JAccent (iOS App) - Japanese accent pronunciation dictionary - New app using KanjiVG
140 views
Skip to first unread message

Trinh DT
Jun 28, 2017, 7:50:14 PM6/28/17
to KanjiVG
Hello everyone,
Also, you can easily find opposite words, Japanese counter suffix, Japanese surname and so on.
Absolutely, you can use it daily for checking the meaning of the word.
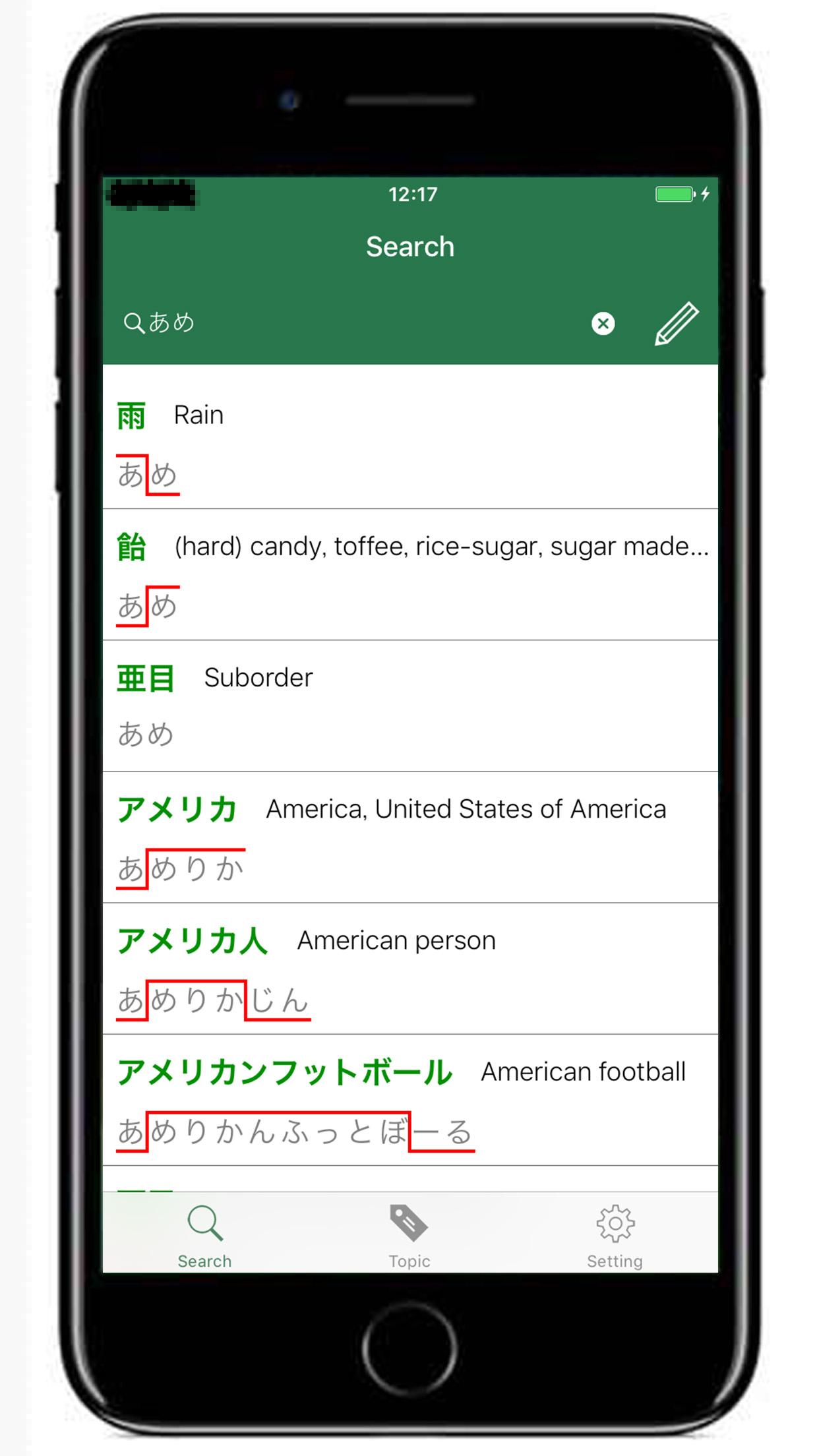
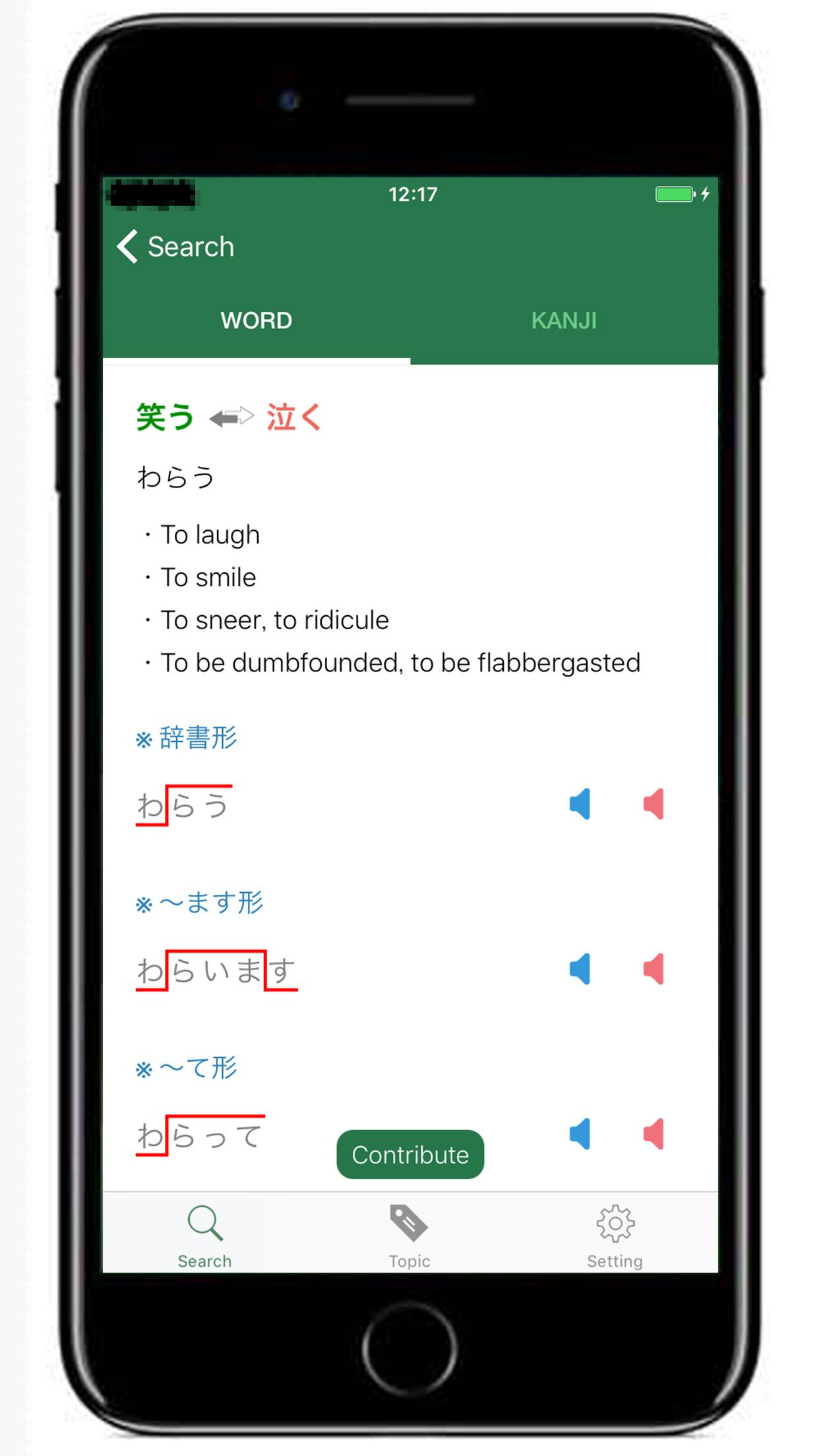
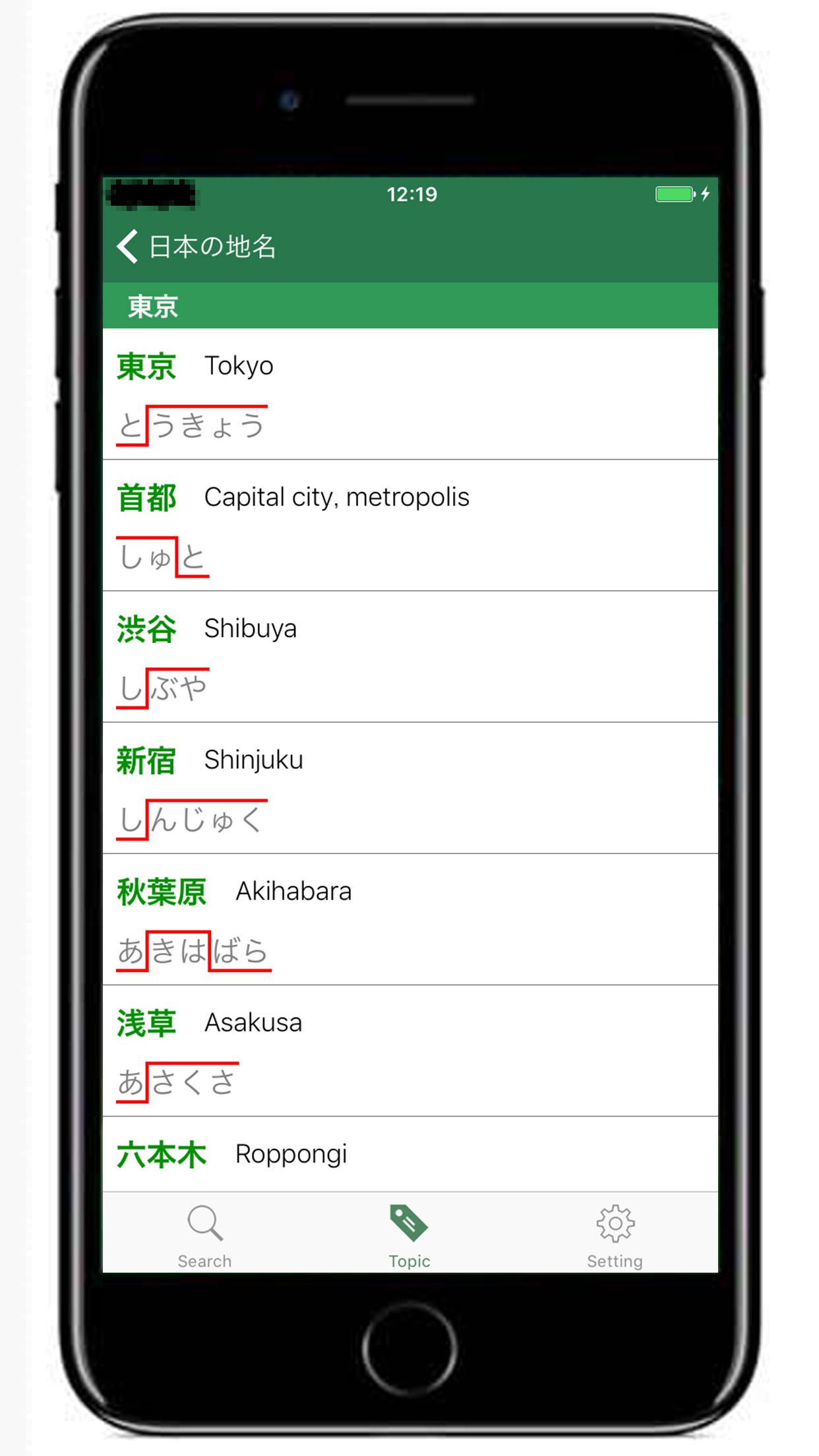
I've just released an iOS app - JAccent on the App Store.
JAccent is an offline Japanese accent dictionary for Japanese teachers and learners.
You can search for the Tokyo dialect accent, and you can also search for kanji's meaning.Also, you can easily find opposite words, Japanese counter suffix, Japanese surname and so on.
Absolutely, you can use it daily for checking the meaning of the word.
Thank you so much for KanjiVG and I've used it to display kanji's drawing in the app.
Here is the download link:
Thanks and best regards.

Tomash Brechko
Jun 29, 2017, 1:36:33 PM6/29/17
to KanjiVG
I was considering using accent data from OJAD for my Android app some time ago, but couldn't figure out their terms of use. The closest I found was last two sentences in the top frame at http://www.gavo.t.u-tokyo.ac.jp/ojad/eng/pages/notes , which ruled out the commercial use (which I targeted at that point), yet left me undecided about whether it's ok to use the data in the free app, or is it supposed to be used only through their site. I don't mean it as any kind of suspicion or rebuke, but did you have any luck finding their explicit terms of use, or did you ask some kind of permission from them, or clarified the matter in some other way? OJAD seems to be the only source of accent data, and their audio is also a valuable resource: though some of us privately use clips from JapanesePod101, alas they can't be used even in free apps, let alone paid.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ulrich Apel
Jun 30, 2017, 5:03:27 AM6/30/17
to kan...@googlegroups.com
The Japanese-German dictionary WaDokuJT contains data for accent and pronunciation, i.e. number for accent and kana plus mark-up which can together be transformed to IPA, phonetic or phonological transcriptions in kana or Rōmaji etc. The dictionary data can be used under the Creative Commons License with Attribution and Share Alike. In my file, about 130'000 records out of 325'000 contain accent information.
In most or at least many cases devocalized mora – like Asakusa where the u is dropped to become [a˹saku̥sa] in IPA – have corresponding mark-up. Similar mark-up is used for the mora ga, gi, gu, ge, go when they are not nasalized within a word, which is the case in many katakana loanwords. An example would be プログラム, and we have an online version of it as "puro’guramu" on http://wadoku.de/entry/view/98996. Further, は that is pronounced wa and へ that is pronounced e have also diacritical markup.
The data is available under https://github.com/Wadoku. This file is a little bit old, but we are working on a new version of the dictionary file, which should be available in autumn. There are two online versions of the dictionary: wadoku.eu and wadoku.de. Accent data is displayed at wadoku.de and a Rōmaji version can be found in a detail layout.
In my opinion too, Japanese pronunciation is important and not always as straight forward as learners of Japanese think. Unfortunately, our programmers were not interested in a decent rendering of the pronunciation details and we couldn't pay them for improvements. So. devocalisation never made to the user interface. Yes, there are rules for devocalisation, but it not always unambiguous. We have also audio data for the basic vocabulary spoken by a former TV announcer. An example would be はし with accent 1 or accent 2 on https://wadoku.eu/?query=%E3%81%AF%E3%81%97, but unfortunately the path to the audio files seems broken.
With the new version of the dictionary data, we hope to not only to fix the existing problems but use also to add stroke order data and will check for characters in the dictionary which are missing in KanjiVG. This means, that we hope to have also improvements to KanjiVG in the foreseeable future.
Best wishes
Ulrich
> Am 29.06.2017 um 19:36 schrieb Tomash Brechko <tomash....@gmail.com>:
>
> I was considering using accent data from OJAD for my Android app some time ago, but couldn't figure out their terms of use. The closest I found was last two sentences in the top frame at http://www.gavo.t.u-tokyo.ac.jp/ojad/eng/pages/notes , which ruled out the commercial use (which I targeted at that point), yet left me undecided about whether it's ok to use the data in the free app, or is it supposed to be used only through their site. I don't mean it as any kind of suspicion or rebuke, but did you have any luck finding their explicit terms of use, or did you ask some kind of permission from them, or clarified the matter in some other way? OJAD seems to be the only source of accent data, and their audio is also a valuable resource: though some of us privately use clips from JapanesePod101, alas they can't be used even in free apps, let alone paid.
>
> --
> --
> You received this message because you are subscribed to the "KanjiVG" group.
> For options and unsubscribing, visit this group at
> http://groups.google.com/group/kanjivg
> ---
> You received this message because you are subscribed to the Google Groups "KanjiVG" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to kanjivg+u...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
In most or at least many cases devocalized mora – like Asakusa where the u is dropped to become [a˹saku̥sa] in IPA – have corresponding mark-up. Similar mark-up is used for the mora ga, gi, gu, ge, go when they are not nasalized within a word, which is the case in many katakana loanwords. An example would be プログラム, and we have an online version of it as "puro’guramu" on http://wadoku.de/entry/view/98996. Further, は that is pronounced wa and へ that is pronounced e have also diacritical markup.
The data is available under https://github.com/Wadoku. This file is a little bit old, but we are working on a new version of the dictionary file, which should be available in autumn. There are two online versions of the dictionary: wadoku.eu and wadoku.de. Accent data is displayed at wadoku.de and a Rōmaji version can be found in a detail layout.
In my opinion too, Japanese pronunciation is important and not always as straight forward as learners of Japanese think. Unfortunately, our programmers were not interested in a decent rendering of the pronunciation details and we couldn't pay them for improvements. So. devocalisation never made to the user interface. Yes, there are rules for devocalisation, but it not always unambiguous. We have also audio data for the basic vocabulary spoken by a former TV announcer. An example would be はし with accent 1 or accent 2 on https://wadoku.eu/?query=%E3%81%AF%E3%81%97, but unfortunately the path to the audio files seems broken.
With the new version of the dictionary data, we hope to not only to fix the existing problems but use also to add stroke order data and will check for characters in the dictionary which are missing in KanjiVG. This means, that we hope to have also improvements to KanjiVG in the foreseeable future.
Best wishes
Ulrich
> Am 29.06.2017 um 19:36 schrieb Tomash Brechko <tomash....@gmail.com>:
>
> I was considering using accent data from OJAD for my Android app some time ago, but couldn't figure out their terms of use. The closest I found was last two sentences in the top frame at http://www.gavo.t.u-tokyo.ac.jp/ojad/eng/pages/notes , which ruled out the commercial use (which I targeted at that point), yet left me undecided about whether it's ok to use the data in the free app, or is it supposed to be used only through their site. I don't mean it as any kind of suspicion or rebuke, but did you have any luck finding their explicit terms of use, or did you ask some kind of permission from them, or clarified the matter in some other way? OJAD seems to be the only source of accent data, and their audio is also a valuable resource: though some of us privately use clips from JapanesePod101, alas they can't be used even in free apps, let alone paid.
>
> --
> You received this message because you are subscribed to the "KanjiVG" group.
> For options and unsubscribing, visit this group at
> http://groups.google.com/group/kanjivg
> ---
> You received this message because you are subscribed to the Google Groups "KanjiVG" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to kanjivg+u...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
Tomash Brechko
Jun 30, 2017, 5:42:10 AM6/30/17
to KanjiVG
The Japanese-German dictionary WaDokuJT contains data for accent and pronunciation, i.e. number for accent and kana plus mark-up which can together be transformed to IPA, phonetic or phonological transcriptions in kana or Rōmaji etc. The dictionary data can be used under the Creative Commons License with Attribution and Share Alike. In my file, about 130'000 records out of 325'000 contain accent information.
Wow, thanks for sharing this!
Tomash Brechko
Jun 30, 2017, 7:27:36 AM6/30/17
to KanjiVG
i.e. number for accent
Hmm, on further examination it seems there's no accent info in the data at https://github.com/Wadoku . For instance https://github.com/WaDoku/WaDokuJT-Data/blob/master/WaDokuDa.tab contains two entries
15 インスリン いんすりん (<POS: N.>) <MGr: {<Dom.: Med.>} <TrE: <HW n: Insulin>>>. 名 HE いんすりん
30 火田民 かでんみん (<POS: N.>) <MGr: <TrE: <HW m: Brandrodungsbauer>>>. 名 HE か'でん[WaSep]みん
Both can be found through wadoku.eu, but it does not show accents. wadoku.de doesn't find the second word at all, yet does provide accent for the first word, and this data doesn't seem to be encoded anywhere in the record above.
Thanks anyway, looking forward for it to be sorted out by autumn.
Ulrich Apel
Jun 30, 2017, 12:33:56 PM6/30/17
to kan...@googlegroups.com
I am very sorry about that. I wasn't aware that the file on GitHub wasn’t complete.
You can download a brand new full version at
https://rokuhara.japanologie.kultur.uni-tuebingen.de/owncloud/index.php/s/pRUY7CZ78expBIl
I hope this works now. We will upload a new version at Github in autumn, and hopefully will have synchronized the two data versions of wadoku.de and wadoku.eu then too. That is what I am working on at the moment.
Then, I also forgot that there is mark-up to produce transcription using DIN 32708:2014-08 Standard "Romanization of Japanese", which is also proposed as ISO Standard. Long compound words contain a separator [DinSP], and we use an additional intern separator [WaSep]. That is what you can see in your example.
Best wishes
Ulrich
You can download a brand new full version at
https://rokuhara.japanologie.kultur.uni-tuebingen.de/owncloud/index.php/s/pRUY7CZ78expBIl
I hope this works now. We will upload a new version at Github in autumn, and hopefully will have synchronized the two data versions of wadoku.de and wadoku.eu then too. That is what I am working on at the moment.
Then, I also forgot that there is mark-up to produce transcription using DIN 32708:2014-08 Standard "Romanization of Japanese", which is also proposed as ISO Standard. Long compound words contain a separator [DinSP], and we use an additional intern separator [WaSep]. That is what you can see in your example.
Best wishes
Ulrich
Tomash Brechko
Jun 30, 2017, 1:37:02 PM6/30/17
to KanjiVG
I hope this works now.
Yes, the new data has the accent number field. Thanks a lot!
Reply all
Reply to author
Forward
0 new messages