Skip to first unread message

Chris Mills
May 22, 2020, 2:11:57 PM5/22/20
to AtoM Users
Apologies for a possibly incendiary title. I am taking my first steps into building an Access to Memory workflow for a small arts residency organization in south Texas. Up until recently I worked as an AV Technician in the Artefactual homeland of Vancouver and found myself in an unofficial (see "uneducated" and "unfunded") preservation specialist role. Now this is formalized and I've tasked myself with creating a database for a semi-organized filesystem of images and video captured over 25 years of institutional history. Been watching all the videos I can, hoping to brush up as fast as possible.
- If you were starting with AtoM from scratch, would you use it as an image lookup and viewing database alone? Is it the best tool for such a thing?
- I would like this to be used by people who are not educated in archival terms, is AtoM well-suited for this?
- Where would I get started in converting a directory tree of labeled directories into an ingestion process for AtoM? I would like to batch process as much as possible then possibly go back and add Authority Records pointing to people in each photo.
- What Archival Description relationship structure would gather individual images under the common parent of (i.e) a specific event?
If this goes swimmingly (even just images is long-term), I would like to move forward with video and then our binders of physical records.
I really appreciate any help on getting my foot in the door, as both AtoM and Archivematica seem like very exciting projects I would like to contribute to someday.

Dan Gillean
May 22, 2020, 6:06:31 PM5/22/20
to ICA-AtoM Users
Hi Chris,
Welcome to the AtoM community! I'm hoping that some of our community members will chime in, as a lot of your questions depend on preferred workflows, intent, etc. However, I can start by trying to offer some general responses.
First, if you're looking to learn more about AtoM in general, I've recently shared a lot of resource links in this thread that you might find helpful:
To respond to your questions:
If you were starting with AtoM from scratch, would you use it as an image lookup and viewing database alone? Is it the best tool for such a thing?
I would like this to be used by people who are not educated in archival terms, is AtoM well-suited for this?
I'm going to tackle these two together.
AtoM was originally built with support from the International Council on Archives, and its data model was structured around the ICA standards. As such, it definitely has a strong focus on archives. That said, even in the early days we tried to make the system flexible, and many of AtoM's labels, menus, and other elements are customizable directly via the user interface. I've recently shared some tips on how to customize menu labels and other user interface labels for the main entities here:
A custom theme plugin, if developed, can also further alter AtoM's look and feel without having to alter the underlying code. This thread has a lot of further information and links on developing a custom theme plugin:
While AtoM does have some Content Management System (CMS) or Digital Asset Management System (DAMS) functionality, it is still at its heart more specifically focused on archives than those types of systems. However, many archives do have collections that are purely image based. Here's one example in our demo data:
I would suggest exploring the demo site, and possibly installing the AtoM Vagrant box to have a local test instance, and then playing around to see if you think AtoM can meet your needs. Information on both of these can be found in the two forum thread links above. If you do set up a local test instance, check out the attachment in the first thread I posted (with the general links) - it's a worksheet that will walk you through some of AtoM's main functionality step by step, which can be useful for understanding how the application works.
Where would I get started in converting a directory tree of labeled directories into an ingestion process for AtoM? I would like to batch process as much as possible then possibly go back and add Authority Records pointing to people in each photo.
Probably the easiest way to bulk add metadata and digital objects to AtoM is via CSV import. We include CSV templates on our wiki, here:
We have documentation on working with CSV imports here:
And these slides will walk you through all the major columns found in the descriptions CSV import template:
A metadata CSV import can include a path to an associated digital object, which will be uploaded and attached during import. You'll need to have access to the installation server to put the directory of images (and/or other digital objects) on the server first, and then you add the path to each one to the relevant row in the CSV. See:
Alternatively, you can bulk import a directory of digital objects and attach them to existing descriptions later from the command-line, using AtoM's digitalobject:load task:
What Archival Description relationship structure would gather individual images under the common parent of (i.e) a specific event?
This is one of those questions where I say, "It Depends." I think here is where I'm especially hoping that other AtoM users might chime in with their opinions - there are a lot of ways you could potentially arrange your content.
The Example from our demo site is one method - a collection-level record, with just a bunch of item-level records beneath it. Alternatively, you could create intermediary series-level descriptions to organize your content. Here's one example:
See the "System of arrangement" note on the top-level record for more information on how this has been organized. Keep in mind that end users can also browse just the digital objects in a hierarchical collection if desired, like so.
Here's a different approach: The Beaton Institute uses a combination of AtoM static pages (to create landing pages with custom links and further information on specific types of holdings, themes, or collections) and subject access points to group together disparate content thematically that may be held in different collections. An example:
If, from this page, you click on the Sound and moving images link, then you end up on a Subject access point browse page, showing all records that have the access point of "Celtic Music - Audiovisual" added to them. This allows Beaton to link to the same content in different ways, as you can add any number of subject access points to a record.
Similarly, Dalhousie University has used place access points to integrate with a map they've embedded on their home page, allowing users entry into the holdings based on geographic region:
This photograph collection in their holdings seems reflect an arrangement that preserves the way the collection was received, and is organized by box:
Meanwhile, the Mills Archive is ... exactly what it sounds like! An archive of old mills (windmills, water mills, etc). Their content is very image-rich, and they have used AtoM in very creative ways to educate their users about archives along the way, while also providing multiple ways into the holdings - note that they've created Browse menu links that include various ways of accessing their holdings: "Images and Documents" and "Images only," and "Images by country and mill type" (where they have used place and subject access points to help curate the list on an intermediary static page):
So.... it depends! But hopefully this might give you some ideas of how others are using AtoM. You can explore more AtoM sites in production via the example links provided here:
Hope this helps!
Dan Gillean, MAS, MLIS
AtoM Program Manager
Artefactual Systems, Inc.
604-527-2056
@accesstomemoryArtefactual Systems, Inc.
604-527-2056
he / him
--
You received this message because you are subscribed to the Google Groups "AtoM Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/72fbf38d-ed0d-4e13-8404-acbacc9efe6e%40googlegroups.com.
Chris Mills
May 29, 2020, 6:46:46 PM5/29/20
to AtoM Users
Dan,
Thank you so much for this ultra-generous intro, I will say after a week straight of following every link you sent, setting up a VM instance (first with 20.04, oops), and poring through just about every setting in the UI, I think I have a better grasp. Truth is, the system is so wide open generic that it leaves a lot of infrastructure decisions to be made. An amazing double-edged sword for sure! For example, wanting to import the LoC MARC List for Geographic Areas and getting mixed up between Geographic Subsections and Places taxonomies. Many pitfalls, but trying to do it right the first time... or making a million backups!
I did a peek into CMS/DAM options and I find our historical catalogue bend does fit AtoM more closely, but I appreciate adding the distinction.
I noticed in another thread you mentioned that with the way Atom is setup, its not intended for preservation and direct file access. If I were adding Archivematica upstream in this process, does Archivematica store the files as well and log the file address in (for example) a drive share into the DIP to be shown in AtoM? I understand the normalization processes more than the intended workflow. Sidenote: I can find more resources on integrating Archivematica with other tools than with AtoM. Am I missing something?
Lastly, cant find this in the group: is there a symfony script to internalize all external URLs? Perhaps even after they are imported as external. In the CSV Import I would like to list a URL and then upon import have AtoM pull that in permanently, Master and Derivatives.
Thanks loads,
Chris
To unsubscribe from this group and stop receiving emails from it, send an email to ica-ato...@googlegroups.com.
Dan Gillean
Jun 1, 2020, 11:29:00 AM6/1/20
to ICA-AtoM Users
Hi Chris,
Some in-line responses below :)
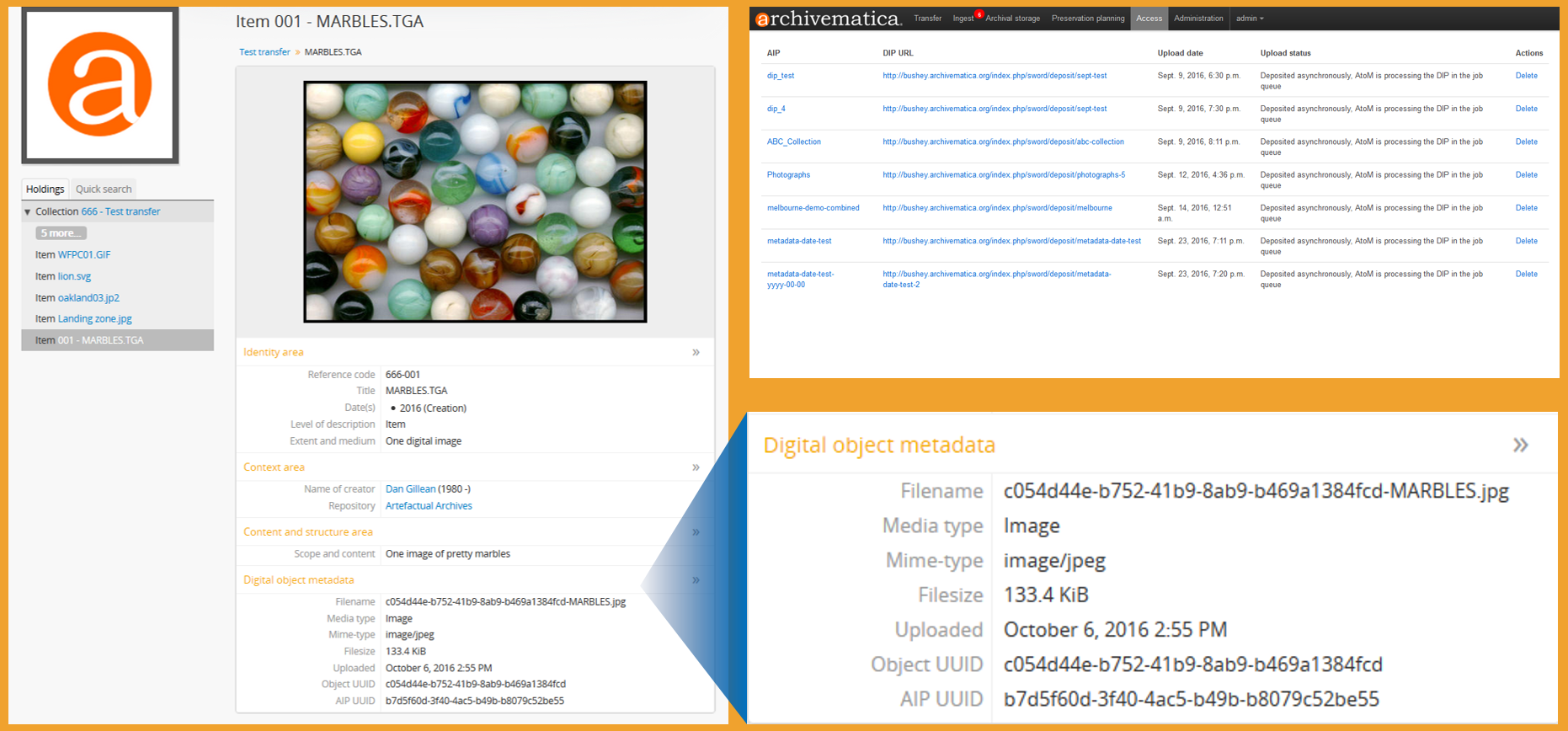
I noticed in another thread you mentioned that with the way Atom is setup, it's not intended for preservation and direct file access. If I were adding Archivematica upstream in this process, does Archivematica store the files as well and log the file address in (for example) a drive share into the DIP to be shown in AtoM? I understand the normalization processes more than the intended workflow.
AtoM won't display a file path to where the preserved AIP (including the original master, and a normalized preservation copy) is stored. It will however display a unique universal identifier (UUID - essentially a hash) for the related file, and the related AIP, that will allow you to find the file's location in Archivematica's Storage Service. Here's an example from a slide deck:
This maintains the chain of custody so there is a way to link the access copies in AtoM back to the preservation versions managed by Archivematica, but avoids the need to update AtoM if the location of your AIP moves in the future. Many archivists also wouldn't want the location of their preserved master shared publicly, so it also adds some security separation.
Sidenote: I can find more resources on integrating Archivematica with other tools than with AtoM. Am I missing something?
This is primarily one of the strange side effects of our business model up until now. Essentially, we give away all our projects and their related resources under open licenses. As a company, we stay afloat and garner the resources necessary to maintain our projects by offering paid additional services (hosting, training, remote tecnical support, consultation, theming, and of course custom development). While we reserve time to add bug fixes, security patches, and minor enhancements to each release, we rely on community support for feature development - either in the form of code contributions, or through paid development contracts. We work with sponsoring institutions to find a way to implement their development requests in a way that will meet their needs, but also be useful to the broader community and follow relevant standards where applicable, and then we bundle all that development into the next public release, so that the entire community benefits from any contribution. You can find more on this, and the history of the AtoM project, on our wiki here:
One of the side effects of this is that it's been difficult to make long-term roadmaps to support the enhancements and integrations we'd really like to see - even between the projects we maintain. For a long time, AtoM's highest user base was in Canada, where uptake of production-level digital preservation was low. Meanwhile, most of our Archivematica users for a long time were based in the US - where AtoM did not have a lot of uptake. Consequently, integrations in Archivematica, sponsored primarily by US institutions, did not focus on enhancing the AtoM integration as often.
This dynamic is now changing in several ways. First of all, we've seen a significant increase in AtoM adoption in the US in the last couple of years; meanwhile, more and more Canadian institutions are reaching the point where they are implementing digital preservation into their production workflows. AtoM and Archivematica both also have increasing international adoption, and more companies are beginning to offer services related to the projects. We hope this might lead to increased AtoM-Archivematica integration sponsorship in the future. Already, I know of at least one project scheduled that will improve the amount of technical information displayed in AtoM when Archivematica DIPs are uploaded, that will be included in a future AtoM release (likely 2.7 at this point, since we are now aiming for a 2.6 release in early July).
Additionally, project governance and community collaboration is shifting, which will hopefully allow for more long-term roadmapping. The Archivematica project recently announced the formation of the Product Support Program, while the AtoM Foundation has been created to help prepare for and govern AtoM3. Each of these initiatives hopes to provide members with a more holistic view of the long-term development priorities for their respective projects. While this doesn't necessarily guarantee increased integration, it does allow for more long-range thinking and planning.
Finally, Artefactual itself has been undergoing an internal reorganization, part of which includes the creation of a dedicated team focused exclusively on the health and maintenance of our open source projects, completely separate from Artefactual as a business. We're dedicating time to trying to solve long-term technical debt issues in each project that have previously been difficult to work on due to our business model - people tend to want to fund new features, while getting development support for upgrading libraries and tools is much more difficult. This is a cross-project team that hopes to start roadmapping across both projects - so while our focus for now is on maintenance and project health, our hope long-term is to be able to start dedicating internal time to integration development in the future that will benefit both projects.
All this to say: you're not mistaken. However, we hope in the future to see better integration between Archivematica and AtoM. We (and our community) have a lot of great ideas for this, all of which haven't previously happened only due to available resources. Hopefully that might change in the future!
Lastly, cant find this in the group: is there a symfony script to internalize all external URLs? Perhaps even after they are imported as external. In the CSV Import I would like to list a URL and then upon import have AtoM pull that in permanently, Master and Derivatives.
Unfortunately, this doesn't exist - though ironically, the reverse does.
When digital objects are uploaded to AtoM via URL, AtoM doesn't keep a copy of the original master locally. Instead, it pulls in a temporary copy of the master, generates the derivatives, and then discards the temp, storing the URL path to the source instead of a local version. It would likely be possible to create a script that will re-fetch the master from the URL, delete the current objects, and then attach a new version as a local upload, but this will take some analysis and development to implement. See my notes above on our business model - if such a feature is a priority for your institution and you might want to sponsor its development, feel free to contact me off-list, and we can prepare some estimates for you. If you have development skills, we also maintain some development resources on our wiki, including information on how you can contribute back to the public project.
We do have the opposite workflow supported in 2.5, however. For cases where institutions maintain their digital objects on a separate local file server but the server is not web accessible, they may not want to duplicate the masters in AtoM. We've added an option to the digitalobject:load task that, when used, will treat local file paths as if they are URLs. That is to say, when the --link-source option is used with this command-line task, the master is only used to generate the derivatives. After that, it is discarded and the source file path is saved instead (much like the URL being saved with external linked objects).
So, sorry, AtoM can't currently do what you're asking, and adding support will require development.
Cheers,
he / him
To unsubscribe from this group and stop receiving emails from it, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/0d73d8b4-ae2e-4e0c-96a4-a5e079699917%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages