IDSgrep Online
49 views
Skip to first unread message

msk...@ansuz.sooke.bc.ca
Oct 18, 2019, 10:12:10 PM10/18/19
to kan...@googlegroups.com
I've written a Javascript-based graphical query builder for my IDSgrep
lookup program, and you can try it at this address:
https://tsukurimashou.osdn.jp/idsquery.php
Still something of a work in progress, and there's basically no
documentation, but I hope the main features are discoverable, and that
it'll be of interest to the people who read this list. Although
IDSgrep can build dictionaries from KanjiVG, the data used in the Web
page is not actually from KanjiVG but rather CJKVI and EDICT2. There's
https://twitter.com/mattskala/status/1185231546153873409
--
Matthew Skala
msk...@ansuz.sooke.bc.ca People before tribes.
https://ansuz.sooke.bc.ca/
lookup program, and you can try it at this address:
https://tsukurimashou.osdn.jp/idsquery.php
Still something of a work in progress, and there's basically no
documentation, but I hope the main features are discoverable, and that
it'll be of interest to the people who read this list. Although
IDSgrep can build dictionaries from KanjiVG, the data used in the Web
page is not actually from KanjiVG but rather CJKVI and EDICT2. There's
https://twitter.com/mattskala/status/1185231546153873409
--
Matthew Skala
msk...@ansuz.sooke.bc.ca People before tribes.
https://ansuz.sooke.bc.ca/
msk...@ansuz.sooke.bc.ca
Oct 18, 2019, 10:21:55 PM10/18/19
to kan...@googlegroups.com
On Fri, 18 Oct 2019, msk...@ansuz.sooke.bc.ca wrote:
> page is not actually from KanjiVG but rather CJKVI and EDICT2. There's
> https://twitter.com/mattskala/status/1185231546153873409
Editing error - that should be "There's a brief video demonstrating an
> page is not actually from KanjiVG but rather CJKVI and EDICT2. There's
> https://twitter.com/mattskala/status/1185231546153873409
earlier version on Twitter at" (the given Twitter address).

Ben Bullock
Oct 24, 2019, 2:47:59 AM10/24/19
to KanjiVG
On Sat, 19 Oct 2019 at 11:12, <msk...@ansuz.sooke.bc.ca> wrote:
I've written a Javascript-based graphical query builder for my IDSgrep
lookup program, and you can try it at this address:
https://tsukurimashou.osdn.jp/idsquery.php
It seems a very interesting concept, and implemented very well. In my opinion the result ordering would be better ordered by stroke count. (There is stroke count data in the Unihan database.) I am currently using the IDS decomposition data to search for matches to the handwritten inputs of qhanzi.com, and I made something which is similar to Jim Breen's multiradical search for the hanzi. It is available here:
The "items" are the parts in the IDS decomposition, sorted by frequency of occurrence and also edited to unify some things. The results are sorted by stroke count. This only does the GB (Chinese simplified) characters at the moment.
msk...@ansuz.sooke.bc.ca
Oct 24, 2019, 4:04:05 PM10/24/19
to KanjiVG
On Thu, 24 Oct 2019, Ben Bullock wrote:
> It seems a very interesting concept, and implemented very well. In my
> opinion the result ordering would be better ordered by stroke count. (There
> is stroke count data in the Unihan database.) I am currently using the IDS
That seems like a good idea. At the moment it's just displaying results
> It seems a very interesting concept, and implemented very well. In my
> opinion the result ordering would be better ordered by stroke count. (There
> is stroke count data in the Unihan database.) I am currently using the IDS
in whatever order they come out of the idsgrep command-line program -
which in turn is whatever was in the original database. Probably the
sensible thing to do would be change the dictionary builder for the
command-line program to sort the dictionary file while it's being
generated.
Ben Bullock
Oct 24, 2019, 8:15:19 PM10/24/19
to KanjiVG
On Fri, 25 Oct 2019 at 05:04, <msk...@ansuz.sooke.bc.ca> wrote:
Probably the
sensible thing to do would be change the dictionary builder for the
command-line program to sort the dictionary file while it's being
generated.
I think your current ordering is sorted by the Unicode value of the characters, but I haven't checked that.
Are you planning to make this a general search for characters for users, or is it for some specialised purpose?
msk...@ansuz.sooke.bc.ca
Oct 26, 2019, 12:52:29 PM10/26/19
to KanjiVG
On Fri, 25 Oct 2019, Ben Bullock wrote:
> I think your current ordering is sorted by the Unicode value of the
> characters, but I haven't checked that.
If so, it's probably by accident.
> I think your current ordering is sorted by the Unicode value of the
> characters, but I haven't checked that.
> The other suggestion which might be useful is to do something similar to
> what I've done with the www.qhanzi.com/mr.html system, pick out the most
> used elements and make a list of them to go with the current radical and
> grade lists, or even offer the "most used elements" as a default to users.
with some codes that don't occur in the dictionary weeded out. I'm not
sure having the grade-level lists is even useful; I put those in because
I had them handy, and they're how I organize characters within the
Tsukurimashou source code, but I doubt that most people who can read a
kanji also know which grade level it is.
> At the moment the default is just a list
> Are you planning to make this a general search for characters for users, or
> is it for some specialised purpose?
implementing this search as part of a larger program to modernize the
Tsukurimashou Project Web site - I hoped IDSgrep in particular might
attract more attention than it's currently getting, and having an online
demo that doesn't require downloading the software would be of benefit in
showing what it's good for. As such, the main goal is to demonstrate what
IDSgrep does and the features that are unique to IDSgrep (in particular,
the structural aspect of the query language), not to replace the kinds of
searches people already do with other tools like traditional multi-radical
kanji lookup.
IDSgrep in turn exists first as a development tool for Tsukurimashou, and
second for whatever other value anyone may find in it. During
Tsukurimashou development I often want to do very specific queries that
incorporate structure - not "What is this kanji I'm looking at?" but stuff
like "Are there any kanji already in the font that have this radical on
the left side and a top-bottom structure on the right, because if so I'll
want to harmonize the design of my new kanji with the existing ones?"
And "no, there are no such kanji yet" is a useful answer to that question,
if it happens to be true - an empty result is not a failure. I expect to
continue using my command-line utility for my own needs most of the time,
but if it happens to be convenient for me to do some of my own lookups
using the Web tool, that's a benefit for me even if nobody else wants
to use it.
Ben Bullock
Oct 27, 2019, 12:38:03 AM10/27/19
to KanjiVG
On Sun, 27 Oct 2019 at 01:52, <msk...@ansuz.sooke.bc.ca> wrote:
On Fri, 25 Oct 2019, Ben Bullock wrote:
> I think your current ordering is sorted by the Unicode value of the
> characters, but I haven't checked that.
If so, it's probably by accident.
I don't know, but I think it's better to sort using another method than "by accident" though.
> At the moment the default is just a list
> Are you planning to make this a general search for characters for users, or
> is it for some specialised purpose?
Interesting question, and TBH one I hadn't thought much about.
I'm currently working on improving the handwritten search at qhanzi.com, and that involves building a body of test data of "user input plus target hanzi". That means I have to look through user data and try to work out what the person was trying to draw (the target hanzi), if I can. Here is an example of the test addition interface:
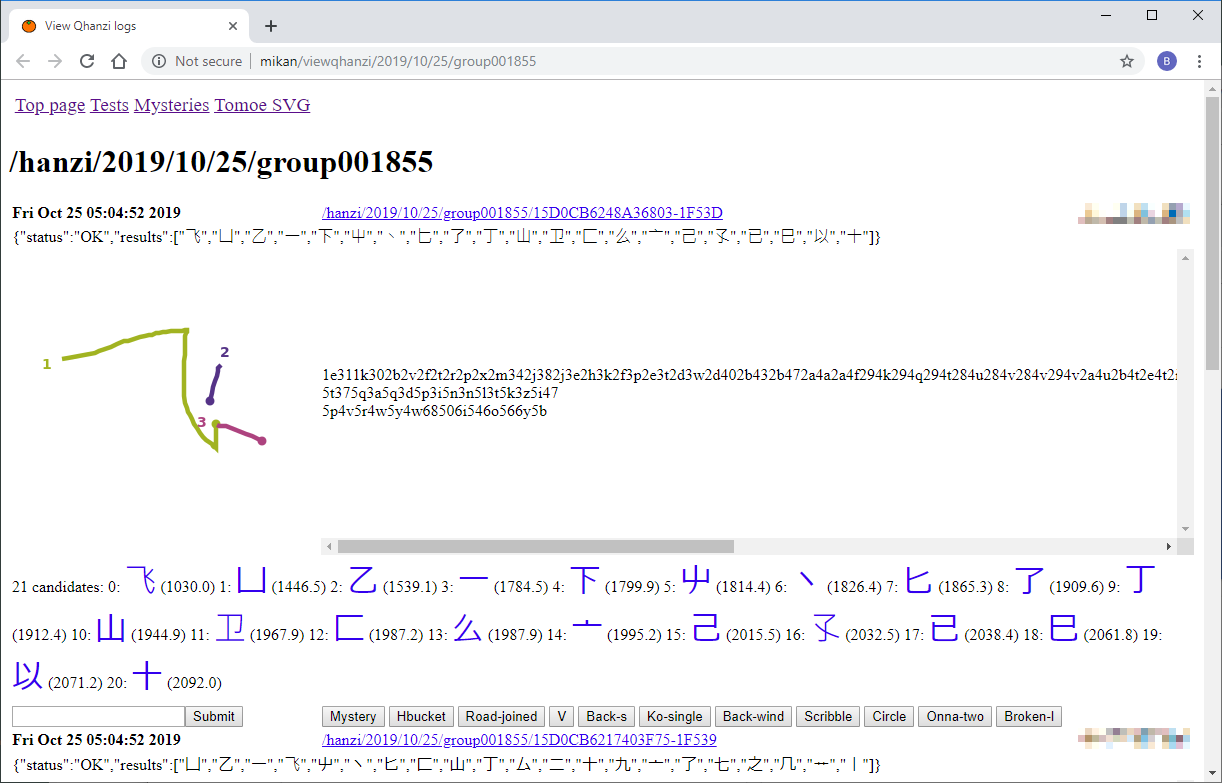
Sometimes they are drawing something which doesn't exist, but to demonstrate that the character doesn't exist I have to go through some kind of search. I was basically looking through the cjkvi-ids.txt file to find similar things, but I've been trying to improve that multiradical search to the point where it does a reasonable job of finding things. The IDSGrep application seems to provide a similar function.
I started
implementing this search as part of a larger program to modernize the
Tsukurimashou Project Web site - I hoped IDSgrep in particular might
attract more attention than it's currently getting, and having an online
demo that doesn't require downloading the software would be of benefit in
showing what it's good for.
What kind of people do you want to use IDSgrep?
As such, the main goal is to demonstrate what
IDSgrep does and the features that are unique to IDSgrep (in particular,
the structural aspect of the query language), not to replace the kinds of
searches people already do with other tools like traditional multi-radical
kanji lookup.
I don't know of a multiradical lookup for Chinese simplified characters except for the one I made at www.qhanzi.com/mr.html.
IDSgrep in turn exists first as a development tool for Tsukurimashou, and
second for whatever other value anyone may find in it. During
Tsukurimashou development I often want to do very specific queries that
incorporate structure - not "What is this kanji I'm looking at?" but stuff
like "Are there any kanji already in the font that have this radical on
the left side and a top-bottom structure on the right, because if so I'll
want to harmonize the design of my new kanji with the existing ones?"
And "no, there are no such kanji yet" is a useful answer to that question,
if it happens to be true - an empty result is not a failure. I expect to
continue using my command-line utility for my own needs most of the time,
but if it happens to be convenient for me to do some of my own lookups
using the Web tool, that's a benefit for me even if nobody else wants
to use it.
I wish you good luck with your project, it shows a great deal of skill in its construction.
Ben Bullock
Nov 11, 2019, 7:24:07 PM11/11/19
to KanjiVG
Perhaps this practical example from today's inputs might give some insight from one potential user what kind of problems I'm facing:

What I'm currently doing is to search through the ids.txt file which comes with the cjkvi-ids project
In this case I looked for 亦 and found
U+5909 変 ⿱亦夂
but there doesn't seem to be any character consisting of a sequence like
⿰月変
in the ids.txt file, so I assume that this user created their own new character or miswrote something somehow. There doesn't seem to be
⿰月变
either, so it's hard to guess. Using the idsgrep, there doesn't seem to be any way to insert text directly into the left/right boxes, which would be useful for me, and it's hard to see how to delete an entry from the boxes as well, so it doesn't currently seem more convenient than directly looking at the text file.
msk...@ansuz.sooke.bc.ca
Nov 12, 2019, 9:01:25 AM11/12/19
to KanjiVG
On Tue, 12 Nov 2019, Ben Bullock wrote:
> Perhaps this practical example from today's inputs might give some insight
> from one potential user what kind of problems I'm facing:
Thanks.
> Perhaps this practical example from today's inputs might give some insight
> from one potential user what kind of problems I'm facing:
> Using the [online] idsgrep, there doesn't seem to be
> any way to insert text directly into the left/right boxes, which would be
> useful for me,
If you click "Tools«", it'll expand to reveal among other things a small
> useful for me,
text box with an equals sign. Type a character there and then drag from
the equals to the query area, and it'll add the character you typed as an
element in the query. You can also click where in the query you want to
put it - at which point that element should become highlighted with a
heavy border - and then click the equals sign, instead of dragging.
One gotcha with the equals tool is that the contents of the associated
text box need to be exactly one character. It's easy to type something in
and have it appended instead of replacing the current contents of the box,
leaving you with a two-character text that won't work. I'm not sure yet
what I can do to make that easier. Options might include automatically
emptying the box whenever it's used; just using the last character of the
text; making the box wider so that it'll be easier to at least see the
mistake; and so on.
> and it's hard to see how to delete an entry from the boxes as
> well,
not obvious enough, but in case of the former, there are several ways:
* Drag the query element you want to remove onto the recycling symbol,
which will appear when you start dragging.
* Drag the question-mark "match anything" operator, which is the first
one, shown in the "Op»" category that is opened by default, onto the query
element you want to remove.
* Click the query element to remove, it will become highlighted with a
heavy border, then click the question mark. Note that this, and the drag
from question mark to query area, can also be used to replace an existing
query element with a different one (not only the question mark).
* Query elements can also be removed as a side effect of removing other
things - for instance, clicking the "X" to remove an operator like ⿰ will
remove whatever was inside it, and you can start over completely by
reloading the page.
Regarding the image in your attachment, I constructed the query ⿰月⿱?夂
and found U+6718 【朘】⿰月⿱允夂 as the only matching structure for which
my browser has font coverage. There is also U+8127, with seemingly the
same structure, in the compatibility range. But although it's not in
my browser's font config, so I see it only as a placeholder, the query
also returns U+26744 【𦝄】⿰月⿱圥夂 and that seems pretty close to what
your user drew.
Ben Bullock
Nov 12, 2019, 10:34:38 PM11/12/19
to KanjiVG
On Tue, 12 Nov 2019 at 23:01, <msk...@ansuz.sooke.bc.ca> wrote:
If you click "Tools«", it'll expand to reveal among other things a small
text box with an equals sign. Type a character there and then drag from
the equals to the query area, and it'll add the character you typed as an
element in the query. You can also click where in the query you want to
put it - at which point that element should become highlighted with a
heavy border - and then click the equals sign, instead of dragging.
Thanks for this assistance.
One gotcha with the equals tool is that the contents of the associated
text box need to be exactly one character. It's easy to type something in
and have it appended instead of replacing the current contents of the box,
leaving you with a two-character text that won't work. I'm not sure yet
what I can do to make that easier. Options might include automatically
emptying the box whenever it's used; just using the last character of the
text; making the box wider so that it'll be easier to at least see the
mistake; and so on.
Your system is very ingenious but it is not very intuitive.
> and it's hard to see how to delete an entry from the boxes as
> well,
I don't know if you're asking how to do this, or just commenting that it's
not obvious enough, but in case of the former, there are several ways:
I didn't know how to do that.
* Drag the query element you want to remove onto the recycling symbol,
which will appear when you start dragging.
* Drag the question-mark "match anything" operator, which is the first
one, shown in the "Op»" category that is opened by default, onto the query
element you want to remove.
* Click the query element to remove, it will become highlighted with a
heavy border, then click the question mark. Note that this, and the drag
from question mark to query area, can also be used to replace an existing
query element with a different one (not only the question mark).
* Query elements can also be removed as a side effect of removing other
things - for instance, clicking the "X" to remove an operator like ⿰ will
remove whatever was inside it, and you can start over completely by
reloading the page.
Regarding the image in your attachment, I constructed the query ⿰月⿱?夂
and found U+6718 【朘】⿰月⿱允夂 as the only matching structure for which
my browser has font coverage. There is also U+8127, with seemingly the
same structure, in the compatibility range. But although it's not in
my browser's font config, so I see it only as a placeholder, the query
also returns U+26744 【𦝄】⿰月⿱圥夂 and that seems pretty close to what
your user drew.
Thanks very much for the very useful guide to your system. It has lots of very ingenious features. I wish you good luck with this site and look forward to future improvements.
Ben Bullock
Nov 13, 2019, 8:43:26 PM11/13/19
to KanjiVG
Here is another example, I found this input today and used idsgrep to break it down using the misidentified character shown highlighted underneath the user input picture:
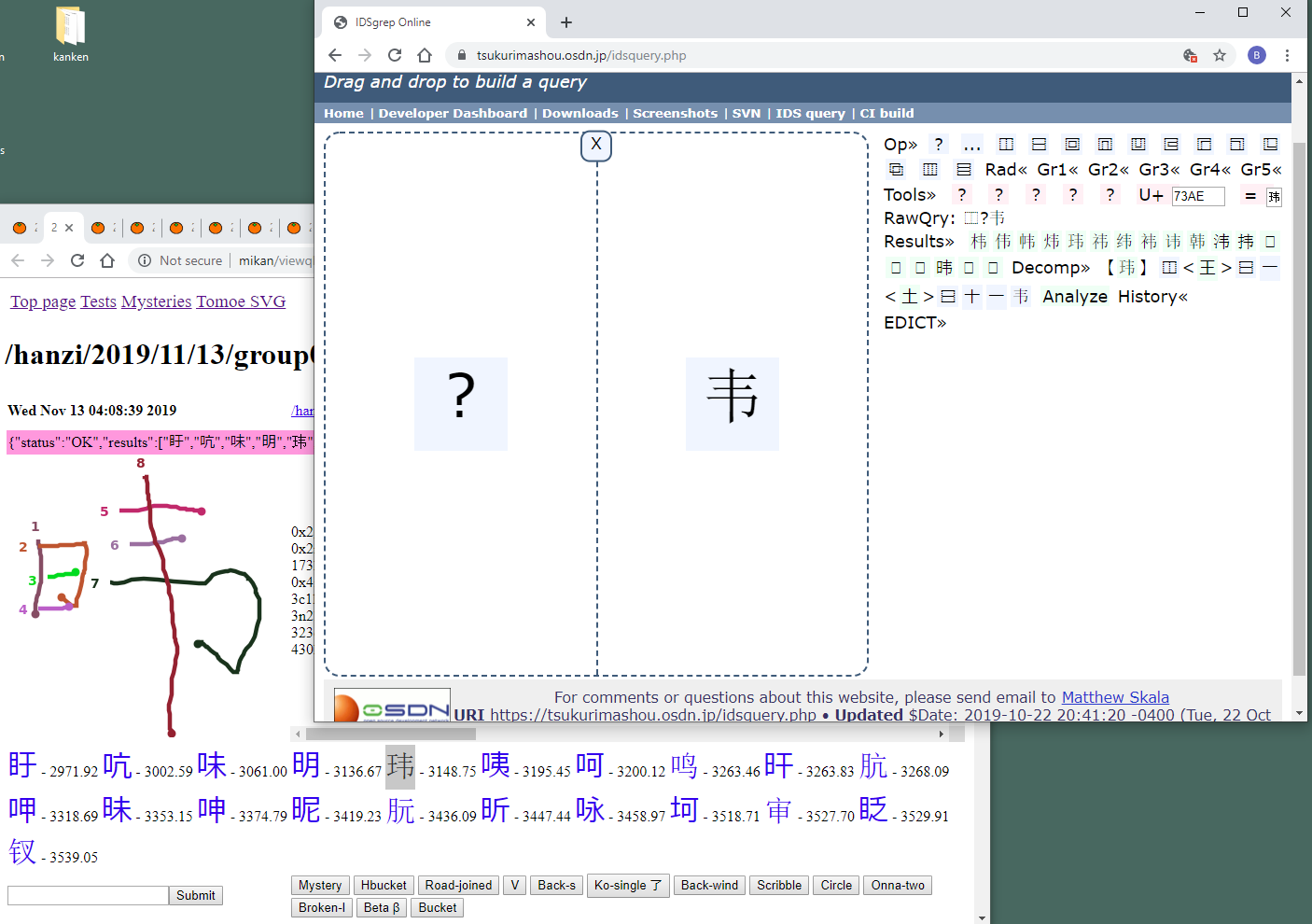
Idsgrep was able to find the correct character, the "day" plus this thing on the right. It seems I can then drag and drop that into the browser bar to get the final character, in this case
Apparently this obscure thing only exists in one Chinese reference, the Xiandai Hanyu Cidian (现代汉语词典).
I wonder why people are trying to find it using my site, but it's quite interesting that they do.
Ben Bullock
Nov 13, 2019, 8:49:22 PM11/13/19
to KanjiVG
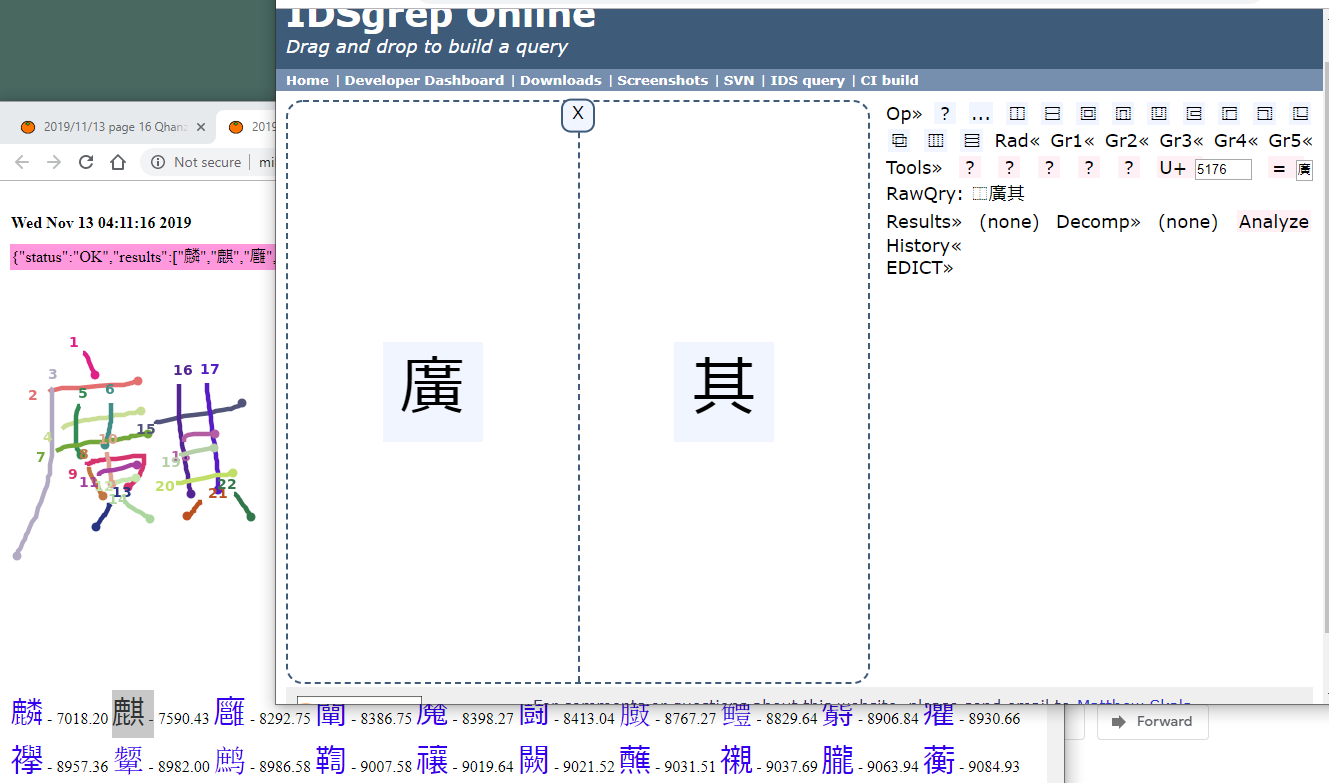
And another one, this thing doesn't seem to exist though:
Reply all
Reply to author
Forward
0 new messages