hive on mr3 map task Initializing slower than apache hive
162 views
Skip to first unread message

Carol Chapman
Jan 11, 2022, 9:51:15 AM1/11/22
to MR3
I recently found that when I use hive on mr3, the DAG I submitted always takes a long time in the initialization phase.
For example:
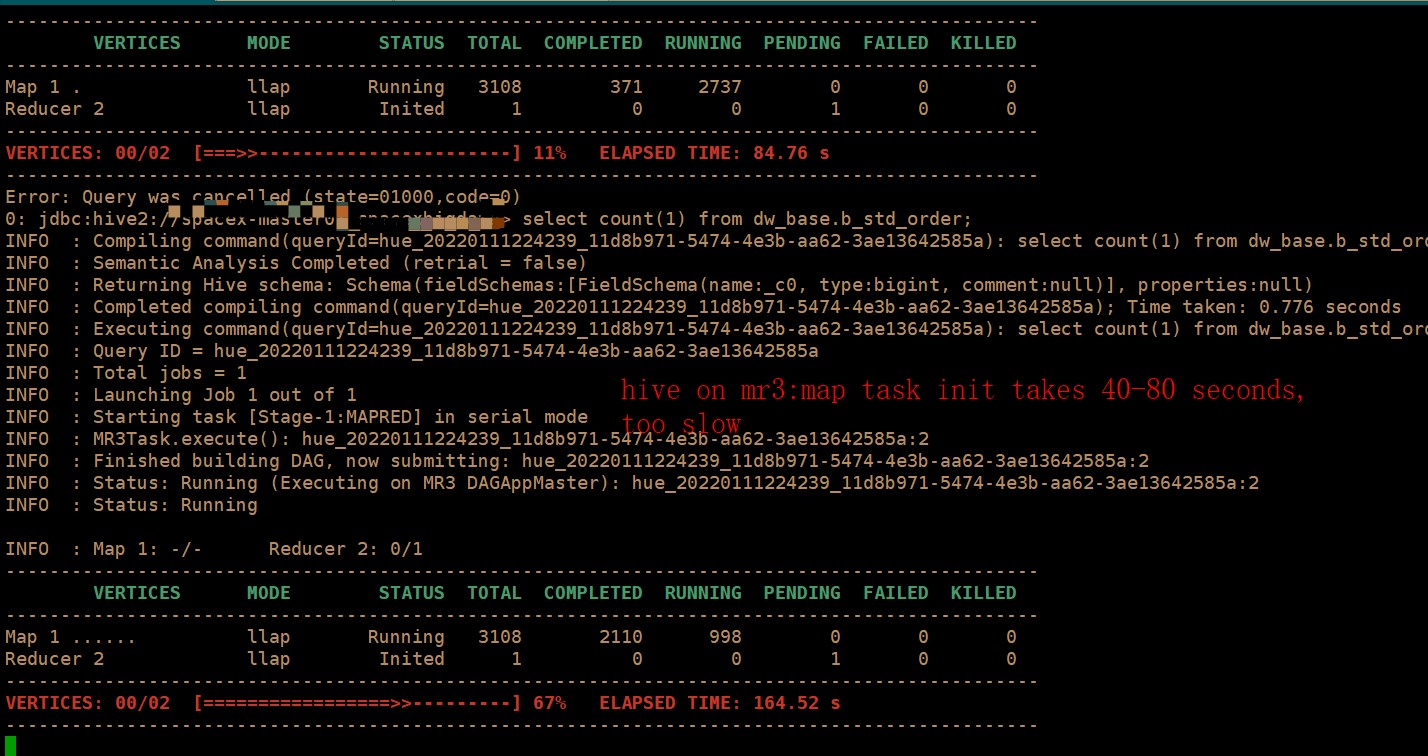
AS you can see,This task takes about 40-80 seconds to initialize map task.
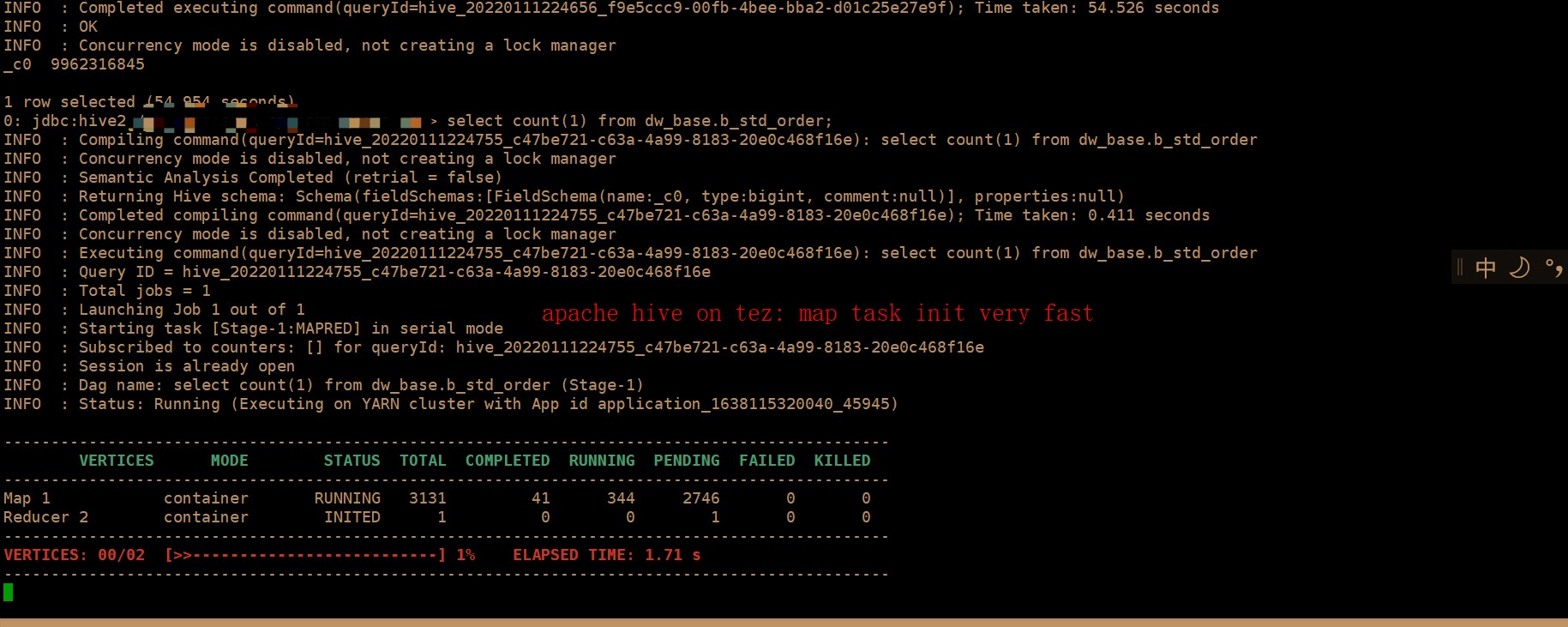
When using Apache hive to analyze data sets of the same size, the initialization of map task takes only 5-6 seconds.
ROW_NUM:9962316845
DATA_SIZE: ABOUT 9 TB
After initializing the map task, hive on mr3 is more efficient than Apache hive However, at present, we find that it often takes a long time in the initialization phase of map task, which leads to the fact that the actual execution efficiency of hive on mr3 is worse than Apache hive.
What is the reason for this phenomenon? What adjustments should I make?

Sungwoo Park
Jan 11, 2022, 11:04:49 PM1/11/22
to MR3
I suspect that different running times are caused by the difference in the configuration (those in hive-site.xml and tez-site.xml). This is because Hive-MR3 reuses the Tez runtime library for initializing Map vertexes. Can you retrieve the difference in hite-site.xml and tez-site.xml for running Hive-Tez and Hive-MR3?
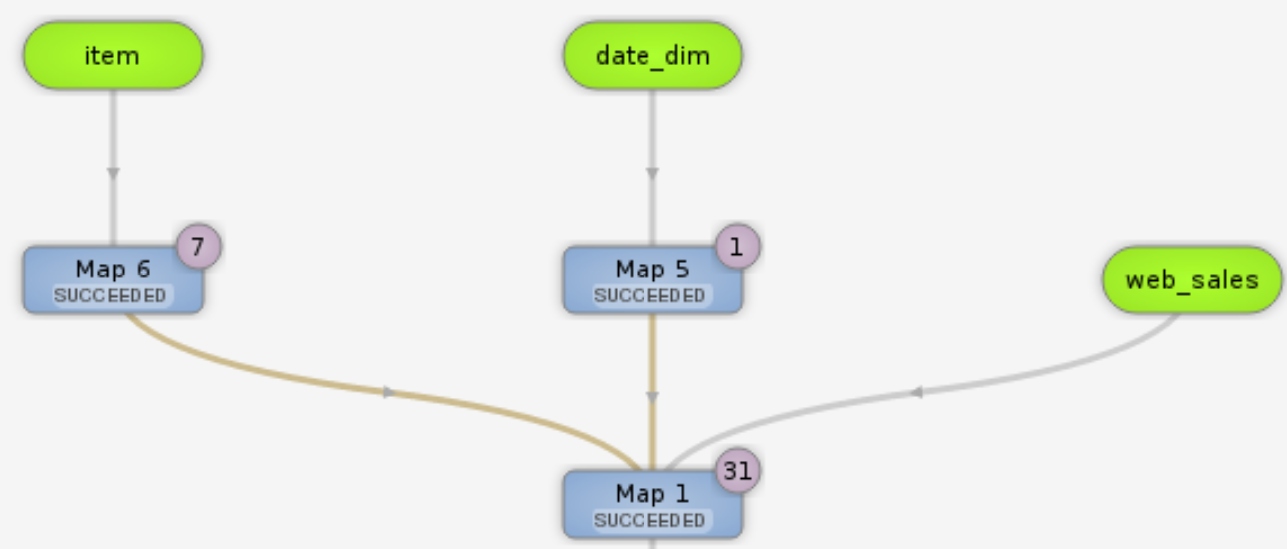
For the sample query in the screenshots ('select count(1) from table'), Hive-MR3 is working correctly when tested with TPC-DS data. For some queries, a Map vertex may stay in the state 'Initializing' for a long time because of its dependence on other Map vertexes. For example, in the following DAG, Map 1 stays in the state 'Initializing' until Map 5 is finished.
MR3 and Tez are quite different at the level of architecture, and this might also contribute to different running times. If you could share the log of MR3 DAGAppMaster when a Map vertex stays in the Initializing tate for long, we could try to analyze it.
Cheers,
--- Sungwoo
Carol Chapman
Jan 12, 2022, 2:02:54 AM1/12/22
to MR3
OK, I will prepare relevant log files and configuration file information in recent days and send them to you in the form of e-mail.We can discuss this problem together
Carol Chapman
Feb 17, 2022, 2:51:50 AM2/17/22
to MR3
I found that when there are a large number of small files in HDFS, the initialization speed of mr3 is often much slower than that of Apache hive.
I will provide relevant log and experiment record information later.
Sungwoo Park
Oct 28, 2022, 1:59:50 AM10/28/22
to MR3
I found that when there are a large number of small files in HDFS, the initialization speed of mr3 is often much slower than that of Apache hive.I will provide relevant log and experiment record information later.
Can you still reproduce this problem? I am revisiting this problem to see if there is something on the MR3 side that I don't understand.
Hive uses the configuration key hive.orc.compute.splits.num.threads to specify the number of threads for split computation. I have verified that MR3 DAGAppMaster creates multiple threads (e.g., ORC_GET_SPLITS #1) as specified by hive.orc.compute.splits.num.threads, and that split computation is distributed among these threads. In other words, MR3 DAGAppMaster (or InputInitializer in it) is running normally as intended. (In the case of Hive-on-Tez, split computation is performed in Tez DAGAppMaster.)
However, it might be that that split computation is slower than Hive-on-Tez for some reason unknown to us. Hive-MR3 reuses the code in Apache Hive for split computation, but there is a slight difference in managing threads for split computation. If you can still reproduce this problem, I wonder if you could try a small experiment.
1) hive.orc.compute.splits.num.threads is probably set to 10. Increase it to 40 in hive-site.xml.
2) Restart HiveServer2 and MR3 DAGAppMaster. This is necessary because new values for hive.orc.compute.splits.num.threads are not effective in Hive-MR3.
3) Run the same query and see if the change makes any difference, especially the duration of INITIALIZING state.
Cheers,
Sungwoo
On Wednesday, 12 January 2022 at 15:02:54 UTC+8 Carol Chapman wrote:
OK, I will prepare relevant log files and configuration file information in recent days and send them to you in the form of e-mail.We can discuss this problem together
On Wednesday, 12 January 2022 at 12:04:49 UTC+8 Sungwoo Park wrote:
I suspect that different running times are caused by the difference in the configuration (those in hive-site.xml and tez-site.xml). This is because Hive-MR3 reuses the Tez runtime library for initializing Map vertexes. Can you retrieve the difference in hite-site.xml and tez-site.xml for running Hive-Tez and Hive-MR3?For the sample query in the screenshots ('select count(1) from table'), Hive-MR3 is working correctly when tested with TPC-DS data. For some queries, a Map vertex may stay in the state 'Initializing' for a long time because of its dependence on other Map vertexes. For example, in the following DAG, Map 1 stays in the state 'Initializing' until Map 5 is finished.MR3 and Tez are quite different at the level of architecture, and this might also contribute to different running times. If you could share the log of MR3 DAGAppMaster when a Map vertex stays in the Initializing tate for long, we could try to analyze it.Cheers,--- Sungwoo
Carol Chapman
Oct 28, 2022, 9:58:39 AM10/28/22
to MR3
OK,I TRY
Carol Chapman
Oct 28, 2022, 10:12:25 AM10/28/22
to MR3
ROW_NUM:9962316845
DATA_SIZE: ABOUT 9 TB
hive.orc.compute.splits.num.threads=> 10 init_time=72S
hive.orc.compute.splits.num.threads=> 40 init_time=84S
Carol Chapman
Oct 28, 2022, 10:16:37 AM10/28/22
to MR3
hive.orc.compute.splits.num.threads=> 40 init_time=50S (
If I execute SQL repeatedly )
Sungwoo Park
Oct 28, 2022, 11:06:13 AM10/28/22
to MR3
Thank you very much for sharing the result. I see that 40 threads are created for split computation, and that InputInitializer spends 30 seconds to over 1 minute for split computation. So, let me keep investigating this issue.
Cheers,
Sungwoo
Sungwoo Park
Oct 30, 2022, 10:49:54 AM10/30/22
to MR3
For this problem, the solution is to set hive.exec.orc.split.strategy to ETL.
1. If
hive.exec.orc.split.strategy is set to BI, split computation uses a single thread, so it takes a lot of time to finish split computation if the input data is stored across thousands of files.
2. If
hive.exec.orc.split.strategy is set to ETL, split computation uses multiple threads as specified by hive.orc.compute.splits.num.threads. The default value for hive.orc.compute.splits.num.threads is 10, and I observe that increasing the value to 20 or higher reduces the time for split computation quite a bit when there are 30,000 input files.
3. If hive.exec.orc.split.strategy is set to HYBRID, split computation mixes BI and ETL. However, the percentage of ETL can be as small as 1 percent, which effectively makes hive.orc.compute.splits.num.threads irrelevant. This is the default value in Hive-MR3 configurations, and my guess is that this is the reason why your query takes a long time in the Initializing state.
So summarize, in order to reduce the time for split computation in the Initializing state, set
hive.exec.orc.split.strategy to ETL and increase the value for
hive.orc.compute.splits.num.threads as necessary. It's too bad that I assumed HYBRID would put a lot more weight on ETL than on BI :-(
I'd appreciate it if you could report new experiment results here.
Cheers,
-- Sungwoo
Sungwoo Park
Oct 30, 2022, 11:03:16 AM10/30/22
to MR3
So summarize, in order to reduce the time for split computation in the Initializing state, set hive.exec.orc.split.strategy to ETL and increase the value for hive.orc.compute.splits.num.threads as necessary. It's too bad that I assumed HYBRID would put a lot more weight on ETL than on BI :-(
As a side note, hive.exec.orc.split.strategy can be set for each individual query (e.g., inside Beeline). However, hive.orc.compute.splits.num.threads is fixed when HiveServer2 starts.
Cheers,
Sungwoo
Sungwoo Park
Oct 31, 2022, 1:59:52 AM10/31/22
to MR3
Also mapreduce.input.fileinputformat.split.maxsize affects split computation. If input files are all small, try a smaller value for mapreduce.input.fileinputformat.split.maxsize (whose default value is 256MB). Then, setting hive.exec.orc.split.strategy to HYBRID might achieve the desired behavior.
Thanks David for the tip on mapreduce.input.fileinputformat.split.maxsize.
Cheers,
--- Sungwoo
Carol Chapman
Nov 2, 2022, 5:14:19 AM11/2/22
to MR3
I'm sorry it took me so long to find out. I'll start experimenting right away.
Carol Chapman
Nov 2, 2022, 5:28:16 AM11/2/22
to MR3
However, I found that in
APACHE HIVE , the default value of 'hive.exec.orc.split.strategy ' is also HYBRID .
Therefore, there may be other reasons why the split calculation speed is different
Reply all
Reply to author
Forward
0 new messages