Limiting volunteer users to particular archival levels
217 views
Skip to first unread message

Stuart Bligh
Mar 1, 2023, 5:19:31 AM3/1/23
to AtoM Users
Hi - is there a way of limiting the rights of a user group on ATOM to a particular archival level? For example so that anyone in that user group can only add, adjust and edit record at file and item level and not at any level above?

Dan Gillean
Mar 1, 2023, 9:09:22 AM3/1/23
to ica-ato...@googlegroups.com
Hi Stuart,
Unfortunately not at this time - mainly to ensure that the application is as flexible as possible for different archival contexts and use cases, AtoM doesn't have any internal sense of hierarchy when it comes to levels. The levels are all just flat sibling terms in a "Levels of description" taxonomy and archival descriptions can have an arbitrary / unbounded number of levels.
This means that when you're creating a record, AtoM currently has no concept of it having a level - internally, a "level" is just a foreign-key relationship to a term in a taxonomy table and not something meaningful that AtoM can enforce.
This more generalized approach allows for a couple important things, such as:
- Any level of description can be a top-level of description, allowing for the Australian Series system to work alongside the European and North-American focus on the Fonds, Record Group, or Collection as top levels; or allowing for museums and others to have Items as standalone / top-level records for objects and ephemera
- Users can add any level of description as needed or as defined by local policy or best practice without AtoM needing to understand where it belongs in a hierarchy - so you can create a Sub-subfonds term, or a Sub-sub-sub-sub-subseries, or a View (to capture one aspect of an item for example) or some other sub-item level
- In general, AtoM's approach has always been very permissive rather than prescriptive - AtoM will display warnings based on recommendations for required fields from relevant standards for example, but it will not enforce these. In fact, you can create a completely blank record in AtoM if you want! To ensure we can cover as many possible use cases as possible, any new features need to be flexible and configurable enough to work in different contexts, jurisdictions, languages, etc. As such, we would want to be careful about how we implemented such functionality, were it ever to be added.
Additionally, AtoM has some known issues in its permissions module that would likely need to be addressed before you could add a significant amount more complexity to it, to be able to support this particular feature request. I've described some of these known issues in previous threads - if you're curious, see for example:
I suspect that attempting to change this and allow an administrator to limit description group permissions by level of description would be a complex and expensive project, and may require us to first resolve the issues described above.
Regards,
he / him
On Wed, Mar 1, 2023 at 5:19 AM 'Stuart Bligh' via AtoM Users <ica-ato...@googlegroups.com> wrote:
Hi - is there a way of limiting the rights of a user group on ATOM to a particular archival level? For example so that anyone in that user group can only add, adjust and edit record at file and item level and not at any level above?
--
You received this message because you are subscribed to the Google Groups "AtoM Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/a01429a2-6e76-4d92-addf-e9bfdbaa9893n%40googlegroups.com.
Stuart Bligh
Mar 1, 2023, 9:37:12 AM3/1/23
to ica-ato...@googlegroups.com
That's really useful thanks Dan ... and thanks too for the quick response
Best wishes
Stuart
Stuart Bligh
Archive Advisor
Mob: 07949377526
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
You received this message because you are subscribed to a topic in the Google Groups "AtoM Users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/ica-atom-users/Xfuqngd679E/unsubscribe.
To unsubscribe from this group and all its topics, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZ%2Bz60AxBo9vhn8wqWu9RApzj_ZA12nSPT169MpvU%3Dm19w%40mail.gmail.com.
Stuart Bligh
May 26, 2023, 9:33:05 AM5/26/23
to ica-ato...@googlegroups.com
Hi Dan
I've been trying to create a location hierarchy in ATOM but am confused by the range of terms relating to the location of an archive item within a storage area ie physical object type, physical storage and location .... and also how these various descriptors of an item's location link to each other.
Ideally for an archival institution I want to create a hierarchy which looks something like ...
storage block 1 - Level 1 - Rack 1 - shelf 1 then storage block 2 Level 1 Rack 1- shelf 1 etc etc
but there doesn't seem to be anywhere to create a location hierarchy like this? Or should it build from the container type? That is box 1 - shelf 1 - rack 1 - level 1 - storage block 1? If that's the case it presumably means that each box needs a unique reference number as well as each archival item having a unique reference number? That may be an issue as in most cases the archive ref is the box ref ... although I suppose I can just use the same reference number.
Would be grateful for your thoughts ...
Thanks
Stuart
Archive Advisor
Mob: 07949377526
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
On Wed, 1 Mar 2023 at 14:09, Dan Gillean <d...@artefactual.com> wrote:
You received this message because you are subscribed to a topic in the Google Groups "AtoM Users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/ica-atom-users/Xfuqngd679E/unsubscribe.
To unsubscribe from this group and all its topics, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZ%2Bz60AxBo9vhn8wqWu9RApzj_ZA12nSPT169MpvU%3Dm19w%40mail.gmail.com.
Dan Gillean
May 26, 2023, 10:02:46 AM5/26/23
to ica-ato...@googlegroups.com
Hi Stuart,
Unfortunately, AtoM's physical storage module is very basic at the moment - it was added early in ICA-AtoM development and has not seen significant sponsorship for a redesign or new features since. Consequently, the module currently is much more like a key/value pair - it does not have the ability to organize containers and locations hierarchically (for example, to nest a folder in a box, on a shelf, in a range, in a specific building, etc.).
Because of this, we generally recommend that you use unique names for storage containers - perhaps even incorporating your description reference code(s) into the container, to make it easier to find the correct container in the future when using drop-downs and autocomplete fields.
This thread, for example, discusses this somewhat, as well as some alternatives that others are using:
This thread, for example, discusses this somewhat, as well as some alternatives that others are using:
You can also search for other threads in the forum that have covered this - for example, here is a search result page of all threads that have the label "physical-storage" and the word "hierarchical" in them:
You can learn more about how we use labels to make searching the forum by topic easier here:
he / him
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAN4d2CeWbf1mMRmxHaNqHn3Pu%2Btfsd9OnQSwNwOGeZPRQPoWaA%40mail.gmail.com.
Stuart Bligh
May 26, 2023, 10:11:39 AM5/26/23
to ica-ato...@googlegroups.com
Thanks Dan - that is really helpful ....
Stuart
Stuart Bligh
Archive Advisor
Mob: 07949377526
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZ%2BqmRCFxeRnxy6v%2BXcgUqho27bgT_GeYagRNSSJzvMHZw%40mail.gmail.com.
Stuart Bligh
Jun 1, 2023, 3:18:33 PM6/1/23
to ica-ato...@googlegroups.com
Hi Dan - apologies another quick query. I can't find anything in the online instruction manual regarding changing the location of items without having to do that for each individual item ... for instance if you're moving a whole load of boxes to a new store? In the example below (from the browse physical storage page) we'd like to switch everything located in EC to a new store AS? Any suggestions or previous threads that have covered this?
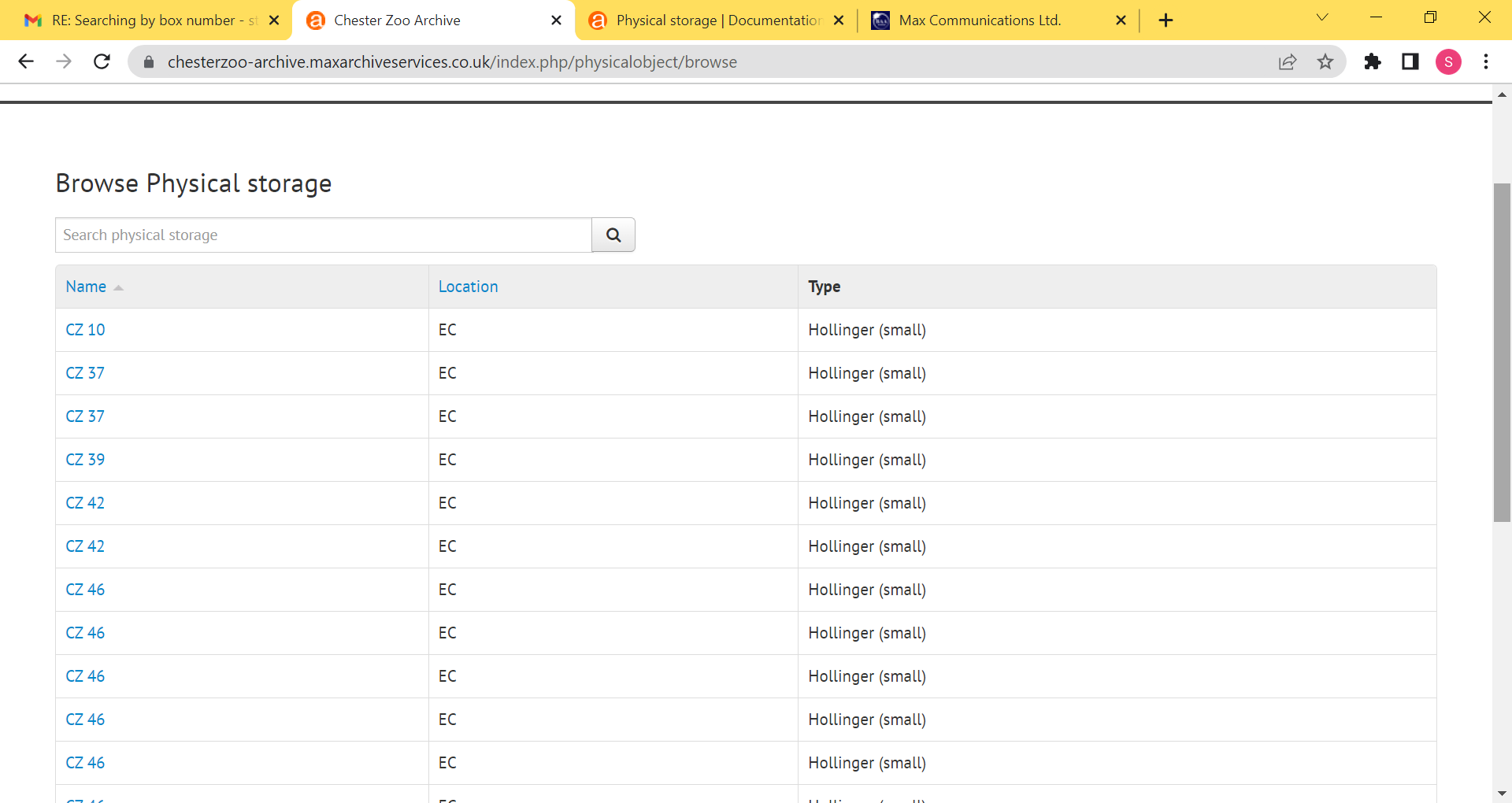
Thanks again
Stuart
Archive Advisor
Mob: 07949377526
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZ%2BqmRCFxeRnxy6v%2BXcgUqho27bgT_GeYagRNSSJzvMHZw%40mail.gmail.com.
Dan Gillean
Jun 1, 2023, 3:56:25 PM6/1/23
to ica-ato...@googlegroups.com
Hi Stuart,
Unfortunately, as previously mentioned the Storage module is very underdeveloped - at this time there are no bulk update options provided.
If you are trying to update EVERY description associated with that location, then you can simply edit the storage record itself.
If it's *most* of them, it may be quickest to do something like... 1) note which ones need to be unchanged, 2) unlink those, 3) update the current location as needed, and 4) create a new storage record for linking those unlinked descriptions.
Otherwise, if it's every storage record with EC as a location updated to AS, then there may be a way to do this via a SQL query?
- We have Entity Relationship Diagrams on the AtoM wiki here
- We have example queries in the documentation here, including how to back up your database first, and how to access the MySQL command prompt
- The two primary tables you'll probably want are physical_object and physical_object_i18n
- the location field appears to be a TEXT field on the physical_object_i18n table
I'm not a developer, but I'd suggest trying a SELECT first using LIKE criteria, to see if the count matches what you're seeing in the UI, something like (please don't laugh if this is terribly wrong!):
- SELECT * FROM physical_object_i18n WHERE location LIKE 'EC';
If the SELECT count matches what you're seeing in the UI, then you can next turn this into an UPDATE query... but I will leave constructing that to others. Just remember to back up your database before making any changes this way! And you'll want to clear the application cache, restart PHP-FPM, and re-populate the search index afterwards.
Good luck - hope this helps!
he / him
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAN4d2Ce5HqAvR%2Bku6tWCvz79aZj9Eo-_OKr2CQe24TBBqfnuLA%40mail.gmail.com.
Stuart Bligh
Jun 7, 2023, 7:25:19 AM6/7/23
to ica-ato...@googlegroups.com
Hi Dan - apologies another query. One of the institutions that we work with on ATOM is getting duplicate entries for specific boxes (see below as an example for box CZ 46) when they create a physical storage report and each of these has a single archival description record attached. We were expecting that there would be one entry for a particular box and when we click on that we would get all the contents of the box displayed ..... as outlined in the user manual. Have they been linking the physical storage wrongly?
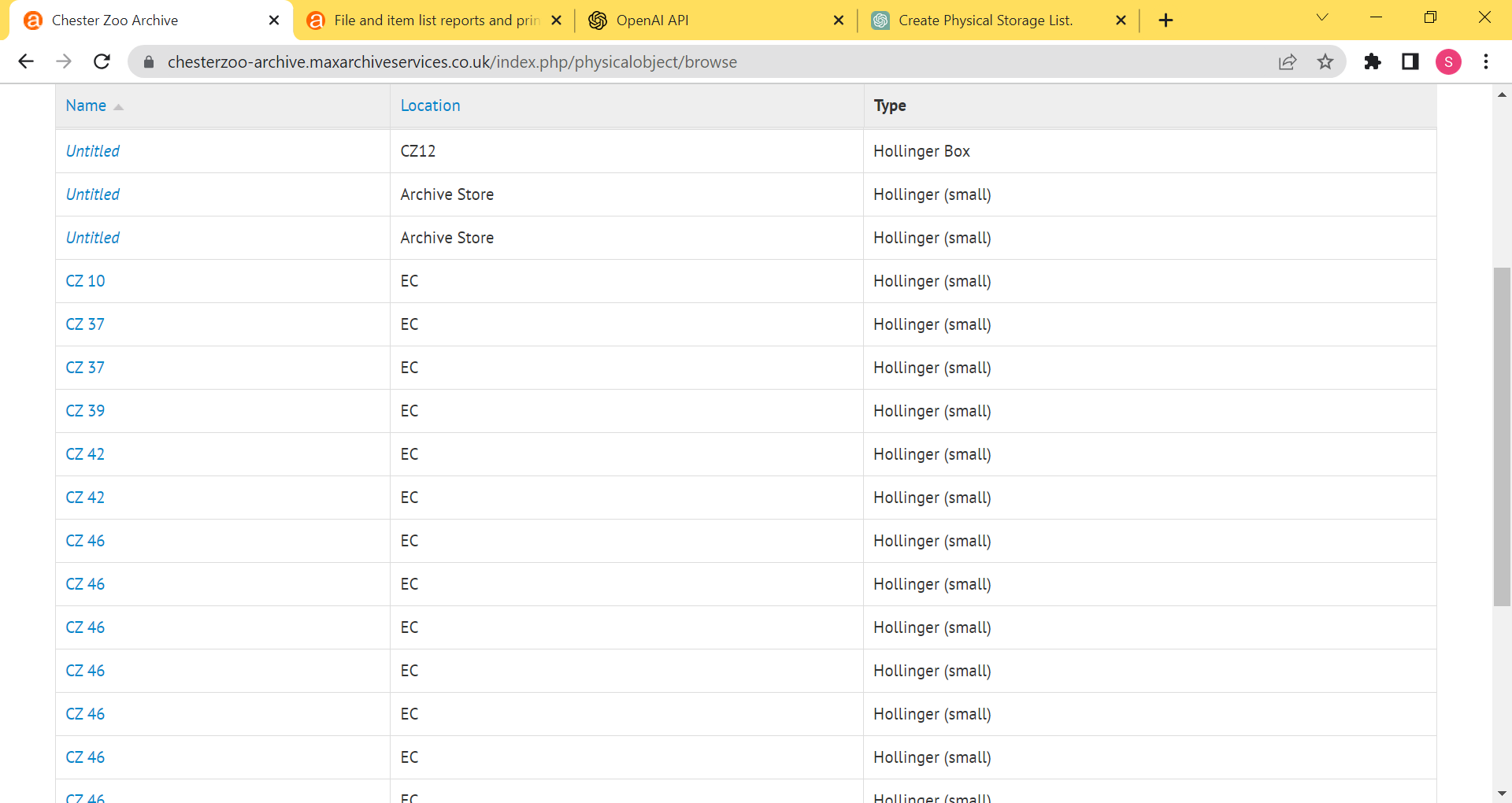
Thanks
Stuart
Stuart Bligh
Archive Advisor
Mob: 07949377526
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZKbjh%3D2XxZfF5i%3Dhe_xBLQOrJvAt25oOOPy5xn%2BB9Ep%2Bg%40mail.gmail.com.
Dan Gillean
Jun 7, 2023, 8:28:46 AM6/7/23
to ica-ato...@googlegroups.com
Hi Stuart,
Interesting. Unfortunately, it's really hard to tell whether this is a user error or something else with just this information. A couple salient points:
First, all autocomplete fields in AtoM have a known issue, where if you type too fast and don't actually select from the autocomplete result that shows up in the drop-down (and instead just tab out or hit enter, etc) then you can end up creating duplicate records. It's possible this is what's happening here.
As a second minor point of information - even though I don't think this is what's happening in this particular case - it's worth noting the way that the new global physical storage report works. From the TIP admonition at the very end of this section of the docs:
Remember, the resulting report is focused on container relations, and not just on the containers themselves. Because of this, the same physical storage container might be described in multiple rows of your export. Each row in the CSV report represents a relation (or for unlinked containers, a lack of one), so if a single storage container is linked to 5 archival description records and 5 accession records, that storage container would appear in 10 rows in the exported report.
However, since your screenshot is showing the user interface and not a report page, this is more of an FYI than a theory as to the cause.
Given the above however, if you are saying that these duplicates are appearing AFTER running a report, then it is possible there's a new application bug at play. Do any of the common maintenance tasks (rebuild nested set, clear cache, restart php-fpm, rebuild search index) resolve this?
Causes aside, there's some good news at least: we have a command-line task that will hopefully help you resolve this issue if in fact these are all accidental exact duplicate locations.
If the name, location, AND container type are identical, then when the following task is run, the oldest of the duplicate locations is preserved, and all accession and description relations are moved to that record before any remaining duplicates are deleted:
- php symfony physicalobject:normalize
- See: https://www.accesstomemory.org/docs/latest/admin-manual/maintenance/cli-tools/#normalize-physical-object-data
Be sure to review the CLI options - for example, there is a --dry-run option so you can see how many containers will be affected before actually running the task, and a --verbose option that will output more of the process in the CLI as the task progresses.
As always, I strongly encourage you to make a database backup first, just in case the outcome is not what you expect!
If that DOES succeed in clearing things up, I would be very curious to hear if you can produce new duplicates by running a storage report (rather than creating/linking new storage locations, which might have been a user error). Let us know how everything goes!
Cheers,
he / him
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAN4d2CekO1iCcOG5YS4t2KBXanO_PV2qAZ5vN8PKkkL4XoD8qw%40mail.gmail.com.
Stuart Bligh
Jun 7, 2023, 8:44:35 AM6/7/23
to ica-ato...@googlegroups.com
Thanks Dan - the duplicates are appearing in the report as well (see attached for info) and I've also noticed that there are some of the references that have been entered with a space between the alpha and numeric elements (so CZ 46 and CZ46) which is another issue!
The name (box ref), location, and container type are all identical so I'll ask someone more technical to run the command line task - all the institution really wants is to be able to click on a box ref and get a list of all the contents of the box ... and be able to print that off or download it. Reading the user manual that seems simple enough so I hope once we've done the command line task it will be straightforward ...
Thanks again
Stuart
Archive Advisor
Mob: 07949377526
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZK2RV-EitH%3DnxaqemxvXdZik6QEwu_2E_0fA7%2Bb%3DwLF5w%40mail.gmail.com.
Dan Gillean
Jun 7, 2023, 9:00:29 AM6/7/23
to ica-ato...@googlegroups.com
Hi Stuart,
Okay, let me know how things are looking after you make a backup and run the storage normalization task.
I've also noticed that there are some of the references that have been entered with a space between the alpha and numeric elements (so CZ 46 and CZ46) which is another issue!
Cases like this sound like a data entry issue from a user - entering *nearly* the same data, but not exactly, so a near-duplicate is made. Unfortunately the task won't clean up such instances, but hopefully these are the minority. Let's hope the task can resolve most of this!
Cheers,
he / him
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAN4d2Cf7O%2Bs6DHZmoMRi6zGFPxa53K-q1xHsfKCk4CXa599uGQ%40mail.gmail.com.
Stuart Bligh
Jun 8, 2023, 3:42:20 AM6/8/23
to ica-ato...@googlegroups.com
Thanks again Dan - yes I think they're going to manually correct the issue re the space between the alpha and numeric elements. Will let you know how we get on with the command line task ...
Stuart
Stuart Bligh
Archive Advisor
Mob: 07949377526
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
2-3, Gunnery Terrace
Cornwallis Road
London SE18 6SW
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZK6_CAsXugqNtY7v2BwnuNHVAugnnpMX1R9E-rDgxK7%3Dg%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages