PDF資料のテキスト化

seigo ishino

naoto_matsumoto
簡易的な方法としては、以下のような形も使えるかもしれませんので、とりいそぎ情報共有までに。
http://www.google.co.jp/gwt/x?u=http%3A%2F%2Feq.sakura.ne.jp
On 4月27日, 午後6:49, seigo ishino <titanox...@gmail.com> wrote:
> こんにちは。 石野 (@wiraqutra <http://twitter.com/#!/wiraqutra>) といいます。
> 私はHack For Japanに賛同し、放射線量を地図に重ね合わせて見ることができるアプリケーションを開発してきています。
> 現在、私の他にも多くの方々がこの災害に関連する数値の可視化・蓄積された情報の分析などを手がけています。
> このような取り組みが存在する背景として、公に発表される情報の多くが数字でしかなく、理解が難しいということがあります。
>
> さらに政府、自治体、電力会社から発表されている、基となる情報は、ほとんどがPDFでの公開となっています。
> そのため、入力となるデータを取得するという単純な段階で多くの労力が費やされてしまっています。
> 一方で原子力発電所の近傍では、正確な情報を分かりやすい形で提供することが望まれているという喫緊の課題があります。
>
> そこで、これらの資料をテキストベースの扱いやすいデータに変換して能力のあるサーバーに保管し、公開するというサービスを提案させていただきます。
> この提案について、みなさんのご意見をおきかせください。
>
> そして、どなたかこの取り組みのために手を貸していただけませんでしょうか。
> 開発スキルなどは問いませんので、ご興味がおありの方はご連絡ください。
>
> よろしくお願いします。
>
> (資料の提供例)
> ・福島県 <http://wwwcms.pref.fukushima.jp/pcp_portal/contents?CONTENTS_ID=23853>
> ・宮城県 <http://www.pref.miyagi.jp/gentai/Press/PressH230315-3(sokutei).html>
> ・電力会社 <http://www.tepco.co.jp/nu/fukushima-np/index-j.html>
>
> (ボランティアによる入力例)
> ・放射線量モニターデータまとめページ <https://sites.google.com/site/radmonitor311/>
>
> (資料の利用例)
> ・Open Radiation Map <http://orm.dip.jp/>
> ・携帯アプリケーション <http://twitgoo.com/22jakh>

Masahiro Muto
武藤(@mutomasa)です。
お疲れ様です。
可視化は必要だと思います。興味あります。
開発スキル(分野によりますが)はありませんが、レビューと
フィードバックしながらアプリケーションの開発に
お役に立ちたいと思います。
よろしくお願いします。
2011年4月27日18:49 seigo ishino <titan...@gmail.com>:

Riotaro OKADA
PDFからテキストをぶっこぬくなら、PDFlib TETという商用ツールがありますが、
これを活用するととりあえずベタなunicodeテキストを抽出することができます。
ご参照: http://pdflib.techstyle.jp/products/tet.html
これ、スクレイピングにお役立にたてそうでしょうか。
技術情報、ライセンス含めツール提供を検討できます。
なお、このサイトでもこのツールでPDFからテキスト情報を抽出しています。
→ http://handsout.jp/
ご参考になれば幸いです。
2011/4/27 seigo ishino <titan...@gmail.com>:
--
Riotaro OKADA
TechStyle Co. Ltd.
http://techstyle.jp/
http://pdflib.techstyle.jp/
located at 3-7-1, IRIFUNE, CHUO, Tokyo, Japan. 104-0042

kamatamadai
鎌玉(@kamatamadai)と申します。
興味があるので、手伝えることがあれば、お手伝いさせてください。
参考情報として、私が知っている範囲内での『情報提供のデータ形式』の現状について
述べさせていただきます。
※石野様も、ご存じのことが大半だと思いますが、整理の意味を込めて
----------
当初は、三重大学教授 奥村晴彦 さんが、ブログで
「 データは自動処理可能な形で提供してほしい
<http://oku.edu.mie-u.ac.jp/~okumura/blog/node/2578> 」
と訴えるほど、セキュリティのかかったPDF形式ばかりでした。
しかし、流れが変わってきており、上記ブログの追記にあるように
・国民へ発信する重要情報のファイル形式について - 財団法人 地方自治情報センター(LASDEC)
<https://www.lasdec.or.jp/cms/12,22060,84.html>
・東北地方太平洋沖地震等に係る情報提供のデータ形式について - 経済産業省
<http://www.meti.go.jp/policy/mono_info_service/joho/other/
2011/0330.html>
という通達が出て、少しずつCSVやExcelでの提供も増えています。
また、経済産業省情報プロジェクト室(@openmeti)が、東電データを使用した電力アプリを
募集するなど、ティム・オライリーの提唱する「gov2.0」という方向が見えてきました。
※「gov2.0」とは「政府がプラットフォームとして様々なAPIを公開し、サードパーティが
アプリを開発できるようにする」という取り組みです
今こそ「gov2.0」を日本にも - NPOにマーケティングの力を!- BLOGOS(ブロゴス)
<http://news.livedoor.com/article/detail/5515096/>
----------
上記のような状況ですが、PDFでのみしか提供されていない資料があれば、
皆が再利用できる形に変換し、公開するサービスがあるのは非常に有益だと思います。
seigo ishino
NAOTO MATSUMOTO
2011年4月28日0:27 seigo ishino <titan...@gmail.com>:
> Googleの携帯電話向けの変換で、PDFがテキスト化されるのですね。
> この機能は知りませんでした。 教えていただいて、ありがとうございます。
> Google Wireless Transcoder (GWT)
> うまく変換できないPDFもあるようですが、携帯からの利用だと軽量でよさそうですね。
すでにミラーをされている方もいるようですが、以下にファイルを一括して閲覧可能
ですので、お使い頂ければと思います。※ファイルの命名則などもご確認を。
http://eq.sakura.ne.jp/ 過去データ一覧
--
Naoto MATSUMOTO

Hiroshi Chonan
2011年4月27日21:26 Riotaro OKADA <rio...@techstyle.jp>:
> テックスタイルの岡田です。
>
> PDFからテキストをぶっこぬくなら、PDFlib TETという商用ツールがありますが、
> これを活用するととりあえずベタなunicodeテキストを抽出することができます。
>
> ご参照: http://pdflib.techstyle.jp/products/tet.html
サーバサイドで、しかも商用でないものということであれば、
Poppler も検討されてみてはいかがでしょうか。
http://poppler.freedesktop.org/
Ubuntu の環境の場合、poppler-util というパッケージも用意されているので、
# apt-get installl poppler-util
でインストールできるかと思います。インストールするとそのものズバリな 'pdftotext'
コマンドが利用できるようになります。
> pdftotext(1) pdftotext(1)
>
> NAME
> pdftotext - Portable Document Format (PDF) to text converter (version
> 3.00)
>
> SYNOPSIS
> pdftotext [options] [PDF-file [text-file]]
>
> DESCRIPTION
> Pdftotext converts Portable Document Format (PDF) files to plain text.
--
Hiroshi Chonan <cho...@pid0.org>
Takuya Oikawa

松浦弘智 o3_
http://ispp.jp に関わってるのと、震災以前から、社会貢献xIT分
野で勉強会をしたりしてました。
ちょうど今日の夜、東京でNetSquaredTokyoという集まりがあります。sinsai
.info の方が話題提供されます。>詳細は netsquared.jp をご覧
ください。
ーーー
並行して障害のある方の情報へのアクセスにいろいろ関わってて、今回の
PDFのテキスト化のスレッドは興味深かく拝見してます。
Adobe社はかなりPDFを目の見えない方に配慮して開発をしています
が、どうしてもPDFでないといけない場合を除いて、行政等公共性
の高い情報は、なるべくテキストにすべきと思います。ということで、今
回の議論は震災以外のところでもアクセシビリティ保障の議論として続い
て欲しいと思ってます!
ーーー
等々の議論もiSPPのMLや「ITにできること」というサ
イト http://adgj.net/cordinateit/ でしたいと思ってます。今後
も宜しくおねがいします。

矢口勇一(会津大)
会津大学の矢口と申します。
知人伝で放射線量の可視化の話をお聞きしまして、
現在私どもの所でも丁度同一点で時系列のあるデータに対しても、
ずっと表示して行けるような表示を作って居た所でした。
ようやくそれなりに扱えるようになったので、折角ですので一例として見て頂きたいと思いました。
http://matsu4512.jp/radiation_map/
観測データなんですが、現状ではradmonitor311さんのGoogle Spread Sheetを、
手前でDLしながらrubyで一生懸命同じフォーマットになる様に変換するスクリプトを作っております。
具体的には
時間, 場所, 原発からの距離, 緯度, 経度, 放射線量
という簡単な一列のデータを、とにかく縦に並べて行くと言った方法です。
何か良い方法があれば…また良いとは思うんですが(汗
とりあえず、私どもの方で、今radmonitor311さんの所でUpdateされているデータに関しては、
今週中くらいまでには先ほどの形式である程度出せるようにしたいなぁと思っています。
その他諸々、色々と関われると思いますので、よろしくお願い致します。
---
Yuichi Yaguchi <u1.ya...@gmail.com>
Image Processing Laboratory
The University of Aizu
# 先週のHack4Fukushima, 行きたかったけど行けなかったです><
# 議事録本当にありがとうございました。
> こんにちは。 石野 (@wiraqutra <http://twitter.com/#!/wiraqutra>) といいます。
> 私はHack For Japanに賛同し、放射線量を地図に重ね合わせて見ることができるアプリケーションを開発してきています。
> 現在、私の他にも多くの方々がこの災害に関連する数値の可視化・蓄積された情報の分析などを手がけています。
> このような取り組みが存在する背景として、公に発表される情報の多くが数字でしかなく、理解が難しいということがあります。
>
> さらに政府、自治体、電力会社から発表されている、基となる情報は、ほとんどがPDFでの公開となっています。
> そのため、入力となるデータを取得するという単純な段階で多くの労力が費やされてしまっています。
> 一方で原子力発電所の近傍では、正確な情報を分かりやすい形で提供することが望まれているという喫緊の課題があります。
>
> そこで、これらの資料をテキストベースの扱いやすいデータに変換して能力のあるサーバーに保管し、公開するというサービスを提案させていただきます。
> この提案について、みなさんのご意見をおきかせください。
>
> そして、どなたかこの取り組みのために手を貸していただけませんでしょうか。
> 開発スキルなどは問いませんので、ご興味がおありの方はご連絡ください。
>
> よろしくお願いします。
>
> (資料の提供例)
Masahiro Muto
武藤です。
>簡単なオーサリングツールのようなもので、PDFと同時にマルチブラウザ/プラットフォームでの表示がサポートされるHTMLも生成してくれるようなものがあれば、それを啓蒙するということも可能ではないでしょうか。
そのようなツールってあるのでしょうか?
検索してみましたが、よくわかりませんでした。
啓蒙は必要だと思います。
現地視点ですが、理由は
* メモリが少ないマシンを持っていてAdobe Reader開くのに一苦労
(PDF Viewerで開けばいいんじゃないというツッコミがきそうですが)
* 仙台に方の携帯(ガラケー)ではpdfが開けない。つまり情報にアクセス出来ない。みんながPC持っているわけではない。
* 自治体はデフォルトはpdfなんですが、情報課の中の人はHTML5とか勉強していて啓蒙すると、だいぶかわると思います。
→表形式のデータはHTMLとCSVで。
追記
宮城県の【福島第一原子力発電所事故に関する情報】の英語のページだけはHTMLでした。
http://www.pref.miyagi.jp/kokusai/en/accidents_fukushima_nuclear.htm
2011年4月28日13:02 Takuya Oikawa <tak...@google.com>:
NAOTO MATSUMOTO
以下で少し変換してみましたが、なかなか良さそうでした。(結果を添付)
http://www.pdftoexcelonline.com/
2011年4月28日15:50 Masahiro Muto <mutom...@gmail.com>:
NAOTO MATSUMOTO
変換元 http://vhost0098.dc1.co.us.compute.ihost.com/files/110426map_1800.pdf
変換後 Excelデータ
2011年4月28日15:58 NAOTO MATSUMOTO <naot...@gmail.com>:
seigo ishino
seigo ishino
NAOTO MATSUMOTO
2011年4月28日17:22 seigo ishino <titan...@gmail.com>:
> 松本さん、
> 過去のデータがアーカイブされているのですね。アクセスしやすいので利用させていただきたいです。
> このプロジェクトのために、さくらインターネットさんのサーバーを貸していただけますか。
はい、いま調達しましたので、別途アカウントを発行しておきますね。※これがクラウド時代の対応速度です(笑)
> Nitro PDFのPDF to Excelですが、良いですね。
> 原発周辺の固定測定点における空間線量率の測定結果
> については、Popplerで変換しても順序がおかしくなってしまうのですが、これはきちんと再現されていました。
使えそうなツールが見つかると良いですね。
--
Naoto MATSUMOTO

Satoshi Takahashi
iPhoneから送信
seigo ishino
kamatama dai
石野さんWrote:
> 配布元に働きかけて扱いやすい形での提供を依頼するという方向があると思います。
> 後者については、交渉力のある方の協力をお願いしたいです。
誠に勝手なお願いですが、『Hack For Japan』として、公式に提言してもらえないでしょうか。
そして、他の団体(iSPPやIT復興円卓会議など)や企業、個人にも、それに乗っかってもらうようお願いする。
※私個人としては、twitterで拡散するしかできないですが
昨日、Yahoo! Japanで「公式避難場所名簿検索」が公開されましたが、
Yahoo! Japan広報からのお知らせとして、以下の記述があります。
> 本サービスをより良いものとし、且つ継続していくためにはいくつかの問題があります。
> 最も大きな問題が名簿が統一されていないことです。
> 公開されている名簿はPDFであったり、画像であったりとフォーマットや記載されている情報がバラバラです。
> これをひとつひとつ整理していくのは大変な作業です。
> そのため管轄省庁である総務省に対しても、地方自治体に向けて名簿のフォーマットの統一化が図られるような
> 働きかけをしていただけないかという提案を行っております。
> http://blogs.yahoo.co.jp/yj_pr_blog/19741810.html
上記のような働きかけの輪を、企業や個人が別箇にするだけでなく、広げていってはいかがでしょうか。

G4GTi
役にたてればと思いディスカッションに参加させていただきます。
石野さんが大きく分類されているように、(1) 提供されたデータの可視化 (2) データの提供元に対して汎用性が高く再利用可能なデータ形式での提
供 の両面を推進していく必要があると理解しています。
私がお手伝いできるとすれば (2) の分野になると思います。
昨日から別途石野さん、及川さんとTwitterで議論させていただいていますが、こちらに合流させていただきます。いろいろ不調法なことが多いと思い
ますが、忌憚なくご意見、ご指導を頂けますようにお願いします。
前置きが長くなり失礼しました。
(2) に関してさらに取り組みを進めるためにいくつかのテーマがあると考えています
i. 提供側に準備してもらいたいデータ形式のテンプレート(サンプル)
これは(1)の開発の効率化や高橋さんが指摘されたように、今後様々な用途に応用が利くことを考慮してデザインしたものを準備する必要がありま
す。
ii. 提供側にそのテンプレートに則ったデータを出してもらうためのツール類(ソリューション)の提案
さまざまな計測値などを提供している関連団体もおそらくリソースは逼迫しており、こういう形のデータを新たに出してくれ、という要求をするだけで
は彼らの負荷を増やすことにつながる恐れがあり、実現を難しくする懸念があります。なるべくデータを提供している側の現在のルーチン・ワークに対して最
小限の付加作業でi.に沿ったものが得られることが肝要と考えます。
iii. 関連団体への働きかけを行うヒューマン・プロセス
鎌玉さんが既に述べられているように、団体の担当者と協議し、要望を実現するためになるべく効率的に進めるための組織性があることが望ましいです。
すくなくともHack for Japanは実績も多く、またマスメディアでも取り上げられていることから「看板」として非常に有効だと思いますが、同
様の取り組みを行っている他の団体などと横の連携も図る必要があると思います。
私がここで提案させていただいている事柄は「要望を受けた側がその実現にyesと言ってくれるためにはこちら側で何が必要か」ということを念頭に置いて
います。
このプロセス自体が皆さんの活動の方法論や方針に沿うものなのか、自分でもよくわからないのでその点でもご指摘を頂けると大変助かります。
[お尋ねしたいこと]
1. Hack 4 Japanで「他の団体(iSPPやIT復興円卓会議など)」との渉外窓口を担当されていらっしゃる方はおられますか? if
yes, いままでどのようなことがそれらの団体間で連携されているか、あるいは課題となっているかなどをお教えください。
2. 要望を上げる文科省(本件以外でも既に関連している所轄官庁)に影響力を持っているメンバーの方はHack 4 Japanではどういった方々が
いらっしゃるでしょうか?
これらをbest effortで迅速にまとめた上で、動けるメンバーがリアル・アクションを取る(私ができることであればもちろん参画いたします)と
いう形で(2)を進める、というのが私のコメントです。
以上、まとまりの悪いコメントですが、皆様の活動にとってお役にたてるものに繋がれば幸いです。ぜひ皆さんのご意見、異論、疑問などお聞かせくださ
い。
よろしくお願いいたします。
4月29日
野田 良平
鎌玉 大
PDFから、HTMLやXMLファイルなどへの変換は、Adobe Acrobatの『他のファイル形式へのPDFの書き出し』
機能を使用すれば、可能なことが分かりました。
<http://help.adobe.com/ja_JP/Acrobat/8.0/Standard/help.html?
content=WS58a04a822e3e50102bd615109794195ff-7efe.html>
※画像が一部、綺麗に抽出できないところもあります
ただし、原発周辺の固定測定点における空間線量率の測定結果
<http://www.mext.go.jp/a_menu/saigaijohou/syousai/1304001.htm>のPDFに対し
て、
「ページの抽出」を許可しないように「パスワードによるセキュリティ」
が掛かっており、通常の手順では変換できませんでした。
しかし、知り合いから昔聞いた話ですが、このセキュリティの設定は、
PDFのデータにフラグとして記録されているだけなので、それを無視して実装することが可能だそうです。
(本当に正しいかどうかは、分かりませんが)
実際、Foxit J-Reader <http://www.foxitsoftware.com/> では、テキストへの抽出ができました。
http://www.pdftoexcelonline.com/ (nitro pdf software)も同様に、抽出禁止フラグを無視して
変換ができました。
ともかく、以下のWebサービスで、セキュリティを外すことが出来ました。
http://www.pdfunlock.com/ (nitro pdf software)
【備考】
「平成23年4月29日 16時00分現在」のPDFを、以下のメッセージが表示されて、変換できませんでした。
------------------------------------------------
次のエラーにより、この文書をアクセシブルにすることができませんでした:
オブジェクト構造を更新できません。[3]
文書の一部のページが変更された可能性があるため、この変更を保存しないことをお勧めします。
[OK]
------------------------------------------------
http://www.pdftoexcelonline.com/ では、正常に変換できました。
現在、調査中です。
kamatama dai
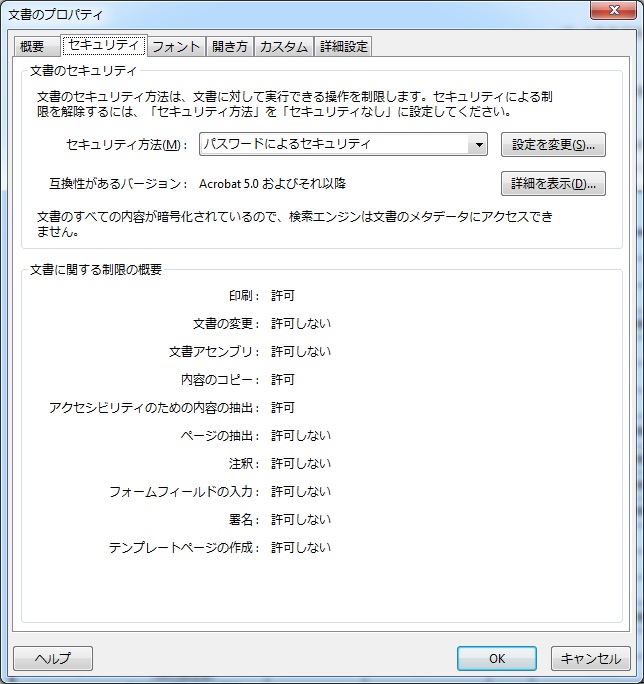
参考資料として、ファイルを添付します。
・文書プロパティ.jpg
文部省の「原発周辺の固定測定点における空間線量率の測定結果」にあるPDFの文書プロパティのスクリーンショット
「アクセシビリティのための内容の抽出」とは、視覚障害者のために音声リーダー用のテキストを
抽出することに対する設定であって、これが許可されていても変換できません。
・1305388_042910.unlocked.pdf
セキュリティを外したPDF
・抽出結果.zip
HTML 4.01形式、XML 1.0形式、プレーンテキストに変換した結果の圧縮。
HTML及びXMLの変換時に、imagesフォルダにjpegファイルが抽出されました。
※ScanSnap S1500付属のAdobe Acrobat 9 Standardを使用しました。
2011年4月30日0:14 鎌玉 大 <kamat...@gmail.com>:
{kind=link}
松浦弘智 o3_
申し遅れましたが、3/21のHack for Japan "beginning"、GoogleWaveと京都に参加しました。
当日はありがとうございました。
これは偶然ですが、その日(2011/3/21)にiSPPの母体となる会合もありました。
その辺りからICT周りの人たちも動き出して今日に至る、なんですね。^-^
----
PDFのテキスト化の件、意見や提言、テスト、おつかれさまです。
まさにこれって、「データの民主化運動」「PDFという独裁者へのジャスミン革命(^^;)」って自分では思ってます。
野田 G4GTi <ryohe...@gmail.com>さん
件名:[hack4japan:33] Re: PDF資料のテキスト化
の提言、賛成です。
iSPPやIT復興円卓会議などとは積極的につなぎたいですし
(「ITにできること」で声をかけられそうなところまとめてます
http://adgj.net/cordinateit/)、今回主に対象になりそうな行政や企業、それから、ソフトメーカー、当事者(アクセシ
ビリティの面も含めて)、キャリア、(海外も含めて)…等々、巻き込んで
いくといいと思います。
そこで、野田さんのご質問への簡単な回答ですが、
> 1. Hack 4 Japanで「他の団体(iSPPやIT復興円卓会議など)」との渉外窓口を担当されていらっしゃる方はおられますか? if
> yes, いままでどのようなことがそれらの団体間で連携されているか、あるいは課題となっているかなどをお教えください。
iSPPでは、http://www.ispp.jp/archives/93 で課題が出てます。
10 情報システムを連携を支援するための共通APIの策定
の部分で議論でしょうかね…。
12 情報支援活動のインデックス化
5 情報ボランティアの派遣
なども、関係しそうです。いずれにしても、iSPPの全体のMLへ
投げるといいです。とりあえずHack4JP ML でこうした議論がある
こと、松浦弘智が担当して投稿します。
> 2. 要望を上げる文科省(本件以外でも既に関連している所轄官庁)に影響力を持っているメンバーの方はHack 4 Japanではどういった方々が
> いらっしゃるでしょうか?
これはカミングアウトを待つしかないですね^^;
私もメールが送れる方はいますので、ダメもとでも送ってみます。
その他、、
・目的等は違いますが、視覚に障害を持った方向けの「daisy フォーマット」の
運動が課題の構造としては、結構似ているかな、と思います。(もちろん、
今後はこれをきっかけに、PDFとdaissyフォーマットのすり合わせ、とかも
調べないといけないかもしれません。)
・必要は発明の母、ってことで、この際、PDFに代わるモノを
作っちゃうのもいいかもしれません。すでにあるのかもしれませんが…
・将来像は data.gov みたいなものを目指す、という感じでいいでしょうかね。。
・並行して、どうしてもPDFのものしかないものは、例えばマイクロボランティア的にガーッとCSVとかにする、というのもアリかな、と思いました。
例えば http://tinyurl.com/3r7mon8 こういう有用なデータって
個人の方で対応されてるのですかね・・?もしそうであれば
もうちょっと人海戦術的にできるといいな、と。
以上です。
---
ITにできること」http://adgj.net/cordinateit/
松浦弘智 matsuura hirosato
matsu...@gmail.com
09096929382
2011年4月29日14:59 G4GTi <ryohe...@gmail.com>:
matsuatbct
今回は与太話、というか愚痴です…
今、あらためて、
石野さん (@wiraqutra) の最初の投稿を読み直し、以下少しまとめて、みました。
。。で、何と言うか、、、これって↓税金払っている者が受けるサービスとしては
あんまりですよね・・なんというか、まとめるほどに、意地悪されているとしか思えず、
我々国民がかわいそうになってきました ^^;
アメリカでは、何年も前に「電子」情報公開法というのが成立していて、
「国民にデータを入手する手間をかけてはならない」というのが、法律に
なってるはず。で、data.gov みたいなのがきちんとできている。一方で、
日本、データを提供するサーバまで民間で提供、、、orz
ちょっと愚痴りたくなりました。
・・でも現状では(すぐに使える形式のものは)「ない」ので、
やるしかないですね。がんばりましょう!
~~~
> Hack For Japanに賛同
> 放射線量を地図に重ね合わせて見ることができるアプリケーションを開発
> 災害に関連する数値の可視化・蓄積された情報の分析などを手がけてる
> 背景:公に発表される情報の多くが数字でしかなく、理解が難しい
(課題)
> 政府、自治体、電力会社から発表されている、基となる情報は、ほとんどがPDF
> での公開
(現状)
> 入力となるデータを取得するという単純な段階で多くの労力が費やされてしまっ
> ている
(需要)
> 原子力発電所の近傍では、正確な情報を分かりやすい形で提供することが望まれ
> ているという喫緊の課題
(解決策)
> 資料をテキストベースの扱いやすいデータに変換して能力のあるサーバーに保管
> し、公開するというサービスを提案
松浦弘智 o3_
> 今回は与太話、というか愚痴です…
:
> 。。で、何と言うか、、、これって↓税金払っている者が受けるサービスとしては
> あんまりですよね・・なんというか、まとめるほどに、意地悪されているとしか思えず、
> 我々国民がかわいそうになってきました ^^;
> アメリカでは、何年も前に「電子」情報公開法というのが成立していて、
> 「国民にデータを入手する手間をかけてはならない」というのが、法律に
> なってるはず。で、data.gov みたいなのがきちんとできている。一方で、
立て続けにすいません、補足です
「電子」情報公開法
=正確にはEFOIA 電子情報自由法 というらしいです。(前提としてFOIAがあって、e-FOIA)
この文章が参考になります。
http://web.sfc.keio.ac.jp/~taiyo/980614/980614paper.html
*この辺りの話を最新情報として1996年当時聞いたことがあったことを思い出しました。それから15年かぁ。。
ーー
PDFで公開されていることによる、国民の損失とかでを数値化できないですかね^^;
例えばコストとして計算できると、税金の話として議員さんなどには持って行きやすいかもしれません。CO2排出量でもいいかも ^^;
seigo ishino
seigo ishino
Ryohei Noda
Ryohei Noda
Takuya Oikawa
松浦弘智 o3_
私も5/21,22は現場にハッカソン等会場で参加したいと思ってます。
東京が便利かな、とも思うし、なるべく被災地近くの会津、仙台にも行きたくもあり、
悩ましいですね。
ぜひ顔をつき合わせてPDFのテキスト化の話もしたいです!
ーーー
こちら
http://code.google.com/p/hack-access/
にアクセスしたいのですが、権限とかは申請するんでしたっけ?
ーーー
iSPP* MLにも「読めない文書をハック」の紹介をしておきました。
ところで前後して、特に行政の現場でのでいわゆる「外字」問題の議論もありました。
PDFはそういったとこももしかしたら関連しているのかなとちょっと思いました。
*http://ispp.jp/
ーーー
アクセシビリティとの兼ね合いも少し調べたところ、目の見えない方のニーズから
生まれたデータフォーマット、"Daisy"のこんな記事が気になりました。
http://www.dinf.ne.jp/doc/japanese/access/daisy/seminar100709/daisy_and_epub.html
「DAISYとEPUBは読書のユニバーサルデザインをどう実現するのか」
河村宏(DAISYコンソーシアム会長)
PDF等書類データも、また、紙を介さずに、電子端末上やクラウド上を飛び交う時代を
見とおさないといけないかもしれません。今回は紙資料が多く津波により流出したとも
ききますし、より現場に近い人ほど、クラウド・デジタルデータなどの重要性に
関心があるかもしれませんね。
ーーー
ついでに、以前ちらっと書いたNetSquaredTokyo、次は5/24なので
アナウンス…
http://netsquared.jp/
http://www.facebook.com/event.php?eid=153244508074187
以上です
--
松浦弘智 ITにできること http://adgj.net/cordinateit/
seigo ishino
Ryohei Noda
Takuya Oikawa
Riotaro OKADA
岡田です。
PDFのテキスト化のスレッドで反応した者です。(PDFlib TETの話含め)
わたしは、21日に仙台会場に行く事にしました。たぶん、20日から
前乗りするかもしれません。
お目にかかれるかどうかわかりませんが、何かできればと思っています。
よろしくお願いします。
2011/5/9 Takuya Oikawa <tak...@google.com>:
--
Riotaro OKADA
TechStyle Co. Ltd.
http://techstyle.jp/
http://pdflib.techstyle.jp/
located at 3-7-1, IRIFUNE, CHUO, Tokyo, Japan. 104-0042
Riotaro OKADA
岡田です。
> hack-access - 読めない文書をハック - Hack For Japanプロジェクト -
> 開発の具体的なことはこちらで進めてゆきたいと思います。
> みなさんのご参加をお待ちしています。
このメールを見落としておりました。
rio...@gmail.comをメンバーに入れていただけますでしょうか。
よろしくお願いいたします。
2011/4/28 seigo ishino <titan...@gmail.com>:
--
seigo ishino
鎌玉 大
・石野様
取り急ぎ、情報共有のため、
『hack-access - 読めない文書をハック <http://code.google.com/p/hack-access/>』に
情報をあげさせていただきました。
http://code.google.com/p/hack-access/source/browse/#svn%2Ftrunk%2Fsample
山田さんからいただいたソースを元に、ビルド/実行ができるJavaのPDFBoxライブラリを
使用したサンプルプログラムを置きました。
また、http://code.google.com/p/hack-access/wiki/tool にPDFの抽出ができる
ツール/サービスの一覧を作りました。
あと、http://code.google.com/p/hack-access/wiki/exsample に
「ページ抽出が禁止されたPDFの抽出例」を現在、作成中です。
(後は、抽出ファイルをアップロードして、リンクを張る予定です)
・テックスタイルの岡田様
>テックスタイルの岡田です。
>
>PDFからテキストをぶっこぬくなら、PDFlib TETという商用ツールがありますが、
>これを活用するととりあえずベタなunicodeテキストを抽出することができます。
>
>ご参照: http://pdflib.techstyle.jp/products/tet.html
>
>技術情報、ライセンス含めツール提供を検討できます。
良かったら、http://code.google.com/p/hack-access/wiki/tool に
「PDFlib TET」について、追記してもらえないでしょうか。
よろしく、お願いします。
以上です。