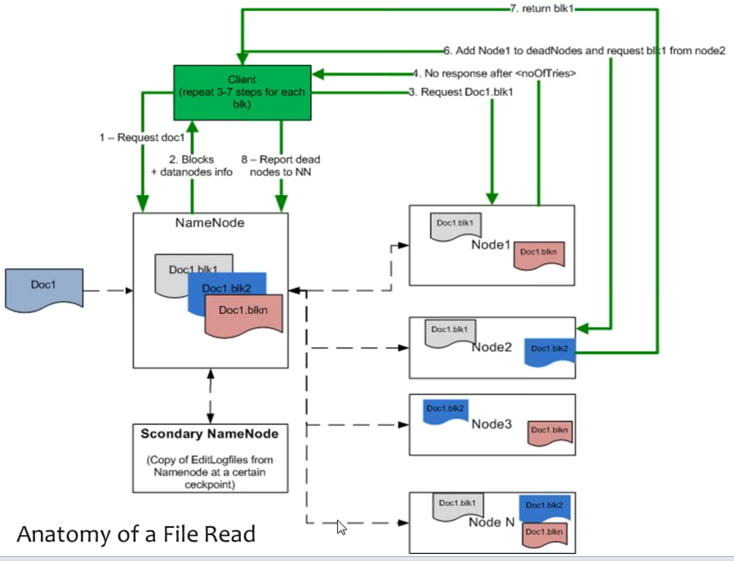
27-June-2013 - Anatomy of a File Read

Raj

Scale up (or vertically) means adding more resources to an existing component of a system. Adding more RAM and/or hard drives to a Hadoop DataNode is an example of scaling up the Hadoop cluster.
Scale out (or horizontally) means adding new components (or building blocks) to a system. Adding a new Hadoop DataNode to a Hadoop cluster is an example of scaling out the cluster.
1. Max Size
2. Failure
3. Computer resource management
4. I0 intensive
5. Cheap Hardwar


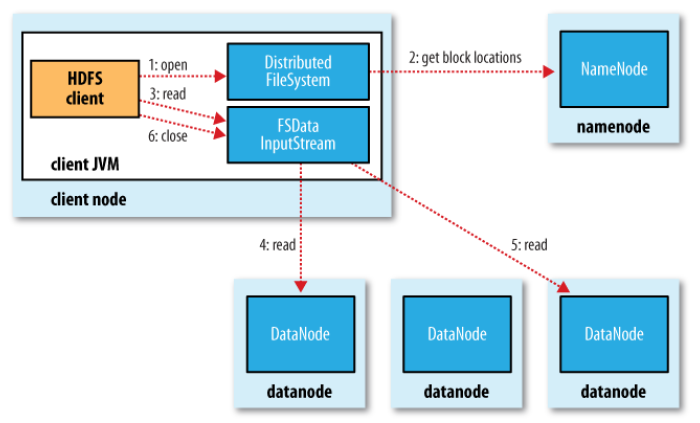
The client opens the file it wishes to read by calling open() on the FileSystem object,which for HDFS is an instance of DistributedFileSystem (step 1).
DistributedFileSystem calls the namenode, using RPC, to determine the locations of the blocks for the first few blocks in the file (step 2). For each block, the namenode returns the addresses of the datanodes that have a copy of that block. Furthermore, the datanodes are sorted according to their proximity to the client. If the client is itself a datanode (in the case of a MapReduce task, for instance), then it will read from the local datanode, if it hosts a copy of the block. The DistributedFileSystem returns an FSDataInputStream (an input stream that supports file seeks) to the client for it to read data from. FSDataInputStream in turn wraps a DFSInputStream, which manages the datanode and namenode I/O. The client then calls read() on the stream (step 3). DFSInputStream, which has stored
the datanode addresses for the first few blocks in the file, then connects to the first (closest) datanode for the first block in the file. Data is streamed from the datanode back to the client, which calls read() repeatedly on the stream (step 4). When the end of the block is reached, DFSInputStream will close the connection to the datanode, then find the best datanode for the next block (step 5). This happens transparently to the client, which from its point of view is just reading a continuous stream. Blocks are read in order with the DFSInputStream opening new connections to datanodes as the client reads through the stream. It will also call the namenode to retrieve the datanode locations for the next batch of blocks as needed. When the client has finished reading, it calls close() on the FSDataInputStream (step 6).
During reading, if the DFSInputStream encounters an error while communicating with
a datanode, then it will try the next closest one for that block. It will also remember
datanodes that have failed so that it doesn’t needlessly retry them for later blocks. The
DFSInputStream also verifies checksums for the data transferred to it from the datanode.
If a corrupted block is found, it is reported to the namenode before the DFSInput
Stream attempts to read a replica of the block from another datanode.
One important aspect of this design is that the client contacts datanodes directly to
retrieve data and is guided by the namenode to the best datanode for each block. This
design allows HDFS to scale to a large number of concurrent clients, since the data
traffic is spread across all the datanodes in the cluster. The namenode meanwhile merely
has to service block location requests (which it stores in memory, making them very
efficient) and does not, for example, serve data, which would quickly become a bottleneck
as the number of clients grew.

Anatomy of Read