Initiall INCEpTION setup for annotation project
322 views
Skip to first unread message

Michaela Polónyová
Sep 24, 2021, 8:21:56 AM9/24/21
to inception-users
Hello to the INCEpTION development team,
we are working on a Czech/English annotation project currently using Brat and hoping to switch to a different tool. We've been experimenting with INCEpTION and are a bit struggling to reach the state of things we particularly need. Would it be possible to get in touch with you and get some hints?
Features we are looking for:
- annotation of named entities (person, organization, location, etc.) and entity linking to wikidata > how to set it up in combination with a recommender/active learning?
- could we search for wikidata items via copying url for specific ids (e.g. https://www.wikidata.org/wiki/Q12028233 and preserving the description of the item)
- can we play with wikidata search relevancy? e.g. when looking up Czech republic in wikidata in named entity layer, we see the relevant item as 11th in the list
- is it possible to label the whole document with categories from a defined set (politics, sports, etc.)
- when annotating English documents, we want to annotate only the stem, not e.g. possessive 's, as in the underlined cases here: UFC's or McGregor-Poirier fight
I understand that such a simplified description will not be enough to help resolve all of my questions but I would very much appreciate it even if we just initiate the discussion.
Thank you very much,
Michaela

Richard Eckart de Castilho
Sep 24, 2021, 8:58:51 AM9/24/21
to inception-users
Hi,
> On 24. Sep 2021, at 14:21, Michaela Polónyová <michaela....@flashnews.com> wrote:
>
> we are working on a Czech/English annotation project currently using Brat and hoping to switch to a different tool. We've been experimenting with INCEpTION and are a bit struggling to reach the state of things we particularly need. Would it be possible to get in touch with you and get some hints?
>
>
> Features we are looking for:
> • annotation of named entities (person, organization, location, etc.) and entity linking to wikidata > how to set it up in combination with a recommender/active learning?
* To learn the class (PER, ORG, etc.) go to the project settings and to there to the recommender tab.
* Press "create"
* Choose "Named entity" as the layer
* Choose "value" as the feature
* Choose "Multi-token Sequence Classifier (OpenNLP NER)" as tool
* Save
If you want a recommender for linking as well, repeat the process but this time choosing "identifier" as the feature.
> • could we search for wikidata items via copying url for specific ids (e.g. https://www.wikidata.org/wiki/Q12028233 and preserving the description of the item)
Search by URL in principle works, but I can see that the result is "lost" in the list of other results. Also, you'd have to use `https://www.wikidata.org/entity/Q1202823` instead of `https://www.wikidata.org/wiki/Q12028233`. But I can see that doesn't work as smoothly as one would expect. I have opened an issue:
https://github.com/inception-project/inception/issues/2620
> • can we play with wikidata search relevancy? e.g. when looking up Czech republic in wikidata in named entity layer, we see the relevant item as 11th in the list
This is not configurable, but if you are open to editing the code:
https://github.com/inception-project/inception/blob/main/inception/inception-concept-linking/src/main/java/de/tudarmstadt/ukp/inception/conceptlinking/ranking/BaselineRankingStrategy.java
> • is it possible to label the whole document with categories from a defined set (politics, sports, etc.)
INCEpTION can do it, yes, but you have to enable the feature first:
https://inception-project.github.io/releases/20.4/docs/user-guide.html#_document_metadata
Reason this is behind a feature flag is that certain functions of INCEpTION do not yet support document-level annotations. E.g. there are no recommenders for the document-level annotations and also no curation functionality. Also, export is limited to UIMA CAS XMI.
User-friendliness of document-level annotations will improve in the upcoming v21.0, but the limitations regarding curation, recommenders and export remain.
> • when annotating English documents, we want to annotate only the stem, not e.g. possessive 's, as in the underlined cases here: UFC's or McGregor-Poirier fight
You can configure your custom layers for "character" granularity. Then you can create sub-token annotations. However, I would possibly recommend annotating the whole word because if you enable sub-token annotations, then it's easy to unintenionally miss or include characters. You can still create an other annotation on a "Stem" layer on the same word and write the stem string into a feature on that layer.
Best,
-- Richard
> On 24. Sep 2021, at 14:21, Michaela Polónyová <michaela....@flashnews.com> wrote:
>
> we are working on a Czech/English annotation project currently using Brat and hoping to switch to a different tool. We've been experimenting with INCEpTION and are a bit struggling to reach the state of things we particularly need. Would it be possible to get in touch with you and get some hints?
>
>
> Features we are looking for:
> • annotation of named entities (person, organization, location, etc.) and entity linking to wikidata > how to set it up in combination with a recommender/active learning?
* Press "create"
* Choose "Named entity" as the layer
* Choose "value" as the feature
* Choose "Multi-token Sequence Classifier (OpenNLP NER)" as tool
* Save
If you want a recommender for linking as well, repeat the process but this time choosing "identifier" as the feature.
> • could we search for wikidata items via copying url for specific ids (e.g. https://www.wikidata.org/wiki/Q12028233 and preserving the description of the item)
Search by URL in principle works, but I can see that the result is "lost" in the list of other results. Also, you'd have to use `https://www.wikidata.org/entity/Q1202823` instead of `https://www.wikidata.org/wiki/Q12028233`. But I can see that doesn't work as smoothly as one would expect. I have opened an issue:
https://github.com/inception-project/inception/issues/2620
> • can we play with wikidata search relevancy? e.g. when looking up Czech republic in wikidata in named entity layer, we see the relevant item as 11th in the list
This is not configurable, but if you are open to editing the code:
https://github.com/inception-project/inception/blob/main/inception/inception-concept-linking/src/main/java/de/tudarmstadt/ukp/inception/conceptlinking/ranking/BaselineRankingStrategy.java
> • is it possible to label the whole document with categories from a defined set (politics, sports, etc.)
INCEpTION can do it, yes, but you have to enable the feature first:
https://inception-project.github.io/releases/20.4/docs/user-guide.html#_document_metadata
Reason this is behind a feature flag is that certain functions of INCEpTION do not yet support document-level annotations. E.g. there are no recommenders for the document-level annotations and also no curation functionality. Also, export is limited to UIMA CAS XMI.
User-friendliness of document-level annotations will improve in the upcoming v21.0, but the limitations regarding curation, recommenders and export remain.
> • when annotating English documents, we want to annotate only the stem, not e.g. possessive 's, as in the underlined cases here: UFC's or McGregor-Poirier fight
You can configure your custom layers for "character" granularity. Then you can create sub-token annotations. However, I would possibly recommend annotating the whole word because if you enable sub-token annotations, then it's easy to unintenionally miss or include characters. You can still create an other annotation on a "Stem" layer on the same word and write the stem string into a feature on that layer.
Best,
-- Richard
Richard Eckart de Castilho
Sep 24, 2021, 9:06:49 AM9/24/21
to inception-users
On 24. Sep 2021, at 14:58, Richard Eckart de Castilho <richard...@gmail.com> wrote:
>
>> Features we are looking for:
>> • annotation of named entities (person, organization, location, etc.) and entity linking to wikidata > how to set it up in combination with a recommender/active learning?
>
> * To learn the class (PER, ORG, etc.) go to the project settings and to there to the recommender tab.
> * Press "create"
> * Choose "Named entity" as the layer
> * Choose "value" as the feature
> * Choose "Multi-token Sequence Classifier (OpenNLP NER)" as tool
> * Save
>
> If you want a recommender for linking as well, repeat the process but this time choosing "identifier" as the feature.
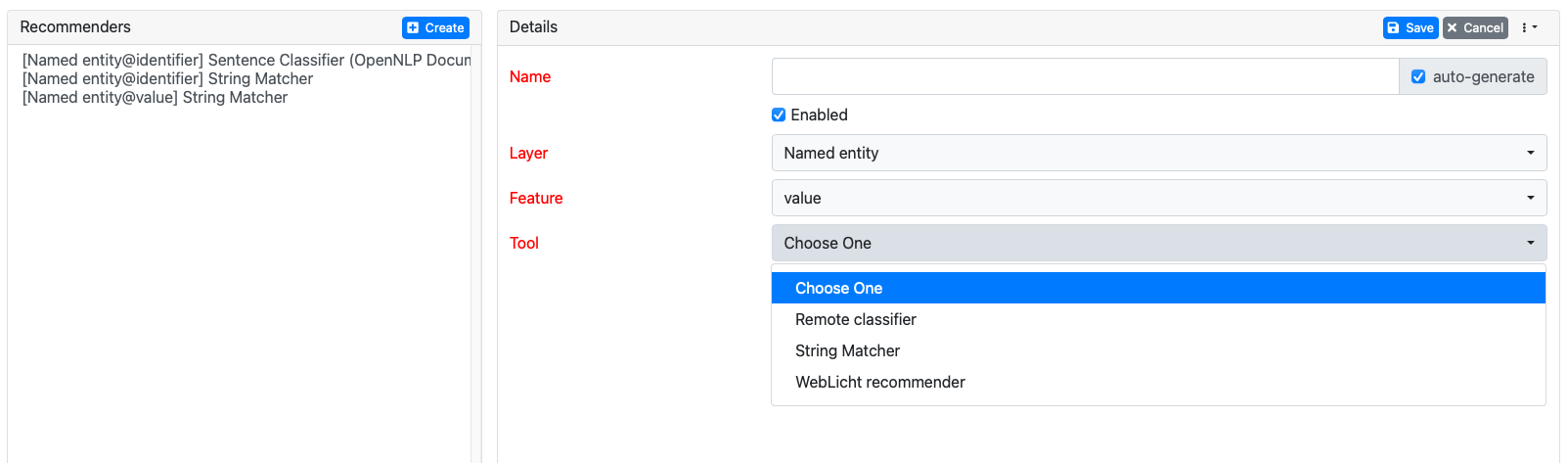
Best also repeat these steps but then using the "String Matching" tool - so you'd end up with two recommender for the "value" feature and another two for the "identifier" feature if you want.
>
>> Features we are looking for:
>> • annotation of named entities (person, organization, location, etc.) and entity linking to wikidata > how to set it up in combination with a recommender/active learning?
>
> * To learn the class (PER, ORG, etc.) go to the project settings and to there to the recommender tab.
> * Press "create"
> * Choose "Named entity" as the layer
> * Choose "value" as the feature
> * Choose "Multi-token Sequence Classifier (OpenNLP NER)" as tool
> * Save
>
> If you want a recommender for linking as well, repeat the process but this time choosing "identifier" as the feature.
-- Richard
Michaela Polónyová
Sep 29, 2021, 5:49:01 AM9/29/21
to inception-users
Hi Richard,
* To learn the class (PER, ORG, etc.) go to the project settings and to there to the recommender tab.
* Press "create"
* Choose "Named entity" as the layer
* Choose "value" as the feature
* Choose "Multi-token Sequence Classifier (OpenNLP NER)" as tool
* Save
If you want a recommender for linking as well, repeat the process but this time choosing "identifier" as the feature.
thank you so much for a speedy reply! I've had a chance to look at the settings and a couple of things are still not completely clear to me.
Features:
* To learn the class (PER, ORG, etc.) go to the project settings and to there to the recommender tab.
* Press "create"
* Choose "Named entity" as the layer
* Choose "value" as the feature
* Choose "Multi-token Sequence Classifier (OpenNLP NER)" as tool
* Save
If you want a recommender for linking as well, repeat the process but this time choosing "identifier" as the feature.
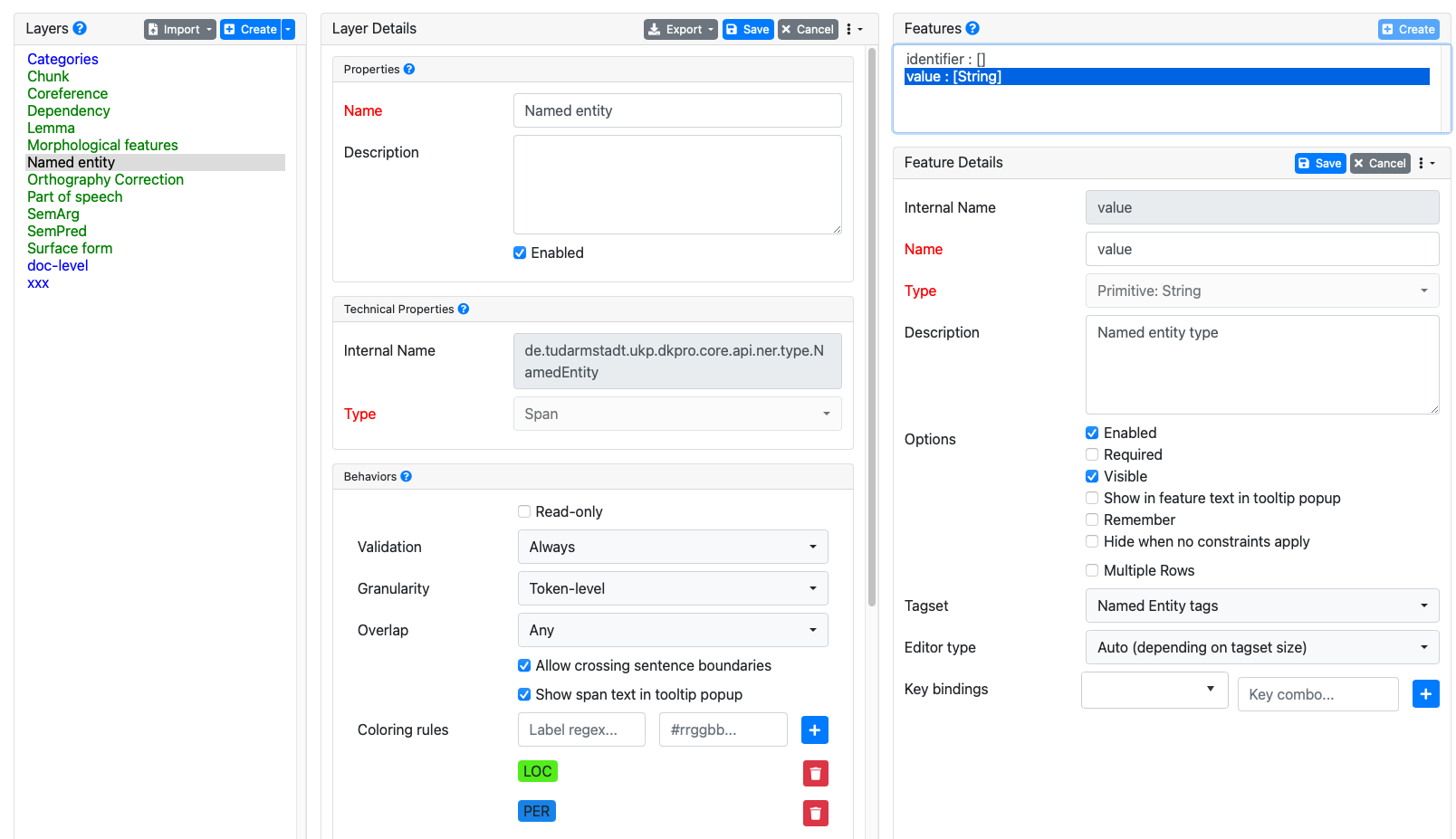
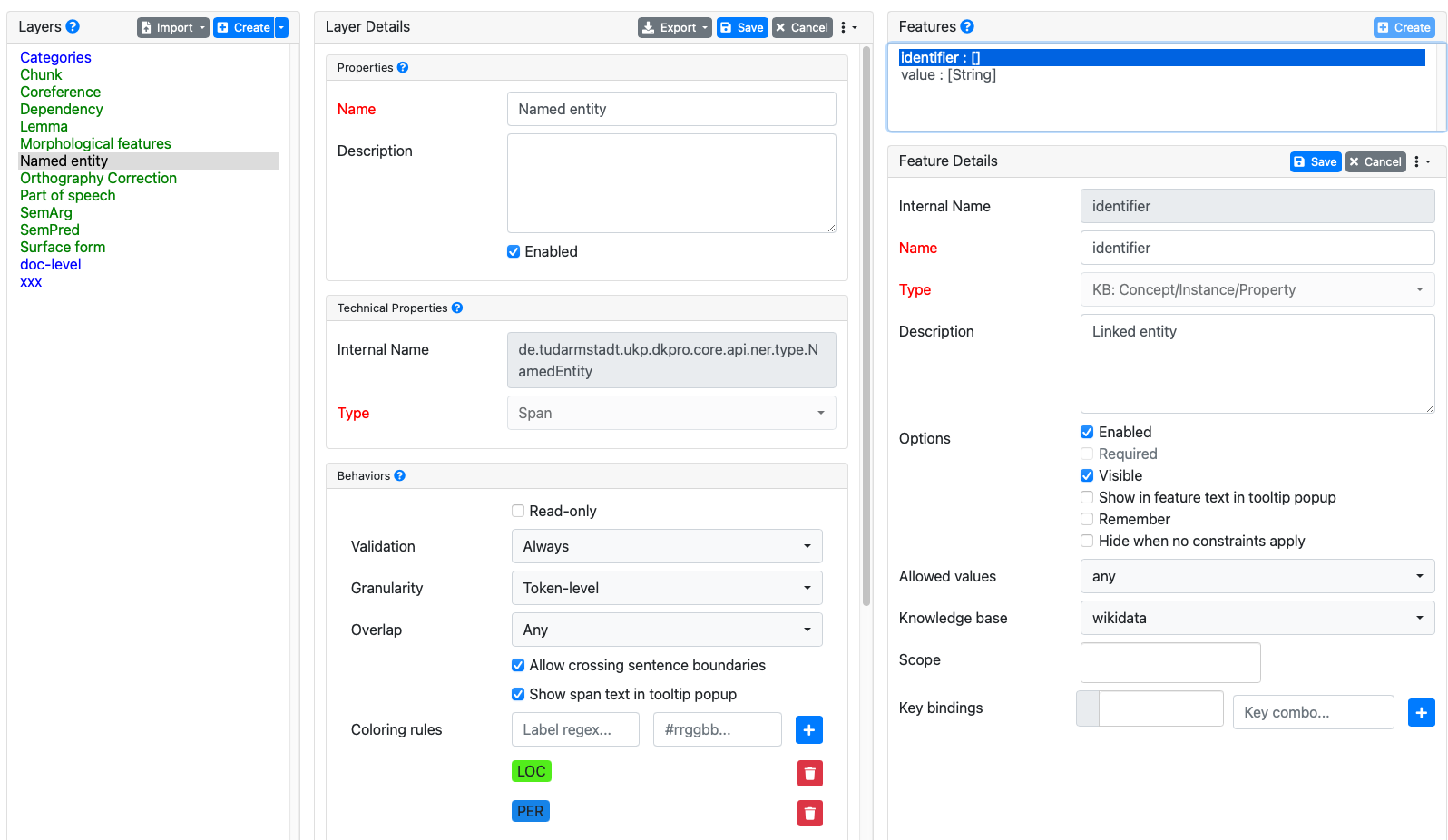
[Michaela] Here I am not certain I have correctly set up the named entity layer itself because when I follow these steps, I do not see "Multi-token Sequence Classifier" as an option - maybe some screenshots attached will help illustrate?
> • could we search for wikidata items via copying url for specific ids (e.g. https://www.wikidata.org/wiki/Q12028233 and preserving the description of the item)
Search by URL in principle works, but I can see that the result is "lost" in the list of other results. Also, you'd have to use `https://www.wikidata.org/entity/Q1202823` instead of `https://www.wikidata.org/wiki/Q12028233`. But I can see that doesn't work as smoothly as one would expect. I have opened an issue:
https://github.com/inception-project/inception/issues/2620
Search by URL in principle works, but I can see that the result is "lost" in the list of other results. Also, you'd have to use `https://www.wikidata.org/entity/Q1202823` instead of `https://www.wikidata.org/wiki/Q12028233`. But I can see that doesn't work as smoothly as one would expect. I have opened an issue:
https://github.com/inception-project/inception/issues/2620
[Michaela] Thank you for opening the issue. However, what is the difference between wiki vs entity? If I search e.g. for European Union as an entity, I cannot find it.
Thank you for info about how to annotate document meta data, it works exactly like we needed it to.
Thank you for info about how to annotate document meta data, it works exactly like we needed it to.
Kind regards,
Michaela
Dne pátek 24. září 2021 v 15:06:49 UTC+2 uživatel richard...@gmail.com napsal:
{kind=link}
{kind=link}
{kind=link}
Michaela Polónyová
Sep 29, 2021, 7:16:09 AM9/29/21
to inception-users
May I add one more question for the wiki vs entity from the url - we have linked e.g. Tiger Woods to wikidata here 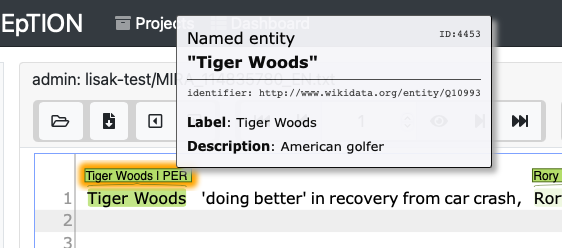 and I do see entity in the url, however, if I click on it I get redirected to wikidata url which actually is https://www.wikidata.org/wiki/Q10993.
and I do see entity in the url, however, if I click on it I get redirected to wikidata url which actually is https://www.wikidata.org/wiki/Q10993.
and I do see entity in the url, however, if I click on it I get redirected to wikidata url which actually is https://www.wikidata.org/wiki/Q10993.This is not clear to me so I think maybe I am missing a piece of information to fit in the puzzle.
Thank you once again for your time and helpful answers.
Kind regards,
Michaela
Dne středa 29. září 2021 v 11:49:01 UTC+2 uživatel Michaela Polónyová napsal:
Richard Eckart de Castilho
Sep 29, 2021, 3:39:34 PM9/29/21
to incepti...@googlegroups.com
Hi,
Features:
* To learn the class (PER, ORG, etc.) go to the project settings and to there to the recommender tab.
* Press "create"
* Choose "Named entity" as the layer
* Choose "value" as the feature
* Choose "Multi-token Sequence Classifier (OpenNLP NER)" as tool
* Save
If you want a recommender for linking as well, repeat the process but this time choosing "identifier" as the feature.
[Michaela] Here I am not certain I have correctly set up the named entity layer itself because when I follow these steps, I do not see "Multi-token Sequence Classifier" as an option - maybe some screenshots attached will help illustrate?
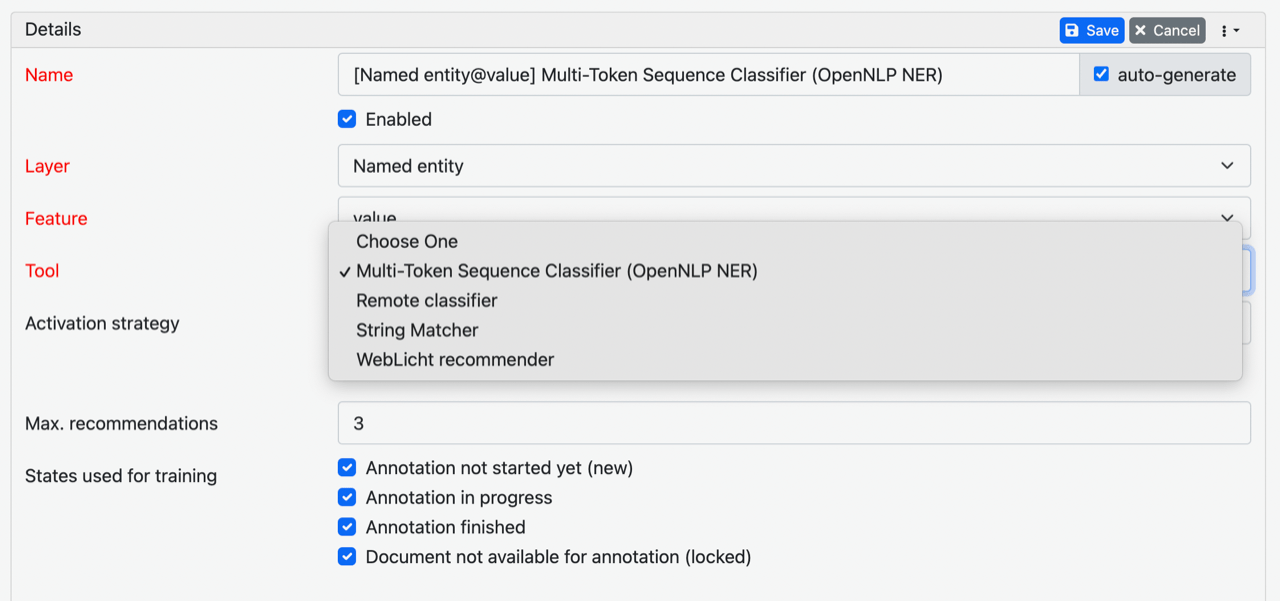
> • could we search for wikidata items via copying url for specific ids (e.g. https://www.wikidata.org/wiki/Q12028233 and preserving the description of the item)
Search by URL in principle works, but I can see that the result is "lost" in the list of other results. Also, you'd have to use `https://www.wikidata.org/entity/Q1202823` instead of `https://www.wikidata.org/wiki/Q12028233`. But I can see that doesn't work as smoothly as one would expect. I have opened an issue:
https://github.com/inception-project/inception/issues/2620
[Michaela] Thank you for opening the issue. However, what is the difference between wiki vs entity? If I search e.g. for European Union as an entity, I cannot find it.
The Wikidata knowledge base internally uses identifiers in the form `http://www.wikidata.org/entity/Q12028233` - if the identifier you enter into the input field is not in that form, then it cannot be properly retrieved. So it must start with "http" (not "https") and it must use "entity" and not "wiki".
If you put that form into a browser, then you are redirected to `HTTPS://www.wikidata.org/WIKI/Q12028233` - so the protocol changes from http to https and the "entity" changes to "wiki". It is nice that Wikidata redirects you from the entity ID to a website that shows information about the ID - cool. However, if you take the address of that website and put it back into INCEpTION, INCEpTION will try to look it up in the Wikidata knowledge base and not find anything because the form does not match what is actually stored in the database.
That said, there is an additional thing you need to do to actually get a proper result. Go to the layer settings, select the named entity layer and then the identifier feature and change "allow values" to "any" and save. Wikidata is at time a bit "dirty" and has missing or occasionally wrong information. To work around that, you need to match against "any" value.

If I search for European Union in the browser, it takes me to https://www.wikidata.org/wiki/Q458
If I search in INCEpTION (with allow values set to any), I get this (the words I try to annotate are "Columbia University" which is why that appears in the results as well - the small gray print is debug information I see on my developer version). So you see I can find it and again the ID is with "http" and "entity".

Cheers,
-- Richard
Richard Eckart de Castilho
Sep 29, 2021, 3:41:48 PM9/29/21
to incepti...@googlegroups.com
On 29. Sep 2021, at 13:16, Michaela Polónyová <michaela....@flashnews.com> wrote:
>
> May I add one more question for the wiki vs entity from the url - we have linked e.g. Tiger Woods to wikidata here <tiger-woods.png> and I do see entity in the url, however, if I click on it I get redirected to wikidata url which actually is https://www.wikidata.org/wiki/Q10993.
-- Richard
>
> May I add one more question for the wiki vs entity from the url - we have linked e.g. Tiger Woods to wikidata here <tiger-woods.png> and I do see entity in the url, however, if I click on it I get redirected to wikidata url which actually is https://www.wikidata.org/wiki/Q10993.
> This is not clear to me so I think maybe I am missing a piece of information to fit in the puzzle.
Well, Wikidata uses one form of IRI in its knowledge base and another form for its web interface. I cannot tell you why they chose to do it this way, but that is how it is. When searching in INCEpTION, you need to use the form with "http" and "entity" instead of "https" and "wiki"... and you need to set the "allowed values" to "any" in the feature settings of the "identifier" feature in the "named entity" layer - then it should work.
-- Richard
Michaela Polónyová
Oct 11, 2021, 7:28:17 AM10/11/21
to incepti...@googlegroups.com
Hi Richard,
I just wanted to thank you for your quick and on-point assistance - as of now, everything works as we needed 🎉🙇
Kind regards,
Michaela
st 29. 9. 2021 v 21:41 odesílatel Richard Eckart de Castilho <richard...@gmail.com> napsal:
--
You received this message because you are subscribed to a topic in the Google Groups "inception-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/inception-users/D78jNNwhxCw/unsubscribe.
To unsubscribe from this group and all its topics, send an email to inception-use...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/inception-users/D7EF3378-5D99-4D1D-B9E1-E090D57CD559%40gmail.com.
Reply all
Reply to author
Forward
0 new messages