroups.com
Hi Roberto,
I will just add that so far you can change the buffer size using the mp.messaging.emitter.default-buffer-size property.
Francisco Javier Tirado Sarti
Feb 15, 2023, 7:40:16 AM2/15/23
to kogito-de...@googlegroups.com
Thanks Marian.
I missed that when reading the Javadoc of OnOverflow
Roberto, since the default buffer size value is 128/256 (depending on which doc you read), you can try increasing it to 1024 and retry.
To view this discussion on the web visit https://groups.google.com/d/msgid/kogito-development/3a8c48dc5b7813e2d98cfa4a5e1ecad26737cccc.camel%40redhat.com.
Francisco Javier Tirado Sarti
Feb 15, 2023, 7:55:09 AM2/15/23
to kogito-de...@googlegroups.com
I created https://issues.redhat.com/browse/KOGITO-8676, with lower priority than the originally intended, since there is workaround through the usage of mp.messaging.emitter.default-buffer-size
Roberto Lopez
Feb 15, 2023, 8:12:46 AM2/15/23
to Kogito development mailing list
hi team!
thank you! it has worked for me.
At the moment I have had to increase the buffer a lot for that amount of requests. 1024 have fallen very short but it is a matter of adjusting.
I have been able to execute those requests without the buffer failure, but at the cost of increasing the memory a lot.
Thank you!
thank you! it has worked for me.
At the moment I have had to increase the buffer a lot for that amount of requests. 1024 have fallen very short but it is a matter of adjusting.
I have been able to execute those requests without the buffer failure, but at the cost of increasing the memory a lot.
Thank you!
Francisco Javier Tirado Sarti
Feb 15, 2023, 11:49:19 AM2/15/23
to kogito-de...@googlegroups.com
Yes, the other alternative to save memory, when the new functionality is ready will be to disable back pressure by choosing none strategy. My expectation in that case is that either you break Kafka or it works fine ;)
To view this discussion on the web visit https://groups.google.com/d/msgid/kogito-development/a1e44268-abb3-4fb4-ac3c-7e618f46b197n%40googlegroups.com.

Tiago Dolphine
Feb 15, 2023, 12:12:34 PM2/15/23
to kogito-de...@googlegroups.com
I'd say exactly this, maybe we could try to set the Emitter with @OnOverflow(value = OnOverflow.Strategy.NONE), in job-service we had a similar situation, and disabling buffer and backpressure had better results.
I think it is worth trying this and compare the results.
To view this discussion on the web visit https://groups.google.com/d/msgid/kogito-development/CABnrMOjz%2BY-gJwRLO5kestt%3D6Ek-xSdzn3BJj7EMfe0aW4ZAFA%40mail.gmail.com.
Francisco Javier Tirado Sarti
Feb 15, 2023, 4:24:44 PM2/15/23
to kogito-de...@googlegroups.com
Tiago, Marian and I were discussing today about this topic. Before I know the existence of mp.messaging.emitter.default-buffer-size, I was supporting using none as default strategy, but in order to be aligned as close as possible with smallrye, I think we should keep the buffer default (basically not adding the annotation if the user does not specify any kogito property), because if we add the annotation (without user explicitly telling us to do that) we were nullifying that Smallrye property, which I do not think is a good idea.
In any case, once we add the properties discussed in the JIRA, user can change that behaviour globally (this is not clear in the JIRA descirption, but it was my intention) or per channel (which internally will result in the annotations being added to the generated emitter class)
This way, If Smallrye eventually change the default, we will following their default. In this case, I prefer to be conservative for once ;)
wdyt?
To view this discussion on the web visit https://groups.google.com/d/msgid/kogito-development/CAPAWzdXs-W6hgFU2hXLV2MLbLVZdqCDO6y1qWT7GxsBwCLGcaA%40mail.gmail.com.
Tiago Dolphine
Feb 16, 2023, 5:39:08 AM2/16/23
to kogito-de...@googlegroups.com
Yeah, that's fine, we can even add the annotation at codegen based on some config property the user could optionally add, and keep the default SmallRye behavior.
To view this discussion on the web visit https://groups.google.com/d/msgid/kogito-development/CABnrMOgbQv3TbvjvinT39CXDV4v%3DsP9cJAVfEkUFk4fy2GwzgQ%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages