Re: MT post-editing vs. human post-editing

Herman
> On Sun, Dec 6, 2020 at 5:46 PM <cpta...@ozemail.com.au
> <mailto:cpta...@ozemail.com.au>> wrote:
>
> Until they endow AI with a sex drive and knowledge of its own
> mortality, you aren’t going to get anything resembling human
> intelligence.____
>
> Chris
>
>
> Err.... how is a sex drive a prerequisite for intelligence? And
> knowledge of mortality would be function of intelligence, not a
> condition. Also, why is "human intelligence" the only kind of intelligence?
> Questions, questions...
>
The point isn't that human intelligence is the only kind of
intelligence, but that in order to model the operation of human
intelligence, as manifested for instance in the human use of language,
including its use in the context of translation in particular, it is
necessary to model human intelligence as a whole (including, e.g. sex
drive and knowledge of mortality).
Herman Kahn

cpta...@ozemail.com.au
Many people plough into discussions about intelligence without defining it (also most other conversations) but if you take human intelligence to be problem-solving ability, well, you will need to consider what motivates people to solve problems. Until then you are just building faster and faster calculators.
And this is relevant to translation. Human translators are motivated by getting paid (so they can win a mate and pack plenty in before they die etc) and AI will never need to please another, irrational human in order to achieve its goals.
Just remember, kids throw rocks at driverless cars, for no reasons other than that they can.
Chris
You received this message because you are subscribed to the Google Groups "Honyaku E<>J translation list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to honyaku+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/honyaku/fa0daa12-4117-edd3-3e15-027943223999%40lmi.net.

Warren Smith
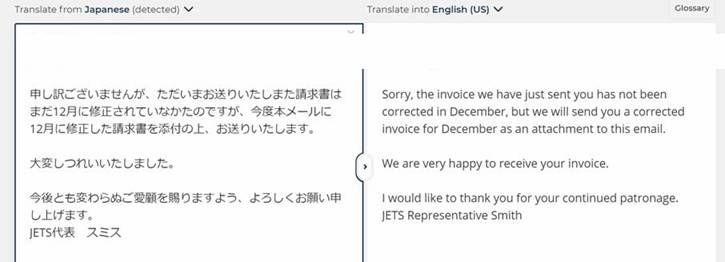
I recently used MT to back-translate a business email I wrote in Japanese. Yes -- it was a silly idea to attempt such a thing. You see, new AI-driven MT is a like a poorly-trained, semi-skilled translator who doesn't know the rules, guessing at what is meant. An MT back-translation will not identify most errors in a text, but will rather gloss over them and try to infer what I was trying to say, rather than what I actually wrote. (This is perhaps good practice for an interpreter on a street, but a huge violation of protocol for a legal translator, and makes MT useless as a tool for a back-translation validation.)
The note I wrote in Japanese talked about some issues I had had in invoicing a client (where I had had an incorrect invoicing date), and informed the client that I was sending an updated invoice. This was followed by an apology: 大変失礼いたしました。Unfortunately, in my draft, I had not yet performed the henkan for "shitsurei," so it appeared as "大変しつれいいたしました"
Any guesses as to how the MT rendered this sentence? It was actually pretty amazing at how it tried to correct the error while looking at the context of the letter: "We are very happy to receive your invoice."
Perhaps the AI keyed off of the "いたしました" and "thought" that I had meant "いただきました" and then from context assumed an invoice must have been received, meaning I must be thanking them. I suppose that "しつれい" and "うれしい" have most kana in common, so perhaps that's where "happy" came from.... But there is a huge difference between what I wrote ("I screwed up") and what appeared in the translation ("We are very happy to receive your invoice"), something that never would have occurred with a human translator.
The point is that AI can make some pretty wild flights of fancy when trying to take context into account.
What is pernicious about this is that when a human is performing post-editing of an AIMT output, there is no way that the human is not going to be influenced by the AI, to exercise unadulterated human judgment. Once human cognition has been influenced -- even by something the human knows to be bogus! -- there is no way to eliminate the influence. This inability to exclude bogus influences in human cognition was demonstrated famously by Amos Tversky and Daniel Kahneman (who went on to win the Nobel Prize) in their research on the "Anchoring Effect." (Look it up -- it is pretty interesting how susceptible human cognition is to influence.)
While my primary concern is still that post-editing of AIMT is more time-consuming for the skilled translator that straight translation would be, I am also concerned that post-editing of AIMT will actually LOWER the quality of the translation, by injecting incorrect "assumptions" about the meaning of the text. This is especially problematic when the use of AIMT enables unskilled translators to work at a viable production pace (enabling unskilled translators -- who would have been screened out by the lack of ability to earn a living wage -- entry into the industry). This can flood the market with bad translations -- especially given the "bottom feeders" out there who will shrug and accept an AI output as long as it sounds OK (without exercising the care and diligence required to verify that the translation actually correctly reflects the meaning of the source text).
Because the end client often cannot tell the quality of the translation (at least not at first), this adversely affects the ability of the skilled translator to make a living. If feedback loops and market forces then kick in, it leads to a race to the bottom. Skilled translators will leave those language service providers who are attempting to implement AIMT, leaving only the lower-level translators (for whom the AI is a blessing!). The language service provider gets some short-term benefits from reduced costs, but eventually declining quality will catch up with it (that is, the market will figure out that the translations by that firm are not serviceable)... and the language service provider will lose market share. Amen to that service provider.
Unfortunately, it is hard for a language service provider to buck this technological trend, because resisting deployment of this technology will cause pricing to be uncompetitive. The result is that the entire mega-LSP industry is rushing to jump on the death-wagon.
A quick example: one firm for which I have several million words went to a post-MT editing model in most languages. While it quickly returned to normal translation for J-E patent work (because machine translation in J-E patent work was not practical), it has lost enough market share (in all languages, I believe) that, by the aura effect, it is no longer getting enough Japanese work to keep me busy. Even though the firm managed to resist pressuring me to lower my prices, the effect of the us of MT on OTHER languages hurts me as well, and I am turning my attentions to other places.
The response to this, as professionals, may include a couple of approaches. While some of my personal approaches must be kept proprietary at this time (sorry), there is opportunity for high-end translators to reassert themselves as offering premium quality human translations, as boutique providers who are free from the quality issues found in the large LSPs. But I think that there will be a shake-out even among high-end translators. I know of one respected J-E translator, one who is truly world class, who has left the industry to be a cabinet maker instead. I view this as a tragic "brain loss" of a truly skilled senior colleague. Personally, I am floating my resume in some international business concerns, thinking that it might be time to dust off my doctorate in technology strategy and my mostly-forgotten engineering skills and hop industries.
Warren
Herman
> The note I wrote in Japanese talked about some issues I had had in
> invoicing a client (where I had had an incorrect invoicing date), and
> informed the client that I was sending an updated invoice. This was
> followed by an apology: 大変失礼いたしました。Unfortunately, in my
> draft, I had not yet performed the henkan for "shitsurei," so it
> appeared as "大変しつれいいたしました"
>
> Any guesses as to how the MT rendered this sentence? It was actually
> pretty amazing at how it tried to correct the error while looking at the
> context of the letter: "We are very happy to receive your invoice."
>
> Perhaps the AI keyed off of the "いたしました" and "thought" that I had
> meant "いただきました" and then from context assumed an invoice must
> have been received, meaning I must be thanking them. I suppose that "し
> つれい" and "うれしい" have most kana in common, so perhaps that's where
> "happy" came from.... But there is a huge difference between what I
> wrote ("I screwed up") and what appeared in the translation ("We are
> very happy to receive your invoice"), something that never would have
> occurred with a human translator.
For 大変しつれいいたしました, Deepl offers the translations:
Very persistent
I am very happy with you
It's very much appreciated
It's a great pleasure
Google presents the options "I was very tired" and "Did you mean:
大変失礼いたしました"
Bing offers "I'm very 100" and "Did you mean: 大変失礼いたしました?"
Prompt suggests "I left very much".
Deepl:
請求書を送くらせていただきます。
大変いたしました。
I will be happy to send you an invoice.
Thank you very much.
請求書を送くらせていただきます。
大変しつれいいたしました。
I will be happy to send you an invoice.
Thank you very much for your patience.
Now changing just the last line:
大変しついれいたしました。
大変じゃまいたしました。
大変じゃがいたしました。
These it keeps as "Thank you very much for your patience."
大変じゃがいもいたしました。
Here it switches to "You have been very well catered for."
大変じゃがいもからいたしました。
Here it goes to "I am very pleased to send you an invoice."
大変じゃがいももいたしました。
Here it first offers "Thank you for the great work you have done." but
then switches to "I have made a great deal of potatoes."
大変にくじゃがいたしました。
Here it goes back to "Sorry for the inconvenience."
I believe the logic of your "happy to receive your invoice" for
しつれいいたしました is the same as that of "pleased to send you an invoice"
for じゃがいもからいたしました in my examples, and is perhaps similar to a situation
where a human interpreter could not make out the entirety of what
somebody said but is compelled by the situation to render some sort of
interpretation anyhow, and so blurts out something which meets the
criteria that it sort of makes sense in this context and comes to mind
quickly (esp. the latter).
Herman Kahn
Warren Smith
I think you are right, Herman, about "blurting out the answer" with incomplete information. When I was interpreting for televised press conferences (many years ago at the Olympics in LA, when I was very green), I erred on the side of saying something quick that sounded good, even at the expense of accuracy.
In rough interpretation that might be OK, but in translation (and legal interpretation) such an approach is a real problem.
In case you are interested, below is the original DeepL screen shot (slightly redacted). There are two renderings of "12月に," and neither of them were what I meant. (It should have been "to December," which the client would have understood perfectly from the broader context.) "I" vs. "We" is a problem too (the same problem that human translators would have -- one reason why I hate translating emails as exhibits for court, where "I" vs. "we" can be very significant in their implications).
But of course, the apology line was what was most striking...
Warren