folly::F14ValueSet vs absl::flat_hash_set
2,271 views
Skip to first unread message

Matthew Fowles Kulukundis
Sep 30, 2018, 12:49:12 PM9/30/18
to hashtable-...@googlegroups.com
All~
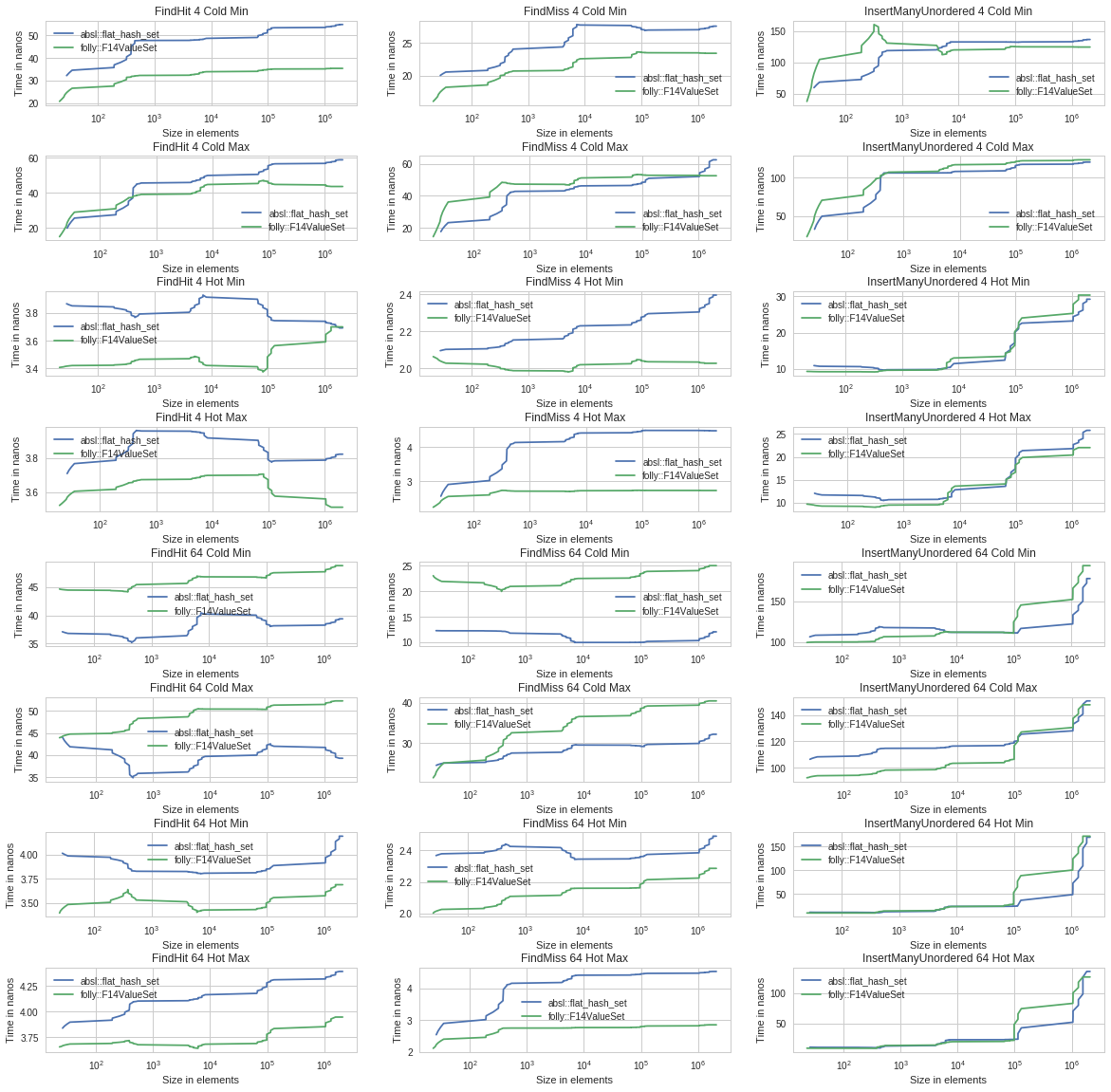
Now that absl::flat_hash_set has been released, I started to look at the relative performance of flat_hash_set vs F14ValueSet.
I tweaked the graphing utilities a bit and am using the data that Nathan submitted when he added support for flat_hash_set.
Below is a table of charts in a digestible fashion. The high level statement I can make from these graphs is that F14 appears faster than SwissTable for most cases. SwissTable wins for large cold payloads. There are a few other lesser uses cases (like iterating) that SwissTable tends to outperform, but on bulk F14 is a clear winner.
Fortunately, this is not a zero sum game and now we all have the chance to look at techniques the others have used and improve everything further.
Cheers,
Matt

Nathan Bronson
Oct 1, 2018, 2:00:43 PM10/1/18
to Matt Kulukundis, hashtable-...@googlegroups.com
Matt,
These initial results are very interesting. I don't think they are conclusive one way or the other. In particular I'm interested in results from hardware running at higher CPU frequencies; this server was only 2.4Ghz. It is also using gcc 5.x, I'd like to see if gcc 8 or clang make a difference.
Here's a stab at explaining some of the differences:
* I think F14 is better at FindMiss Hot because it doesn't need to use a second vector-wide test to exit the loop on match failure. F14 materializes the number of keys that have been displaced into a byte that will already be in the L1, so testing that it is zero is less work than computing group.MatchEmpty().
* flat_hash_set is better than F14ValueSet for 64 byte Cold because the latter's strategy of intermixing the H2 metadata and the data hurts locality for larger values (as well as leading to sub-optimal alignment for the values).
* intermixing the metadata and data is a win or neutral, however, for 4 byte values. In that case F14 fits metadata and 12 slots into a 64-byte cache line.
Internally very little code uses F14Value directly, we recommend that people use F14FastMap or F14FastSet. That type then forwards to F14Value for small value_type-s (sizeof(value_type) < 24) or F14Vector for larger entries. Rehash and destruction are faster with F14Vector, and when sizeof(value_type) >= 40 it also uses less memory, but this benchmark makes it seem like that might not be a good tradeoff (F14Vector FindHit is slower than F14Value even for 64 byte values). When I get some time I will experiment with increasing the threshold, or perhaps trying to take into account whether the underlying types are trivial.
I'm running the benchmark with some more value sizes > 4 but < 64 now.
Thanks for open-sourcing SwissTable, it's been a real pleasure to read the code (not done yet). I expect flat_hash_map and flat_hash_set to be widely adopted.
- Nathan
These initial results are very interesting. I don't think they are conclusive one way or the other. In particular I'm interested in results from hardware running at higher CPU frequencies; this server was only 2.4Ghz. It is also using gcc 5.x, I'd like to see if gcc 8 or clang make a difference.
Here's a stab at explaining some of the differences:
* I think F14 is better at FindMiss Hot because it doesn't need to use a second vector-wide test to exit the loop on match failure. F14 materializes the number of keys that have been displaced into a byte that will already be in the L1, so testing that it is zero is less work than computing group.MatchEmpty().
* flat_hash_set is better than F14ValueSet for 64 byte Cold because the latter's strategy of intermixing the H2 metadata and the data hurts locality for larger values (as well as leading to sub-optimal alignment for the values).
* intermixing the metadata and data is a win or neutral, however, for 4 byte values. In that case F14 fits metadata and 12 slots into a 64-byte cache line.
Internally very little code uses F14Value directly, we recommend that people use F14FastMap or F14FastSet. That type then forwards to F14Value for small value_type-s (sizeof(value_type) < 24) or F14Vector for larger entries. Rehash and destruction are faster with F14Vector, and when sizeof(value_type) >= 40 it also uses less memory, but this benchmark makes it seem like that might not be a good tradeoff (F14Vector FindHit is slower than F14Value even for 64 byte values). When I get some time I will experiment with increasing the threshold, or perhaps trying to take into account whether the underlying types are trivial.
I'm running the benchmark with some more value sizes > 4 but < 64 now.
Thanks for open-sourcing SwissTable, it's been a real pleasure to read the code (not done yet). I expect flat_hash_map and flat_hash_set to be widely adopted.
- Nathan
--
You received this message because you are subscribed to the Google Groups "hashtable-benchmarks" group.
To unsubscribe from this group and stop receiving emails from it, send an email to hashtable-benchm...@googlegroups.com.
To post to this group, send email to hashtable-...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CAApERuYUrqA667-BjtVSoUfK6f7ya9nUbe_Vsc8FAQeZV84CwQ%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
Nathan Grasso Bronson
ngbr...@gmail.com
ngbr...@gmail.com
Nathan Bronson
Oct 2, 2018, 9:31:54 AM10/2/18
to Matt Kulukundis, hashtable-...@googlegroups.com
Heads up that the existing benchmark (and committed results) are biased. F14 is getting a bonus on ColdMiss because the benchmark's Hash functor puts bit that separates RandomExistent from RandomNonexistent in the F14 tag (the H2 value), so the vector filtering stage is perfect. F14 gets a penalty on other scenarios because the tag has one fewer bit of real entropy, which doubles the false positive rate of the filtering. I'll fix and rerun.
- Nathan
- Nathan
Nathan Bronson
Oct 2, 2018, 9:34:29 AM10/2/18
to Matt Kulukundis, hashtable-...@googlegroups.com
There's actually two ways to fix it, and I'm interested in this group's opinion. One option is to adjust the Hash functor but try to keep it as minimal as possible. The other option is to use the per-implementation default hasher for uint32_t, which will perform the necessary bit mixing.
Matthew Fowles Kulukundis
Oct 2, 2018, 9:40:31 AM10/2/18
to Nathan Bronson, hashtable-...@googlegroups.com
Nathan~
Historically, we have avoided doing the per-implementation default hasher because we wanted to get a good feel for how the table itself handles things algorithmically. That may create a blind-spot for us though, so it might be worth experimenting with both options.
Cheers,
Matt
Matthew Fowles Kulukundis
Oct 3, 2018, 9:58:34 AM10/3/18
to Nathan Bronson, hashtable-...@googlegroups.com
All~
Nathan spotted an issue in the benchmarks reserved bits conflicting with special bits for F14[1].
The updated performance is still broadly similar.[2] But I figured it is worth mentioning to anyone else playing along at home.
Cheers,
Matt
[2]:
Nathan Bronson
Oct 3, 2018, 3:28:03 PM10/3/18
to Matt Kulukundis, hashtable-...@googlegroups.com
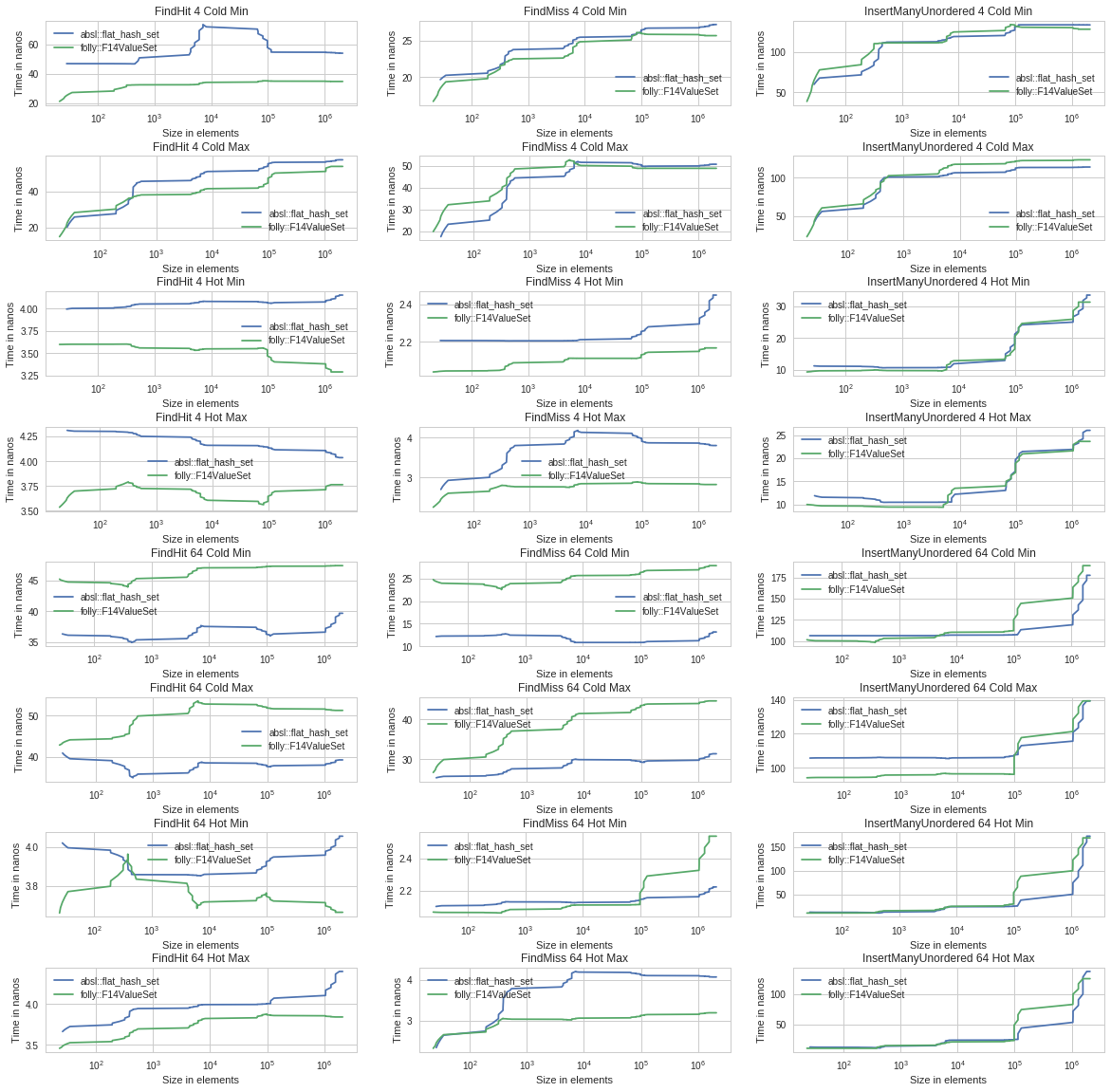
From a performance perspective the main design difference between SwissTable and F14 is whether the metadata and data are separated (as in SwissTable) or colocated (as in F14). I would expect colocation to work better when the entries are small, and separation to work better the elements are large. F14 also pushes users toward a third storage strategy, F14VectorSet, for medium and large values. This stores elements in a contiguous array and puts a 4-byte index into the main hash table, which makes lookup slower but iteration (and hence destruction) faster. This indirect strategy also saves memory, because the vector effectively has a perfect load factor.
To see how the tradeoffs change with the size of the item, I expanded the figure so that each row shows a single configuration at 5 different value sizes. I've also separated out the Hot case from the Cold case. To help make small relative differences look small I have included the origin on the y axis.
If I was going to try to drop absl::flat_hash_map/set into a program already using F14FastMap/Set, the most likely blocker would be the memory overhead of small hash tables.
Both SwissTable and F14 have more variation between Min and Max load factor than I expected. Perhaps we should revisit the design choice of using a fixed max_load_factor?
- Nathan
To see how the tradeoffs change with the size of the item, I expanded the figure so that each row shows a single configuration at 5 different value sizes. I've also separated out the Hot case from the Cold case. To help make small relative differences look small I have included the origin on the y axis.
- The FindHit Cold rows show that F14Vector is always the slowest (because of its indirection), that F14Value is the fastest for small values (because the tag/H2 values are in the same cache line or cache line pair as the values), and that flat_hash_set is the fastest for large values. The tradeoff between F14Value and flat_hash_set changes smoothly across value sizes, a surprisingly clean result.
- FindMiss Cold shows that separated metadata is better, which is also not surprising since most FindMiss calls only need to access the metadata. In fact, for the larger value sizes the entire flat_hash_set ctrl_ array fits in the L3. flat_hash_set's quadratic probing might also help locality in this case. F14 uses double-hashing, which reduces both clumping (good) and probe locality (bad).
- Iterate Cold shows that F14Vector's contiguously-packed elements allow much faster iteration, as expected. This helps destruction (and copy construction) performance.
- The Hot results show that the tables are all quite close to each other in performance.
- FindHit Hot shows a 1 or 2 cycle advantage for F14Value. I don't know if this is because it executes fewer instructions, because it achieves higher IPC, or if this result would go away with a stateless equality functor.
- flat_hash_set for FindMiss Hot seems to get a bit of a slowdown with Max load factor. My guess is that this is because quadratic probing leads to longer probe lengths than double hashing. Also, flat_hash_set needs to probe when a chunk is full but hasn't actually overflowed, whereas F14 only probes if a live (non-erased) key was actually displaced.
If I was going to try to drop absl::flat_hash_map/set into a program already using F14FastMap/Set, the most likely blocker would be the memory overhead of small hash tables.
Both SwissTable and F14 have more variation between Min and Max load factor than I expected. Perhaps we should revisit the design choice of using a fixed max_load_factor?
- Nathan
To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CAApERuaAz7Fby9xZ%3DP5Lm73tnokBcBQL4KiTC6vB0UezxGW9nw%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.

Samuel Benzaquen
Oct 3, 2018, 5:23:01 PM10/3/18
to Nathan Bronson, Matt Kulukundis, hashtable-...@googlegroups.com
On Wed, Oct 3, 2018 at 3:28 PM Nathan Bronson <ngbr...@gmail.com> wrote:
From a performance perspective the main design difference between SwissTable and F14 is whether the metadata and data are separated (as in SwissTable) or colocated (as in F14). I would expect colocation to work better when the entries are small, and separation to work better the elements are large. F14 also pushes users toward a third storage strategy, F14VectorSet, for medium and large values. This stores elements in a contiguous array and puts a 4-byte index into the main hash table, which makes lookup slower but iteration (and hence destruction) faster. This indirect strategy also saves memory, because the vector effectively has a perfect load factor.
To see how the tradeoffs change with the size of the item, I expanded the figure so that each row shows a single configuration at 5 different value sizes. I've also separated out the Hot case from the Cold case. To help make small relative differences look small I have included the origin on the y axis.
- The FindHit Cold rows show that F14Vector is always the slowest (because of its indirection), that F14Value is the fastest for small values (because the tag/H2 values are in the same cache line or cache line pair as the values), and that flat_hash_set is the fastest for large values. The tradeoff between F14Value and flat_hash_set changes smoothly across value sizes, a surprisingly clean result.
- FindMiss Cold shows that separated metadata is better, which is also not surprising since most FindMiss calls only need to access the metadata. In fact, for the larger value sizes the entire flat_hash_set ctrl_ array fits in the L3. flat_hash_set's quadratic probing might also help locality in this case. F14 uses double-hashing, which reduces both clumping (good) and probe locality (bad).
We can actually experiment with this. That is, we could easily test flat_hash_set with double-hashing. Making F14 try quadratic probing should not be hard also, though I don't know the code enough to know.
Double-hashing does lead to smaller code size, which might just mean that it is faster in some cases because it is less code to run.
To me these benchmark results show that you'd need to know a lot about the operation profile and working set of a program to predict whether SwissTable or F14 would be faster. For example, if you take a lot of cache misses reading from tables with large entries then flat_hash_set is clearly best, but if you construct and destroy those tables a lot then F14Vector seems like the most compelling.
- Iterate Cold shows that F14Vector's contiguously-packed elements allow much faster iteration, as expected. This helps destruction (and copy construction) performance.
- The Hot results show that the tables are all quite close to each other in performance.
- FindHit Hot shows a 1 or 2 cycle advantage for F14Value. I don't know if this is because it executes fewer instructions, because it achieves higher IPC, or if this result would go away with a stateless equality functor.
- flat_hash_set for FindMiss Hot seems to get a bit of a slowdown with Max load factor. My guess is that this is because quadratic probing leads to longer probe lengths than double hashing. Also, flat_hash_set needs to probe when a chunk is full but hasn't actually overflowed, whereas F14 only probes if a live (non-erased) key was actually displaced.
If I was going to try to drop absl::flat_hash_map/set into a program already using F14FastMap/Set, the most likely blocker would be the memory overhead of small hash tables.
Funny that you mention this. We are considering a change that reduces the minimum capacity to 3 without impacting the find/insert code paths, only the reallocation.
Both SwissTable and F14 have more variation between Min and Max load factor than I expected. Perhaps we should revisit the design choice of using a fixed max_load_factor?
Note that they use a different max load factor. F14 uses 12/14, while flat_hash_set uses 14/16, so there is that too.
To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CALo6A%2Bso6ZkjwEm%3DzxdQH482EDzgcikJvRYdYAgD1aipvCQGDg%40mail.gmail.com.
Nathan Bronson
Oct 3, 2018, 6:03:41 PM10/3/18
to Samuel Benzaquen, Matt Kulukundis, hashtable-...@googlegroups.com
On Wed, Oct 3, 2018 at 5:23 PM Samuel Benzaquen <sbe...@google.com> wrote:
On Wed, Oct 3, 2018 at 3:28 PM Nathan Bronson <ngbr...@gmail.com> wrote:From a performance perspective the main design difference between SwissTable and F14 is whether the metadata and data are separated (as in SwissTable) or colocated (as in F14). I would expect colocation to work better when the entries are small, and separation to work better the elements are large. F14 also pushes users toward a third storage strategy, F14VectorSet, for medium and large values. This stores elements in a contiguous array and puts a 4-byte index into the main hash table, which makes lookup slower but iteration (and hence destruction) faster. This indirect strategy also saves memory, because the vector effectively has a perfect load factor.
To see how the tradeoffs change with the size of the item, I expanded the figure so that each row shows a single configuration at 5 different value sizes. I've also separated out the Hot case from the Cold case. To help make small relative differences look small I have included the origin on the y axis.
- The FindHit Cold rows show that F14Vector is always the slowest (because of its indirection), that F14Value is the fastest for small values (because the tag/H2 values are in the same cache line or cache line pair as the values), and that flat_hash_set is the fastest for large values. The tradeoff between F14Value and flat_hash_set changes smoothly across value sizes, a surprisingly clean result.
- FindMiss Cold shows that separated metadata is better, which is also not surprising since most FindMiss calls only need to access the metadata. In fact, for the larger value sizes the entire flat_hash_set ctrl_ array fits in the L3. flat_hash_set's quadratic probing might also help locality in this case. F14 uses double-hashing, which reduces both clumping (good) and probe locality (bad).
We can actually experiment with this. That is, we could easily test flat_hash_set with double-hashing. Making F14 try quadratic probing should not be hard also, though I don't know the code enough to know.Double-hashing does lead to smaller code size, which might just mean that it is faster in some cases because it is less code to run.
I don't think double-hashing saves code size, since we need an iteration counter anyway to avoid a rare infinite loop. That means double-hashing occupies two registers in the core loop rather than one (assuming you do the multiply instead of doing power reduction). It should be trivial to try quadratic probing in F14 once I get some more free cycles.
To me these benchmark results show that you'd need to know a lot about the operation profile and working set of a program to predict whether SwissTable or F14 would be faster. For example, if you take a lot of cache misses reading from tables with large entries then flat_hash_set is clearly best, but if you construct and destroy those tables a lot then F14Vector seems like the most compelling.
- Iterate Cold shows that F14Vector's contiguously-packed elements allow much faster iteration, as expected. This helps destruction (and copy construction) performance.
- The Hot results show that the tables are all quite close to each other in performance.
- FindHit Hot shows a 1 or 2 cycle advantage for F14Value. I don't know if this is because it executes fewer instructions, because it achieves higher IPC, or if this result would go away with a stateless equality functor.
- flat_hash_set for FindMiss Hot seems to get a bit of a slowdown with Max load factor. My guess is that this is because quadratic probing leads to longer probe lengths than double hashing. Also, flat_hash_set needs to probe when a chunk is full but hasn't actually overflowed, whereas F14 only probes if a live (non-erased) key was actually displaced.
If I was going to try to drop absl::flat_hash_map/set into a program already using F14FastMap/Set, the most likely blocker would be the memory overhead of small hash tables.Funny that you mention this. We are considering a change that reduces the minimum capacity to 3 without impacting the find/insert code paths, only the reallocation.
Nice, it should be quite easy given that you materialize the number of insertions before resize. How did you pick 3? Hmm, another followup for me. It should be possible to pick an initial capacity with minimal internal fragmentation from the allocator. For example if sizeof(value_type) was 4 or 8 then an initial capacity of 4 will actually reserve the same amount of memory as 3 due to 16 byte alignment. If you have good knowledge of the allocation classes it might work to squeeze out a free item for other sizes as well.
Both SwissTable and F14 have more variation between Min and Max load factor than I expected. Perhaps we should revisit the design choice of using a fixed max_load_factor?Note that they use a different max load factor. F14 uses 12/14, while flat_hash_set uses 14/16, so there is that too.
Yes, although that's only a 2% difference. Also, when storing 4-byte items (including the vector indexes for F14Vector) F14 actually uses a chunk size of 12 and a max load factor of 10/12, to make a chunk fit exactly in one cache line.
It's outside the scope of benchmarking, but is there somebody with whom I could follow up on regarding the correctness of the slot_type union in absl/container/internal/container_memory.h ? We faced a similar problem and concluded that it required relying on undefined behavior (which we have attempted to quarantine with std::launder).
- Nathan
...snip...
Matthew Fowles Kulukundis
Oct 3, 2018, 6:39:08 PM10/3/18
to Nathan Bronson, abse...@googlegroups.com, Samuel Benzaquen
Nathan~
Switching the correctness discussion to Abseil's mailing list since that is where it belongs.
Switching the correctness discussion to Abseil's mailing list since that is where it belongs.
I think that the set of checks in IsLayoutCompatible are sufficient to guarantee correctness, but I am not the language expert on our team.
Cheers,
Matt
--
You received this message because you are subscribed to the Google Groups "hashtable-benchmarks" group.
To unsubscribe from this group and stop receiving emails from it, send an email to hashtable-benchm...@googlegroups.com.
To post to this group, send email to hashtable-...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CALo6A%2BvnycaRN-w997XsNgxJp3U8gtAfYTvkmUQ3Unow7te_MQ%40mail.gmail.com.
Samuel Benzaquen
Oct 4, 2018, 11:15:05 AM10/4/18
to Nathan Bronson, Matt Kulukundis, hashtable-...@googlegroups.com
On Wed, Oct 3, 2018 at 6:03 PM Nathan Bronson <ngbr...@gmail.com> wrote:
On Wed, Oct 3, 2018 at 5:23 PM Samuel Benzaquen <sbe...@google.com> wrote:On Wed, Oct 3, 2018 at 3:28 PM Nathan Bronson <ngbr...@gmail.com> wrote:From a performance perspective the main design difference between SwissTable and F14 is whether the metadata and data are separated (as in SwissTable) or colocated (as in F14). I would expect colocation to work better when the entries are small, and separation to work better the elements are large. F14 also pushes users toward a third storage strategy, F14VectorSet, for medium and large values. This stores elements in a contiguous array and puts a 4-byte index into the main hash table, which makes lookup slower but iteration (and hence destruction) faster. This indirect strategy also saves memory, because the vector effectively has a perfect load factor.
To see how the tradeoffs change with the size of the item, I expanded the figure so that each row shows a single configuration at 5 different value sizes. I've also separated out the Hot case from the Cold case. To help make small relative differences look small I have included the origin on the y axis.
- The FindHit Cold rows show that F14Vector is always the slowest (because of its indirection), that F14Value is the fastest for small values (because the tag/H2 values are in the same cache line or cache line pair as the values), and that flat_hash_set is the fastest for large values. The tradeoff between F14Value and flat_hash_set changes smoothly across value sizes, a surprisingly clean result.
- FindMiss Cold shows that separated metadata is better, which is also not surprising since most FindMiss calls only need to access the metadata. In fact, for the larger value sizes the entire flat_hash_set ctrl_ array fits in the L3. flat_hash_set's quadratic probing might also help locality in this case. F14 uses double-hashing, which reduces both clumping (good) and probe locality (bad).
We can actually experiment with this. That is, we could easily test flat_hash_set with double-hashing. Making F14 try quadratic probing should not be hard also, though I don't know the code enough to know.Double-hashing does lead to smaller code size, which might just mean that it is faster in some cases because it is less code to run.I don't think double-hashing saves code size, since we need an iteration counter anyway to avoid a rare infinite loop.
Oh. It did in my case because we don't use the iteration counter for anything else other than quadratic probing.
That means double-hashing occupies two registers in the core loop rather than one (assuming you do the multiply instead of doing power reduction). It should be trivial to try quadratic probing in F14 once I get some more free cycles.To me these benchmark results show that you'd need to know a lot about the operation profile and working set of a program to predict whether SwissTable or F14 would be faster. For example, if you take a lot of cache misses reading from tables with large entries then flat_hash_set is clearly best, but if you construct and destroy those tables a lot then F14Vector seems like the most compelling.
- Iterate Cold shows that F14Vector's contiguously-packed elements allow much faster iteration, as expected. This helps destruction (and copy construction) performance.
- The Hot results show that the tables are all quite close to each other in performance.
- FindHit Hot shows a 1 or 2 cycle advantage for F14Value. I don't know if this is because it executes fewer instructions, because it achieves higher IPC, or if this result would go away with a stateless equality functor.
- flat_hash_set for FindMiss Hot seems to get a bit of a slowdown with Max load factor. My guess is that this is because quadratic probing leads to longer probe lengths than double hashing. Also, flat_hash_set needs to probe when a chunk is full but hasn't actually overflowed, whereas F14 only probes if a live (non-erased) key was actually displaced.
If I was going to try to drop absl::flat_hash_map/set into a program already using F14FastMap/Set, the most likely blocker would be the memory overhead of small hash tables.Funny that you mention this. We are considering a change that reduces the minimum capacity to 3 without impacting the find/insert code paths, only the reallocation.Nice, it should be quite easy given that you materialize the number of insertions before resize. How did you pick 3?
Our capacity has to be a power-of-two-minus-one right now.
And our find/insert algorithm assumes there is at least one empty slot in the table.
This means that a capacity of 1 would not actually allow any object in it.
A capacity of 3 would allow 2 elements in.
This thread actually made me think about this problem a little more and I think we can forgo the empty slot requirement for very small tables, which would make capacity of 1 feasible and allow a max load factor of 1.0 these small tables.
Hmm, another followup for me. It should be possible to pick an initial capacity with minimal internal fragmentation from the allocator. For example if sizeof(value_type) was 4 or 8 then an initial capacity of 4 will actually reserve the same amount of memory as 3 due to 16 byte alignment.
we don't have a 16 byte alignment requirement on the data.
The memory usage right now is (capacity + 1) * sizeof(value_type) + 16. The 16 comes from sentinel control bytes we add at the end of the control block. This allows for unaligned queries on find and iterator's operator++. Having floating groups reduced the average probe chain length by distributing the elements more uniformly.
With the proposed change we would still have those 16 bytes, though. So a capacity of 3 would use 4*sizeof(value_type)+16. It is not very useful for `int`, but can save a lot of memory for larger types.
We could push it to get a minimum allocation of 16 bytes, but might require some clever tricks to add the special small-table logic without affecting regular probing.
Nathan Bronson
Oct 4, 2018, 3:54:01 PM10/4/18
to Samuel Benzaquen, Matt Kulukundis, hashtable-...@googlegroups.com
On Thu, Oct 4, 2018 at 11:15 AM 'Samuel Benzaquen' via hashtable-benchmarks <hashtable-...@googlegroups.com> wrote:
On Wed, Oct 3, 2018 at 6:03 PM Nathan Bronson <ngbr...@gmail.com> wrote:On Wed, Oct 3, 2018 at 5:23 PM Samuel Benzaquen <sbe...@google.com> wrote:On Wed, Oct 3, 2018 at 3:28 PM Nathan Bronson <ngbr...@gmail.com> wrote:From a performance perspective the main design difference between SwissTable and F14 is whether the metadata and data are separated (as in SwissTable) or colocated (as in F14). I would expect colocation to work better when the entries are small, and separation to work better the elements are large. F14 also pushes users toward a third storage strategy, F14VectorSet, for medium and large values. This stores elements in a contiguous array and puts a 4-byte index into the main hash table, which makes lookup slower but iteration (and hence destruction) faster. This indirect strategy also saves memory, because the vector effectively has a perfect load factor.
To see how the tradeoffs change with the size of the item, I expanded the figure so that each row shows a single configuration at 5 different value sizes. I've also separated out the Hot case from the Cold case. To help make small relative differences look small I have included the origin on the y axis.
- The FindHit Cold rows show that F14Vector is always the slowest (because of its indirection), that F14Value is the fastest for small values (because the tag/H2 values are in the same cache line or cache line pair as the values), and that flat_hash_set is the fastest for large values. The tradeoff between F14Value and flat_hash_set changes smoothly across value sizes, a surprisingly clean result.
- FindMiss Cold shows that separated metadata is better, which is also not surprising since most FindMiss calls only need to access the metadata. In fact, for the larger value sizes the entire flat_hash_set ctrl_ array fits in the L3. flat_hash_set's quadratic probing might also help locality in this case. F14 uses double-hashing, which reduces both clumping (good) and probe locality (bad).
We can actually experiment with this. That is, we could easily test flat_hash_set with double-hashing. Making F14 try quadratic probing should not be hard also, though I don't know the code enough to know.Double-hashing does lead to smaller code size, which might just mean that it is faster in some cases because it is less code to run.I don't think double-hashing saves code size, since we need an iteration counter anyway to avoid a rare infinite loop.Oh. It did in my case because we don't use the iteration counter for anything else other than quadratic probing.
That's because you always keep at least 1 empty slot, right?
That means double-hashing occupies two registers in the core loop rather than one (assuming you do the multiply instead of doing power reduction). It should be trivial to try quadratic probing in F14 once I get some more free cycles.To me these benchmark results show that you'd need to know a lot about the operation profile and working set of a program to predict whether SwissTable or F14 would be faster. For example, if you take a lot of cache misses reading from tables with large entries then flat_hash_set is clearly best, but if you construct and destroy those tables a lot then F14Vector seems like the most compelling.
- Iterate Cold shows that F14Vector's contiguously-packed elements allow much faster iteration, as expected. This helps destruction (and copy construction) performance.
- The Hot results show that the tables are all quite close to each other in performance.
- FindHit Hot shows a 1 or 2 cycle advantage for F14Value. I don't know if this is because it executes fewer instructions, because it achieves higher IPC, or if this result would go away with a stateless equality functor.
- flat_hash_set for FindMiss Hot seems to get a bit of a slowdown with Max load factor. My guess is that this is because quadratic probing leads to longer probe lengths than double hashing. Also, flat_hash_set needs to probe when a chunk is full but hasn't actually overflowed, whereas F14 only probes if a live (non-erased) key was actually displaced.
If I was going to try to drop absl::flat_hash_map/set into a program already using F14FastMap/Set, the most likely blocker would be the memory overhead of small hash tables.Funny that you mention this. We are considering a change that reduces the minimum capacity to 3 without impacting the find/insert code paths, only the reallocation.Nice, it should be quite easy given that you materialize the number of insertions before resize. How did you pick 3?Our capacity has to be a power-of-two-minus-one right now.And our find/insert algorithm assumes there is at least one empty slot in the table.This means that a capacity of 1 would not actually allow any object in it.A capacity of 3 would allow 2 elements in.
That makes sense. Floating groups are very nice, but they mean that you might have a hole in the elements even in a very small map. Fixed groups would let you guarantee that if there was only a single group the elements were all packed into the bottom. If you could map all hash values to index 0 when the capacity was <= 1 group (and disable the debug end-of-group insert) then you could do any sub-group size exactly while retaining floating groups for the case when they matter.
This thread actually made me think about this problem a little more and I think we can forgo the empty slot requirement for very small tables, which would make capacity of 1 feasible and allow a max load factor of 1.0 these small tables.Hmm, another followup for me. It should be possible to pick an initial capacity with minimal internal fragmentation from the allocator. For example if sizeof(value_type) was 4 or 8 then an initial capacity of 4 will actually reserve the same amount of memory as 3 due to 16 byte alignment.we don't have a 16 byte alignment requirement on the data.The memory usage right now is (capacity + 1) * sizeof(value_type) + 16. The 16 comes from sentinel control bytes we add at the end of the control block. This allows for unaligned queries on find and iterator's operator++. Having floating groups reduced the average probe chain length by distributing the elements more uniformly.With the proposed change we would still have those 16 bytes, though. So a capacity of 3 would use 4*sizeof(value_type)+16. It is not very useful for `int`, but can save a lot of memory for larger types.
16 byte alignment is a restriction on malloc, and comes from alignof(std::max_align_t). malloc doesn't know about the type that you are going to put in allocated memory, so it has to give you max_align_t-aligned memory. We use jemalloc, so the underlying allocation sizes are 8, 16, 32, 48, {64, 80, 96, 112} * {1, 2, 3, ...}.
We could push it to get a minimum allocation of 16 bytes, but might require some clever tricks to add the special small-table logic without affecting regular probing.If you have good knowledge of the allocation classes it might work to squeeze out a free item for other sizes as well.Both SwissTable and F14 have more variation between Min and Max load factor than I expected. Perhaps we should revisit the design choice of using a fixed max_load_factor?Note that they use a different max load factor. F14 uses 12/14, while flat_hash_set uses 14/16, so there is that too.Yes, although that's only a 2% difference. Also, when storing 4-byte items (including the vector indexes for F14Vector) F14 actually uses a chunk size of 12 and a max load factor of 10/12, to make a chunk fit exactly in one cache line.
It's outside the scope of benchmarking, but is there somebody with whom I could follow up on regarding the correctness of the slot_type union in absl/container/internal/container_memory.h ? We faced a similar problem and concluded that it required relying on undefined behavior (which we have attempted to quarantine with std::launder).- Nathan
...snip...
--
You received this message because you are subscribed to the Google Groups "hashtable-benchmarks" group.
To unsubscribe from this group and stop receiving emails from it, send an email to hashtable-benchm...@googlegroups.com.
To post to this group, send email to hashtable-...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CAM9aRsJFSkKfpASfHicsFzd07oTGBE9Lk0qfk8PRhfMEHGJxQA%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
Samuel Benzaquen
Oct 5, 2018, 11:14:02 AM10/5/18
to Nathan Bronson, Matt Kulukundis, hashtable-...@googlegroups.com
On Thu, Oct 4, 2018 at 3:54 PM Nathan Bronson <ngbr...@gmail.com> wrote:
On Thu, Oct 4, 2018 at 11:15 AM 'Samuel Benzaquen' via hashtable-benchmarks <hashtable-...@googlegroups.com> wrote:On Wed, Oct 3, 2018 at 6:03 PM Nathan Bronson <ngbr...@gmail.com> wrote:On Wed, Oct 3, 2018 at 5:23 PM Samuel Benzaquen <sbe...@google.com> wrote:On Wed, Oct 3, 2018 at 3:28 PM Nathan Bronson <ngbr...@gmail.com> wrote:From a performance perspective the main design difference between SwissTable and F14 is whether the metadata and data are separated (as in SwissTable) or colocated (as in F14). I would expect colocation to work better when the entries are small, and separation to work better the elements are large. F14 also pushes users toward a third storage strategy, F14VectorSet, for medium and large values. This stores elements in a contiguous array and puts a 4-byte index into the main hash table, which makes lookup slower but iteration (and hence destruction) faster. This indirect strategy also saves memory, because the vector effectively has a perfect load factor.
To see how the tradeoffs change with the size of the item, I expanded the figure so that each row shows a single configuration at 5 different value sizes. I've also separated out the Hot case from the Cold case. To help make small relative differences look small I have included the origin on the y axis.
- The FindHit Cold rows show that F14Vector is always the slowest (because of its indirection), that F14Value is the fastest for small values (because the tag/H2 values are in the same cache line or cache line pair as the values), and that flat_hash_set is the fastest for large values. The tradeoff between F14Value and flat_hash_set changes smoothly across value sizes, a surprisingly clean result.
- FindMiss Cold shows that separated metadata is better, which is also not surprising since most FindMiss calls only need to access the metadata. In fact, for the larger value sizes the entire flat_hash_set ctrl_ array fits in the L3. flat_hash_set's quadratic probing might also help locality in this case. F14 uses double-hashing, which reduces both clumping (good) and probe locality (bad).
We can actually experiment with this. That is, we could easily test flat_hash_set with double-hashing. Making F14 try quadratic probing should not be hard also, though I don't know the code enough to know.Double-hashing does lead to smaller code size, which might just mean that it is faster in some cases because it is less code to run.I don't think double-hashing saves code size, since we need an iteration counter anyway to avoid a rare infinite loop.Oh. It did in my case because we don't use the iteration counter for anything else other than quadratic probing.That's because you always keep at least 1 empty slot, right?
Yes. We only stop at empty slots.
That means double-hashing occupies two registers in the core loop rather than one (assuming you do the multiply instead of doing power reduction). It should be trivial to try quadratic probing in F14 once I get some more free cycles.To me these benchmark results show that you'd need to know a lot about the operation profile and working set of a program to predict whether SwissTable or F14 would be faster. For example, if you take a lot of cache misses reading from tables with large entries then flat_hash_set is clearly best, but if you construct and destroy those tables a lot then F14Vector seems like the most compelling.
- Iterate Cold shows that F14Vector's contiguously-packed elements allow much faster iteration, as expected. This helps destruction (and copy construction) performance.
- The Hot results show that the tables are all quite close to each other in performance.
- FindHit Hot shows a 1 or 2 cycle advantage for F14Value. I don't know if this is because it executes fewer instructions, because it achieves higher IPC, or if this result would go away with a stateless equality functor.
- flat_hash_set for FindMiss Hot seems to get a bit of a slowdown with Max load factor. My guess is that this is because quadratic probing leads to longer probe lengths than double hashing. Also, flat_hash_set needs to probe when a chunk is full but hasn't actually overflowed, whereas F14 only probes if a live (non-erased) key was actually displaced.
If I was going to try to drop absl::flat_hash_map/set into a program already using F14FastMap/Set, the most likely blocker would be the memory overhead of small hash tables.Funny that you mention this. We are considering a change that reduces the minimum capacity to 3 without impacting the find/insert code paths, only the reallocation.Nice, it should be quite easy given that you materialize the number of insertions before resize. How did you pick 3?Our capacity has to be a power-of-two-minus-one right now.And our find/insert algorithm assumes there is at least one empty slot in the table.This means that a capacity of 1 would not actually allow any object in it.A capacity of 3 would allow 2 elements in.That makes sense. Floating groups are very nice, but they mean that you might have a hole in the elements even in a very small map. Fixed groups would let you guarantee that if there was only a single group the elements were all packed into the bottom.
This was actually a feature because it allowed us to cheaply have non-deterministic iteration order.
This has been a huge thing in the migration to flat_hash_*, as it opens the door for changing the implementation details without breaking users.
Before floating groups we had deterministic order of iteration in 1 group tables, and that was enough to have code depend on it.
If you could map all hash values to index 0 when the capacity was <= 1 group (and disable the debug end-of-group insert) then you could do any sub-group size exactly while retaining floating groups for the case when they matter.
The 16 extra control bytes for floating groups actually also help with the iterator implementation.
The iterator does SSE lookups to find the next element on operator++, but that requires a 16-byte read at arbitrary positions in the control block.
Before floating groups we were overflowing the control block and reading some of the payload bytes. It theoretically doesn't affect program logic because we never actually used the payload bytes there. We would always find and stop at the sentinel control byte.
However, the payload bytes can be uninitialized memory which is UB and this was continuously triggering Memory Sanitizer.
One solution we tried is to explicitly initialize the first 16 bytes of the payload block to zeros to avoid the UB, but this doesn't really work when you have user-defined payload types. The common source of MSan reports were user-defined types with padding. MSan considered those padding bytes to be uninitialized after the constructor of those objects ran. We didn't have any control over those bytes after we constructed the object.
If we are willing to have specialized implementations, we could go to a more compact layout for small tables of types we know are safe, like fundamental types. Overflowing the control block there would be fine if we ensure it is not uninitialized to begin with. I don't know if specializing for fundamental types is worth it as it is extra complexity, but they are very common and are also the types that would mostly benefit from a compact control block representation.
Having an overhead of 16 bytes for a 1 element flat_hash_set<std::string> is not that much of a problem since the string itself is already large enough.
Having the overhead for a 1 element flat_hash_set<int> is more relevant.
This thread actually made me think about this problem a little more and I think we can forgo the empty slot requirement for very small tables, which would make capacity of 1 feasible and allow a max load factor of 1.0 these small tables.Hmm, another followup for me. It should be possible to pick an initial capacity with minimal internal fragmentation from the allocator. For example if sizeof(value_type) was 4 or 8 then an initial capacity of 4 will actually reserve the same amount of memory as 3 due to 16 byte alignment.we don't have a 16 byte alignment requirement on the data.The memory usage right now is (capacity + 1) * sizeof(value_type) + 16. The 16 comes from sentinel control bytes we add at the end of the control block. This allows for unaligned queries on find and iterator's operator++. Having floating groups reduced the average probe chain length by distributing the elements more uniformly.With the proposed change we would still have those 16 bytes, though. So a capacity of 3 would use 4*sizeof(value_type)+16. It is not very useful for `int`, but can save a lot of memory for larger types.16 byte alignment is a restriction on malloc, and comes from alignof(std::max_align_t). malloc doesn't know about the type that you are going to put in allocated memory, so it has to give you max_align_t-aligned memory. We use jemalloc, so the underlying allocation sizes are 8, 16, 32, 48, {64, 80, 96, 112} * {1, 2, 3, ...}.
Yes. malloc is discouraged here for this and other reasons, like not supporting sized deletes.
We prefer allocating memory through std::allocator. The alignment is limited to the requested object's alignment.
We use TCMalloc, as its preferred alignment is 8 bytes. Using malloc is significantly slower than std::allocator in these cases.
Nathan Bronson
Oct 5, 2018, 12:08:23 PM10/5/18
to Samuel Benzaquen, Matt Kulukundis, hashtable-...@googlegroups.com
Yes, we are planning to add this to F14. Presumably the non-allocated slots are marked as unavailable for allocation, so the randomization of insertion order should continue to work fine even if you do sub-group capacity.
If you could map all hash values to index 0 when the capacity was <= 1 group (and disable the debug end-of-group insert) then you could do any sub-group size exactly while retaining floating groups for the case when they matter.The 16 extra control bytes for floating groups actually also help with the iterator implementation.The iterator does SSE lookups to find the next element on operator++, but that requires a 16-byte read at arbitrary positions in the control block.Before floating groups we were overflowing the control block and reading some of the payload bytes. It theoretically doesn't affect program logic because we never actually used the payload bytes there. We would always find and stop at the sentinel control byte.However, the payload bytes can be uninitialized memory which is UB and this was continuously triggering Memory Sanitizer.One solution we tried is to explicitly initialize the first 16 bytes of the payload block to zeros to avoid the UB, but this doesn't really work when you have user-defined payload types. The common source of MSan reports were user-defined types with padding. MSan considered those padding bytes to be uninitialized after the constructor of those objects ran. We didn't have any control over those bytes after we constructed the object.If we are willing to have specialized implementations, we could go to a more compact layout for small tables of types we know are safe, like fundamental types. Overflowing the control block there would be fine if we ensure it is not uninitialized to begin with. I don't know if specializing for fundamental types is worth it as it is extra complexity, but they are very common and are also the types that would mostly benefit from a compact control block representation.Having an overhead of 16 bytes for a 1 element flat_hash_set<std::string> is not that much of a problem since the string itself is already large enough.Having the overhead for a 1 element flat_hash_set<int> is more relevant.This thread actually made me think about this problem a little more and I think we can forgo the empty slot requirement for very small tables, which would make capacity of 1 feasible and allow a max load factor of 1.0 these small tables.Hmm, another followup for me. It should be possible to pick an initial capacity with minimal internal fragmentation from the allocator. For example if sizeof(value_type) was 4 or 8 then an initial capacity of 4 will actually reserve the same amount of memory as 3 due to 16 byte alignment.we don't have a 16 byte alignment requirement on the data.The memory usage right now is (capacity + 1) * sizeof(value_type) + 16. The 16 comes from sentinel control bytes we add at the end of the control block. This allows for unaligned queries on find and iterator's operator++. Having floating groups reduced the average probe chain length by distributing the elements more uniformly.With the proposed change we would still have those 16 bytes, though. So a capacity of 3 would use 4*sizeof(value_type)+16. It is not very useful for `int`, but can save a lot of memory for larger types.16 byte alignment is a restriction on malloc, and comes from alignof(std::max_align_t). malloc doesn't know about the type that you are going to put in allocated memory, so it has to give you max_align_t-aligned memory. We use jemalloc, so the underlying allocation sizes are 8, 16, 32, 48, {64, 80, 96, 112} * {1, 2, 3, ...}.Yes. malloc is discouraged here for this and other reasons, like not supporting sized deletes.We prefer allocating memory through std::allocator. The alignment is limited to the requested object's alignment.We use TCMalloc, as its preferred alignment is 8 bytes. Using malloc is significantly slower than std::allocator in these cases.
I meant malloc in the general sense, which is typically invoked by std::allocator. We use jemalloc underneath. Do you plumb the alignment constraints through to TCMalloc from operator new? If you don't then it can't know whether the type being allocated has 8 or 16 byte alignment (assuming the allocation itself is >= 16 bytes), so it seems like it must be conservative and give you 16 byte alignment.
----We could push it to get a minimum allocation of 16 bytes, but might require some clever tricks to add the special small-table logic without affecting regular probing.If you have good knowledge of the allocation classes it might work to squeeze out a free item for other sizes as well.Both SwissTable and F14 have more variation between Min and Max load factor than I expected. Perhaps we should revisit the design choice of using a fixed max_load_factor?Note that they use a different max load factor. F14 uses 12/14, while flat_hash_set uses 14/16, so there is that too.Yes, although that's only a 2% difference. Also, when storing 4-byte items (including the vector indexes for F14Vector) F14 actually uses a chunk size of 12 and a max load factor of 10/12, to make a chunk fit exactly in one cache line.
It's outside the scope of benchmarking, but is there somebody with whom I could follow up on regarding the correctness of the slot_type union in absl/container/internal/container_memory.h ? We faced a similar problem and concluded that it required relying on undefined behavior (which we have attempted to quarantine with std::launder).- Nathan
...snip...
You received this message because you are subscribed to the Google Groups "hashtable-benchmarks" group.
To unsubscribe from this group and stop receiving emails from it, send an email to hashtable-benchm...@googlegroups.com.
To post to this group, send email to hashtable-...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CAM9aRsJFSkKfpASfHicsFzd07oTGBE9Lk0qfk8PRhfMEHGJxQA%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--Nathan Grasso Bronson
ngbr...@gmail.com
You received this message because you are subscribed to the Google Groups "hashtable-benchmarks" group.
To unsubscribe from this group and stop receiving emails from it, send an email to hashtable-benchm...@googlegroups.com.
To post to this group, send email to hashtable-...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CAM9aRsJrYnDhL%2Bpi_73jv1t_1jjaXBQrfPLpRsR4ih3cCFWV7g%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
Samuel Benzaquen
Oct 5, 2018, 12:27:43 PM10/5/18
to Nathan Bronson, Matt Kulukundis, hashtable-...@googlegroups.com
std::allocator does not use malloc. It calls `operator new` with the size and alignment.
We use jemalloc underneath. Do you plumb the alignment constraints through to TCMalloc from operator new?
Yes.
If you don't then it can't know whether the type being allocated has 8 or 16 byte alignment (assuming the allocation itself is >= 16 bytes), so it seems like it must be conservative and give you 16 byte alignment.
Yes. It used to be the case before `operator new` gained the alignment argument.
Nathan Bronson
Oct 5, 2018, 12:32:20 PM10/5/18
to Samuel Benzaquen, Matt Kulukundis, hashtable-...@googlegroups.com
Thanks for clarifying. This would be pretty nice for 24 byte allocations, which currently need to come from the 32 byte allocation class for us.
Samuel Benzaquen
Mar 13, 2019, 11:05:04 AM3/13/19
to Nathan Bronson, Matt Kulukundis, hashtable-...@googlegroups.com
I'd like to poke this dead thread to inform that flat_hash_map has been updated to support smaller capacities.
It now starts with a capacity of 1.
Any capacity smaller than Group::kWidth-1 uses the full capacity, so a capacity of 1/3/7 can hold 1/3/7 elements respectively.
A flat_hash_set<int> of 1 element now allocates 24 bytes instead of 96. A flat_hash_set<string> (assuming sizeof(string)==32) with one string will be 56 bytes instead of 512!
The floating window approach requires us to still have 16 extra control bytes, but these bytes actually help us use the full capacity because they will contain the "empty"s we need to stop the iteration.
This change actually also fulfills an unrelated user request: finding latent use-after-free bugs earlier.
We've had users report that they had latent bugs in their code where they were using pointers/references to objects that just happened to never be invalidated because their data had less than 15 elements. Once the data grew in production it triggered the rehash and caused UB.
With this change the 2th element inserted will cause a rehash (and so will the 4th and 8th), so users can detect these bugs earlier in testing.

Roman Perepelitsa
Mar 13, 2019, 11:12:07 AM3/13/19
to Samuel Benzaquen, Nathan Bronson, Matt Kulukundis, hashtable-benchmarks
Very nice!
On Wed, Mar 13, 2019 at 4:05 PM 'Samuel Benzaquen' via
> To view this discussion on the web visit https://groups.google.com/d/msgid/hashtable-benchmarks/CAM9aRs%2BoYgkHpXRppdE3f2quhku4MTMu1aB6oad91NA1J6UYfQ%40mail.gmail.com.
On Wed, Mar 13, 2019 at 4:05 PM 'Samuel Benzaquen' via
Nathan Bronson
Mar 13, 2019, 11:25:16 AM3/13/19
to Roman Perepelitsa, Samuel Benzaquen, Matt Kulukundis, hashtable-benchmarks
Yes, this is great! Did you consider supporting other sub-group capacities if the user calls explicit reserve() or provides an initial capacity?
Samuel Benzaquen
Mar 13, 2019, 12:40:53 PM3/13/19
to Nathan Bronson, Roman Perepelitsa, Matt Kulukundis, hashtable-benchmarks
On Wed, Mar 13, 2019 at 11:25 AM Nathan Bronson <ngbr...@gmail.com> wrote:
Yes, this is great! Did you consider supporting other sub-group capacities if the user calls explicit reserve() or provides an initial capacity?
Yes, but we still want "capacity" to be a power-of-two-minus-one to be able to use it as a mask.
One way to do this was to store capacity and mask as separate things. We could have a capacity of 2, with a mask of 0x3 and it will work as long as we make sure that insert only uses the valid slots.
The added benefit might not be worth the extra complexity and struct size increase. We could use a mask of 0 for all small sizes, but that would slow down the find() path too.
Reply all
Reply to author
Forward
0 new messages