MR3 has some performance issues
31 views
Skip to first unread message

Ill
Mar 5, 2023, 11:58:05 AM3/5/23
to MR3
HI.


I found that when HIVE ON MR3 is used to execute SQL with de-duplication statistics, its execution performance is always poor.
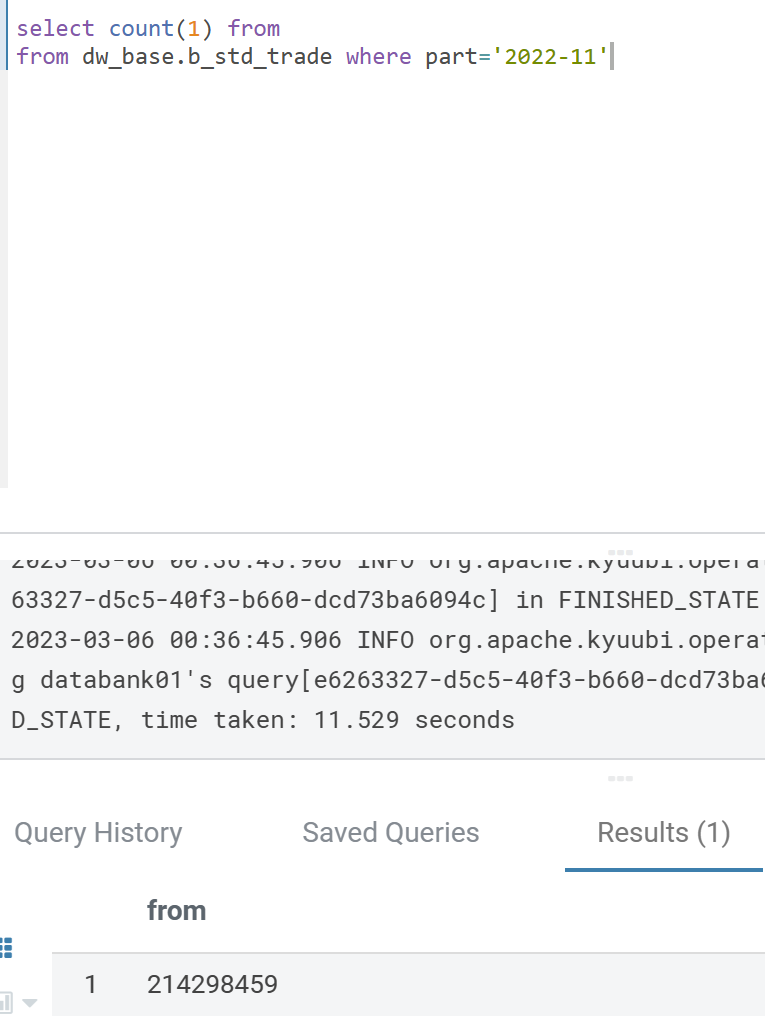
I prepared a table with 200 million data, as shown below:
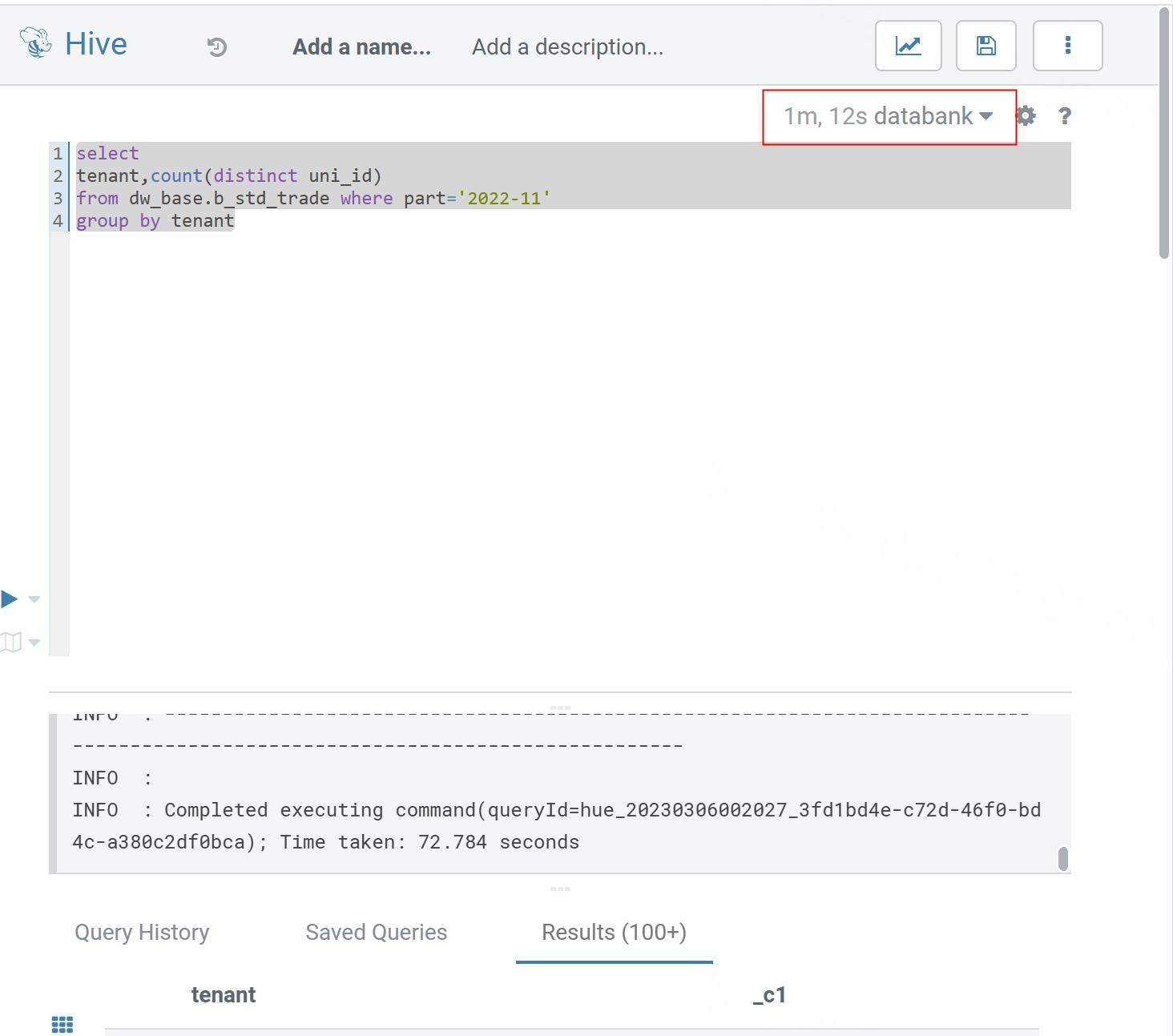
First of all, I use HIVE ON MR3 to perform a group de-replication statistics on this table. The time consumption is as follows:(ORC TABLE)
The resources used by mr3 are shown in the following figure:
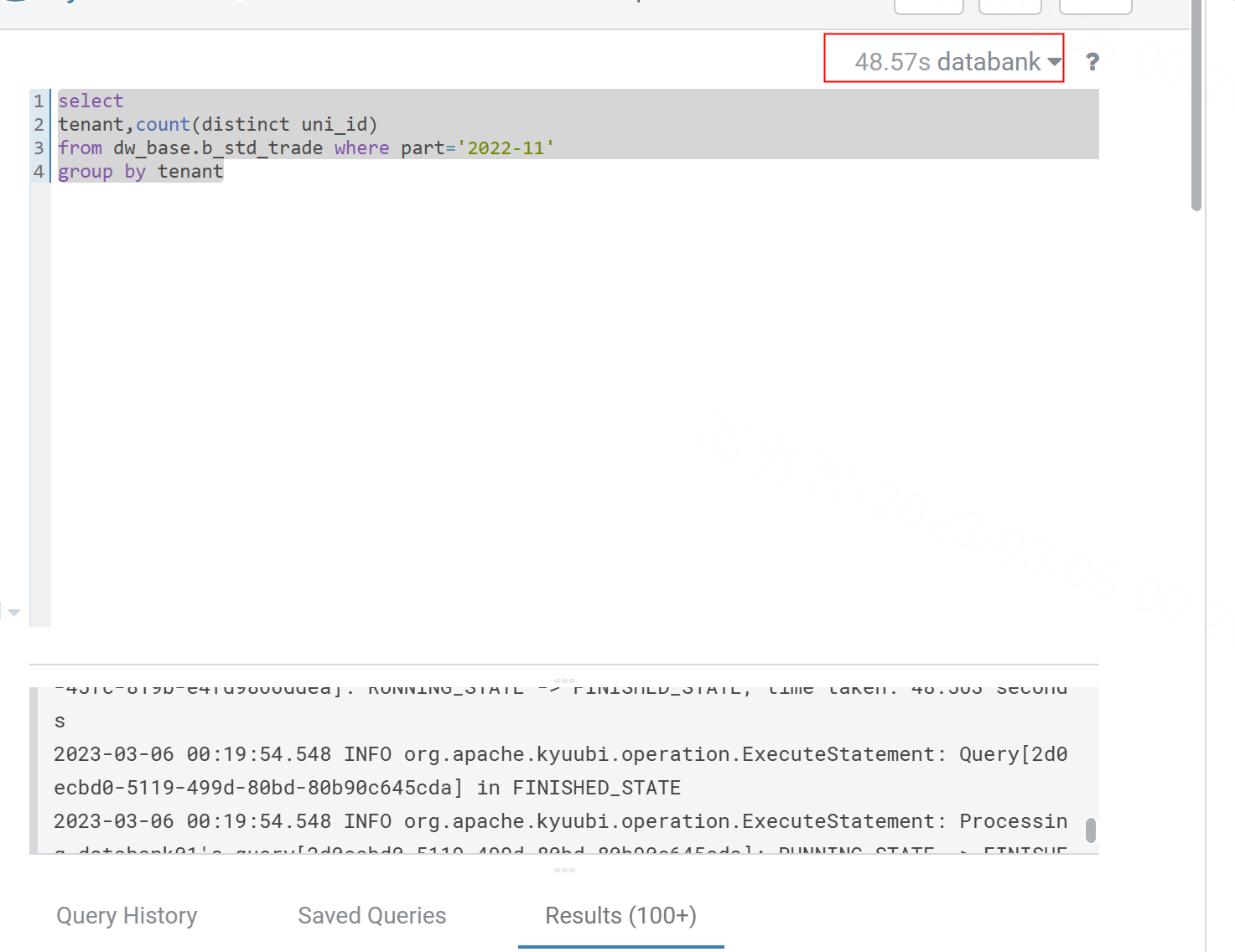
Then, I executed the same SQL using APACHE KYUUBI+SPARK3.3.2. The execution time is as follows:
The resources used by KYUUBI SPARK are shown in the following figure:
When I use Kyuubi Spark, I only use 1/10 of MR3 resources, but the execution efficiency has improved by nearly 40%.
I think there may be some problems in the process of using MR3. I need to optimize the parameters of MR3 to a certain extent. Otherwise, according to previous experience, MR3 is unlikely to be so much less efficient than SPARK.
Can you help me?

Sungwoo Park
Mar 6, 2023, 2:45:59 AM3/6/23
to MR3
Hello,
Perhaps Spark 3.3.2 is faster than Hive 3 on your query. I think this is an issue with optimizing Hive or compiling queries in Hive, not with optimizing MR3.
Could you test again Hive-MR3 using the same amount of resources as in Spark (52224MB)? By allocating the same amount of resources to both Hive-MR3 and Spark, we can better compare their performance. (40% slower with 10 times more resources does not necessarily mean that Hive-MR3 is 400% slower.)
--- Sungwoo
Reply all
Reply to author
Forward
0 new messages