🤗 Daily Paper Newsletter |
 |
Hope you found some gems! |
This newsletter delivers you the curated list of papers by 🤗 Daily Papers. |
|
|
|
|

|
GRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models |
Published at 2025-12-17 |
|
#Diffusion Models
,
#Text-to-Image Generation
|
AI models that create pictures and videos from text often struggle to perfectly understand what you ask for, and it's usually very slow to test them. A new system provides a much faster way to check how well these AI models understand text, and also offers a better text-understanding component that improves the quality of the generated images and videos.... |
Read More |
|
|
|

|
DiRL: An Efficient Post-Training Framework for Diffusion Language Models |
Published at 2025-12-23 |
|
#Diffusion Language Models
,
#Post-Training Optimization
|
Diffusion Language Models struggle with learning after their initial setup, especially for tough tasks like math, because current methods are slow and don't align well with how they're actually used. A new system called DiRL was developed to make this post-training process much faster and more effective, leading to top-tier math performance for these models, even outperforming some established competitors.... |
| Read More |
|
|
|
|

|
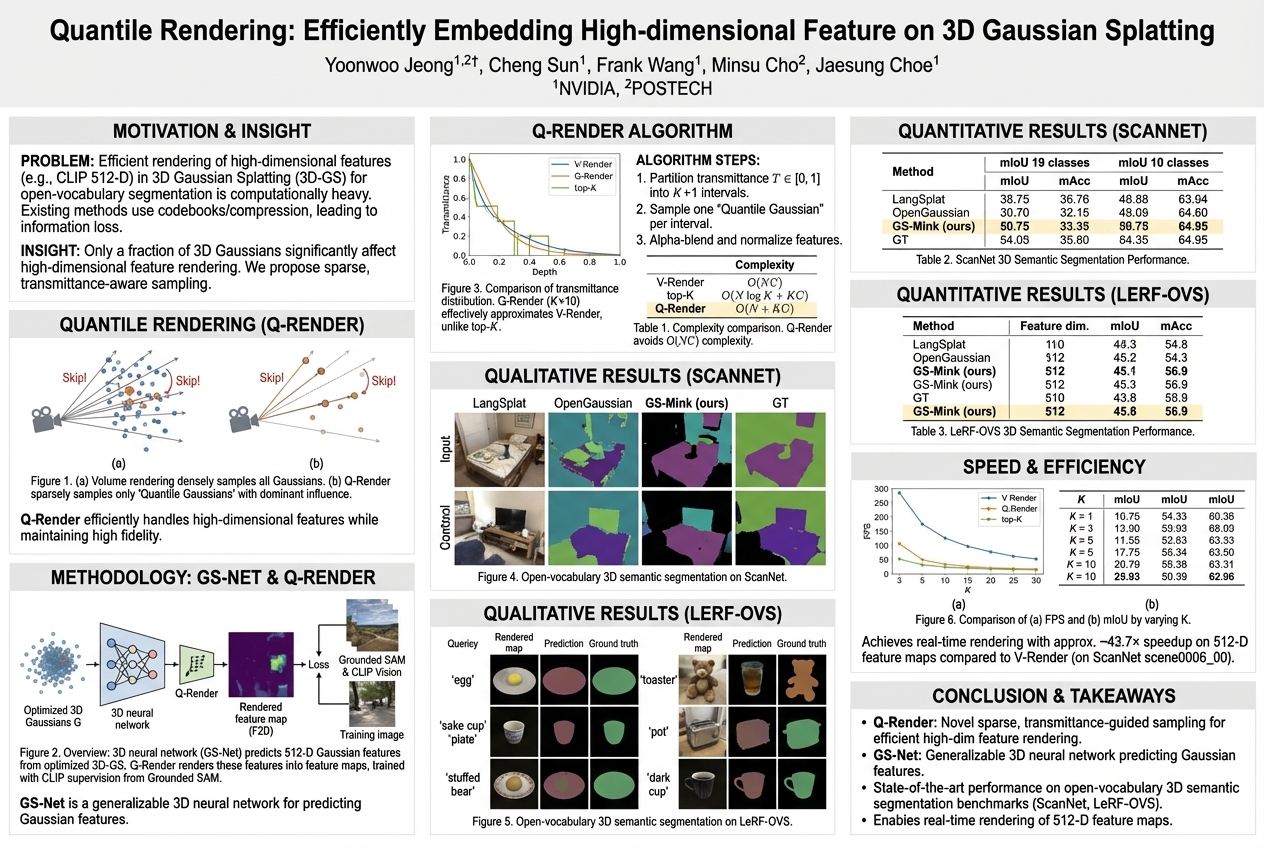
Quantile Rendering: Efficiently Embedding High-dimensional Feature on 3D Gaussian Splatting |
Published at 2025-12-23 |
|
#3D Gaussian Splatting
,
#Rendering Optimization
|
A new rendering method, Quantile Rendering (Q-Render), efficiently handles complex visual information for understanding objects in 3D. It speeds up the process significantly by focusing only on the most important scene elements, offering much faster and more accurate results than previous techniques.... |
| Read More |
|
|
|

|
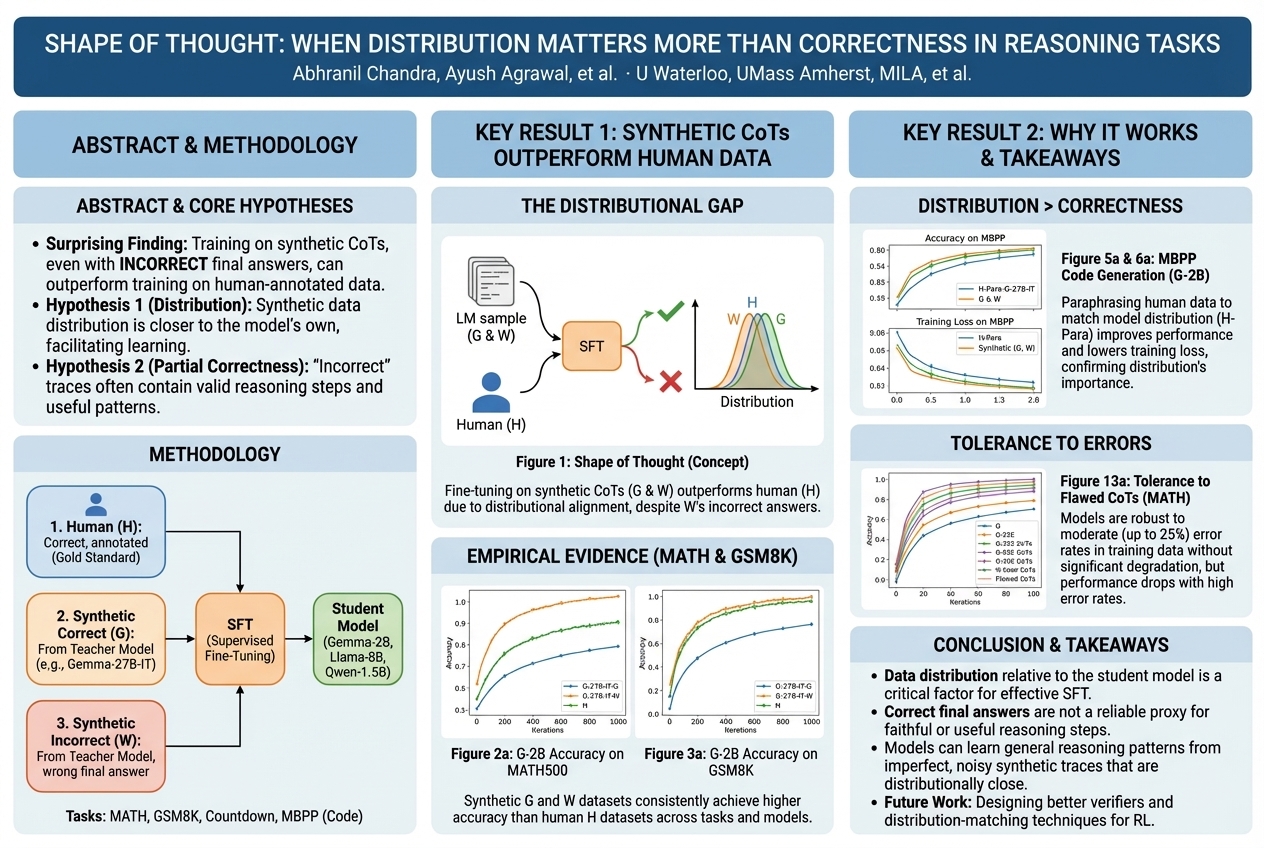
Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks |
Published at 2025-12-24 |
|
#Imitation Learning
,
#Knowledge Distillation
|
Surprisingly, a computer can learn to think better by watching how other clever computers try to solve problems, even when those others make a mistake. It seems computers learn best from examples that look like their own way of thinking, and even 'wrong' thinking often has good parts they can pick up.... |
| Read More |
|
|
|
|

|
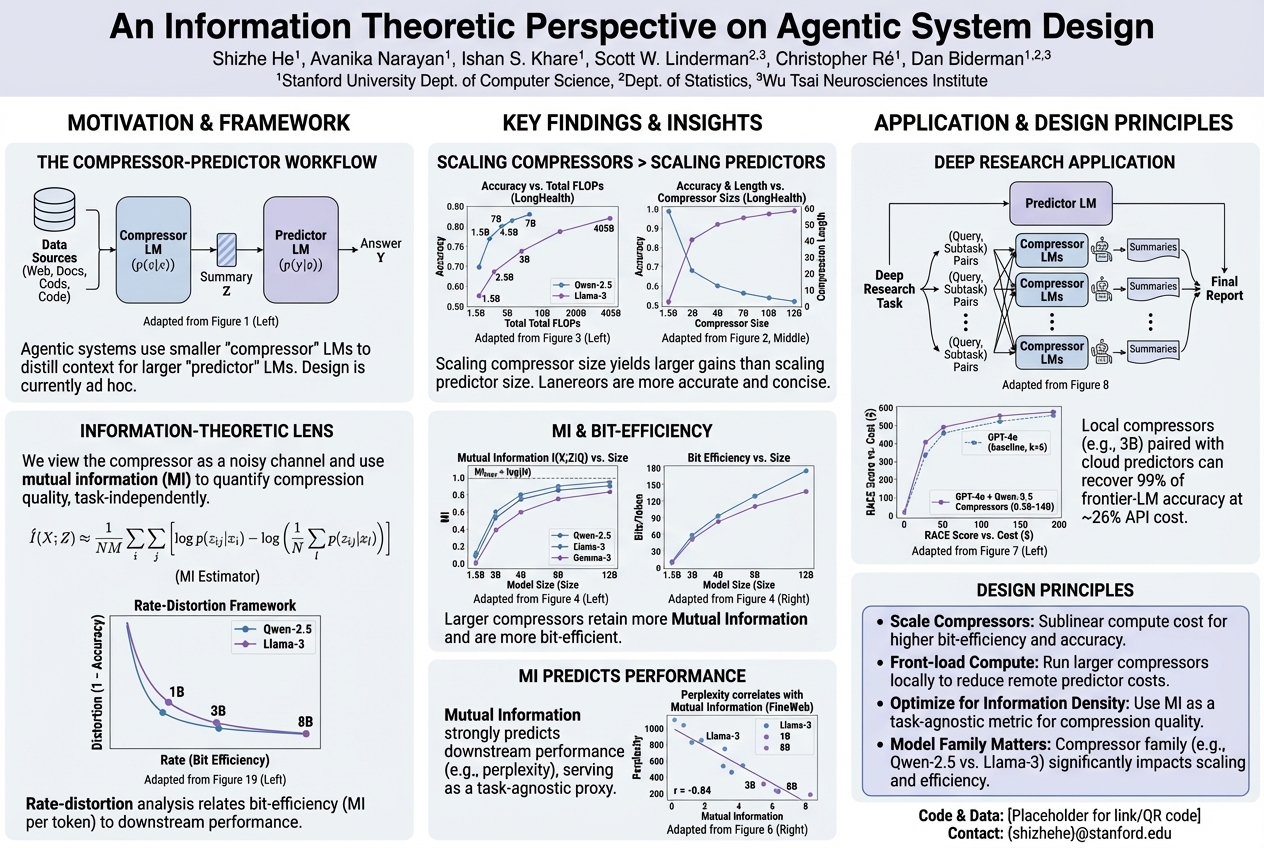
An Information Theoretic Perspective on Agentic System Design |
Published at 2025-12-25 |
|
#Information Theory
,
#Information Bottleneck
|
Many smart computer programs use a small AI to condense information for a bigger AI, but figuring out the best way to design that "condensing" AI used to be a guessing game. A clever way to measure how much useful information the small AI keeps now predicts how well the whole program will work, showing that making the condensing AI more powerful is far more effective than making the main AI bigger, resulting in systems that are both better and cheaper.... |
| Read More |
|
|
|

|
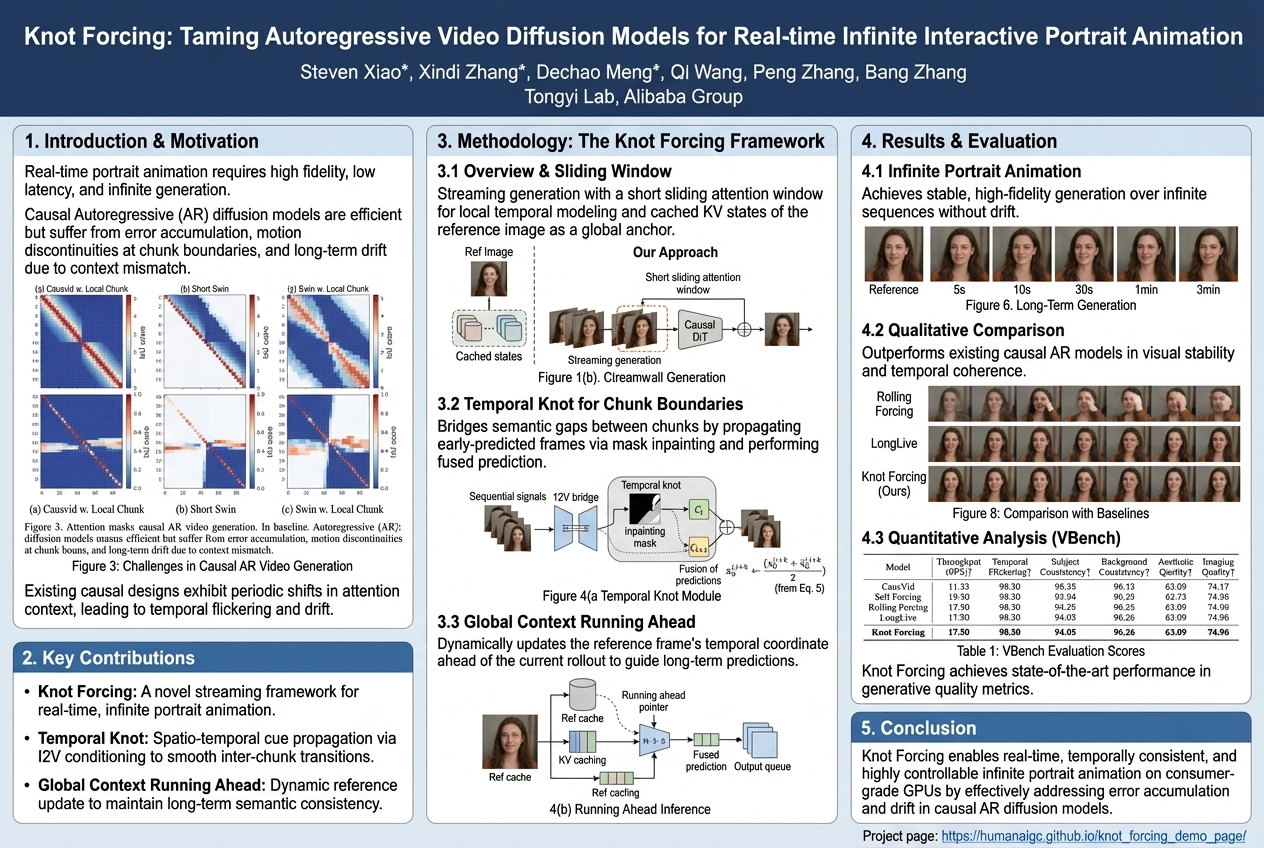
Knot Forcing: Taming Autoregressive Video Diffusion Models for Real-time Infinite Interactive Portrait Animation |
Published at 2025-12-25 |
|
#Video Diffusion Models
,
#Facial Animation
|
Creating real-time, smooth, and endlessly consistent animated faces is tough, as existing tools either look great but are slow, or are fast but glitchy. Knot Forcing is a clever new method that produces high-quality, fluid, and interactive animated portraits non-stop, even on standard computers, by smartly generating video chunks and blending them seamlessly.... |
| Read More |
|
|
|
|

|
Introducing TrGLUE and SentiTurca: A Comprehensive Benchmark for Turkish General Language Understanding and Sentiment Analysis |
Published at 2025-12-26 |
|
#Turkish Language Understanding
,
#Sentiment Analysis
|
Computers haven't had good enough tests to truly understand the Turkish language, making it hard to see how well their smart programs are doing. To fix this, a new comprehensive set of challenges called TrGLUE has been created for Turkish language understanding, alongside SentiTurca for analyzing sentiment, helping researchers build and evaluate better Turkish-speaking AI.... |
| Read More |
|
|
|

|
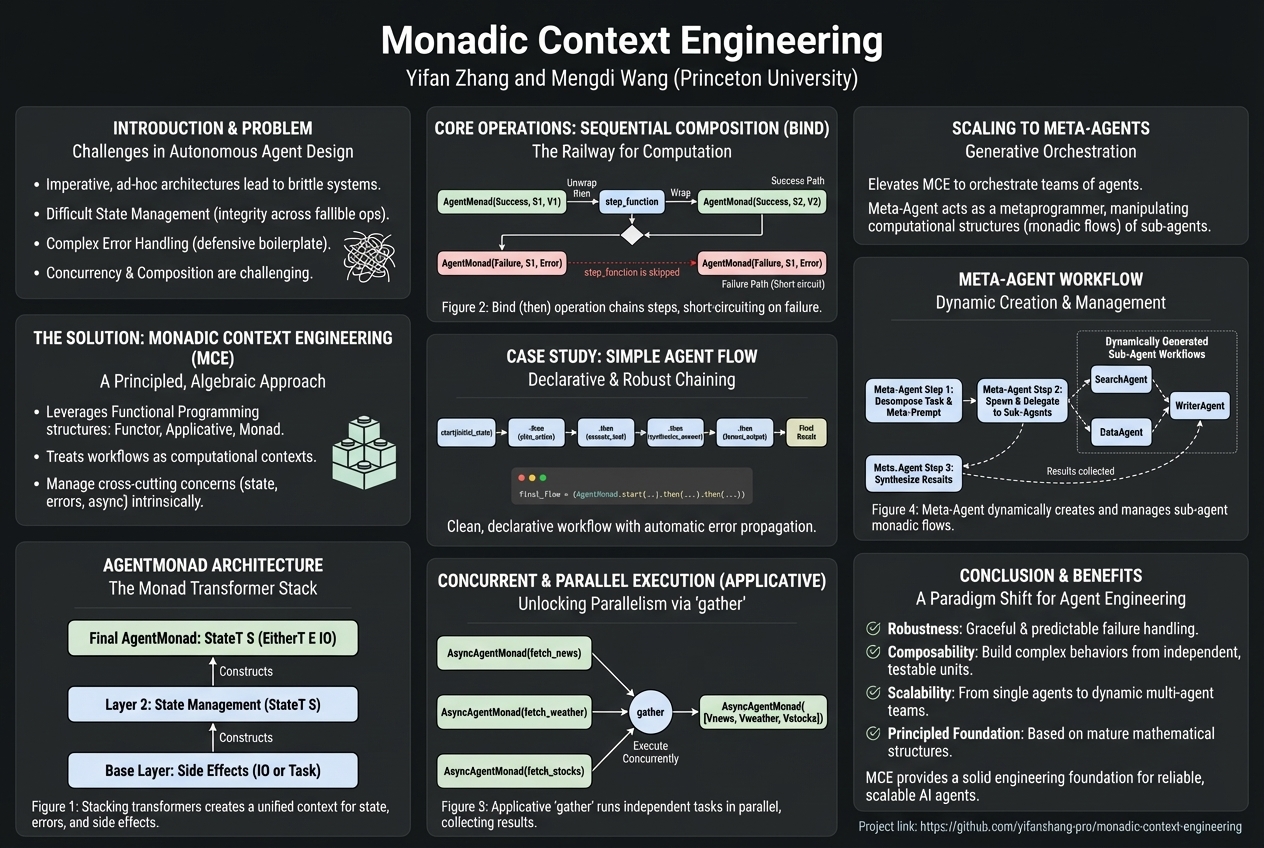
Monadic Context Engineering |
Published at 2025-12-26 |
|
#Context Engineering
,
#Formal Methods for AI
|
Today's smart computer helpers often get mixed up or break because they're built in a jumbled way. Monadic Context Engineering is a clever new blueprint that uses special math tools to build these helpers strongly and neatly, making sure they can handle complex tasks and tricky situations without falling apart.... |
| Read More |
|
|
|
|

|
Self-Evaluation Unlocks Any-Step Text-to-Image Generation |
Published at 2025-12-26 |
|
#Text-to-Image Generation
,
#Self-Evaluation
|
A new image-generating system called Self-E learns to create pictures from text by teaching itself, evaluating its own creations to get better. This allows it to generate high-quality images very quickly in just a few steps, and can also make even better images with more steps, all without needing a pre-trained mentor.... |
| Read More |
|
|
|

|
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents |
Published at 2025-12-26 |
|
#Self-Verifying Agents
,
#Task Completion Verification
|
AI programs often struggle to prove they've finished complicated computer tasks because they wait until the end and sift through too much information, which is slow and unreliable. A clever new system helps these programs learn to actively collect only the most important snapshots of their progress, allowing them to quickly and effectively confirm their own success.... |
| Read More |
|
|
|
|

|
SpotEdit: Selective Region Editing in Diffusion Transformers |
Published at 2025-12-26 |
|
#Image Inpainting
,
#Diffusion Transformers
|
Imagine you want to change just one small thing in a picture, but the computer redraws the whole image every time, making it slow and sometimes messing up parts you liked. SpotEdit is a smart new tool that only redraws the tiny part you actually changed, making edits super fast and keeping the rest of your picture looking exactly how it should be.... |
| Read More |
|
|
|

|
VL-LN Bench: Towards Long-horizon Goal-oriented Navigation with Active Dialogs |
Published at 2025-12-26 |
|
#Vision-and-Language Navigation
,
#Goal-Oriented Dialogue
|
Most robot navigation tasks use clear instructions, but real-world directions are often vague; a new approach called Interactive Instance Object Navigation (IION) teaches robots to ask questions to clarify their goals while moving. To support this, the VL-LN benchmark offers a large dataset and evaluation tools, helping improve robots that can both talk and navigate effectively.... |
| Read More |
|
|
|
|

|
Yume-1.5: A Text-Controlled Interactive World Generation Model |
Published at 2025-12-26 |
|
#Text-to-3D Generation
,
#Interactive World Generation
|
Making interactive computer worlds you can explore has been tough because existing tools are often too big, slow, and hard to tell what to create using words. Yume-1.5 is a new system that quickly builds realistic, explorable worlds from a simple image or text prompt, letting you walk around and even control events within them just by typing.... |
| Read More |
|
|
|

|
Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion Language Model Backbone |
Published at 2025-12-27 |
|
#Diffusion Models
,
#Embodied AI
|
Current smart programs that understand pictures and words often struggle with complex visual planning and robot control because they think one step at a time. A new type of smart program, Dream-VL and Dream-VLA, was developed using a different "diffusion" thinking style, allowing them to understand pictures, words, and robot actions much more efficiently, leading to faster robot learning and top performance on challenging tasks.... |
| Read More |
|
|
|
|

|
Reverse Personalization |
Published at 2025-12-28 |
|
#Face Anonymization
,
#Controllable Face Manipulation
|
AI can create very realistic faces, but it's tricky to remove someone's unique identity from an image without complex steps. A new method called "reverse personalization" helps anonymously alter faces while still letting you control other features like hair or expression, even for faces the AI hasn't seen before.... |
| Read More |
|
|
|

|
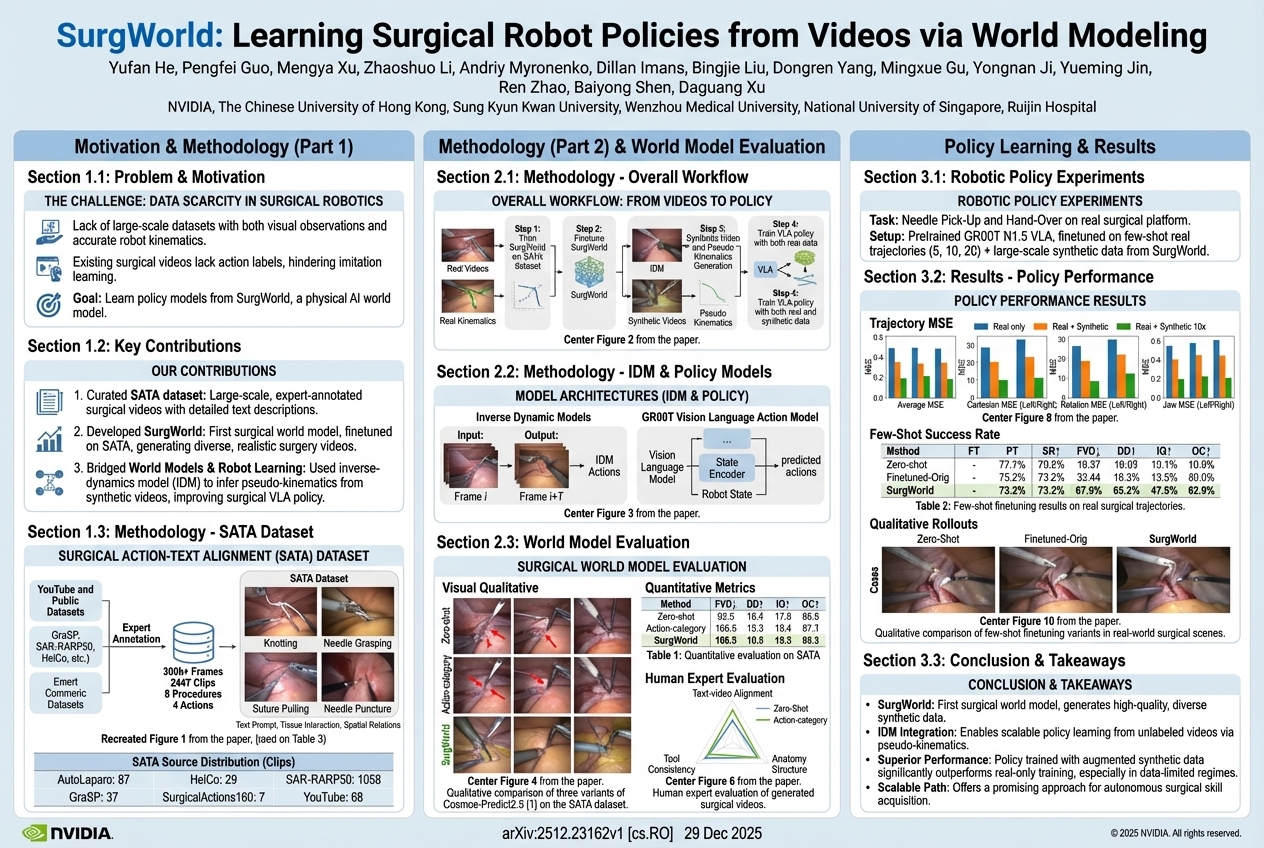
SurgWorld: Learning Surgical Robot Policies from Videos via World Modeling |
Published at 2025-12-28 |
|
#Surgical Robotics
,
#World Modeling
|
Surgical robots can't easily learn from existing operation videos because those videos don't show the exact movements the robot made. A special computer program called SurgWorld generates realistic practice videos and figures out the robot's actions within them, greatly improving how well robots learn to perform surgical tasks.... |
| Read More |
|
|
|
|

|
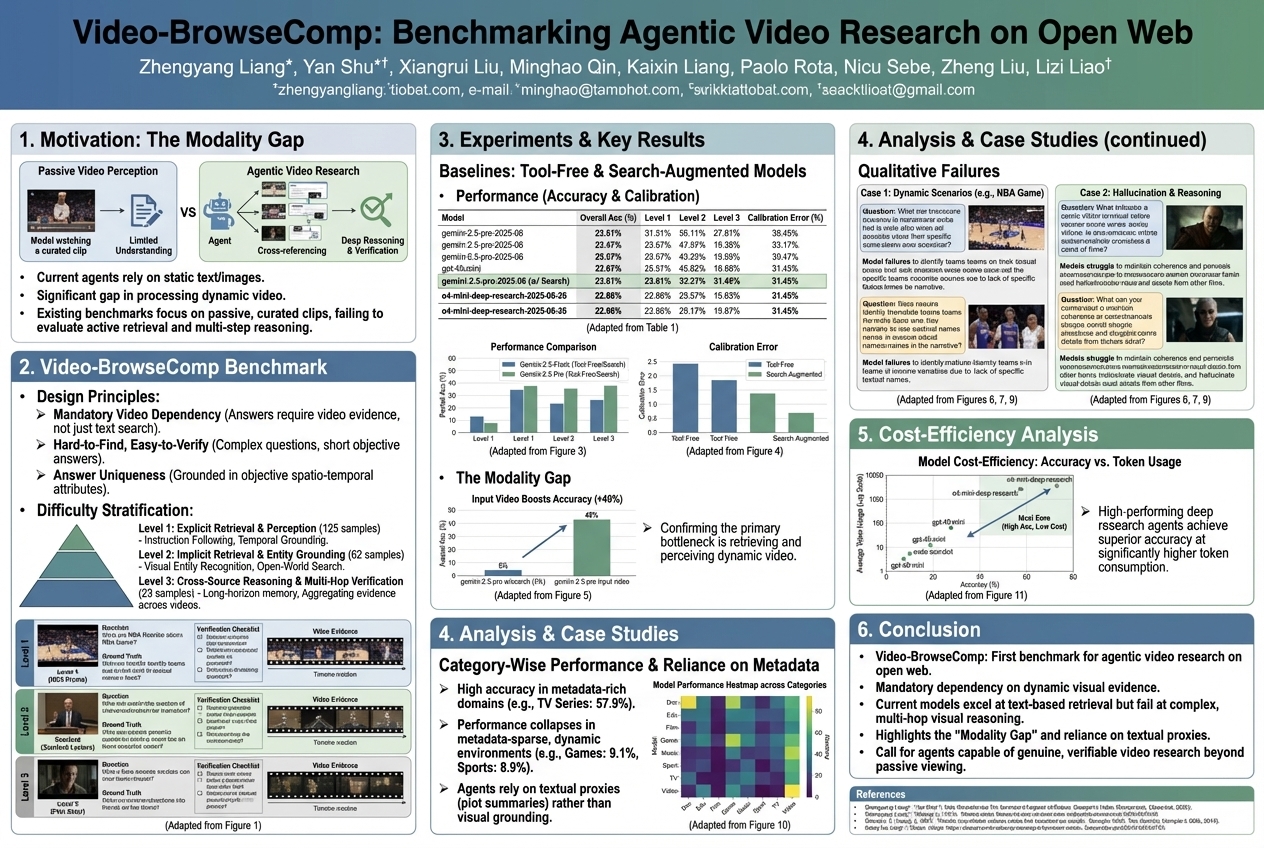
Video-BrowseComp: Benchmarking Agentic Video Research on Open Web |
Published at 2025-12-28 |
|
#AI Agents
,
#Video Understanding
|
Smart computer programs are good at reading and looking at pictures, but they struggle to really understand information from videos on the internet, especially when they need to actively "watch" and find specific details. A new, harder challenge called Video-BrowseComp reveals that even the best programs are still very bad at truly seeing and using video evidence, often trying to guess from text instead of learning from what's actually shown.... |
| Read More |
|
|
|

|
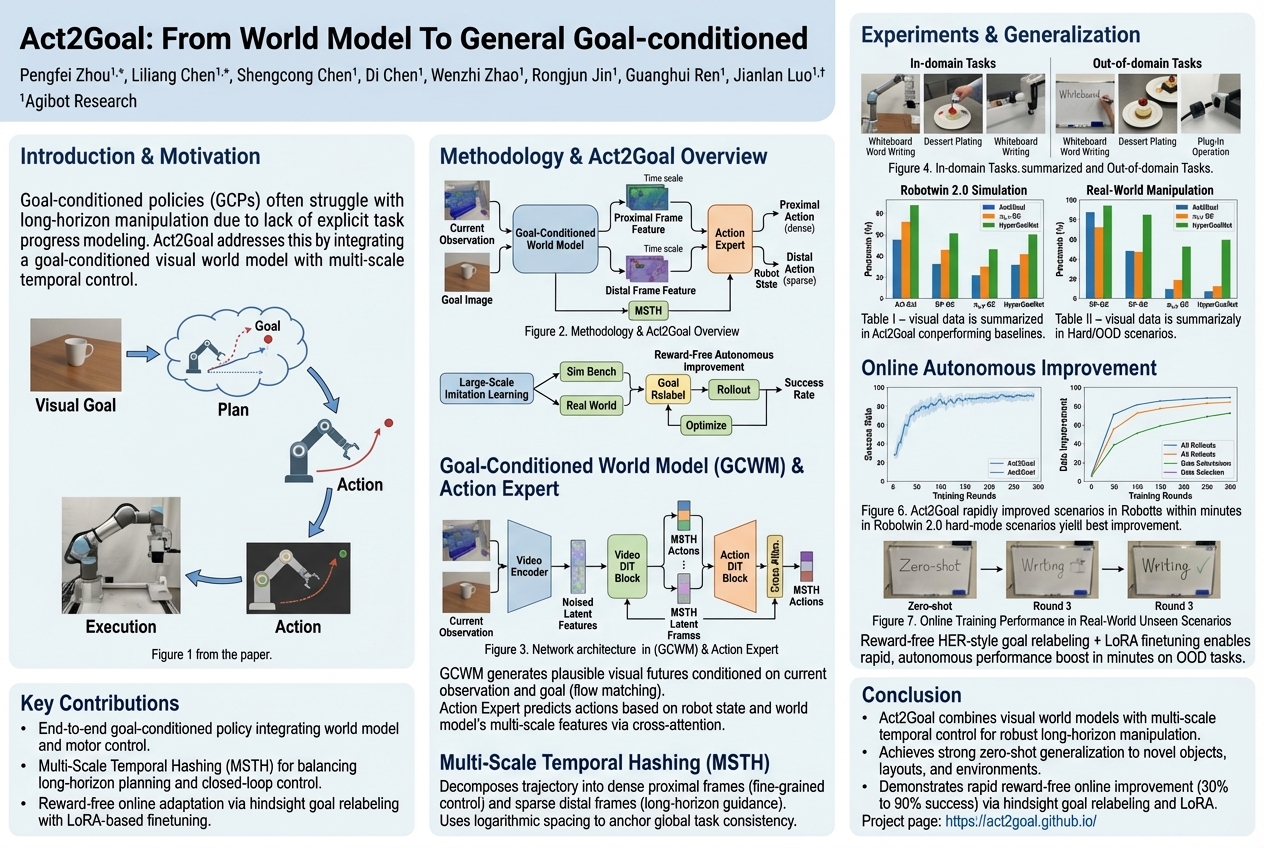
Act2Goal: From World Model To General Goal-conditioned Policy |
Published at 2025-12-29 |
|
#Robotics
,
#Goal-conditioned Reinforcement Learning
|
Robots find it hard to do long, tricky tasks because they only think one step ahead, even when shown the final picture. A new system called Act2Goal helps robots by letting them imagine all the necessary steps to reach a big goal, then guides them through those steps to perform complex tasks much more reliably and learn quickly.... |
| Read More |
|
|
|
|

|
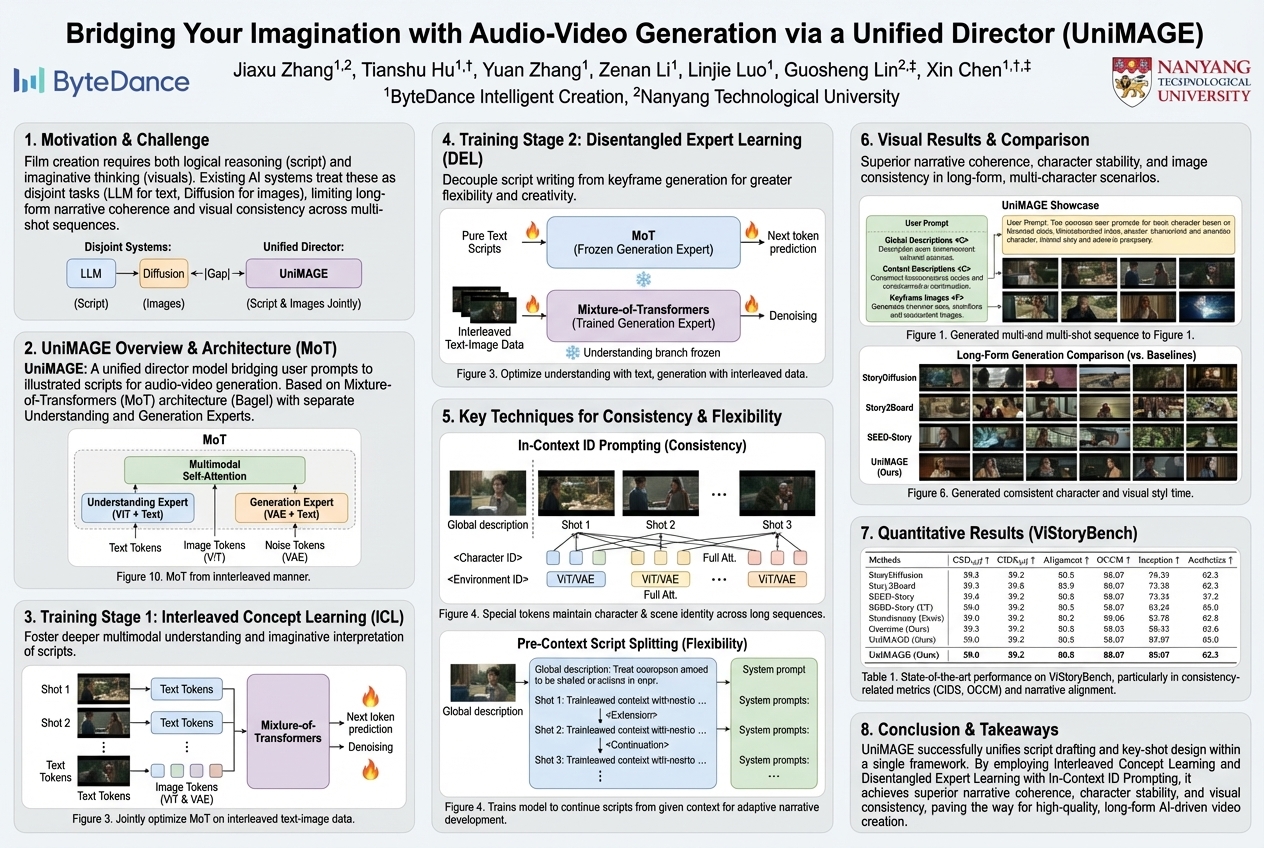
Bridging Your Imagination with Audio-Video Generation via a Unified Director |
Published at 2025-12-29 |
|
#Audio-Video Generation
,
#Multimodal Generation
|
An AI model acts like a unified movie director, taking simple ideas and turning them into complete, multi-scene films. It combines story writing and visual planning into one process, making it easier for anyone to create videos with coherent scripts and consistent images.... |
| Read More |
|
|
|

|
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss |
Published at 2025-12-29 |
|
#Mixture-of-Experts
,
#Expert Specialization
|
Mixture-of-Experts models sometimes struggle because the system that directs information (router) doesn't reliably match tasks with the right specialized processing unit (expert). A new helper called ERC loss ensures each expert truly excels at the type of information it's supposed to handle, making the router's choices much better and improving the overall performance of these models.... |
| Read More |
|
|
|
|

|
Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation |
Published at 2025-12-29 |
|
#Diffusion Models
,
#Transparent Object Perception
|
Getting computers to understand clear objects like glass is really hard because light plays tricks, making it tough to figure out their shape and distance. But by taking a video-making AI that already "knows" how to create realistic clear objects and teaching it a little more, it can now precisely map these tricky items, even helping robots grasp them better.... |
| Read More |
|
|
|

|
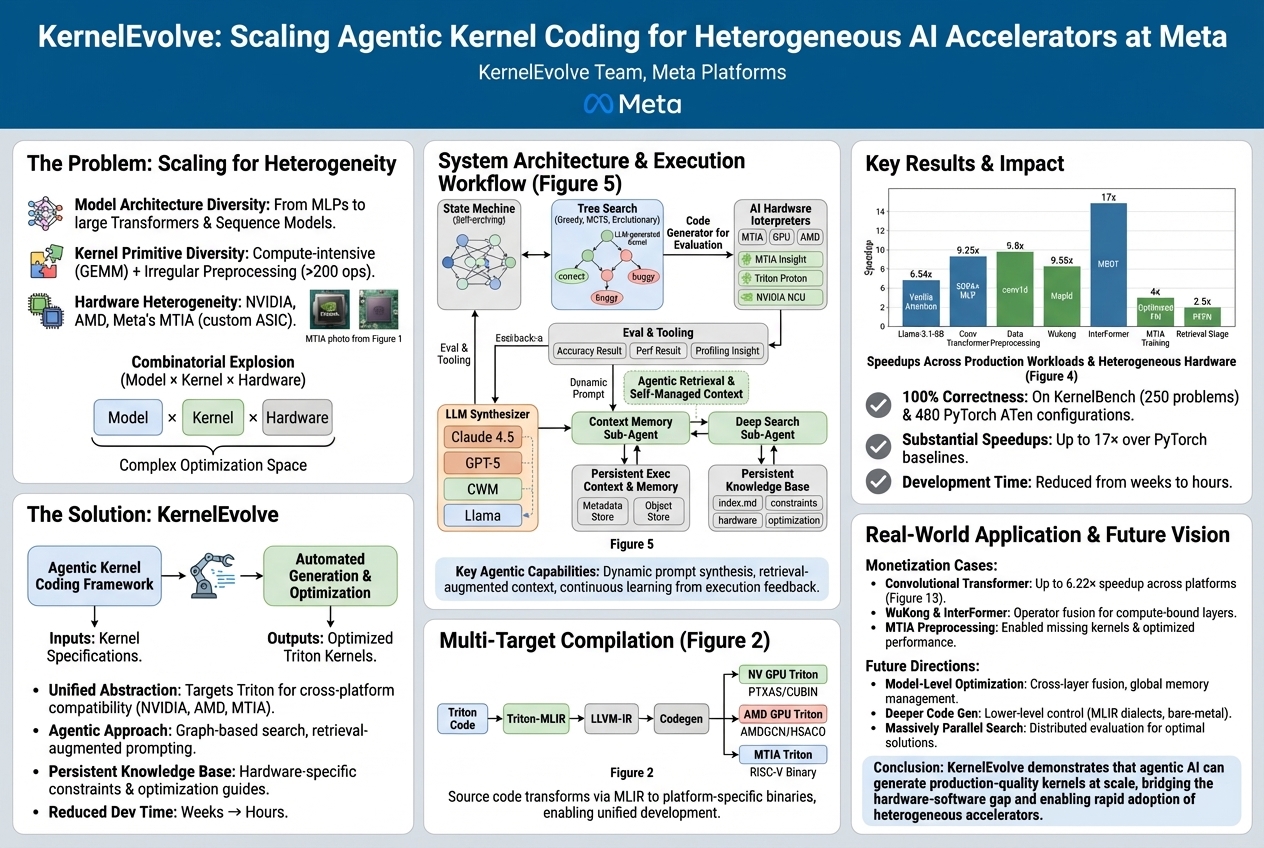
KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta |
Published at 2025-12-29 |
|
#Automated Code Generation
,
#AI Hardware Optimization
|
Making AI recommendation models run quickly and efficiently is tough due to the many different models, math operations, and computer chips involved. A smart system called KernelEvolve automatically writes and fine-tunes the special instructions for these chips, making recommendation models run much faster and significantly simplifying the use of new AI hardware.... |
| Read More |
|
|
|
|

|
LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation |
Published at 2025-12-29 |
|
#Multimodal Learning
,
#Video Diffusion Models
|
Making AI-generated videos interactive and in real-time is tricky, especially when the AI needs to understand words, pictures, and sounds all at once. A new method drastically speeds up this process, creating high-quality videos instantly and enabling smooth, natural conversations with AI avatars, like the LiveTalk system.... |
| Read More |
|
|
|

|
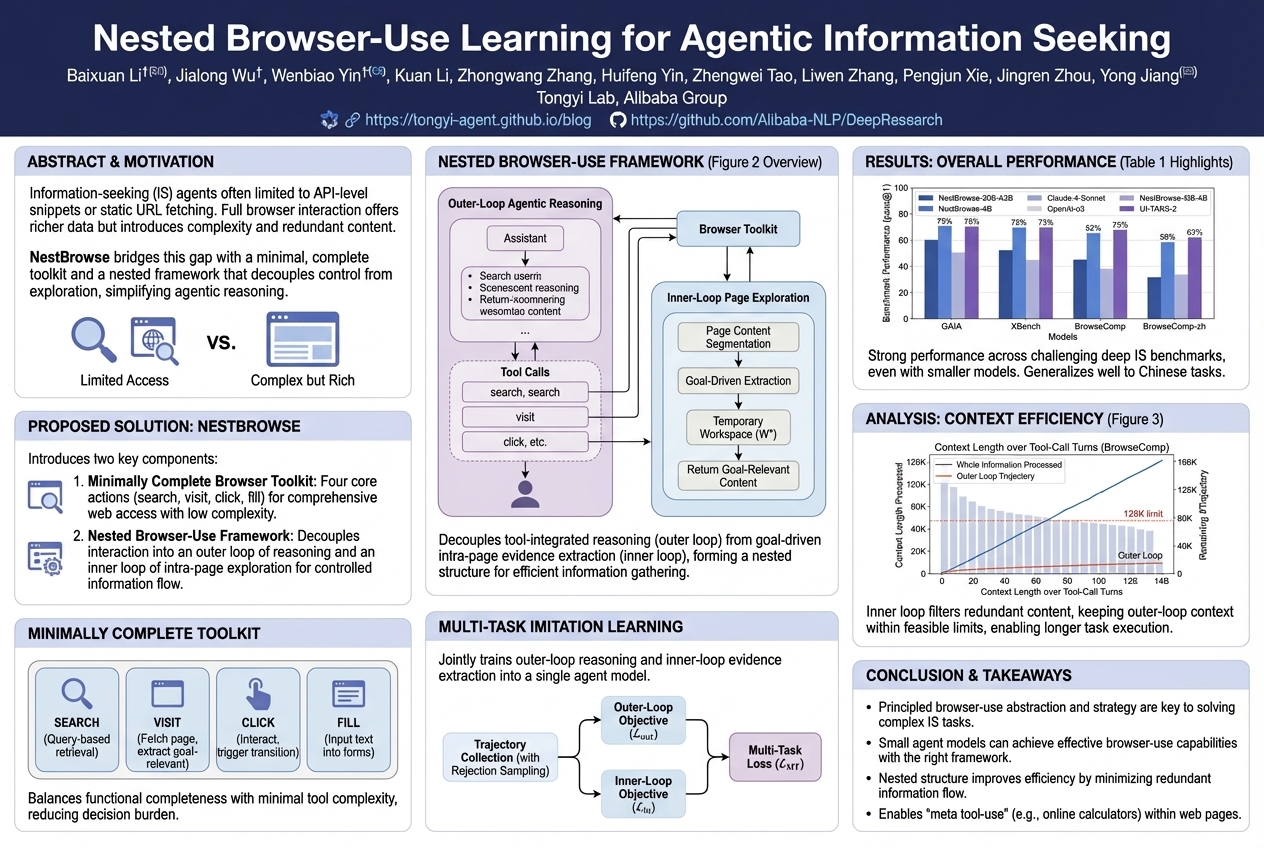
Nested Browser-Use Learning for Agentic Information Seeking |
Published at 2025-12-29 |
|
#Agentic AI
,
#Web Information Seeking
|
AI agents currently struggle to truly browse the internet like humans, limiting their access to rich information on complex websites. A new technique, NestBrowse, makes this easier by splitting how agents control the browser from how they explore page content, allowing them to efficiently find deep web information.... |
| Read More |
|
|
|
|

|
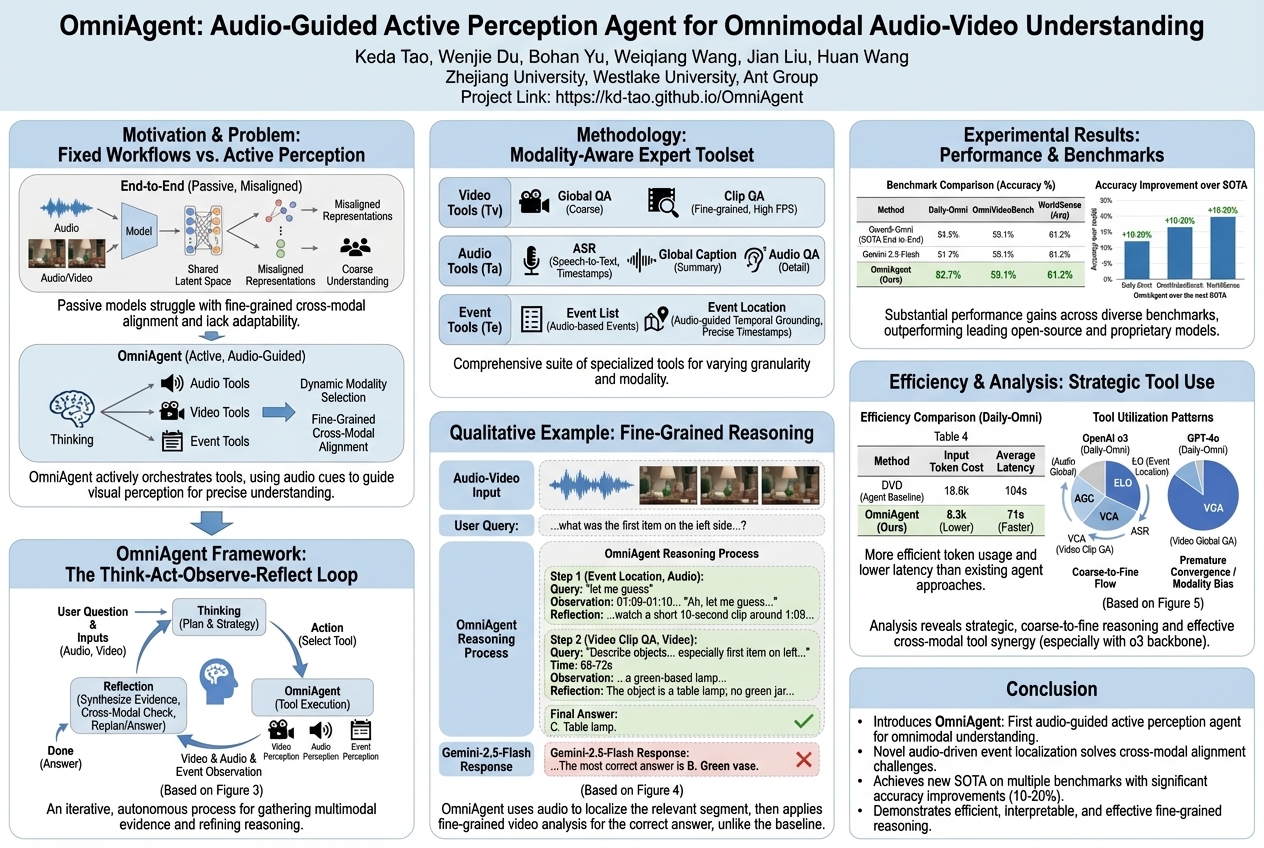
OmniAgent: Audio-Guided Active Perception Agent for Omnimodal Audio-Video Understanding |
Published at 2025-12-29 |
|
#Multimodal Learning
,
#Active Perception
|
Smart systems that try to understand both sounds and videos often miss the tiny details of how they connect. A new clever agent called OmniAgent solves this by actively listening to sounds, using them as clues to decide where to focus its attention and what special tools to use, making it much better at truly understanding sound and video together.... |
| Read More |
|
|
|

|
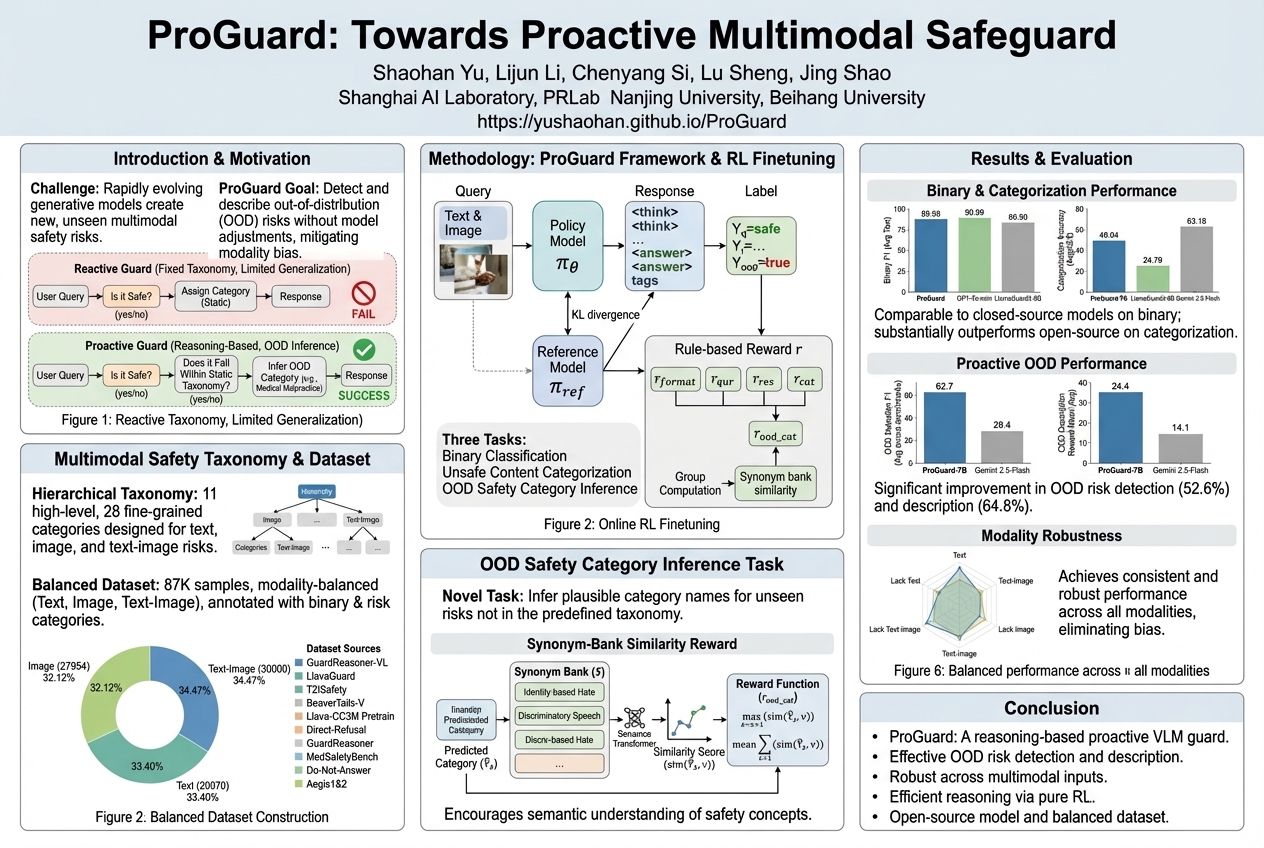
ProGuard: Towards Proactive Multimodal Safeguard |
Published at 2025-12-29 |
|
#Multimodal Learning
,
#Novelty Detection
|
AI models that create content often introduce new safety risks that current protection systems struggle to handle. A new digital guardian called ProGuard proactively identifies and describes these unexpected dangerous situations in both images and text, proving much better at spotting brand-new threats than existing tools.... |
| Read More |
|
|
|
|

|
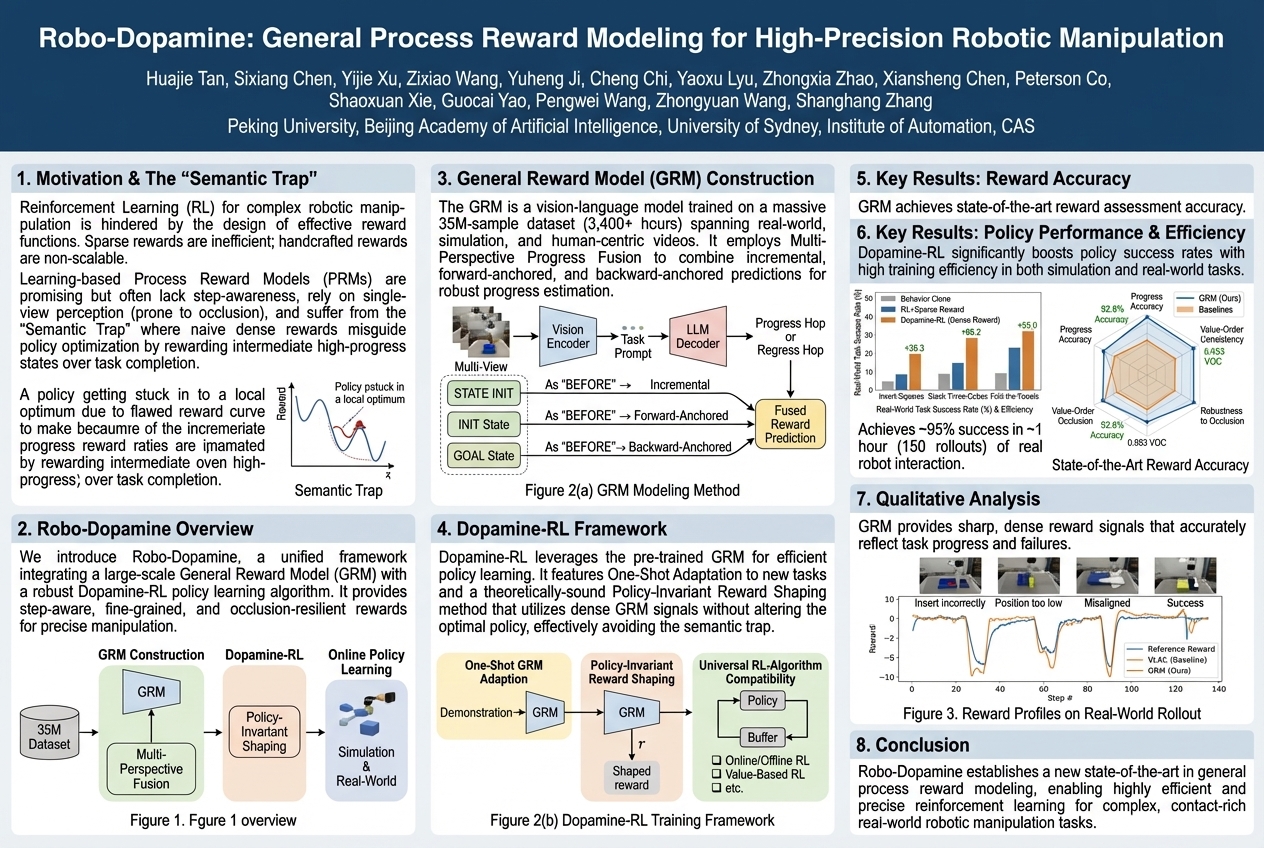
Robo-Dopamine: General Process Reward Modeling for High-Precision Robotic Manipulation |
Published at 2025-12-29 |
|
#Robotic Manipulation
,
#Reward Modeling
|
Robots learning new skills often struggle because it's hard to precisely tell them if they're making progress, especially with complex tasks and only one viewpoint. A new system called Dopamine-Reward helps robots understand their actions better by using many camera angles and breaking down progress into clear, small steps. This approach allows robots to learn intricate manipulation tasks much faster and more reliably, leading to significant improvements in their success rate with minimal traini... |
| Read More |
|
|
|

|
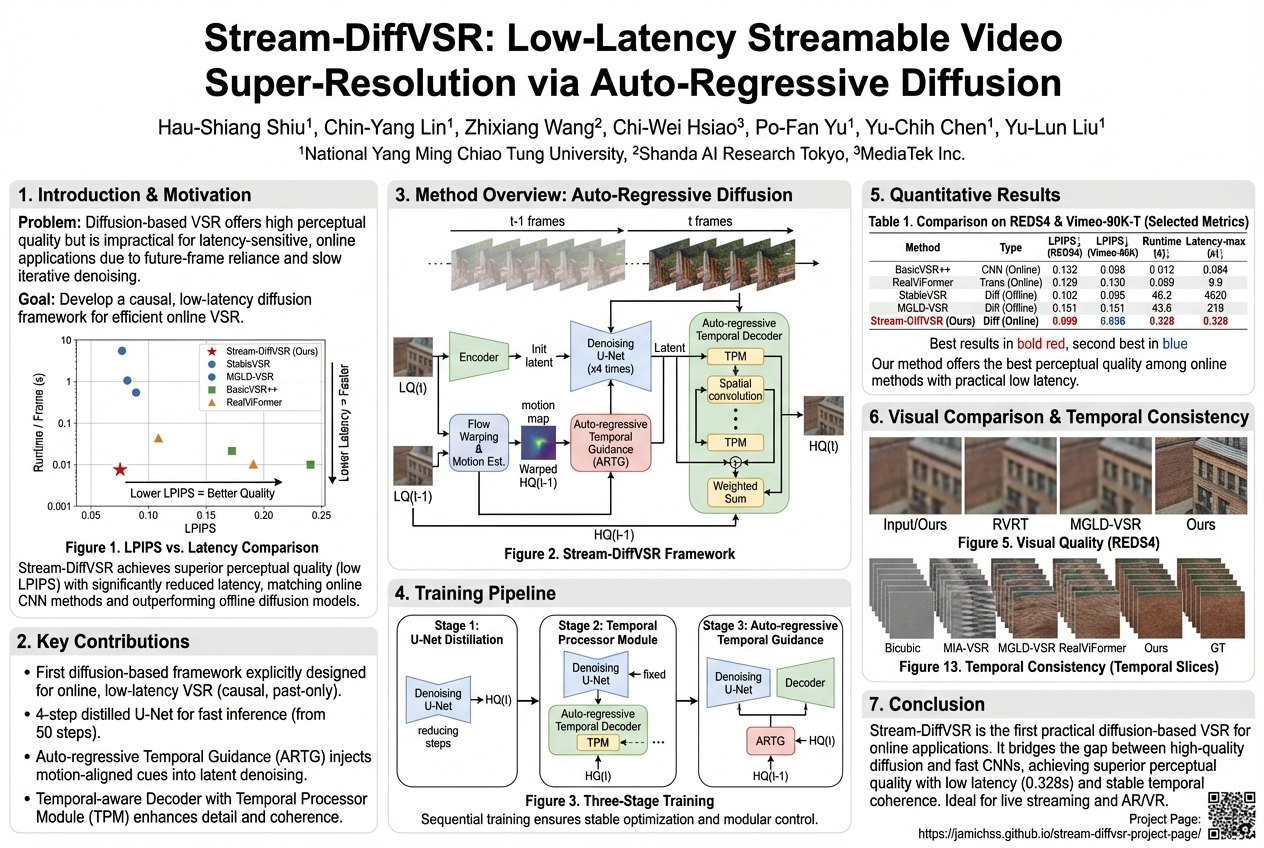
Stream-DiffVSR: Low-Latency Streamable Video Super-Resolution via Auto-Regressive Diffusion |
Published at 2025-12-29 |
|
#Video Super-Resolution
,
#Auto-Regressive Diffusion
|
High-quality video enhancement tools usually make blurry videos super sharp, but they're too slow for live viewing because they try to predict the future. A new method called Stream-DiffVSR fixes this by only looking at past video, making videos look much better and smoother incredibly fast, which means live streams can now have amazing quality.... |
| Read More |
|
|
|
|

|
Training AI Co-Scientists Using Rubric Rewards |
Published at 2025-12-29 |
|
#Scientific Discovery
,
#Automated Assessment
|
AI can now be trained to create better research plans for scientists by learning from existing papers and grading its own work using automatically extracted rules. This self-improvement process leads to plans that human experts prefer and is effective across various scientific fields, like medicine.... |
| Read More |
|
|
|

|
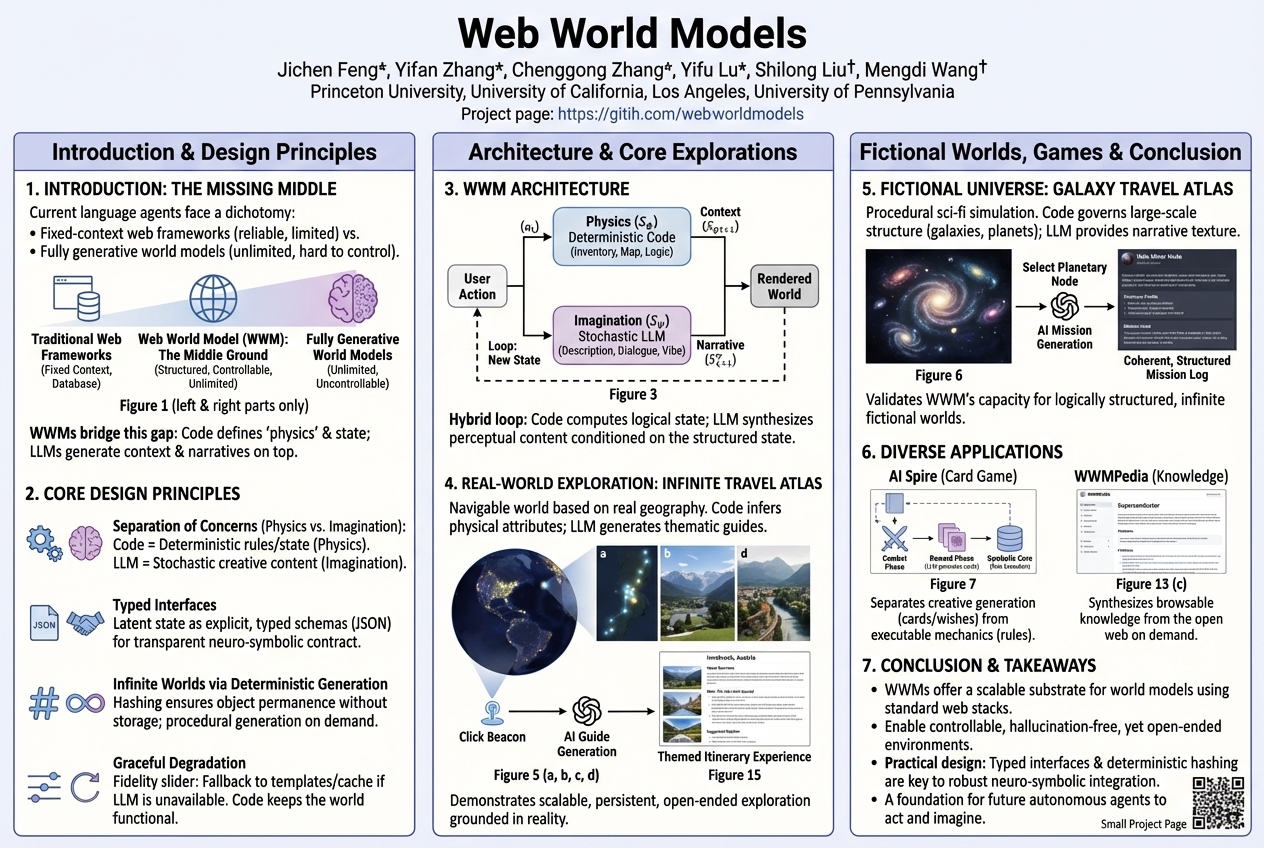
Web World Models |
Published at 2025-12-29 |
|
#Web-based Simulations
,
#Generative World Modeling
|
Building interactive worlds for AI typically involves choosing between rigid, fixed environments or totally wild, unpredictable ones. A new approach offers a middle ground by using standard web code for the reliable rules and structure, letting AI models then imagine all the stories and details within those boundaries.... |
| Read More |
|
|
|
|

|
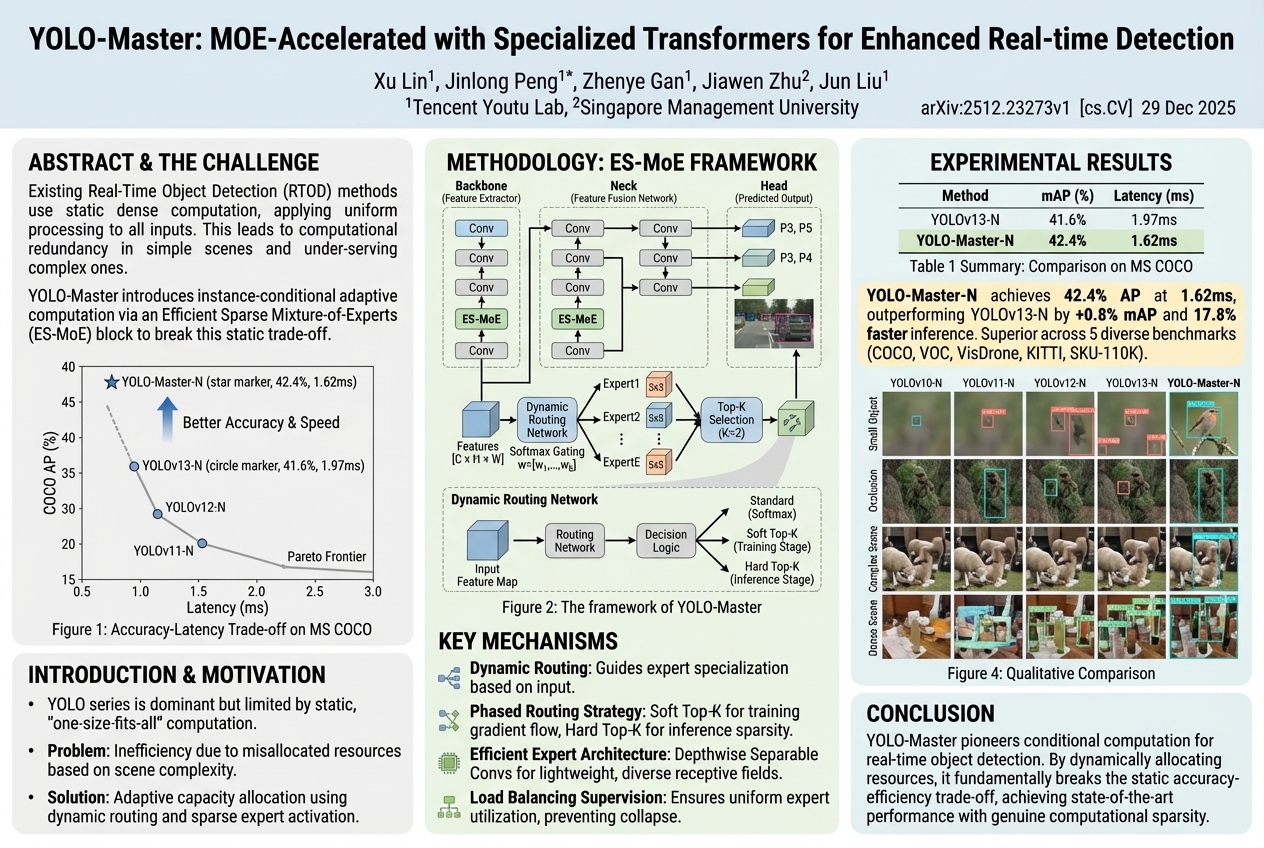
YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection |
Published at 2025-12-29 |
|
#Object Detection
,
#Mixture-of-Experts
|
Existing systems for finding objects in real-time use the same amount of effort for every picture, which wastes energy on easy scenes and struggles with difficult ones. A new method called YOLO-Master learns to smartly focus more processing power on complex scenes and less on simple ones, making object detection both faster and more accurate, especially in challenging situations.... |
| Read More |
|
|
|
|
|