fine tuning nnet3 with new lexicons file?
140 katselukertaa
Siirry ensimmäiseen lukemattomaan viestiin

Trương Trang
30.11.2021 klo 22.44.3030.11.2021
vastaanottaja kaldi-help
hi everyone,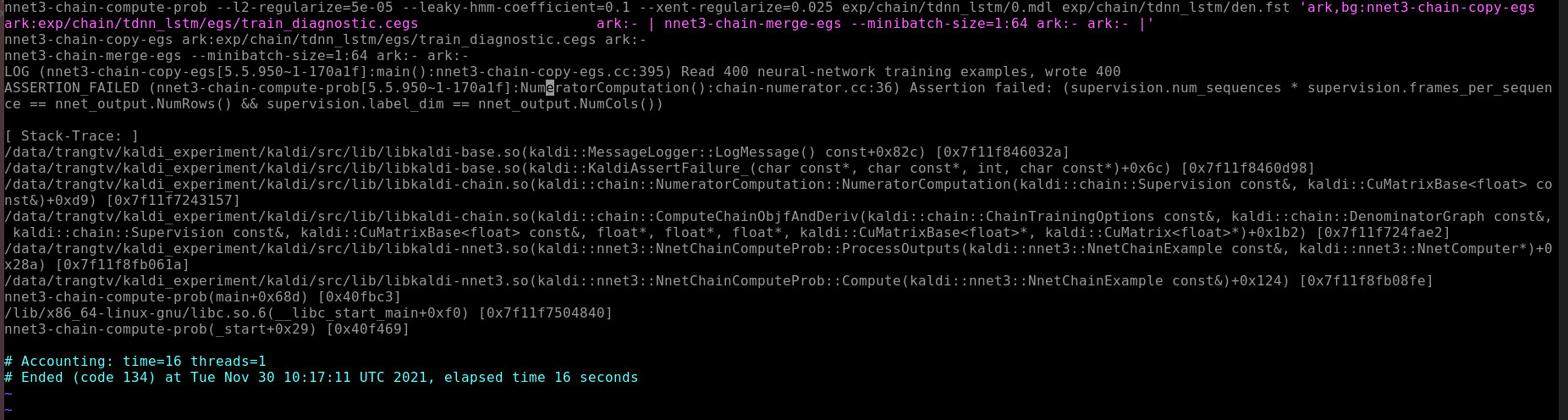 \
\
As my question, I want to fine tune old model with new dataset and with this dataset.
I want to build new lexicons for its, not just extend old lexicon. I already try keep non-silence-phones of new lexicon with old lexicon is same. But number phones in data/lang.phones.txt is difference. It's is just difference the "Disambiguation symbols" old version has #1-> #8 but new has #1 -> #20.
So it's make the fine tune training failed. I think.
\So how can i figure out problem. Or I need to retrain all data with new lexicon file?
Thanks you

Jan Yenda Trmal
1.12.2021 klo 9.43.351.12.2021
vastaanottaja kaldi-help
there is a parameter for prepare_lang.sh script that allows you to provide the original phones.txt table. It's kinda mouthful name like "phone-index-table" or something like that -- if you run prepare_lang.sh without any parameter, you should be able to spot it.
y.
--
Go to http://kaldi-asr.org/forums.html to find out how to join the kaldi-help group
---
You received this message because you are subscribed to the Google Groups "kaldi-help" group.
To unsubscribe from this group and stop receiving emails from it, send an email to kaldi-help+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/kaldi-help/83ce015d-4e08-4630-9893-06d5bd1da8bdn%40googlegroups.com.

Daniel Povey
2.12.2021 klo 0.23.582.12.2021
vastaanottaja kaldi-help
Even if he manages to run that script, and keep the phone indexes the same, I don't know how much it will help because he'd have to rebuild the tree.
I think it's only really useful if the number of phones is less than before, not more.
To view this discussion on the web visit https://groups.google.com/d/msgid/kaldi-help/CAFReZQYp2yhHWaM%2BYVoXJWDwRHv1G01bWDGezeovdNrQR4n-_A%40mail.gmail.com.
Trương Trang
5.12.2021 klo 10.47.075.12.2021
vastaanottaja kaldi-help
tks @Dan Povey,
I can be run script with change parameter of prepare_lang.sh with old phones.txt, I use tree trained before, not retrain the tree. But result has problem, the result decoding get worst compare with old version AM. So I'm try to train model with retrain tree but not sure it's help. So perfect answer is all dataset should be retrained all with the same phones.txt, same lexicon? Does I understand it right?
Tks all
Daniel Povey
5.12.2021 klo 23.48.285.12.2021
vastaanottaja kaldi-help
Best to just rerun training from scratch. Extending the phone set would be difficult to handle.
To view this discussion on the web visit https://groups.google.com/d/msgid/kaldi-help/6f119498-d8e2-4b85-afaa-22117648ddd9n%40googlegroups.com.
Trương Trang
6.12.2021 klo 2.14.086.12.2021
vastaanottaja kaldi-help
tks for your suggest,
But problem is when i have another dataset has some word not appear in old dataset. So lexicon need be update and I need retrain all ?. Does it right?.
I don't think it's should not like that, right?, everything may be so hard when we have new dataset for transfer.
tks @Dan Povey
Jan Yenda Trmal
6.12.2021 klo 8.37.416.12.2021
vastaanottaja kaldi-help
it's not that everything is hard... adding new phones is hard
Retraining or adaptation is fairly straightforward as long as you don't increase the size of the phone set
y.
To view this discussion on the web visit https://groups.google.com/d/msgid/kaldi-help/9c720ca3-0d92-4764-ac10-59417b025de7n%40googlegroups.com.
Jan Yenda Trmal
6.12.2021 klo 8.40.336.12.2021
vastaanottaja kaldi-help
fyi, you could merge all the data for the initial training and then retrain only on your "adaptation" subset
y.
Trương Trang
6.12.2021 klo 9.02.496.12.2021
vastaanottaja kaldi-help
Tks Yenda,
I need clearly that set phonemes using in old lexicon file and new lexicon file is the same. All the new word has new phoneme in new lexicon file I already filter. So all phoneme is the same. Just difference disambiguation set. So the result after training is worse.
But i think it's should be work in this case, or something is wrong or miss understand with me.
Trương Trang
6.12.2021 klo 9.04.476.12.2021
vastaanottaja kaldi-help
I already has experiment with use same lexicon for both training base dataset and then not change anything lexion to train subset dataset. And it's work. I know it. But my base dataset so large. And I need more than 2 week to retrain and then transfer. So I want know why my experiment with new lexicon but same phones don't work.
Tks/
On Monday, December 6, 2021 at 8:40:33 PM UTC+7 Yenda wrote:
Daniel Povey
6.12.2021 klo 10.18.096.12.2021
vastaanottaja kaldi-help
If the phone set is not changed it should be possible/fine to use that parameter to prepare_lang.sh, it's
--phone-symbol-table data/old_lang_dir/phones.txt
You shouldn't need to retrain the model, you should be able to rebuild the graph with the new lang dir and test with the existing model.
To view this discussion on the web visit https://groups.google.com/d/msgid/kaldi-help/6215f297-5df0-4f87-96ec-f79d6c46d3c1n%40googlegroups.com.
Trương Trang
6.12.2021 klo 21.14.416.12.2021
vastaanottaja kaldi-help
Yes, I able to train model with old phones.txt and old tree build, but I don't know why final model iter the result is so worse when compare with old model.
And If I try to retrain tree, not use old tree. It's make errorr mismatch like first figure. So I think, I wrong at something, but I don't know, becasue I don't have much deep understanding about tree, lexicon ....
Thanks.
Trương Trang
8.12.2021 klo 2.24.198.12.2021
vastaanottaja kaldi-help
I have try run script utils/prepare_lang.sh with option --phone-symbol-table like this:
utils/prepare_lang.sh --phone-symbol-table data/old_lang/phones.txt data/local/dict '!SIL' data/local/lang data/lang || exit 1
But phones.txt in data/lang is not change to same with old lang it's just like new old lang, all file in folder data/lang not has any difference when I not use --phone-symbol-table option. So I'm stuck here. How can I debug what's error. Because run with or without this option, both is success without any error. But after that, training still error with mismatch:
ASSERTION_FAILED (nnet3-chain-compute-prob[5.5.950~1-170a1f]:NumeratorComputation():chain-numerator.cc:36) Assertion failed: (supervision.num_sequences * supervision.frames_per_sequen
ce == nnet_output.NumRows() && supervision.label_dim == nnet_output.NumCols())
ce == nnet_output.NumRows() && supervision.label_dim == nnet_output.NumCols())
Thanks you
Daniel Povey
8.12.2021 klo 9.51.188.12.2021
vastaanottaja kaldi-help
As I think I said,it's likely something where you reran/regenerated some intermediate file in the recipe, e.g. the alignments or lattices or tree or something like that.
Check file times. You may need to remove something and repeat a stage.
To view this discussion on the web visit https://groups.google.com/d/msgid/kaldi-help/4d43c02c-4b1e-4fb1-8d7e-81f1e81080c9n%40googlegroups.com.
Vastaa kaikille
Vastaa kirjoittajalle
Välitä
0 uutta viestiä