Continuously record time series compound data using h5py
616 views
Skip to first unread message

Adam Insanoff
Apr 23, 2020, 11:00:16 AM4/23/20
to h5py
Hi Folks! I need a bit assistance. I am trying to record time series data from sensors. But unable to write data preserving different data types for columns. The requirement is to record data continuously over long periods of time.
Sensor is supplying 250 messages per second consisting of timestamp and values: [15858470255501616, 487, -0.21712538599967957, 0.6170574426651001, -0.4243968725204468].
Here is an example of series of data:
[(15858454834467256, -257, -0.27251104, 0.5188583 , -0.23071696)
(15858454834467256, -316, -0.27149168, 0.56167173, -0.24668705)
(15858454834477220, -338, -0.2708121 , 0.60924226, -0.26911315)
(15858454834487184, -361, -0.25076452, 0.6554536 , -0.30071357)
(15858454834487184, -376, -0.21270812, 0.72409105, -0.337071 )
...
(15858454303800120, 30, -0.24057084, 1.2127081, -0.98165137)
(15858454303800120, 78, -0.23037717, 1.4128441, -1.1199456 )
(15858454303810080, 62, -0.22867823, 1.7179749, -1.2959565 )
(15858454303810080, 36, -0.2422698 , 2.0383961, -1.4502208 )
(15858454303820050, 12, -0.27183145, 2.3462453, -1.5722052 )]As I understood, I need to resize HDF5 table to add more data in it. My problem with the code is I do not know how to implement specific data types for different columns when extending the table.
import h5pyimport pandas as pdimport numpy as npimport numpy.lib.recfunctions as rf
hdfFile = 'dtype.hdf5'dataset = 'measurement'dataTypes = np.dtype([('ts', '<u8'), ('r', '<i2'), ('x', '<f4'), ('y', '<f4'), ('z', '<f4')])
if __name__ == '__main__': try: dataList = [[15858470255501616, 487, -0.21712538599967957, 0.6170574426651001, -0.4243968725204468], [15858470255512022, 355, -0.2449881136417389, 0.705402672290802, -0.38430172204971313], [15858470255512022, 379, -0.2759089469909668, 0.9048590064048767, -0.32857629656791687], [15858470255522018, 386, -0.2990145981311798, 1.1875636577606201, -0.3227998614311218], [15858470255531978, 367, -0.3567788004875183, 1.4342507123947144, -0.3486238420009613], [15858470255531978, 308, -0.45327895879745483, 1.5297315120697021, -0.37037035822868347], [15858470255541552, 221, -0.47740399837493896, 1.4566768407821655, -0.42269793152809143], [15858470255541552, 135, -0.37410804629325867, 1.2918790578842163, -0.4631328582763672], [15858470255551908, 69, -0.245327889919281, 1.212368369102478, -0.5120625495910645], [15858470255551908, 18, -0.20591233670711517, 1.1542643308639526, -0.4981311559677124]]
structData = rf.unstructured_to_structured(np.array(dataList), dataTypes)
with h5py.File(hdfFile, 'w') as hf: if not dataset in hf: # Check if dataset exists # Creat an empty dataset hf.require_dataset(dataset, (10, 5), compression="gzip", chunks=True, maxshape=(None, 5), dtype=dataTypes) hf[dataset][:] = structData for f in range(3): # Adding data into existing table by extending it hf[dataset].resize((hf[dataset].shape[0] + 10, 5)) hf[dataset][-10:] = structData print("Shape of table:", hf[dataset].shape) print("Data types of table:", hf[dataset].dtype) df = pd.DataFrame(hf[dataset][:]) print(df)
except KeyboardInterrupt: link.close()
I am able to write a single batch of data using following code:
import h5py
import pandas as pd
import numpy as np
import numpy.lib.recfunctions as rf
hdfFile = 'dtype.hdf5'
dataset = 'measurement'
dataTypes = np.dtype([('ts', '<u8'), ('r', '<i2'), ('x', '<f4'), ('y', '<f4'), ('z', '<f4')])
if __name__ == '__main__':
try:
dataList = [[15858470255501616, 487, -0.21712538599967957, 0.6170574426651001, -0.4243968725204468], [15858470255512022, 355, -0.2449881136417389, 0.705402672290802, -0.38430172204971313], [15858470255512022, 379, -0.2759089469909668, 0.9048590064048767, -0.32857629656791687], [15858470255522018, 386, -0.2990145981311798, 1.1875636577606201, -0.3227998614311218], [15858470255531978, 367, -0.3567788004875183, 1.4342507123947144, -0.3486238420009613], [15858470255531978, 308, -0.45327895879745483, 1.5297315120697021, -0.37037035822868347], [15858470255541552, 221, -0.47740399837493896, 1.4566768407821655, -0.42269793152809143], [15858470255541552, 135, -0.37410804629325867, 1.2918790578842163, -0.4631328582763672], [15858470255551908, 69, -0.245327889919281, 1.212368369102478, -0.5120625495910645], [15858470255551908, 18, -0.20591233670711517, 1.1542643308639526, -0.4981311559677124]]
structData = rf.unstructured_to_structured(np.array(dataList), dataTypes)
#print(structData)
#print(structData.dtype)
#df = pd.DataFrame(structData)
#print(df.dtypes)
with h5py.File(hdfFile, 'w') as hf:
hf[dataset] = structData
with h5py.File('dtype.hdf5', 'r') as hf:
sa = hf[dataset][:]
print(sa)
print(sa.dtype)
except KeyboardInterrupt:
link.close()Although the whole table appears under the column zero. But it is not possible to extend the table that way.
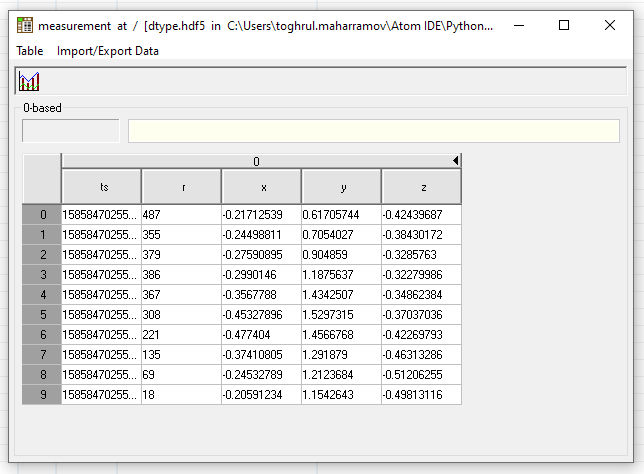
Thanks!

Thomas Kluyver
Apr 23, 2020, 12:24:06 PM4/23/20
to h5...@googlegroups.com
Hi Adam,
If I was doing this, I'd probably make 5 separate datasets for the different columns. I find struct arrays a hassle to work with, and accessing one column - e.g. to take an average or plot a timeseries - is more efficient if it's stored as a separate dataset.
However, if you prefer to do this with a compound datatype, I think your mistake is that the columns are not part of the shape. I.e. your shape should be (10,) instead of (10, 5). Each entry in your dataset is a struct of 5 numbers, but in terms of the shape and the indexing, it's still just one entry.
Best wishes,
Thomas
--
You received this message because you are subscribed to the Google Groups "h5py" group.
To unsubscribe from this group and stop receiving emails from it, send an email to h5py+uns...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/h5py/90f8a792-709e-4e42-85b1-9b8a79bea989%40googlegroups.com.
Adam Insanoff
Apr 30, 2020, 10:14:13 AM4/30/20
to h5py
Hi Thomas,
thank you for the reply. You have right. Compound dataset is considered as a single object. But before I will try something else, maybe I can achieve to define different data types for columns.
Btw. it does work if I separate datasets for each data type.
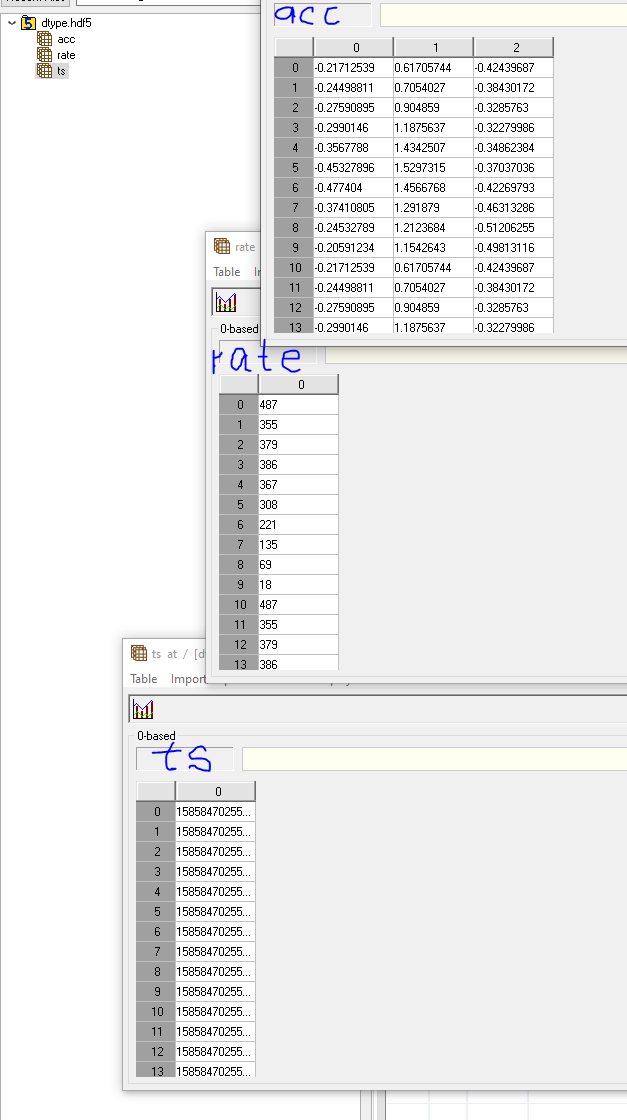
I used this snippet below:
# create an array from the list
dataArray = np.array(dataList)
# define seperate data frames for each type # for timestamp tsDf = pd.DataFrame({'ts': dataArray[:, 0]}) tsDf = tsDf.astype(np.uint64)
rateDf = pd.DataFrame({'rate': dataArray[:, 1]}) rateDf = rateDf.astype(np.int16)
accDf = pd.DataFrame({'x': dataArray[:, 2], 'y': dataArray[:, 3], 'z': dataArray[:, 4]}) accDf = accDf.astype(np.float32)
with h5py.File(hdfFile, 'w') as hf: # create seperate datasets for each dataframes dset = hf.create_dataset('ts', data=tsDf, compression="gzip", chunks=True, maxshape=(None,5), dtype='u8') dset = hf.create_dataset('rate', data=rateDf, compression="gzip", chunks=True, maxshape=(None,5), dtype='i4') dset = hf.create_dataset('acc', data=accDf, compression="gzip", chunks=True, maxshape=(None,5), dtype='f4')
# get new location to resize from fromRow = hf['ts'].shape[0] # resize datasets and add more data hf['ts'].resize((hf['ts'].shape[0] + 10, 1)) hf['ts'][fromRow:] = tsDf
hf['rate'].resize((hf['rate'].shape[0] + 10, 1)) hf['rate'][fromRow:] = rateDf hf['acc'].resize((hf['acc'].shape[0] + 10, 3)) hf['acc'][fromRow:] = accDfThanks
Adam
To unsubscribe from this group and stop receiving emails from it, send an email to h5...@googlegroups.com.
Adam Insanoff
May 4, 2020, 12:02:55 PM5/4/20
to h5py
Hi again!
So I modified my code here, and now I try to write different columns into separate datasets. For "counter" number 10 it works fine, but for 100 it fails. I can't run it for a long time:
Traceback (most recent call last):
File ".\test.py", line 41, in <module>
structData = rf.unstructured_to_structured(np.array(dataList), dataTypes)
File "<__array_function__ internals>", line 5, in unstructured_to_structured
File "C:\Users\adam.insanoff\AppData\Local\Programs\Python\Python38\lib\site-packages\numpy\lib\recfunctions.py", line 1090, in unstructured_to_structured
raise ValueError('The length of the last dimension of arr must '
ValueError: The length of the last dimension of arr must be equal to the number of fields in dtypeI need it to run for multiple days. Does anyone have an idea how to write iteratively to HDF5? I could hardly find any information on the internet.
import struct
import h5py
import pandas as pd
import numpy as np
import time
from pySerialTransfer import pySerialTransfer as txfer
import numpy.lib.recfunctions as rf
bufLen = 10
counter = 10
hdfFile = 'dtype.hdf5'
dataTypes = np.dtype([('ts', '<u8'), ('r', '<i2'), ('x', '<f4'), ('y', '<f4'), ('z', '<f4')])
if __name__ == '__main__':
try:
link = txfer.SerialTransfer('COM3', 460800)
link.open()
time.sleep(3)
with h5py.File(hdfFile, 'w') as hf:
''' Create seperate datasets for each variable '''
for i in range(len(dataTypes)):
hf.create_dataset(dataTypes.names[i], (0,), dtype=dataTypes[i], chunks=True, compression="gzip", maxshape=(None,))
''' Write data in HDF5 file '''
# Test write counter
for i in range(counter):
#while(True):
dataList = [[0 for x in range(4)] for x in range(bufLen)]
# Collect data into buffer
for e in range(bufLen):
# Append values from serial port
if link.available():
dataList[e][0] = struct.unpack('h', bytes(link.rxBuff[0:2]))[0]
dataList[e][1] = struct.unpack('f', bytes(link.rxBuff[2:6]))[0]
dataList[e][2] = struct.unpack('f', bytes(link.rxBuff[6:10]))[0]
dataList[e][3] = struct.unpack('f', bytes(link.rxBuff[10:14]))[0]
dataList[e].insert(0, int(time.time() * 10**7))
elif link.status < 0:
print('ERROR: {}'.format(link.status))
# Create compound data frame
structData = rf.unstructured_to_structured(np.array(dataList), dataTypes)
df = pd.DataFrame(structData)
# Write data frame columns to HDF5 file in separate datasets
for colName in df.columns:
hf[colName].resize((hf[colName].shape[0] + len(df.index),))
hf[colName][-len(df.index):] = df.loc[:, colName]
except KeyboardInterrupt:
link.close()Thomas Kluyver
May 6, 2020, 8:39:54 AM5/6/20
to h5...@googlegroups.com
Hi Adam,
I can't see exactly where it's going wrong, but I'd suggest that you're making things overly complicated by going from a list of lists, to a plain array, to a structured array, to a pandas dataframe, to HDF5 datasets. Try making a list for each column (rather than for each row), and then writing that to the h5py dataset directly. Here's a rough illustration for a single column:
hf.create_dataset('x', shape=(0,), dtype='<f4')
new_x_values = []
for e in range(bufLen):
new_x_values.append(struct.unpack('f', bytes(link.rxBuff[2:6]))[0])
hf['x'].resize((hf['x'].shape[0] + bufLen,))
hf['x'][-bufLen:] = new_x_values
Best wishes,
Thomas
--
You received this message because you are subscribed to the Google Groups "h5py" group.
To unsubscribe from this group and stop receiving emails from it, send an email to h5py+uns...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/h5py/a78e914f-afb8-4103-b7cf-21ef6a4565a0%40googlegroups.com.

Stan West
May 7, 2020, 10:11:58 AM5/7/20
to h5...@googlegroups.com
On Wed, May 6, 2020 at 8:39 AM Thomas Kluyver <tak...@gmail.com> wrote:
I can't see exactly where it's going wrong, but I'd suggest that you're making things overly complicated by going from a list of lists, to a plain array, to a structured array, to a pandas dataframe, to HDF5 datasets.
Hello, Adam. I second the suggestion from Thomas to simplify the data structures involved. I suspect that the cause of the specific exception you saw is that, sometimes, the length of at least one inner list of dataList differs from the number of fields in dataTypes. When created, the inner dimension of
dataList
is four, but, for some (and presumably most) outer indices (specifically, those for which link.available() is True-like), the code inserts a time-stamp element, enlarging that inner list to five elements, thereby matching dataTypes. If link.available() is False-like for at least one outer index, which might be more likely the longer the code runs, that inner list remains four elements long, and
unstructured_to_structured() complains about the mismatch.
On the topic of your higher-level goal of streaming to HDF, one limitation that I eventually encountered in appending to chunked datasets was that the HDF library occasionally needed to rebalance the tree that it used to track the chunks. As the dataset and tree grew, the processing burden during rebalancing likewise grew, and for faster write rates, that burden interfered more. My eventual solution was to write raw binary data to disk files; HDF wasn't involved in that process. To read such data via HDF, one can create a small HDF file containing datasets for which you declare that the data is stored externally in the binary files.
Adam Insanoff
May 18, 2020, 9:39:31 AM5/18/20
to h5py
Thank you everyone for your great help!
Yes, this is what happens if you're newbie, you want to apply every piece of knowledge you've learned. I made it too complicated.
Crude but working example of code:
import structimport h5pyimport pandas as pdimport numpy as npfrom pySerialTransfer import pySerialTransfer as txferimport time
buffLen = 1000 # Length of single batchhdfFile = 'dtype.hdf5'dataTypes = ['<i2', '<f4', '<f4', '<f4']dataSets = ['r', 'x', 'y', 'z']
if __name__ == '__main__': try: # Define the serial connection link = txfer.SerialTransfer('COM3', 460800) # Connect to port and check if link.open(): # Wait serial to start time.sleep(3) # Create an HDF5 file with h5py.File(hdfFile, 'w') as hf: # Create HDF5 datasets for all sensors for i in range(len(dataSets)): hf.create_dataset(dataSets[i], (0,), dtype=dataTypes[i], chunks=True, compression="gzip", maxshape=(None,))
# Write N batches of data while True: # Batch buffer buffer_r = [] buffer_x = [] buffer_y = [] buffer_z = [] # Fill the buffer with lists of values for count in range(buffLen): while len(buffer_r) < buffLen: if link.available(): buffer_r.append(struct.unpack('h', bytes(link.rxBuff[0:2]))[0]) buffer_x.append(struct.unpack('f', bytes(link.rxBuff[2:6]))[0]) buffer_y.append(struct.unpack('f', bytes(link.rxBuff[6:10]))[0]) buffer_z.append(struct.unpack('f', bytes(link.rxBuff[10:14]))[0]) elif link.status < 0: print('ERROR: {}'.format(link.status)) else: continue # Write buffer data frame to HDF5 file hf["r"].resize((hf["r"].shape[0] + buffLen,)) hf["r"][-buffLen:] = buffer_r
hf["x"].resize((hf["x"].shape[0] + buffLen,)) hf["x"][-buffLen:] = buffer_x
hf["y"].resize((hf["y"].shape[0] + buffLen,)) hf["y"][-buffLen:] = buffer_y
hf["z"].resize((hf["z"].shape[0] + buffLen,)) hf["z"][-buffLen:] = buffer_z
except KeyboardInterrupt: link.close() except: import traceback traceback.print_exc()
link.close()Adam Insanoff
May 18, 2020, 9:45:03 AM5/18/20
to h5py
Hello, Stan. Do you mean to make something similar to pseudo files in Linux? Sounds like a great idea, but my knowledge does not allow me to fully understand it.
Stan West
May 19, 2020, 10:03:26 AM5/19/20
to h5...@googlegroups.com
On Mon, May 18, 2020 at 9:45 AM Adam Insanoff <cros...@gmail.com> wrote:
Hello, Stan. Do you mean to make something similar to pseudo files in Linux? Sounds like a great idea, but my knowledge does not allow me to fully understand it.
Hi, Adam. No; the files were ordinary files, opened in binary mode and with each buffer of data written with the write() method. So, each file simply contained a sequence of elements of some basic data type—unsigned 16-bit integers, for example. That approach lacks the self-documenting and platform-independent benefits of HDF, but, in my application, I sacrificed those for
sustainable
and relatively
fast
writing (although, when reading the files later, I could get the benefits back through HDF's external storage mechanism). The
occasional
rebalancing of the chunk tree might not cause a problem in your application.
Adam Insanoff
May 20, 2020, 5:52:45 AM5/20/20
to h5py
Thank you very much, Stan, for the answer. Seems to be a more efficient way of temporarily storing data.
Reply all
Reply to author
Forward
0 new messages