Assessing model convergence based on traces and autocorrelation plots and fixing convergence issues
53 views
Skip to first unread message

Maï-Carmen Requena
Oct 11, 2021, 8:47:43 AM10/11/21
to hddm-users
Hi,
I am a new user of HDDM and have little experience in MCMC sampling in general so I have trouble figuring out what is and what is not acceptable in terms of convergence just by looking at traces and autocorrelation plots, and also how to appropriately fix convergence issues as it seems to be a lot of trial and error.
I am analysing data from a temporal bisection task where each decision may depend on the duration of the sound played (one of 7 durations) and the type of sound (one of 4 categories). I am using HDDMStimCoding to run several models of increasing complexity as follows: v depends on duration < v and a depend on duration < v, a, and t depend on duration < v, a, t, z depend on duration and then only v depends on duration and sound category, etc until all 4 parameters depend on both duration and sound category.
I always use the same sampling parameters to run each model (model.sample(10000, burn=2000, thin=5)), but I obtain different levels of convergence depending on the complexity of the model.
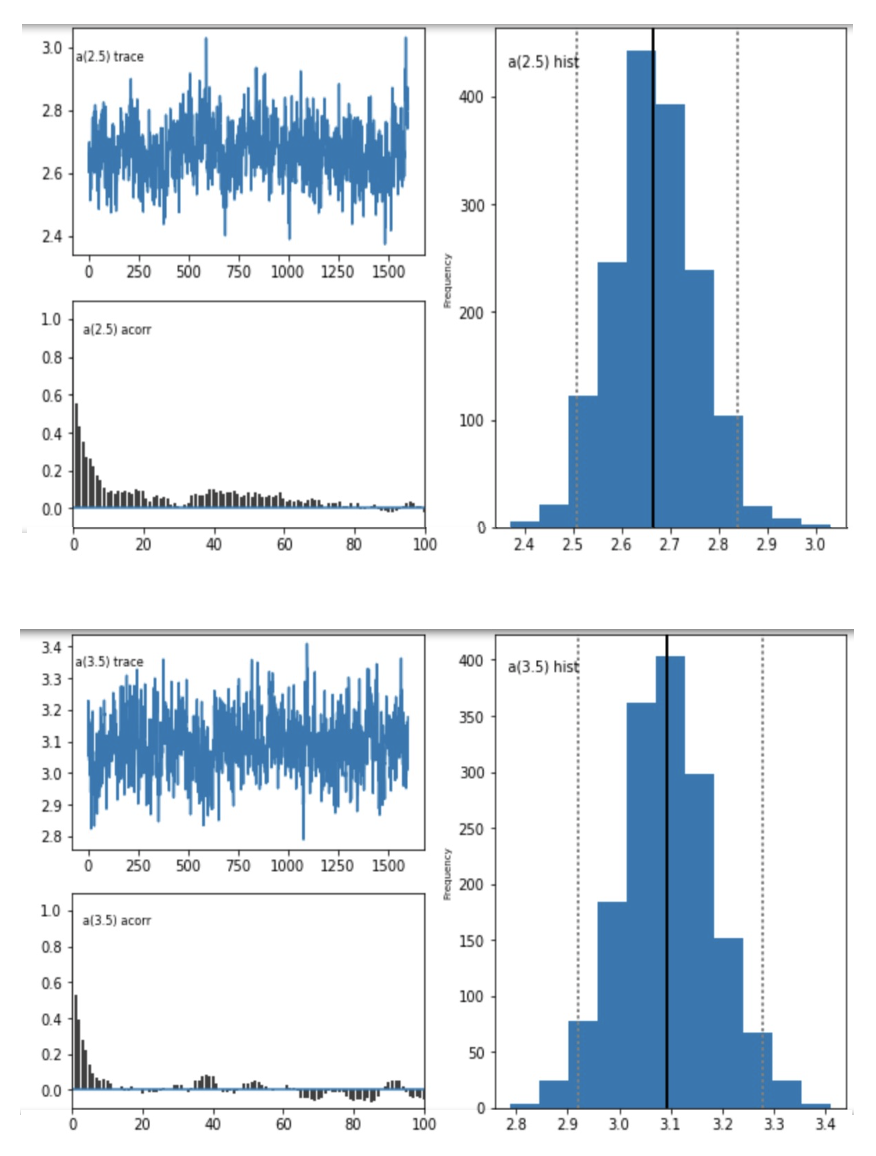
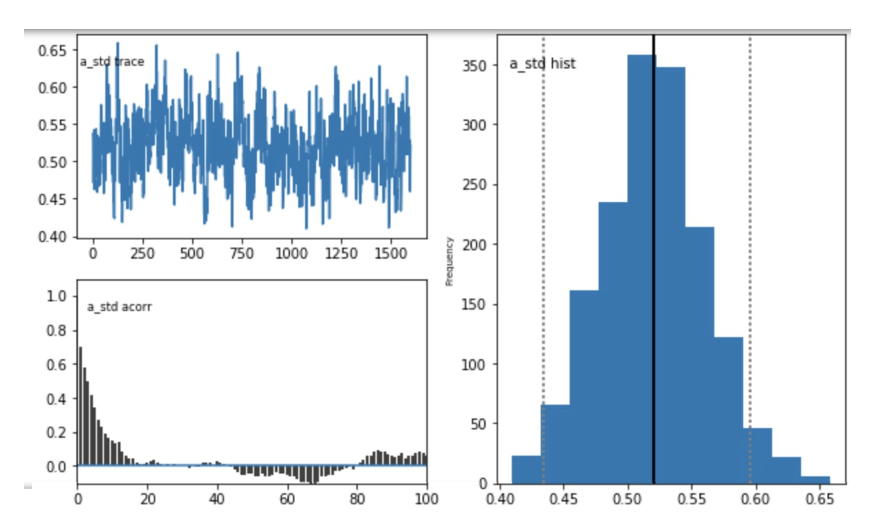
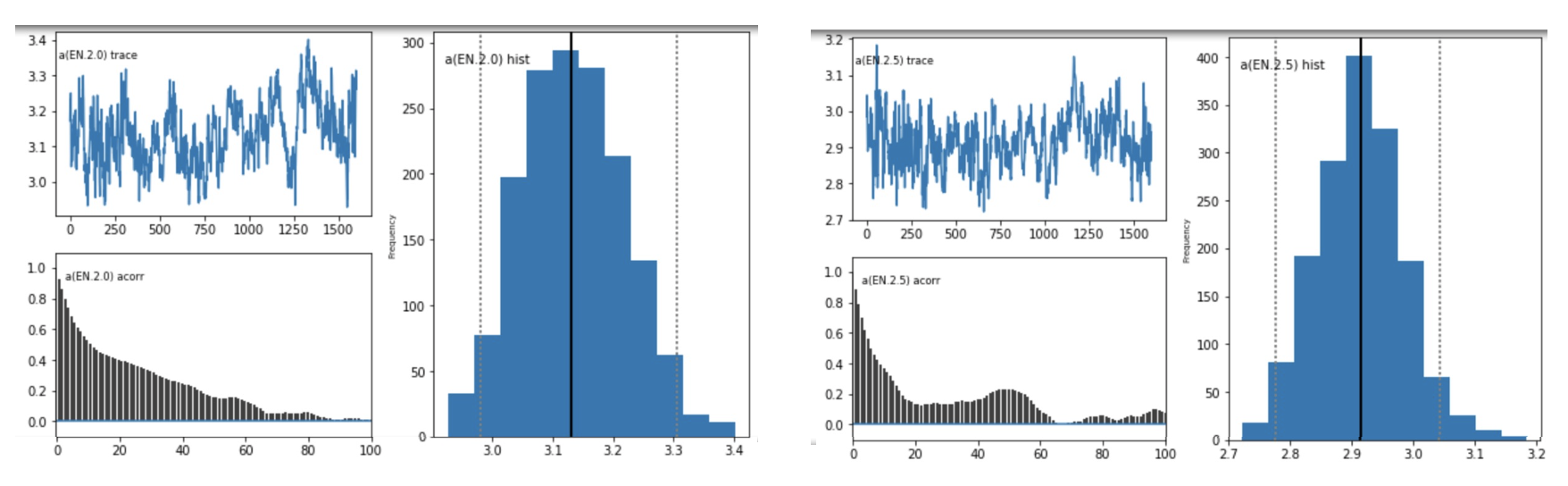
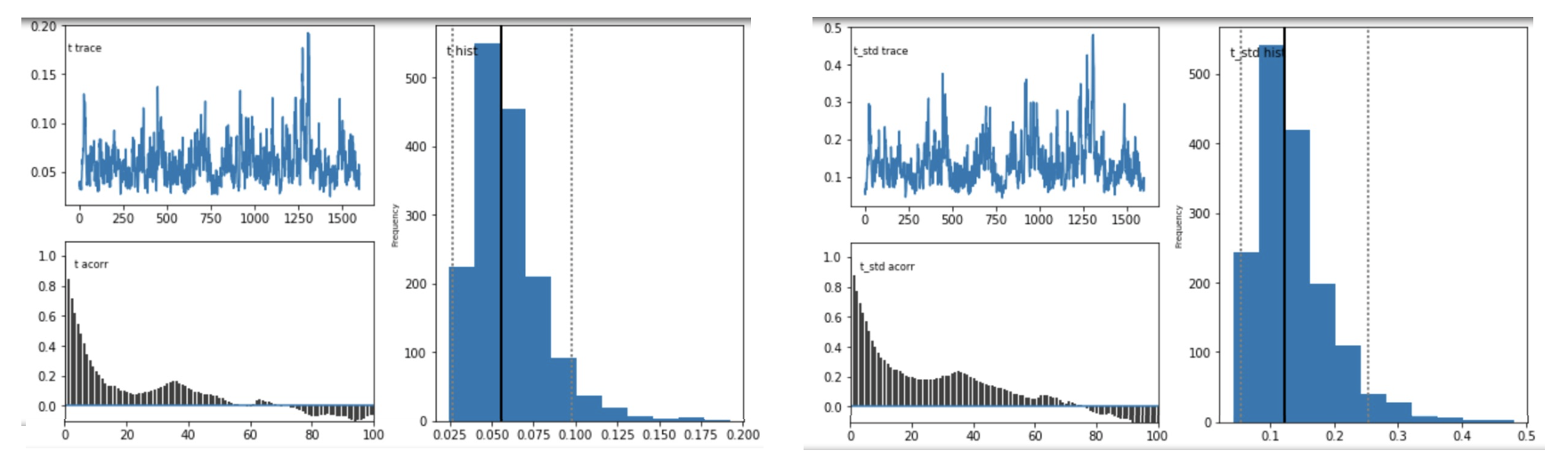
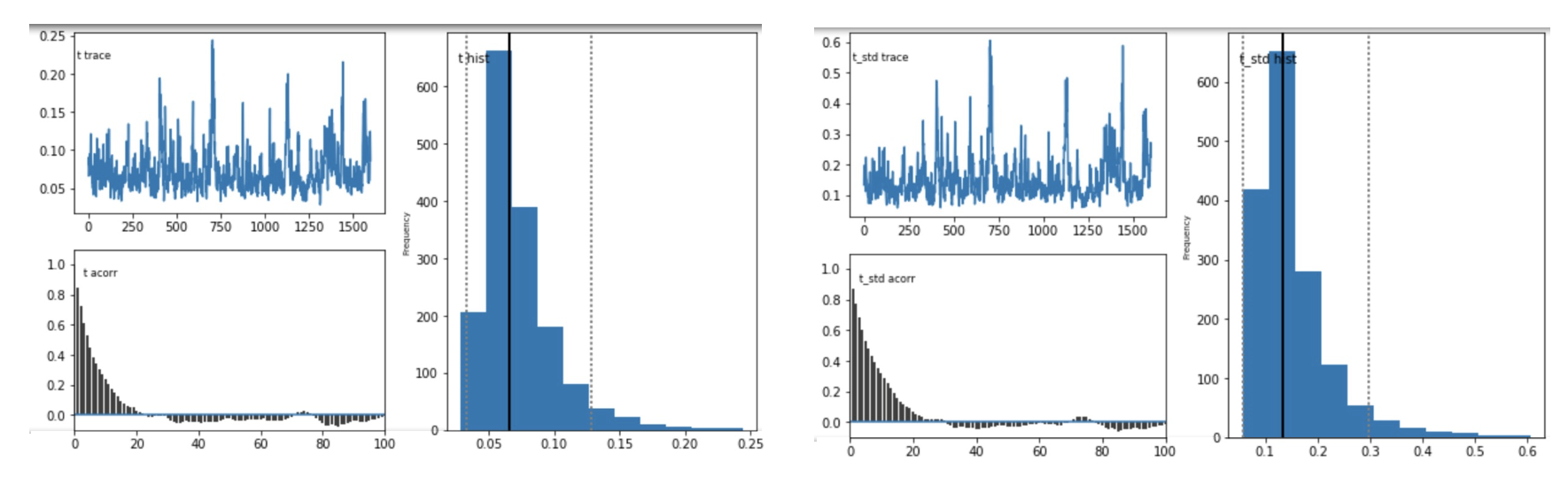
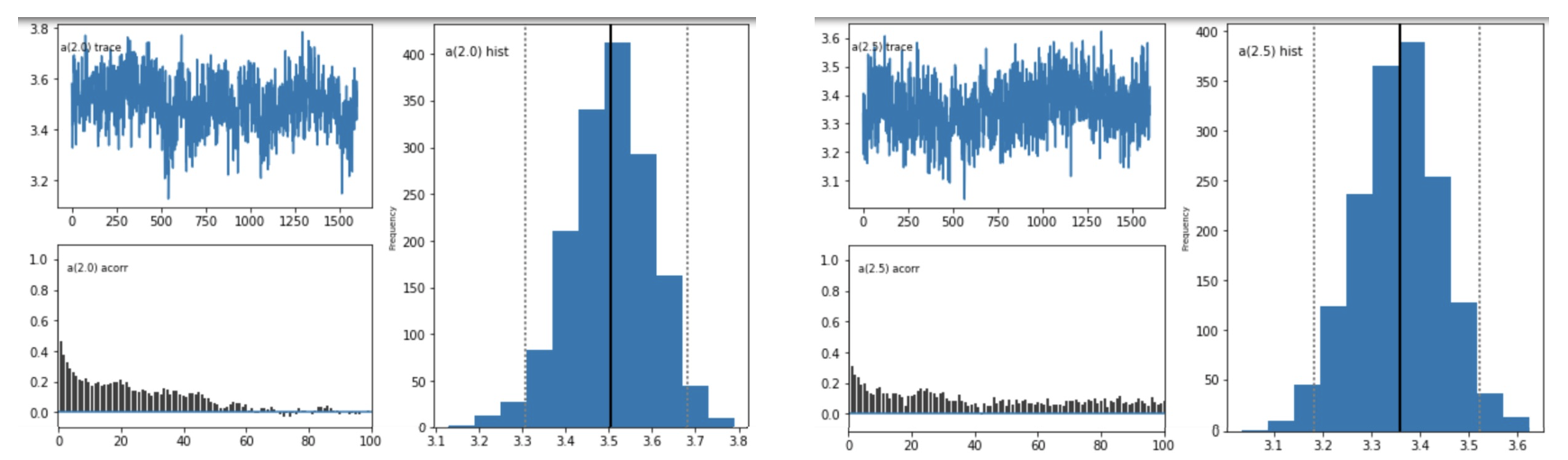
Question 1: Do these posterior plots look fine?
model A - plots for parameter a
model B - plots for parameter a
model C - plots for parameter a
model D - plots for parameter t
model E - plots for parameter t
model F - plots for parameter a
Question 2: If there are signs of non-convergence, I understand that increasing the number of samples will help, but is there any rule to help determine how many more samples I should add? For example, model C looks to me like it has not converged yet, but should I be trying 15000 samples or 20000 samples or even more? Each model takes quite a lot of time to run so I am trying to minimise the time spent on optimisation.
Question 3: Once I have run all the different models, my plan is to choose the one with the lowest DIC value to run the German-Rubin statistic. However, I am wondering whether it is right to compare models for which I will not have used the same sampling parameters? This is because I have noticed that a model that has converged will have a lower DIC value than the same model when it has not converged.
Thank you in advance for your help on any of these questions.
Mai-Carmen
Reply all
Reply to author
Forward
0 new messages