BGP Table grown too big

Willy Sutrisno
Ada yang mengalaminya di Indonesia mungkin, ISP atau NAP yang routernya tidak bisa handle BGP table >512k routes ?
http://www.zdnet.com/internet-hiccups-today-youre-not-alone-heres-why-7000032566/
- RSEmail AInternet hiccups today? You're not alone. Here's why
Summary: It's not just you. Many Internet providers have been having trouble as they run into long expected (but not adequately prepared for) routing table problems.
By Steven J. Vaughan-Nichols for Networking | August 12, 2014 -- 21:52 GMT (05:52 SGT)
 (Image via CNET/CBS Interactive)
(Image via CNET/CBS Interactive)If you found your Internet speed has been pathetic today and some sites wouldn't load at all, you're not alone.
 The Border Gateway Protocol (BGP) routing tables hit the limit, and older routers failed — taking some of the Internet with them.
The Border Gateway Protocol (BGP) routing tables hit the limit, and older routers failed — taking some of the Internet with them.Many tier-one Internet service providers (ISPs), and in turn, the last mile ISPs they support, experienced technical problems that resulted in bad service throughout the US and some parts of Canada.
According to postings in the North American Network Operators Group (NANOG) mailing list, the professional association for Internet engineering and architecture, there have been "major problems with multiple ISPs since around 4-5 AM EST."
According to NANOG, and complaints tracker DownDetector, many Internet providers — including Comcast, Level 3, AT&T, Cogent, Sprint, Verizon, and others — have suffered from serious performance problems at various times on Tuesday.
And they won't be the last.
Most of the ISPs have not commented on these disruptions. Level 3, in a statement, did say, "Our network is currently experiencing limited service disruptions affecting some of our customers. Ensuring the stability of our network and communications services is our primary concern and we are dedicated to minimizing impact to our customers. Our technicians are currently working to restore services as quickly as possible, and we are in close contact with affected customers.”
As a result of these problems, some Web hosting companies, such as LiquidWeb, and its sites have been effectively knocked offline.

The company reported on Twitter that the problem first appeared to be the result of a "large network provider is performing maintenance."
While an ISP maintenance activity may have played a factor, the real problem was that Border Gateway Protocol (BGP)routing tables have grown too large for some top-level Internet routers to handle. The result was that these routers could no longer properly handle Internet traffic.
BGP is the routing protocol used to share the master routes, or map, of the Internet. On top of this the Domain Name System (DNS) is layered so that when you click on "www.zdnet.com" you're taken to ZDNet.
When the BGP maps grow too large for their routers' memory then, as the Internet Storm Center said, "BGP is flapping."
Dutch Internet expert Teun Vink explained:
"Some routing tables hit 512K routes today. Some old hardware and software can't handle that and either crash or ignore newly learned routes. So this may cause some disturbances in the Force."
By this, Vink meant that some routers have only a limited amount of memory for their maps of the Internet. These BGP routing tables are typically kept in a specialized kind of memory called Tertiary Content Addressable Memory (TCAM). Once there were more than 512,000 routes, many older routers could no longer properly track the routes.
Adding insult to injury, Internet engineers who were paying attention, knew this problem was coming was early as May. As one IPv4 address reselling site explained:
"We expect to see/hear of some bugs once the Internet reaches 512k routes. If the growth of the routing table will continue as in the past months, we expect to see 512k routes in the global routing table not earlier than August and not later than October."
Lucky us. We got there early.
Cisco also warned its customers in May that this BGP problem was coming and that, in particular, a number of routers and networking products would be affected. There are workarounds, and, of course the equipment could have been replaced. But, in all too many cases this was not done.
Still, it could have been far worse. Instead of sporadic Internet problems we could have seen entire swathes of the Internet go out of service for hours at a time.
Sources at several major tier-one ISPs admitted that the BGP routing map problem was indeed the source of the service troubles. All of them are working on correcting it as quickly as possible.
One site, the well-regarded security service provider LastPass, appeared at first to be impacted by the problem. In the event, LastPass went down because one of its datacenters had failed.
LastPass' services have since been restored.
Unfortunately, we can expect more hiccups on the Internet as ISPs continue to deal with the BGP problem. In a week or two the problem should be fixed for once and for all, but as older routers are upgraded or replaced we will see more Internet blockages and slowdowns.
Willy Sutrisno
What caused today’s Internet hiccup
Posted by Andree Toonk - August 13, 2014Like others, you may have noticed some instability and general sluggishness on the Internet today. In this post we’ll take a closer look at what happened, including some of the BGP details!
At around 8am UTC Internet users on different mailing lists, forums and twitter, reported slow connectivity and intermediate outages. Examples can be found on the Outages mailing list . Company support site such as liquidweb and of course on Nanog
How stable is the Internet
So how do we know if the Internet was really unstable today? One way to look at this is by looking at the outages visible in BGP over the last 12 months. On average we see outages for about 6,033 unique prefixes per day, affecting on average 1470 unique Autonomous Systems. These numbers are global averages and it’s worth noting that certain networks or geographical areas are more stable than others.

BGP stability and outages differ per country.
If we look at the number of detected outages by BGPmon today we see outage for 12,563 unique prefixes affecting 2,587unique Autonomous Systems. This is well above the daily average and indeed both the unique prefixes and the unique Autonomous Systems count are the highest we’ve seen in the last 12 months. Based on this data it is fair to say that Internet did indeed suffer from more hiccups than normally.
The graph below shows the number of Autonmous systems that were affected by an outage just over the last month. Note that most outage happen during week days and that the Internet is in fact much more stable during the weekend.

Number of ASns affected by outages each day
What caused the instability
Folks quickly started to speculate that this might be related to a known default limitation in older Cisco routers. These routers have a default limit of 512K routing entries in their TCAM memory. The BGP routing table size depends on a number of variables. The primary contributors are Internal, or local routes (more specific and VPN routes used only in the local AS) and External routes. These External routes are all the routes of everyone on the Internet, we sometimes refer to this as the global routing table of Default Free Zone (DFZ). For most networks on the Internet today the global routing table is the major contributor, while local routes vary from a few dozen to a few hundred. Only a small percentage of the networks have a few thousand Internal routes.
The size of the global routing table today (August 12 2014) is about 500k, this number marginally varies per provider. Let’s compare a few major ISP’s. The table below shows the number of IPv4 prefixes received per provider on a full feed BGP session.
| Provider | Location | Number of IPv4 routes on full BGP feed |
| Level3 | Amsterdam | 497,869 |
| GTT | Amsterdam | 499,272 |
| NTT | Amsterdam | 499,610 |
| Telstra | Sydney | 491,522 |
| NTT | Sydney | 500,265 |
| Singtel | Singapore | 501,061 |
| NTT | Singapore | 499,830 |
| Level3 | Chicago | 497,470 |
| GTT | Chicago | 499,326 |
| NTT | Chicago | 499,523 |
The table above shows that depending on the provider and location the numbers differ slightly, but are indeed very close. It also shows that right now the number of prefixes is still several thousands under the 512,000 limit so it shouldn’t be an issue. However when we take a closer look at our BGP telemetry we see that starting at 07:48 UTC about 15,000 new prefixes were introduced into the global routing table.
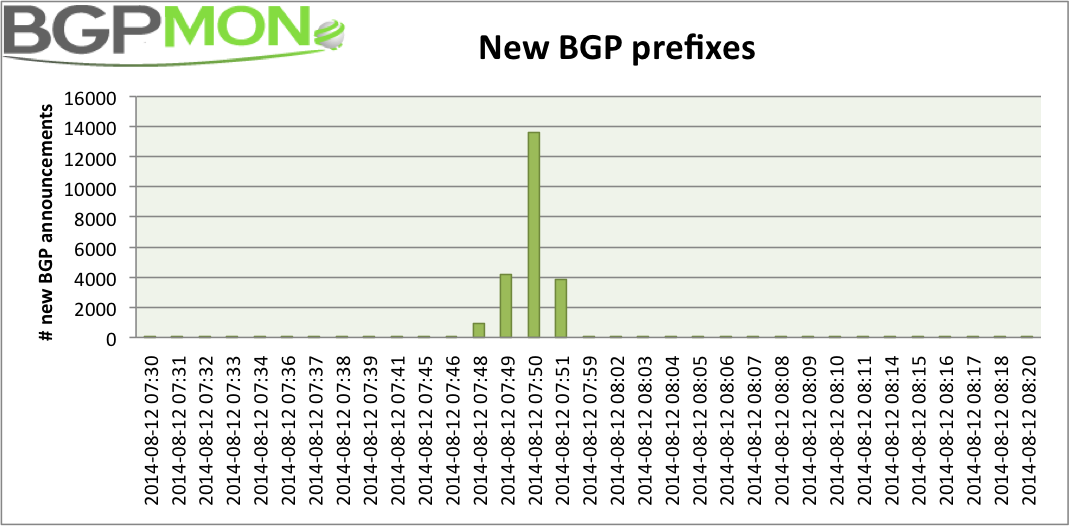
Note that the timestamps of the introduction of these new prefixes overlap with the reports of hickups on the Internet today. The picture below shows the number of prefixes received by a Level3 customer in Chicago and shows how the prefix count peaked at around 8am UTC to 515,000 prefixes and then dropped back to 500,000 prefixes. Clearly visible as well is that the 15,000 new prefixes were only visible for a few minutes.

BGP feed Level3, Chicago
What caused the increase in prefixes.
Now that we know that there was indeed an increase in prefixes it is time to look into where these prefixes came from. Looking at the our data we quickly see that the new prefixes being announced at that time were almost all originated by the Verizon Autonomous systems 701 and 705. All of the new routing entries appear to be more specific announcements for their larger aggregate blocks. For example BGPmon detected 170 more specific /24 routes for the larger 72.69.0.0/16 block.
So whatever happened internally at Verizon caused aggregation for these prefixes to fail which resulted in the introduction of thousands of new /24 routes into the global routing table. This caused the routing table to temporarily reach 515,000 prefixes and that caused issues for older Cisco routers.
Luckily Verizon quickly solved the de-aggregation problem, so we’re good for now. However the Internet routing table will continue to grow organically and we will reach the 512,000 limit soon again. The good news is that there’s a solution for those operating these older cisco routers. The 512,000 route limitation can be increased to a higher number, for details see this Cisco doc.
Willy Sutrisno
Internet Touches Half Million Routes: Outages Possible Next Week
13 AUG, 2014 | 10:14 AM | BY JIM COWIEThere was minor consternation in Internet engineering circles today, as the number of IPv4 networks worldwide briefly touched another magic “power of 2″ size limit. As it turns out, 512K (524,288 to be exact, or 2-to-the-19th power) is the maximum number of routes supported by the default TCAM configuration on certain aging hardware platforms.
The problem is real, and we still haven’t seen the full effects, because most of the Internet hasn’t yet experienced the conditions that could cause problems for underprovisioned equipment. Everyone on the Internet has a slightly different idea of how big the global routing table is, thanks to slightly different local business rules about peering and aggregation (the merging of very similar routes to close-by parts of the Internet address space). Everyone has a slightly different perspective, but the consensus estimate is indeed just under 512K, and marching higher with time.
The real test, when large providers commonly believe that the Internet contains 512K routes, and pass that along to all their customers as a consensus representation of Internet structure, will start later this week, and will be felt nearly everywhere by the end of next week.
Enterprises that rely on the Internet for delivery of service should pay close attention to the latency and reachability of the paths to customers in the coming weeks, in order to identify affected service providers upstream and work around them while they perform appropriate upgrades to their infrastructure.
| Here’s a plot of monthly routing table sizes from our peers, over the last several years. Note that there’s no good exact opinion about the One True Size of the Internet — every provider we talk to has a slightly different guess. The peak of the distribution today (the consensus) is actually only about 502,000 routes, but recognizably valid answers can range from 497,000 to 511,000, and a few have straggled across the 512,000 line already. The number varies from minute to minute as well, and this close to 512K, any minor event, such as a deaggregation by a large provider (fragmenting a network route into smaller ones for traffic engineering purposes) could push the global collective past the critical point. |  |
PUTTING THIS EVENT IN PERSPECTIVE: DON’T PANIC
It’s important to put this all in proper perspective (and yes, friends from the media who cover Internet infrastructure issues, I’m especially hoping you read down to this paragraph).
This situation is more of an annoyance than a real Internet-wide threat. Most routers in use today at midsize to large service providers, and certainly all of the routers that operate the core infrastructure of the Internet, have plenty of room to deal with the Internet’s current span, because they were provisioned that way by sensible network operators.
Affected boxes cause local connectivity problems for the network service providers who still run them, so they will be identified quickly and upgraded as we pass the threshold. Their instability in turn causes some minor additional load on adjacent routers.
But the overall stability of the global routing system should be unaffected. In terms of a threat, this isn’t nearly in the same class as some poison-message scenarios we’ve described before,which combine router failure with contagion dynamics.
ORIGINS OF THE PROBLEM
This has been coming for some time. The Internet keeps growing, which is what it does best. There’s very little indication that the current shortage of IPv4 space has done anything to dissuade new autonomous systems (enterprises, universities, service providers, etc.) from connecting to the Internet and expecting to route some space of their own.
Ironically, exhaustion may be speeding up the growth, as enterprises and service providers learn to use tricks like carrier-grade NAT to get their jobs done in tinier and tinier fragments of the remaining IPv4 space.
| The routing table in every border router on Earth has to carry a route to each and every one of those tiny fragments, as free addressable space gets tighter and tighter. And every IPv4 route takes basically the same amount of memory in the router, whether it’s an enormous university-sized block of 64K IP addresses, or a little taste of 256 IP addresses (the smallest generally routable block). That relentless pressure has pushed the distribution of global routing table sizes up and up, as more and more people join the Internet, and find themselves fighting over smaller and smaller crumbs of IPv4 space. |  |
And that means that 512K is right around the corner for everyone on Earth, as early as next week. Here’s a plot of the distribution of routing table size, marching forward, from May 2014 (red) through July 2014 (purple) and up to today (blue). This wave only propagates one way. Someday, sooner than you think, we’ll be facing the 1024K routing table challenge.
The Good NewsSo far, as the first providers cross the 512K line, we’re not seeing real, serious evidence of increased Internet instability, at least not at the levels that would affect enterprises and service providers worldwide in meaningful ways. Some people who are downstream of affected equipment may be noticing early problems, if they find themselves learning 512K routes today thanks to a deaggregation event that injects thousands of transient routes. Here we can see the percentage of the Internet that’s affected by routing instability on a daily basis, the kind of flickering change that we’d expect to see if routers everywhere were rebooting. Typically it’s 3 to 7 percent and obeys cycles based on human timescale: less on the weekends, when networking professionals leave the Internet alone, less during the December holidays. We see some increase in 2014, but in recent months and days, no clear trend higher in instability. |   |
What Comes Next
This event won’t be over tomorrow; in fact, it has barely begun. As the routing table size distribution creeps to the right, the number of routers in the world who “see” 512K+ routes will steadily increase. Within a few weeks, nearly every piece of vulnerable gear will have been discovered, as 512K+ becomes the global consensus opinion. We don’t know how many machines that represents, and we don’t know what the net impact will be on local Internet connectivity before it all gets sorted out.
There is irony lurking here, of course, if you read the advisories. You can change the default configuration to reclaim more TCAM for IPv4 .. but only at the expense of support for IPv6, the “next generation” Internet addressing scheme that continues to struggle for widespread adoption. Sadly, this elderly gear was shipped at a time when the world was full of hope for the emergence of a real, live, flourishing IPv6 routing table. There’s far too much TCAM alloted to IPv6, as a result (in at least one case, 256K routes, when the current IPv6 routing table still requires fewer than 20K).
You can reclaim most of that precious router memory for IPv4, and you’ll be fine again .. at the expense of evicting your IPv6 routes from TCAM. That’s probably a decent bet, since anyone who failed to future-proof their deployment and is still running this older gear probably has very, very little IPv6 traffic on their network anyway. For IPv6 aficionados who are are tracking the continuing growth and robust good health of the “legacy” IPv4 Internet, that’s called “cold comfort.”