Preemptible nodes stalling (not being preempted)
43 views
Skip to first unread message

TJ
Nov 20, 2020, 1:01:20 AM11/20/20
to google-cloud-slurm-discuss
Hello everyone,
![]()
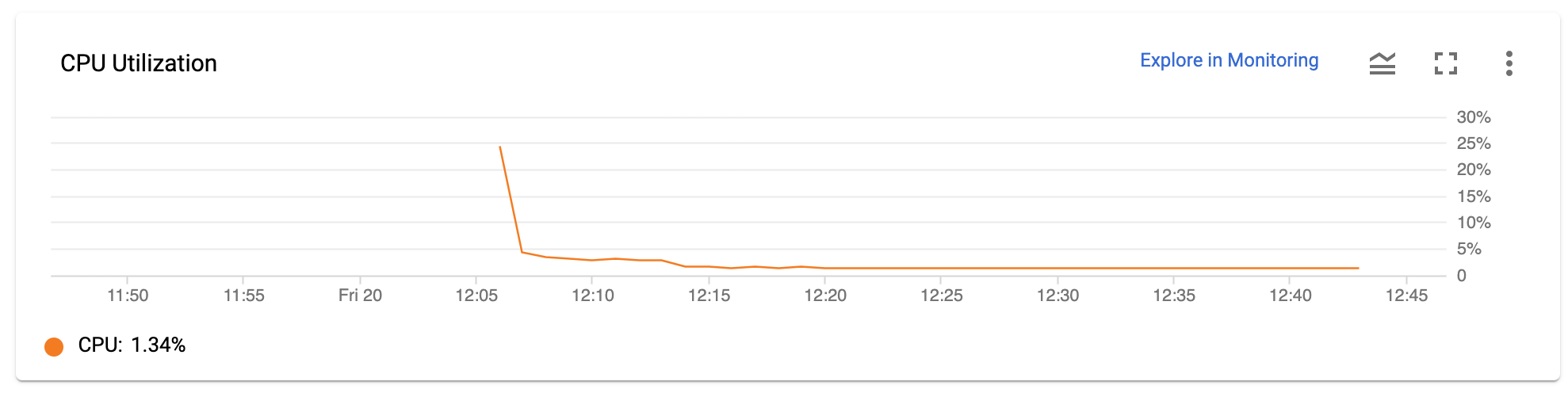
I am trying to run 1,000 iterations of a program that should take 10 minutes each. To that end, I've set up a 250 node cluster on google cloud and I've made sure I have all the correct quotas and everything, and I am also using an 8 vCPU controller node. When I submit one realization of the program via a batch script, everything works fine; the program finishes in 10 minutes. However, when I submit 250 realizations of the same program via a slightly modified version of the same batch script, what happens is the controller calls up 250 nodes, and each of them runs at 100% CPU capacity for like, a minute....then they all stall or something, and run at about 1% capacity without doing anything, even though the program hasn't finished. And this situation lasts for like, an hour. I've also noticed that during this time, the login node is very laggy- commands like "squeue" or "ls" take a while to carry out. I've attached an image of the CPU usage of a single node that's currently "stalled" and not doing anything. This isn't the first time this has happened, either- I've had the same problem on a different, 1000-node cluster I made a while ago. The nodes all ended up "un-stalling" themselves after an hour or two, and the jobs did run successfully to completion, but I really would like to know why it is doing this and find a solution.
Has anyone else had this problem? Thank you!
TJ
Nov 20, 2020, 1:02:18 AM11/20/20
to google-cloud-slurm-discuss

mska...@gmail.com
Nov 20, 2020, 6:29:10 AM11/20/20
to google-cloud-slurm-discuss
Hi,
Are these jobs independent or they communicate, such as mpi? It seems that you hit some limits. Have you checked IOPS and throughput on shared disk?
Best,
Maciej
TJ
Nov 20, 2020, 5:19:15 PM11/20/20
to google-cloud-slurm-discuss
Thank you Maciej for your response. These jobs are independent. However, they do draw all the data they process from the same disk, mounted on the controller node. I could see how drawing 250 GB of data from a single disk all at once might cause some delays. Are you saying that there's a way to throttle the allowable IOPS by changing my permissions, or is this something that's limited by the hardware? Thanks again.

Alex Chekholko
Nov 20, 2020, 5:30:03 PM11/20/20
to TJ, google-cloud-slurm-discuss
Maybe one simple test you can do is a scaling test with more steps. Sounds like you tested 1 job vs 250 jobs, but try 5, 10, 50, 100 and see if you have the same issue?
--
You received this message because you are subscribed to the Google Groups "google-cloud-slurm-discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to google-cloud-slurm-...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/google-cloud-slurm-discuss/2bab5d60-b971-416a-90c3-9d45c81fc0c2n%40googlegroups.com.
Maciej Skarysz
Nov 20, 2020, 6:07:26 PM11/20/20
to Alex Chekholko, TJ, google-cloud-slurm-discuss
Disk limits are related to hardware. They scale with the size of the disk, so one option is to increase the size. You can also switch to SSD. You can monitor current limits in the disk monitor. Also, agree with Alex.
Best,
Maciej
To view this discussion on the web visit https://groups.google.com/d/msgid/google-cloud-slurm-discuss/CANcy_PaydA1a0RQUz-2K12-AJ_14KANwvxWf34aBJAhVSyivXw%40mail.gmail.com.

Wyatt Gorman
Nov 23, 2020, 12:46:01 PM11/23/20
to Maciej Skarysz, Alex Chekholko, TJ, google-cloud-slurm-discuss
Hi TJ,
The controller node hosts the NFS storage that all your nodes are hitting simultaneously, and given that it's currently a 8 vCPU instance (4 cores) and likely has a relatively small disk (under 1TB?), the most likely explanation is that you're bogging down the controller node. Please consider increasing the machine type of the controller node (i.e. c2-standard-16), with a larger disk (i.e. several TB), or otherwise use a Filestore, NetApp, or other storage system in concert with the network_storage fields to offload the file storage work from the controller node.
Wyatt Gorman HPC Solutions Manager |

To view this discussion on the web visit https://groups.google.com/d/msgid/google-cloud-slurm-discuss/CAF55sMuqpfb-G_R0hjYyjzuoBWjjqDOoi858zgkCidSNOvAZ5w%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages