CSV Import and Access Points
298 views
Skip to first unread message

Scott Breeden
Feb 3, 2022, 4:19:18 PM2/3/22
to AtoM Users
When importing archival descriptions from a non-AtoM source using AtoM's ISAD 2.6 CSV template, would an Extent and Medium value be equivalent to a Genre Access Point value plus a quantity?
Or to put it another way, could a Genre Access Point be generated automatically from every Extent and Medium value? Why or why not would this be a good idea?
Use of Genre Access Points seems rather spotty in AtoM sites that I have visited, including https://demo.accesstomemory.org.
-Scott Breeden

Dan Gillean
Feb 3, 2022, 5:01:58 PM2/3/22
to ICA-AtoM Users
Hi Scott,
Currently Extent and Medium is a free-text field in AtoM, meaning what is entered is not controlled in any way. While the Genres taxonomy comes pre-populated with terms from the Basic Genre Terms for Cultural Heritage Materials vocabulary maintained by the Library of Congress, those terms are not comprehensive, nor are they universally translated, and the taxonomy itself is user editable - meaning terms may be added, changed, or deleted by authorized users.
These factors all pose problems to automation at present.
There's also a subtle but present distinction between format and genre that, depending on your terms, don't always translate. I wouldn't usually expect to see "Correspondence" or "Leaflets" appearing in an Extent statement, but I might see "Textual document" or similar, as well as number of pages, or even paper type and size possibly - but those don't translate back to Genre terms. With certain media you also run into the distinction between the content and the carrier - for example, the aspect ratio and color profile of a film, versus the size and type of tape it's on, etc.
Additionally, this opens a broader more philosophical question about whether a system *should* automatically add metadata that an archivist hasn't explicitly chosen to appear, unless they are presented as suggestions that can be ignored or modified at will.
A relevant example: In working with a client using AtoM's Dublin Core template, an old behavior recently came to light - when a digital object (like an image) was attached to a DC description, AtoM would automatically add a Format entry (using mime types as a controlled vocabulary - e.g. image/jpeg) and a Type entry (using DC's suggested controlled vocabulary) to the record. Because this was done programmatically, these changes were not in fact in the edit page itself (or the database) and could not be removed without also removing the image.
The problem we discovered is that an associated digital object is not necessarily the object being described in the record itself. The DC record in question was about a museum object, with very different type/format properties - the image merely provided a view of that object. The archivists in question felt that the automatic additions were misleading to end users, but they couldn't remove them. I had to ask around, and it seems that this is a behavior that had been in AtoM for years, likely added by Artefactual's founder in an early iteration of the DC template, and never questioned since the DC template is less used than others.
In the end, we have now filed a bug ticket to remove this behavior from the next version of AtoM:
If users want to add this metadata, they still can - but they should always have a choice.
I do believe that machine learning and natural language processing will continue to improve and become increasingly relevant to archivists processing at scale, particularly with born-digital content. There are already some very interesting experiments that incorporate such techniques - one of my favorite being the Linked Jazz project out of Pratt. However, even they have a QA process in place, and ML is currently only used for name extraction and basic relationships - all the refining happens via expert crowdsourcing.
For now, there's no easy way to implement what you're asking for in AtoM, and in my personal opinion there's not always a direct correlation between an extent statement and genre terms, though in the future there might be ways to suggest terms based on what is entered.
he / him
--
You received this message because you are subscribed to the Google Groups "AtoM Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/fafffeca-d91e-4368-a04b-b0d296dbb719n%40googlegroups.com.
Scott Breeden
Feb 5, 2022, 5:53:53 PM2/5/22
to AtoM Users
Dan,
Once again I am in awe of your ability to whip out detailed replies so quickly.
For the project that I'm working on, I wasn't thinking in terms of changing AtoM anytime soon. I have written a program to generate AtoM-friendly CSV from my source database, and I'm generally happy with the results. Things like names, dates, subjects, etc. are no problem. But extentAndMedium and genreAccessPoints are a bit of a puzzle. I could set those to anything I feel like, but what SHOULD I set them to?
Searching for examples, I found archival descriptions like one on the AtoM demo site where "clippings" appeared under both "Extent and medium" and "Genre access points." At the Oregon Historical Society site, "lantern slides" got the same treatment. To me, this seemed like redundant data.
I understand your point about needing to distinguish between format and genre at times: I think that a movie could have a "Betamax cassette" format and a "film noir" genre. But "clippings" could be both a format and a genre. So, Marshall McLuhan is sometimes correct--the medium is the message.
My source database includes a field with values like "book," "drawing," "photograph," etc., which almost perfectly match some LOC basic genre terms. But I assume that terms like these would also be acceptable in extent and medium specifications. Not "poetry," though--I wouldn't measure shelf space in poems. And this illustrates something that I think is better handled in EAD than in ISAD(G), through separate <physdesc> and <genreform> elements for describing storage vs. access. I see now, reading the fine print, that AtoM allows embedding some EAD subelements in the Extent and medium text. I might make use of that.
The good news in my particular case is that the source field containing "book," "drawing," "photograph," etc. is not free-text: It uses a controlled vocabulary of about 20 terms. So when I process these values, I could simply sort them into extentAndMedium or genreAccessPoints, or both, or neither. The source field is also repeatable, so a book of poetry could have both "book" and "poetry" checked.
Once again I am in awe of your ability to whip out detailed replies so quickly.
For the project that I'm working on, I wasn't thinking in terms of changing AtoM anytime soon. I have written a program to generate AtoM-friendly CSV from my source database, and I'm generally happy with the results. Things like names, dates, subjects, etc. are no problem. But extentAndMedium and genreAccessPoints are a bit of a puzzle. I could set those to anything I feel like, but what SHOULD I set them to?
Searching for examples, I found archival descriptions like one on the AtoM demo site where "clippings" appeared under both "Extent and medium" and "Genre access points." At the Oregon Historical Society site, "lantern slides" got the same treatment. To me, this seemed like redundant data.
I understand your point about needing to distinguish between format and genre at times: I think that a movie could have a "Betamax cassette" format and a "film noir" genre. But "clippings" could be both a format and a genre. So, Marshall McLuhan is sometimes correct--the medium is the message.
My source database includes a field with values like "book," "drawing," "photograph," etc., which almost perfectly match some LOC basic genre terms. But I assume that terms like these would also be acceptable in extent and medium specifications. Not "poetry," though--I wouldn't measure shelf space in poems. And this illustrates something that I think is better handled in EAD than in ISAD(G), through separate <physdesc> and <genreform> elements for describing storage vs. access. I see now, reading the fine print, that AtoM allows embedding some EAD subelements in the Extent and medium text. I might make use of that.
The good news in my particular case is that the source field containing "book," "drawing," "photograph," etc. is not free-text: It uses a controlled vocabulary of about 20 terms. So when I process these values, I could simply sort them into extentAndMedium or genreAccessPoints, or both, or neither. The source field is also repeatable, so a book of poetry could have both "book" and "poetry" checked.
Although AtoM's Advanced Search supports searching for particular Extent and medium values, you apparently have to know exactly what to search for ahead of time. The advantage of access points is that they are listed under "Narrow your search by" facet filters on search results pages. So I think I would prefer to create genre access points from genre-y source values whenever possible.
For what I'm doing, the only change to AtoM that I think would be an improvement would be changing the threshold for displaying facet filters. Currently, the "Genre Access Points" list is not displayed unless more than one archival description has a genre access point. I would rather see the list even if there were only one such description.
-Scott Breeden
Dan Gillean
Feb 7, 2022, 9:10:57 AM2/7/22
to ICA-AtoM Users
Hi Scott,
Ultimately, this is going to be a matter informed by personal preference, local conventions or policies, and standards-based guidance. AtoM is designed to be a permissive system, rather than a prescriptive one that enforces certain descriptive practices. For example, while AtoM will provide an authenticated user with a warning if there are fields in a template left blank that are considered mandatory in the related standard - but you can actually save a completely blank record in AtoM without causing an error.
I think in many ways you've already defined the core of the issue well - adding information in both the extent statement and a genre access point could be redundant, but the purpose of access points is to provide a controlled vocabulary offering users entry into related material from a common term that's easier to find without knowing it in advance.
Here's what the U.S. DACS standard has to say about access points:
----------------------------------
Then there is the matter of “access points.” While archival description is narrative, and electronic catalogs and databases typically provide full-text searching of every word in the text, information systems often also identify specific terms, codes, concepts, and names for which specialized indexes are created to permit faster and more precise searching. In a manual environment, these terms appear as entry headings on catalog records. A variety of protocols, both standardized and local, determine which of the names and terms in a description become “access points” for searching in this way, as well as the form in which they appear. For example, Element 3.1 of DACS instructs the archivist to include in the scope and content element information about the “subject matter to which the records pertain, such as topics, events, people, and organizations.” The natural language terminology used to describe such a topic in the scope and content statement must be subsequently translated into the formal syntax of a subject heading, as specified by a standardized thesaurus like the Library of Congress Authorities. For example, a collection might contain information about railroads in Montana. After consulting the Library of Congress subject headings and reviewing the directions in the Subject Cataloging Manual: Subject Headings on the formulation of compound subject terms, the archivist will establish the access point as Railroads—Montana. When embedded in a MARC 21 record, the coding will be
650 b0 ‡a Railroads ‡z Montana
If this data is placed in an EAD finding aid, the resulting encoding will look like this:
<controlaccess> <subject source="lcsh">Railroads--Montana</subject> </controlaccess>
Once rendered in a consistent form and included in electronic indexes or as headings in a card file, such standardized data become a powerful tool for researchers to discover materials related to that topic.
It is a local decision as to which names, terms, and concepts found in a description will be included as formal access points, but repositories should provide them in all types of descriptions. Such indexing becomes increasingly important as archivists make encoded finding aids and digital content available to end users through a variety of repository based and consortial online resource discovery tools.
650 b0 ‡a Railroads ‡z Montana
If this data is placed in an EAD finding aid, the resulting encoding will look like this:
<controlaccess> <subject source="lcsh">Railroads--Montana</subject> </controlaccess>
Once rendered in a consistent form and included in electronic indexes or as headings in a card file, such standardized data become a powerful tool for researchers to discover materials related to that topic.
It is a local decision as to which names, terms, and concepts found in a description will be included as formal access points, but repositories should provide them in all types of descriptions. Such indexing becomes increasingly important as archivists make encoded finding aids and digital content available to end users through a variety of repository based and consortial online resource discovery tools.
----------------------------------
On genre access points specifically:
----------------------------------
Documentary Forms
Terms that indicate the documentary form(s) or intellectual characteristics of the records being described (e.g., minutes, diaries, reports, watercolors, or documentaries) provide the user with an indication of the content of the materials based on an understanding of the common properties of particular document types. For example, one can deduce the contents of ledgers because they are a standard form of accounting record, one that typically contains certain types of data. Documentary forms are most often noted in the following areas of the descriptive record:
- Title Element (2.3)
- Extent Element (2.5)
- Scope and Content Element (3.1)
----------------------------------
What I take from this is mostly that a certain amount of duplication is expected, since the source of your access points is often extracted from other generally free-text fields such as Extent, Scope and Content, Creator names, etc. However, access points provide a different function in the description, "created to permit faster and more precise searching" in an otherwise more narrative description. Ultimately, you're going to have to decide what will work best for your metadata and your use of AtoM.
Regarding your other point:
For what I'm doing, the only change to AtoM that I think would be an improvement would be changing the threshold for displaying facet filters. Currently, the "Genre Access Points" list is not displayed unless more than one archival description has a genre access point. I would rather see the list even if there were only one such description.
I will ask our developers if there's any easy way to make a local modification to the facets display so that only those headings with zero results are hidden by default, instead of those with either zero or one result. I'm not a developer so I can't comment on what to change or what other files I might be missing, but I found the following 3 elements related to facet display in AtoM's code, in case you're more PHP savvy than myself:
- https://github.com/artefactual/atom/blob/HEAD/apps/qubit/modules/term/templates/_sidebar.php#L45-L52
- https://github.com/artefactual/atom/blob/HEAD/apps/qubit/modules/informationobject/templates/browseSuccess.php#L97-L102
- https://github.com/artefactual/atom/blob/HEAD/apps/qubit/modules/search/templates/_aggregation.php
In the meantime, one minor thing you could possibly do without any code modifications to improve end-user discoverability would be to add a link to the Genre taxonomy browse page in the global Browse menu, using the Admin > Menus module, like so:
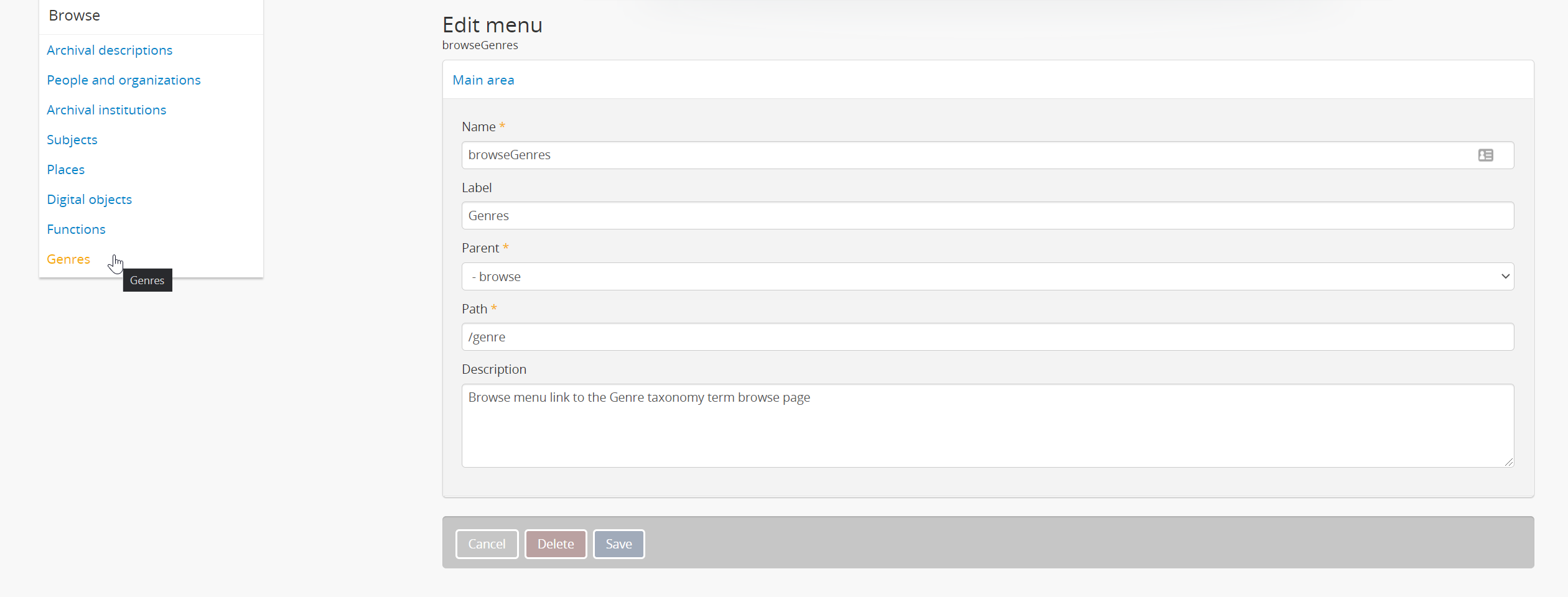
Not a perfect solution, but it may help.
Cheers,
he / him
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/ff46cdb5-d502-473e-a3cd-2e4f9e5ac168n%40googlegroups.com.
Scott Breeden
Feb 8, 2022, 1:59:06 PM2/8/22
to AtoM Users
Dan,
OK, you've convinced me that if the same word appears in both "Extent and medium" and "Genre access point," that might make sense, and it is not necessarily an error.
As a matter of fact, I did read the DACS standard before I posted my question--I remembered that there was an example of something involving Wyoming. It made sense, but I guess the point didn't quite sink in. Also, that was DACS, so I went ahead and asked a more AtoM-specific question anyway.
Thanks for the suggestion about modifying the Browse menu. That's in an area of AtoM that I haven't really explored.
Also, thank you for looking into changing AtoM's facet display. In the third file that you cited, _aggegation.php, I discovered that on the first line, if I change this:
count($aggs[$name]) < 2
to this:
count($aggs[$name]) < 1
then I get exactly the results that I was expecting: The GENRE list appears even when there is only one genre access point. Perfect! Maybe I'll keep my copy of
_aggegation.php patched for now, just like my patched version of whatever the file was that was preventing creation of PDF thumbnail images.
I suspect that on that same line of code in _aggretaion.php, the "languages" threshold ought to be changed from 3 to 2, but I did not investigate that. I will leave that up to you since, despite your claim of not being a developer, I noticed that you were the last person to modify this file, on line 1, to fix Bug #13299. Since I read that on the Internet, I know that it must be true.
-Scott Breeden
Dan Gillean
Feb 9, 2022, 9:03:21 AM2/9/22
to ICA-AtoM Users
Hi Scott,
I'm glad you were able to find the right place to modify the code yourself! Thanks for sharing your solution.
Ha, ok you're right, I do occasionally manage to submit small pull requests - generally they are either 1 line changes I can figure out with a bit of experimentation and good code review from my colleagues; a suggestion a developer has made but hasn't had time to implement; or else a suggestion from the forum that I've confirmed works (and which, like all PRs, also gets code reviewed by our team).
In that particular case, it looks like previously the threshold was 2 previously, being applied to all facets equally. The reason for the change is described on the related ticket itself:
Currently in our facet filters, if there is a filter with zero or only one facet, then the whole filter is hidden, since it is not useful to the end user to have nothing to facet against, or a single facet common to all the current results.
With the language facet, this doesn't happen because there is always a separate count of "Unique records," in addition to the current language of the available records (e.g. English) - so there are at least 2 facets always present in this facet filter, even in a monolingual site with all other cultures removed (via Admin > Settings > i18n languages) and the language menu hidden.
Some users have reported finding this confusing for their researchers, and they would prefer that the facet does not display unnecessarily. Given that it is not currently displaying useful data for monolingual sites (and given the 0 or 1 hiding behavior of other facets), I consider this a bug.
I think we're unlikely to change this in the public release at this time, given that it's a recent fix that brings the language facet behavior in line with the other current default behaviors. However, you could likely change it just by removing the clause I added in the related commit!
RE:
Maybe I'll keep my copy of _aggegation.php patched for now, just like my patched version of whatever the file was that was preventing creation of PDF thumbnail images.
I recommend keeping a file somewhere with notes on any local modifications - what they are and why - because you will need to manually reapply them after any upgrade in the future.
Cheers,
he / him
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/bd81ec1e-8f83-4667-b7a5-d1b90ce68e42n%40googlegroups.com.
Scott Breeden
Feb 10, 2022, 5:49:50 PM2/10/22
to AtoM Users
Dan,
In _aggegation.php, even though I said that I wasn't going to investigate whether the "languages" threshold on line 1 ought to be changed from 3 to 2, I did anyway. What I discovered was that no, 3 is correct.
The change that you made, inspired by Monica Wood's version at https://groups.google.com/g/ica-atom-users/c/134crsm9gEs, does exactly what is desired: display a language list only if it contains something useful in narrowing the search. If the only things on the list simply restate the original search results, then there can be no narrowing, so displaying the list is pointless.
The unique aspect of the Language facet list is that it always starts out with two items containing the original description count: "Unique records," plus "English" or whatever the default language is. In neither case would the number narrow the search, so the test for displaying a language list boils down to whether it contains more than 2 items.
The other facet lists are different: They do not start out with two unnecessary items, and all such items narrow the result in some way. So the test for displaying these lists can be simply whether they contain any items.
Given these facts, it follows that in the current (2.6.4) release, the language facet behavior is in fact NOT in alignment
with the other facet behaviors: A language list is displayed if it contains at least one item more than the default. The other lists are not displayed unless they contain at least two items more than the default. Why?
In fact, prior to the AtoM 2.3 release, the threshold for non-language facet list display was apparently one item, not two. These are the first few lines of
_aggegation.php from the Git "stable 2.2.x" release of Jan 22, 2015:
<?php if (isset($sf_request->$facet) || (isset($open) && $open
&& isset($pager->facets[$facet]) && 0 < count($pager->facets[$facet]['terms']))): ?>
<section class="facet open">
<?php else: ?>
<section class="facet">
<?php endif; ?>
&& isset($pager->facets[$facet]) && 0 < count($pager->facets[$facet]['terms']))): ?>
<section class="facet open">
<?php else: ?>
<section class="facet">
<?php endif; ?>
In the "stable 2.3.x " release of Dec 11, 2015, this became:
<?php if (isset($pager->facets[$facet]) && (isset($filters[$facet])
|| count($pager->facets[$facet]['terms']) > 1)): ?>
<?php if (isset($sf_request->$facet) || (isset($open) && $open
&& 0 < count($pager->facets[$facet]['terms']))): ?>
<section class="facet open">
<?php else: ?>
<section class="facet">
<?php endif; ?>
|| count($pager->facets[$facet]['terms']) > 1)): ?>
<?php if (isset($sf_request->$facet) || (isset($open) && $open
&& 0 < count($pager->facets[$facet]['terms']))): ?>
<section class="facet open">
<?php else: ?>
<section class="facet">
<?php endif; ?>
Note that the count() test changed from 0 to 1. This change appeared as part of commit 4a947c9 on Nov 15, 2015. This was a big set of changes described as "Merge IO browse and adv. search pages, refs #9141." The commit comments include this line:
- Don't show facets with only one item unless it's selected
However, there is no mention of "facets with only one item" at https://projects.artefactual.com/issues/9141. Did anybody request this facet threshold change? If so, why?
When I described my patch for displaying genre facet lists even when they contained only one item, I meant to add that this fixed not only genre, but also subjects, places, names, etc.
One way to demonstrate the current (peculiar) display of facets like subjects and places is at the AtoM
demo installation, https://demo.accesstomemory.org. Log in, browse Archival descriptions, then in the Level of Description facet list, click on Series. This should generate a single result: the Jim Heldmann fonds. The Subject facet should now show two items: Children and youth, and Education. If you edit the archival description and delete the Education access point, then after you save the change, the Subject facet disappears. What happened to those poor Children and youth? Aren't they still worth mentioning?
-Scott Breeden
Dan Gillean
Feb 11, 2022, 10:27:46 AM2/11/22
to ICA-AtoM Users
Hi Scott,
Nice work tracking down the original source of the language facet changes! Sometimes everything blurs a bit over time in my memory.
Regarding the unique behavior of the language facet and this "Unique records" option, this goes back to the 2.1 release. See:
It's been quite a long time, but if I recall correctly, the reported problem had to do with multilingual sites that had some content in language A, some in language B, and some that had translations (e.g. A with B, B with A, etc). Depending on how you faceted the results, you might find duplicates, and strange facet count totals that didn't match the expected total number of records or make it clear how many records there actually were. The "Unique records" was our attempt to address that feedback, so that you could filter the results to only show original source record languages, and not just say English ones (some of which might be incomplete translations - for example, a full ISAD-compliant description with just the title translated).
- Don't show facets with only one item unless it's selected
However, there is no mention of "facets with only one item" at https://projects.artefactual.com/issues/9141. Did anybody request this facet threshold change? If so, why?
I don't recall if we got specific feedback on this, but we do regularly receive feedback from institutional users that many of their researchers (i.e. public end users) feel overwhelmed by all the page elements and options on AtoM search/browse pages. In general, this was a question of usability, and trying to avoid displaying additional information that would not help a user to refine their search.
Keep in mind that what follows are just my own thoughts, and not necessarily an Artefactual-wide position!
Facets are typically used to allow the progressive refinement of the search results by restricting the records that match the query based on their shared properties. By selecting one or more values of some of the facets, the result set is narrowed down to only those records that possess the selected values. The primary goal of the search page is not necessarily to display detailed metadata properties of the records, but rather enough information for a user to determine if they have found records of interest - and if not, to provide further options for narrowing the results, so they can get to records of interest. When there is a single facet element, applying it will not change the result set - if all records have the same subject access point of "Education" then applying the filter will not change the results and was not part of the user's original query parameters, and the user will still see the subject access point when viewing the record (and can go to a general search for all descriptions with the Education access point by clicking on the access point hyperlink on the description).
One way to demonstrate the current (peculiar) display of facets like subjects and places is at the AtoM demo installation, https://demo.accesstomemory.org. Log in, browse Archival descriptions, then in the Level of Description facet list, click on Series. This should generate a single result: the Jim Heldmann fonds. The Subject facet should now show two items: Children and youth, and Education. If you edit the archival description and delete the Education access point, then after you save the change, the Subject facet disappears. What happened to those poor Children and youth? Aren't they still worth mentioning?
I see what you're saying here. Perhaps it would be more helpful for users to know there are subject terms applied here, even if there's only one term and one description result. However, it's also a bit of an edge case. If you're starting your search by looking for series, and have already narrowed the results to 1 record, does it change the likelihood you will click through to the full description if the facets are displayed or not? If instead you are interested in "Children and youth" and not series-level descriptions, might the original search query have started differently?
That said, I can see examples that don't auto-hide the way that we do - for example, the DPLA site seems to behave more as you expect. An example:
Despite the fact that I've already narrowed the results to "interactive resource", the second Type filter (image) is still available, even though it applies to both results. These are filters rather than facets, but point taken.
In any case, it sounds like you've figured out how to modify the current default facet behavior locally if you want. With an international user community made of many different types and sizes of organizations, it's often very hard for us to find the right balance and implementation of any feature. So far, this is the first feedback that I can recall receiving about this change since it was introduced in the 2.3 release. Ideally, there'd be a setting for users to be able to choose the default behavior - but that also adds complexity and an additional maintenance burden for us.
Long-term, I would love to see filters instead of facets in AtoM, so users can apply multiple filters from a single category, and we can have options for expanding the available filters beyond the top ten and even searching when there are many possible filters in a single category. The UI may look a bit dated based on contemporary web design practices, but I've always liked how this is implemented in the Getty Search Gateway:
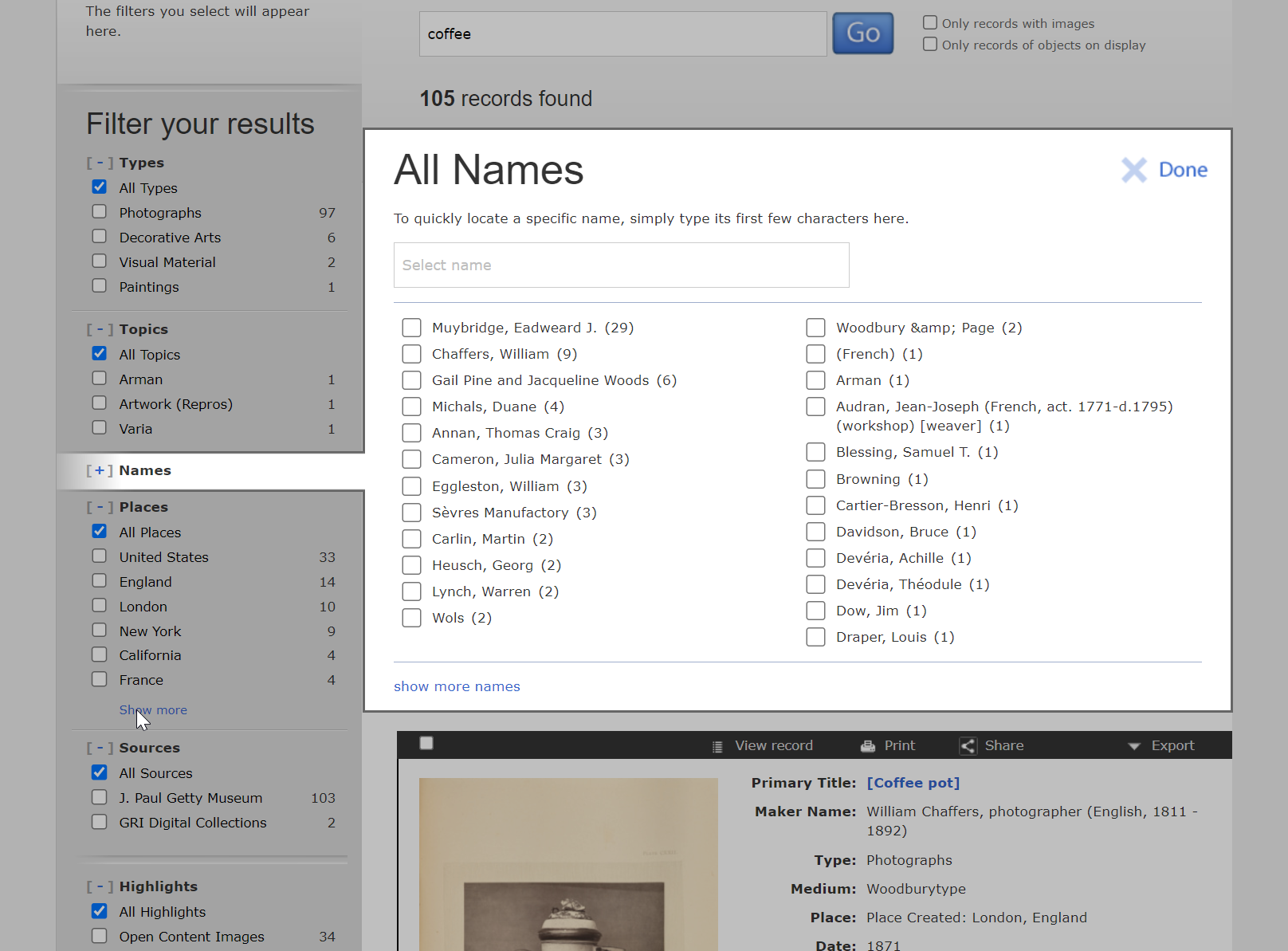
Facets are unique shared properties along a specific dimension, and when implementing them with Elasticsearch, we don't have as many options for things like multi-selection in a single facet/category, or increasing the default number of displayed results per facet, etc (at least, this is what I recall the developers explaining at one point). If we ever have the opportunity to overhaul the search along these lines, I think it'd make sense for us to gather more user testing feedback, and do some A/B testing to determine the best implementation, including whether filters should display with only 1 result.
For now, I'd be curious to hear from other users about this particular behavior. Despite the above, if there's a strong consensus among users that displaying facets with only 1 result is preferable, you've shown that this is not a hard change to make in AtoM and is something we could potentially return in a future release.
In the meantime, I hope you're able to update the _aggregation.php file as needed so it behaves as you expect. One of the nice things about open source code!
Regards,
he / him
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/c5e6aa61-2c00-4349-9642-f26f97870817n%40googlegroups.com.
Scott Breeden
Feb 13, 2022, 7:29:21 PM2/13/22
to AtoM Users
Dan,
I had forgotten that AtoM's "Narrow your results by" lists were limited to the top 10 (by default) matches in each category. So whenever you see a list with 10 items, you don't know how many other items would have been displayed if there were room, so the 1 vs. 0 question is irrelevant. Maybe nobody has complained recently because they're used to seeing at least 2 items anyway.
One thing that I like
about the dp.la interface is the scroll bars under Subject, Type, etc.
that activate whenever the corresponding list gets too big. Thanks for sharing that. I probably need more time to understand distinctions
like facet vs. filter, and browse vs. search, but right now I have to work on some other stuff. I should be able to get back to AtoM in another week or so.
-Scott Breeden
Reply all
Reply to author
Forward
0 new messages