Multitask learning with missing outputs
200 views
Skip to first unread message

Niko Colnerič
Apr 13, 2016, 9:51:33 AM4/13/16
to Keras-users
I would like to train a multi task LSTM that would look like this: 
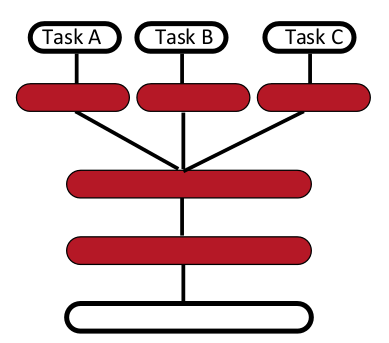
The common layer would contain an LSTM with three different softmax on top. All the LSTM layers should be the same for all the tasks (two common red layers on the image). After the final state of the LSTM, there are three different softmax layers, each for one task A, B, C. To put it another way, all weights, except the last softmax, should be the same for all three tasks. I imagine could be done with graph model; however, there is a catch. I am doing this on three different data sets, meaning that for each input example I only have labels for just one of the tasks. Therefore, I would like a way to update all the common layer and just one of the final softmax at a time. I tried doing this with three different Sequential models, to which I added the same layers like this:
emb_layer = Embedding(input_dim=embeddings.shape[0], output_dim=DIM, weights=[embeddings], trainable=TRAIN_WE)dwe_layer = Dropout(0.2)lstm_layer = LSTM(DH)dsm_layer = Dropout(0.5)# build modelsmodels = []for tY in train_Y: # for each of the three tasksm = Sequential()m.add(emb_layer)m.add(dwe_layer)m.add(lstm_layer)m.add(dsm_layer)m.add(Dense(tY.shape[1]))m.add(Activation('softmax'))m.compile(loss='categorical_crossentropy', optimizer='RMSprop')models.append(m)
After that, I train it for X epochs. Each of this epochs include the one epoch on each of the data sets:
for epoch in range(X):for m, tX, tY in zip(models, train_X, train_Y):m.fit(tX, tY, nb_epoch=1)
After some debugging it looks like that the upper approach keeps all the weights in sync throughout the training of all three models, however I am not completely sure. Will this approach really keep all LSTM layer weights in sync throughout the training? Will this also work ok on the GPU? Is there a batter way of doing this? Or more efficient on in terms of training time?
Reply all
Reply to author
Forward
0 new messages