FAQ for out of preview pricing changes

Gregory D'alesandre
Definitions
Instance: A small virtual environment to run your code with a reserved amount of CPU and Memory.
Frontend Instance: An Instance running your code and scaling dynamically based on the incoming requests but limited in how long a request can run.
Backend Instance: An Instance running your code with limited scaling based on your settings and potentially starting and stopping based on your actions.
Scheduler: Part of the App Engine infrastructure that determines which Instance should serve a request including whether or not a new Instance is needed.
Serving Infrastructure
Q: What’s an Instance?
A: When App Engine starts running your code it creates a small virtual environment to run your code with a reserved amount of CPU and Memory. For example if you are running a Java app, we will start a new JVM for you and load your code into it.
Q: Is an App Engine Instance similar to a VM from infrastructure providers?
A: Yes and no, they both have a set amount of CPU and Memory allocated to them, but GAE instances don’t have the overhead of operating systems or other applications running, so a much larger percentage of the CPU and memory is considered “usable.” They also operate against high-level APIs and not down through layers of code to virtual device drivers, so it’s more efficient, and allows all the services to be fully managed.
Q: How does GAE determine the number of Frontend Instances to run?
A: For each new request, the Scheduler decides whether there is an available Instance for the request, the request should wait, or a new Instance should be created to service the request. It looks at the number of Instances, the throughput of the Instances, and the number of requests waiting. Based on that it predicts how long it will take before it can serve the request (aka the Pending Latency). If it predicts the delay will be over 1 second, a new Instance is created. If it looks like an Instance is no longer needed, it will take that Instance down.
Q: Should I assume I will be charged for the number of Instances currently being shown in the Admin console?
A: No, we are working to change the Scheduler to optimize the utilization of instances, so that number should go down somewhat. If you are using Java, you can also make your app threadsafe and take advantage of handling concurrent requests. You can look at that as an upper bound on how many Instances you will be charged for.
Q: How can I control the number of instances running?
A: With the new Scheduler you’ll have the ability to choose a set of parameters that will help you specify how many instances are spun up to serve your traffic. More information about the specific parameters and how they will affect the Scheduler will be available on this within a few weeks.
Q: What can I control in terms of how many requests an Instance can handle?
A: The single largest factor is your application’s latency in handling the request. If you service requests quickly, a single instance can handle a lot of requests. Also, Java apps support concurrent requests, so it can handle additional requests while waiting for other requests to complete. This can significantly lower the number of Instances your app requires.
Q: Will there be a solution for Python concurrency? Will this require any code changes?
Python concurrency will be handled by our release of Python 2.7 on App Engine. We’ve heard a lot of feedback from our Python users who are worried that the incentive is to move to Java because of its support for concurrent requests, so we’ve made a change to the new pricing to account for that. While Python 2.7 support is currently in progress it is not yet done so we will be providing a half-sized instance for Python (at half the price) until Python 2.7 is released.
Q: How many requests can an average instance handle?
A: Single-threaded Instances (python or java) can currently handle 1 concurrent request. Single-threaded Instances (python or java) can currently handle 1 concurrent request. Therefore there is a direct relationship between the latency and number of requests which can be handled on the instance per second, for instance: 10ms latency = 100 request/second/Instance, 100ms latency = 10 request/second/Instance, etc. Multi-Threaded Instances can handle many concurrent requests. Therefore there is a direct relationship between the cpu consumed and the number of requests/second. For instance, for a B4 (approx 2.4GHz) instance: consuming 10 Mcycles/request = 240 request/second/Instance, 100 Mcycles/request = 24 request/second/Instance, etc. These numbers are the ideal case but they are pretty close to what you should be able to accomplish on an Instance. Multi-Threaded instances are currently only supported for Java; we are planning support for Python later this year.
Q: Why is Google charging for instances rather than CPU as in the old model? Were customers really asking for this?
A: CPU time only accounts for a portion of the resources used by App Engine. When App Engine runs your code it creates an Instance, this is a maximum amount of CPU and Memory that can be used for running a set of your code. Even if the CPU is not currently working due to waiting for responses, the instance is still resident and considered “in use” so, essentially, it still costs Google money. Under the current model, apps that have high latency (or in other words stay resident for long periods of time without doing anything) are not able to scale because it would be cost-prohibitive to Google. So, this change is designed to allow developers to run any sort of application they would like but pay for all of the resources that are being used.
Q: What does this mean for existing customers?
A: Many customers have optimized for low CPU usage to keep bills low, but in turn are often using a large amount of memory (by having high latency applications). This new model will encourage low latency applications even if it means using larger amounts of CPU.
Q: How will always-on work under the new model?
A: Still determining how this will work, answer coming very soon (no seriously, we are almost done).
Q: What is the difference between On-demand Instances and Reserved Instances?
A: On-demand Instances have no pre-commitment in terms of the number that will be used. You pay for them as you use them. Reserved Instances are pre-commitment to a certain number of Instance Hours in a week. They are cheaper but you must pay for all the Instance Hours that you have pre-committed to whether you use them or not. This does not mean they have to be running the whole time.
Q: Wait, so Reserved instances don’t mean you have to keep them running the whole time?
A: No, it is just a way to get cheaper instance-hours by pre-committing to them.
Q: What is the time granularity of the instance pricing? ie if I have an instance up for 5 minutes, what am I charged, $0.08 / 60*5?
A: Instances are charged for their uptime and until they are idle for 15 minutes (when the scheduler takes them down). So if you have an on-demand Instance only serving traffic for 5 minutes, you will pay for 5+15 minutes, or $0.08 / 60 * 20 = 2.6 cents.
Q: You seem to be trying to account for RAM in the new model. Will I be able to purchase Frontend Instances that use different amounts of memory?
A: We are only planning on having one size of Frontend Instance.
Q: Do Frontend instances handle Task Queues and Cron?
A: Yes.
Q: Can the experimental Go Runtime handle concurrent requests?
A: Not currently.
Costs
Q: Is the $9/app/month a fee or a minimum spend?
A: Based on the feedback we’ve received we are changing this $9 fee to be a minimum spend rather than a fee a originally listed. In other words you will still have to spend $9/month in order to scale but you won’t pay an additional $9 for your first $9 worth of usage each month. The $500/account/month will still be a fee as it covers the cost of operational support.
Q: Will most customers have to move to Paid Apps?
A: No, we expect the majority of current active apps will still fall under the free quota.
Q: Will existing apps be grandfathered in and continue under today’s billing model?
A: No, existing apps will fall under the new billing model once App Engine is out of preview.
Q: Will most customers’ bills increase? If so, why is Google increasing the price for App Engine?
A: Yes, most paying customers will see higher bills. During the preview phase of App Engine we have been able to observe what it costs to run the product as well as what typical use patterns have been. We are changing the prices now because GAE is going to be a full product for Google and therefore needs to have a sustainable revenue model for years to come.
APIs
Q: How were the APIs priced?
A: For the most part the APIs are priced similarly to what they cost today, but rather than charging for CPU hours we are charging for operations. For instance the Channel API is $0.01/100 channels. This is approximately what users pay today (although it would be paid as a fraction of a CPU hour). The datastore API is the most significantly changed and is described below.
Q: For the items under APIs on the pricing page that just have a check, what does that mean?
A: Those items come free with using App Engine.
Q: For XMPP, how does the new model work? How much do presence messages cost?
A: For XMPP we will only be charging an operation fee for outgoing stanzas. Incoming stanzas are just considered requests similar to any other request and so we’ll charge for the bandwidth used as well as whatever it takes to process the request in terms of Instance Hours. We don’t charge for presence messages other than the bandwidth it consumes. This is almost exactly how it works today with the exception that your bill would show CPU hours as opposed to Stanzas.
Q: For Email, how much do incoming emails cost?
A: Incoming emails will just be considered requests similar to any other request and so we’ll charge for the bandwidth used as well as whatever it takes to process the request in terms of Instance Hours. This is in essence how it works today.
Q: Will the Front End Cache feature ever be formalized as an expected, documented part of the service offering?
A: We are currently looking at various options, but don’t yet have any plans for when this would happen.
Q: What is being charged for in terms of Datastore operations? What do you expect the ratio to be between the new pricing metric and the Datastore API calls metric we have today?
A: Today we charge for the CPU consumed per entity written, index written, entity read, query index scanned, and query result read. Under the new model we will charge per operation rather than CPU, and we will no longer charge for query index scans. This means the cost of your queries will be tied exclusively to the size of your result set. We expect the cost of these operations will be approximately 4x the cost of the equivalent CPU under today’s model, but for apps that make heavy use of indexes, this will be somewhat offset by the fact that we will no longer be charging for query index scans. The admin console today shows total Datastore API Calls, but this is not a good gauge of how many operations you will be charged for under the new model. Your costs will be highly dependent on the types and contents of your API calls, not the number of calls themselves, which is what we currently display. For example a single get() API call may retrieve 1 Entity or 100 Entities, and a beginTransaction() API call doesn’t consume any billable resources.
Q: Could emails sent to admins be cheaper or free?
A: That’s a possibility that we can look into.
Usage Types
Q: What does the Premier cost of "$500/account" mean? Per Google Apps Account? Per Developer Account, Per Application Owner Account?
A: It is per Organization (which would translate into per Google Apps account if you are currently a Google Apps customer). So, for instance if you are working at gregco.com and you signed up for a Premier account, gregco.com users will be able to create apps which are billed to the gregco.com account.
Q: Will there be special programs for non-profit usage?
A: Possibly, we are currently looking into this.
Q: Will there be special programs for educational usage?
A: Possibly, we are currently looking into this.
Q: Will there be special programs for open-source projects?
A: Possibly, we are currently looking into this.
Usage Limits
Q: If I migrate to HR Datastore, does that mean I have a "newly created" application, and will get the new, lower, free quota for email? Could you grandfather in migrated apps at the old 2000 limit?
A: Yes, we can grandfather in the email quota for HRD apps that are migrating from M/S apps.

Robert Kluin
I'm looking forward to seeing the scheduler improvements in the
coming weeks. Overall this looks promising, I'm actually pretty happy
to see that the API calls 'with checks' will be included and just
billed by time consumed. Is the 4x cost relative to a master-slave
(M/S) or high-replication (HR) apps? Certainly if that is relative to
M/S then it is not that bad, HR is totally worth it. ;)
Thanks for listening to and addressing the community's feedback.
Robert
> --
> You received this message because you are subscribed to the Google Groups
> "Google App Engine" group.
> To post to this group, send email to google-a...@googlegroups.com.
> To unsubscribe from this group, send email to
> google-appengi...@googlegroups.com.
> For more options, visit this group at
> http://groups.google.com/group/google-appengine?hl=en.
>

Stephen Johnson
Still not clear on the datastore costs. For this you say, "This means
the cost of your queries will be tied exclusively to the size of your
only query) or also the entities. It seems like it should not be the
same since a fetch to get the whole entity is not required but I'm not
clear when you say "size of your result set." I think a lot of people
have tried to optimize some operations by just returning the keys and
not the entire entities and I hope that wasn't wasted effort.
Thanks,
Stephen

Vinuth Madinur
--

Maxim Lacrima
Under the new model for the Datastore API calls, does it mean that I don't care anymore about performing operations in batches? So in terms of costs db.get(key1); db.get(key2) is essentially the same as db.get([key1, key2])?
Thank you!
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.
--
with regards,
Maxim

Sudhir Jonathan
Great job with the FAQ... I think it clarifies things a lot, and is
quite will written.
I'm still not clear on some points, though.
If I do db.get([key1, key2]), and two entities were fetched, how many
'operations' have I consumed?
If key2 didn't exist and only one entity was fetched, what would be
the charges?
If db.get(key1) fetches a 5kb entity and db.get(key2) fetches a 500kb
entity, what's the difference in charges?
Under the new scheme, is it more economical to do keys only query that
fetches 1000 keys, and then do a get on the 500 of them that I need,
or just fetch all 1000 directly?
Being able to provide a definitive answer to these questions would
really help.
Sudhir
> > *Instance*: A small virtual environment to run your code with a reserved
> > actions.
> > needed.
>
> > complete. This can significantly lower the number of Instances your app
> > requires.
>
> > Q: Will there be a solution for Python concurrency? Will this require any
> > code changes?
> > Python concurrency will be handled by our release of Python 2.7 on App
> > Engine. We’ve heard a lot of feedback from our Python users who are worried
> > that the incentive is to move to Java because of its support for concurrent
> > requests, so we’ve made a change to the new pricing to account for that.
> > a minimum spend rather than a fee a originally listed*. In other words
> > additional $9 for your first $9 worth of usage each month. The
> > $500/account/month will still be a fee as it covers the cost of operational
> > support.
>
> > Q: Will most customers have to move to Paid Apps?
> > A: No, we expect the majority of
>
>
> read more »

Kngt
Thanks for the FAQ. A follow-up question: will datastore queries be
priced only according to the number of entities fetched/saved or will
entity size also come into play?
Thanks,
H.E.
On May 18, 7:49 am, "Gregory D'alesandre" <gr...@google.com> wrote:
> Hello All!
>
> As you've likely heard, when Google App Engine leaves Preview in the second
> half of 2011, the pricing model will change. Prices are listed here:http://www.google.com/enterprise/appengine/appengine_pricing.html. But that
> leaves a lot of questions unanswered, this FAQ is intended to help answer
> some of the frequently asked questions about the new model. We are
> interested in hearing additional thoughts and comments you have based on
> this. Once it is relatively stable I'll add it to our official docs. If
> you find there is something you want to know but it is not yet answered,
> just ask and I'll try to answer it as clearly as possible. We've made some
> changes based on the feedback we've gotten (from this group in particular),
> they are bolded below but not updated on the external pages yet. There are
> still blanks to fill in and I will be sending that information to this group
> first in order as it is available. Finally, thank you for your questions
> and bearing with us as we are ironing out details, I and the whole App
> Engine team very much appreciate it.
>
> Greg D'Alesandre
> Senior Product Manager, Google App Engine
>
> -------------------
>
> *Instance*: A small virtual environment to run your code with a reserved
> actions.
> needed.
>
> complete. This can significantly lower the number of Instances your app
> requires.
>
> Q: Will there be a solution for Python concurrency? Will this require any
> code changes?
> Python concurrency will be handled by our release of Python 2.7 on App
> Engine. We’ve heard a lot of feedback from our Python users who are worried
> that the incentive is to move to Java because of its support for concurrent
> requests, so we’ve made a change to the new pricing to account for
> providing a half-sized instance for Python (at half the price) until Python
> minimum spend rather than a fee a originally listed*. In other words you
> additional $9 for your first $9 worth of usage each month. The
> $500/account/month will still be a fee as it covers the cost of operational
> support.
>
> Q: Will most customers have to move to Paid Apps?
> A: No, we expect the majority of current active apps will still fall under
> the free quota.
>
> Q: Will existing apps be grandfathered in and continue under today’s billing
> model?
> A: No, existing apps will fall under the new billing model once App Engine
> is out of preview.
>
> Q: Will most customers’ bills increase? If so, why is Google increasing the
> price for App Engine?
> A: Yes, most paying customers will see higher bills. During the preview
> phase of App Engine we have been able to observe what it costs to run the
> product as well as what typical use patterns have been. We are changing the
> prices now because GAE is going to be a full product for Google and
> therefore needs to have a sustainable revenue model for years to come.
>
> Account? Per Developer Account, Per Application Owner Account?
> A: It is per Organization (which would translate into per Google Apps
> account if you are currently a Google Apps customer). So, for instance if
> you are working at gregco.com and you signed up for a Premier account,
> gregco.com users will be able to create apps which are billed to the
> gregco.com account.
>
> Q: Will there be special programs for non-profit usage?
> A: Possibly, we are currently looking into this.
>
> Q: Will there be special programs for educational usage?
> A: Possibly, we are currently looking into this.
>
> Q: Will there be special programs for open-source projects?
> A: Possibly, we are currently looking into this.
>
> application, and will get the new, lower, free quota for email? Could you
> grandfather in migrated apps at the old 2000 limit?
> migrating from M/S apps.*

Brandon Wirtz
My current provider offers me Unlimited bandwidth for $14.95 a month. How
much is your unlimited plan?
:-)
Greg,
Sudhir
--

风笑雪
--

Jeff Schnitzer
> Hi Greg,
> Can you raise On-demand Frontend Instances free quota to 25 Instance Hours
> per day?
> The small apps have very low traffics in average, but sometime (maybe
> several minutes) it may use more than 1 instances to handle burst traffics,
> so that they will got OverQuotaErrors at the end of the day.
> Thank you.
To unofficially answer your question, I presume that one of the new
scheduler options will be "do not exceed N instances" which, if you
set N=1, will prevent you from going over free instance quota. Bursty
traffic will sit in the pending queue.
Jeff

Sylvain
But : "[...] will still have to spend $9/month in order to scale but
So with this change : an app thats use 1GB above the free quota will
pay $9/month (and not $9,15) ?
Currently, this app cost $0.15/month
It's x60 than now.... more than $100 / year...
This drastic change is not fair.
I think that many small apps that don't fit within the free quotas
will be shutdown.
Regards
Sylvain
> > *Instance*: A small virtual environment to run your code with a reserved
> > actions.
> > needed.
>
> > complete. This can significantly lower the number of Instances your app
> > requires.
>
> > Q: Will there be a solution for Python concurrency? Will this require any
> > code changes?
> > Python concurrency will be handled by our release of Python 2.7 on App
> > Engine. We’ve heard a lot of feedback from our Python users who are worried
> > that the incentive is to move to Java because of its support for concurrent
> > requests, so we’ve made a change to the new pricing to account for that.
>
> plus de détails »

Matija

Dennis
> > Q: Will there be a solution for Python concurrency? Will this require any
> > code changes?
> > Python concurrency will be handled by our release of Python 2.7 on App
> > Engine. We’ve heard a lot of feedback from our Python users who are worried
> > that the incentive is to move to Java because of its support for concurrent
> > requests, so we’ve made a change to the new pricing to account for that.
> > While Python 2.7 support is currently in progress it is not yet done so we
> > will be providing a half-sized instance for Python (at half the price) until
> > Python 2.7 is released.
about code change for concurrency.
If code change is not needed, that would be great and well worth
mentioning.
If code change is needed, what changes are needed and what can we do
now to start preparing for those changes?
Dennis
concurrency solution?
Robert Kluin
Batch calls can reduce your latency allowing your app to service
requests much faster -- so batching is still going to be a good idea.
Also, be sure to check out the async db methods, they can help reduce
latency even further.
Robert
Maxim Lacrima
Thanks for the clarification.

Andrei
Why can't people write their own scheduler if the they pay for
instances
On May 18, 12:49 am, "Gregory D'alesandre" <gr...@google.com> wrote:
> Hello All!
>
> As you've likely heard, when Google App Engine leaves Preview in the second
> half of 2011, the pricing model will change. Prices are listed here:http://www.google.com/enterprise/appengine/appengine_pricing.html. But that
> leaves a lot of questions unanswered, this FAQ is intended to help answer
> some of the frequently asked questions about the new model. We are
> interested in hearing additional thoughts and comments you have based on
> this. Once it is relatively stable I'll add it to our official docs. If
> you find there is something you want to know but it is not yet answered,
> just ask and I'll try to answer it as clearly as possible. We've made some
> changes based on the feedback we've gotten (from this group in particular),
> they are bolded below but not updated on the external pages yet. There are
> still blanks to fill in and I will be sending that information to this group
> first in order as it is available. Finally, thank you for your questions
> and bearing with us as we are ironing out details, I and the whole App
> Engine team very much appreciate it.
>
> Greg D'Alesandre
> Senior Product Manager, Google App Engine
>
> -------------------
>
> *Instance*: A small virtual environment to run your code with a reserved
> actions.
> needed.
>
> complete. This can significantly lower the number of Instances your app
> requires.
>
> Q: Will there be a solution for Python concurrency? Will this require any
> code changes?
> Python concurrency will be handled by our release of Python 2.7 on App
> Engine. We’ve heard a lot of feedback from our Python users who are worried
> that the incentive is to move to Java because of its support for concurrent
> requests, so we’ve made a change to the new pricing to account for
> providing a half-sized instance for Python (at half the price) until Python
> minimum spend rather than a fee a originally listed*. In other words you
> additional $9 for your first $9 worth of usage each month. The
> $500/account/month will still be a fee as it covers the cost of operational
> support.
>
> Q: Will most customers have to move to Paid Apps?
> A: No, we expect the majority of current active apps will still fall under
> the free quota.
>
> Q: Will existing apps be grandfathered in and continue under today’s billing
> model?
> A: No, existing apps will fall under the new billing model once App Engine
> is out of preview.
>
> Q: Will most customers’ bills increase? If so, why is Google increasing the
> price for App Engine?
> A: Yes, most paying customers will see higher bills. During the preview
> phase of App Engine we have been able to observe what it costs to run the
> product as well as what typical use patterns have been. We are changing the
>
> read more »
Gregory D'alesandre
Hi Greg,
I'm looking forward to seeing the scheduler improvements in the
coming weeks. Overall this looks promising, I'm actually pretty happy
to see that the API calls 'with checks' will be included and just
billed by time consumed. Is the 4x cost relative to a master-slave
(M/S) or high-replication (HR) apps? Certainly if that is relative to
M/S then it is not that bad, HR is totally worth it. ;)
Thanks for listening to and addressing the community's feedback.
Gregory D'alesandre
Gregory D'alesandre
Hi Greg,Can you raise On-demand Frontend Instances free quota to 25 Instance Hours per day?The small apps have very low traffics in average, but sometime (maybe several minutes) it may use more than 1 instances to handle burst traffics, so that they will got OverQuotaErrors at the end of the day.

stevep

marcdmarc
you have been bombarded with over the past few days.
The python "multi-threading" support seems like good news, although I
am sure many would like a little more information about the plans for
python to make sure it will be the right runtime to stick with. Will
the "multi-threading" in python actually be using multiprocessing to
get around the GIL, similar to twisted web framework? Or will it use
python's epoll, similar to the tornado web framework? Or how about a
combination of both?
As Dennis mentioned above, what kind of code changes may be required?
Will webapp be getting a rewrite? Will frameworks such as twisted or
tornado work with this new "multi-threading" python runtime?
Personally, I would rather have to deal with code changes later, than
to have to port my app over to java now, but as soon as this
information is known by the Google App Engine team, it would be
beneficial for all of us python devs to know as much as we can to plan
ahead for any code changes we may have to endure later.
Best

pdknsk
> able to purchase Frontend Instances that use different amounts of memory?
> A: We are only planning on having one size of Frontend Instance.
wants to make (more) money. I'm just curious.
Dennis
- How many concurrent requests can a single instance handle (for python)? If the process is waiting for the datastore, is the number of processes (and thus concurrency) dependent mainly on the number of processes that can fit in memory?
- Will heavy python frameworks (like django) have a lower concurrency ability because they use more memory? If so, what will their concurrent requests / instance be (for the simplest django app, then we can add in our own app's memory usage)?
- For those considering switching to java, what is the estimated concurrent requests / instance for java apps? Java uses threads instead of processes.
Mike Wesner
I am concerned about the potential changes to the python front end
instances. Currently an instance could use at least 200mb. Soft
memory limit errors aside you could bump into the hard limit
(MemoryError) at 300mb. I don't think it is wise to change that limit
down to 128mb. It really guts the capability of task queues if you
reduce the memory further. 10 minutes of processing time doesn't mean
much if you are that restricted by ram. Reducing memory on front end
instances will break some of our heavy weight features.
-Mike Wesner
Sergey Schetinin
1) What are the expected limits on the concurrency for Python 2.7
instances? Assuming the requests handlers / threads are just waiting
for RPC to finish (say on urlfetch service), how many per-process are
allowed? This is probably still TBD, but a ballpark figure would be
very welcome.
2) How the keys-only queries will be charged for?
3) What controls are in place to make sure that the instances do not
get stuck on a bad / slow host? I have experienced very different
response times from a noop WSGI app hosted on GAE, and given the costs
will now be tied very directly to the latency, how can you make us
comfortable with the fact that this latency is volatile and often
completely out of our control? (or remove the volatility)
4) Can we have some assurance that the hosts are not oversold and the
CPU / Memory quota is actually guaranteed? Volatility in response
times (as measured by the GAE dashboard itself) suggests that
different hosts are under a different load and sometimes the
instance's process has to wait to get to run on a CPU. (When a no-op
app sometimes runs in 10ms and sometimes in 300ms+, that doesn't look
like guaranteed CPU to me).
5) Can we configure scheduler to shut instances down faster than in 15
minutes? (And not get charged for that idle time). If not, please
justify this limitation.
6) Will we have a way to explicitly shut down an instance from the
instance itself? (Without returning an error, basically to suggest to
scheduler that "this is the last request I want to handle")
7) Will the pricing become stable after this change? How can you
assure us that it will?
8) Is there any intention to adjust the prices in a year or two to
account for falling hardware prices?
Thank you.
-Sergey
PS I also wanted to mention to people asking if GIL will be removed --
of course it will stay. Also, there's no need to remove it, so please
don't make random requests and learn what GIL is and why it's there. I
would bet that the concurrency will be via regular Python threads (no
multiprocessing), but the app itself would not be allowed to spawn or
control those threads.

vlad

Chris Farmiloe
Brandon Wirtz
It was a joke… My Sprint Phone has Unlimited Text, Talk and Data. It would be farer to say unmetered… Obviously I can’t download 100 Terabytes of data a month the phone won’t go that fast, nor can I talk 2000 hours a month, because I can only have one conversation at a time.
-Brandon
--

goog_fanboy
care much for the business side of things. But, can we get at least
some of your thoughts about the new PRICING and the change.
For me, as someone who have been evangelizing AppEngine in person and
in forums, it's like a slap in the face. I do realize that you must
make money from this endeavor, but can we hear you say in this. A post
in the blog dedicated to just this issue would be appreciated.
Like someone here in the group said, i looks like a move from pure
PaaS towards IaaS, which BTW is just the opposite of the Windows Azure
team, which slowly move from IaaS towards PaaS.
I looks like the (major) change in pricing goes very much against you
motto (don't be evil). Even if you miscalculated pricing when you
started AppEngine (maybe you set your pricing too low then), or you
didn't expect the king of users you get (maybe too many spammers or
malicious users), we want your say.

Luís Marques
transition between 0$ and 9$.
The change to "max(9$, used billable quota)" from the earlier "$9 +
used billable quota" is nice, but still makes the gap somewhat
jarring.
I was thinking, can't there be a middle ground between:
1) small fixed quotas, min $0, max 0$
2) very large fixed quotas, min 9$, max unlimited$
What is the rationale for the $9? To recoup the losses from the $0
loss leader? To support the cost of the free quota that paid apps
receive (e.g. 24 free IHs)? To provide guarantees for serious apps?
(how so?).
Consider offering a billing class which doesn't need to be
particularly generous regarding fixed quotas, but is more elastic than
"max $0 billable quota". That would allow for, say, a web service
which has very low traffic but needs 600 MB of HR storage.
BTW: looking at the price of reserved front-end instances, if one had
to allocate all of the provided free front-end instances, that would
cost 0.05$ * 24h * 30d = 36$ per month. So the 9$ now seems cheap. But
why bundle all that and charge the 9$? You are offering 720 free
monthly instance hours. Many people won't be needing that, just the
elasticity that comes with billing. So just let people buy a whatever
amount they need. Some will need less, and will pay less. Others will
buy more and pay proportionally.

nickmilon
IMHO this is a sisyphean task, new policy has opened Pandora's box
with questions popping up from it in a much faster rate that can be
answered.
Nick
Jeff Schnitzer
just to work around the deficiencies in Google Checkout that produce
the current $0.01 bills?
Jeff
2011/5/18 Luís Marques <luism...@gmail.com>:

rekby
time in both storage type. http://code.google.com/intl/en/appengine/docs/java/datastore/hr/
On May 18, 7:47 pm, "Gregory D'alesandre" <gr...@google.com> wrote:
>
> read more »
Brandon Wirtz
Welcome to the real world.
Did you know that when you buy Gasoline on a day that is 10 below zero, you
get 30% more energy per gallon (and dollar) than when you buy on a 114
degree day? Do they charge less for gasoline on Hot days?
When the 85 pound skinny little Asian girl that is my best friend comes to
visit and doesn't have any checked bags flies she is 110 pounds of cargo,
but they charge her as much as the 250 pound guy with two 55 pound checked
bags and a 25 pound carry on even though she is 1/3 the weight.
The Buffet at Circus Circus is all you can eat, but I don't get a discount
if the family of 6 sumo wrestlers are in line ahead of me and eats all of
the prime-rib before I can get to it.
Oh, and the only variability I have seen is not tied to nodes, or instances
it was tied to if I get good rolls of the dice on my caching and data store
look ups. But I could probably write some test code to see if different
instances have variability between them performance wise. I would just have
to test with sever app Id's so that I could tell if I had the same
instances. (also variability probably gets lessened by me having 100+
instances across my apps at almost all times)
-Brandon
--
Brandon Wirtz
deal. You can't get any hosting for $9 a month short of Dreamhost. If you
want cheaper than DreamHost pricing likely you don't need GAE's
infrastructure.
-----Original Message-----
From: google-a...@googlegroups.com
[mailto:google-a...@googlegroups.com] On Behalf Of Jeff Schnitzer
Sent: Wednesday, May 18, 2011 3:48 PM
To: google-a...@googlegroups.com
Sergey Schetinin
My test case is this: there's an app that is just a noop wsgi app
(webob.Response('pong')). It is not under any load. There's a
different GAE app that urlfetches it once a minute on a cron schedule.
I am looking at the logs of the first app and the graphs on the
dashboard, and the time / request and even cpu / request vary wildly.
See attachment.
Remember, this is an app that does absolutely nothing.
Such variability isn't perfect but is OK, if I only pay for the CPU
used -- if at some point the host running the app is too busy to
actually run my code, I'm fine with a new instance serving the
concurrent requests. But when I have to pay for this, it's not OK at
all.
Frankly, I'm not too happy that every request takes ~15ms even when
the luck is on my side, cause I know the app itself doesn't take even
that long to execute, but that's not the issue here.
Anyway, your comparisons are wrong.
-Sergey
Luís Marques
> $9 is less than I spend on Mountain Dew a Day. This shouldn't be a big
> deal. You can't get any hosting for $9 a month short of Dreamhost. If you
> want cheaper than DreamHost pricing likely you don't need GAE's
> infrastructure.
Jeff Schnitzer
$9/mo accumulates when you have multiple apps that aren't being
monetized. I have one app that is a failed commercial venture which
never took off, so I run it as a free service to a small group of
users. I could pay $9/mo for it, or I could let it stop working for
the handful of users towards the end of the day. I'm just going to
let it hit the quota limits.
Jeff
Jeff Schnitzer
> Regarding differences in pricing based on Differences in Latency:
>
> Welcome to the real world.
This isn't quite right. Yes, there is a real-world cost to latency -
but due to a poor design decision by GAE's engineers, that cost is at
least two orders of magnitude higher than it is on any other platform.
Google has sheltered us from not only the cost of their
single-threaded python system, but also the knowledge that the system
is as inefficient as it is.
I built a GAE/Python backend for a client whose "internet bill" ends
up being ~$10/mo. I'm very concerned that this bill is about to go to
$100-$200/mo (even with the price halved) for a system that would
still be $10/mo if I had written it in Java like all my other GAE
apps. Hell, this guy's app could even run on a simple LAMP stack - it
peaks around 4 hits per second.
If my client's bill spikes like this, I'm going to look like a total
asshole. And I really shouldn't - if I had known the technology
limitations ahead of time, I could have worked around it (or simply
not used appengine for that project). I don't mind that GAE's price
reflects actual cost of services as long as 1) I know what that is
ahead of time and 2) the cost is reasonable - and a single-threaded
service layer is simply not an adequate use of precious memory in this
day and age.
Jeff
Brandon Wirtz
on it.

Rafael Nunes
Dennis
use AppEngine as a platform.
Although AppEngine has it's disadvantages (vendor lock-in, restricted
architecture, etc),
the key reason to choose AppEngine is scalability.
The datastore scales.
Now we need to focus the other component of scalability:
Does the frontend processing scale? Does it scale ECONOMICALLY?
We are on AppEngine for scalability, so give us information on what
needs to be done
to get economical, end-to-end scalability.
Is Java more economical than python at scale?
What is the python solution for frontend scalability?
How much better is it than the current python solution and how does it
compare to Java?
Tell us so we can make the tradeoffs for our own situation and
preferences.
It's better for us to know now so we can do our planning with plenty
of lead time and being well informed of what the tradeoffs are.
On May 19, 3:30 am, Dennis <dennisf...@gmail.com> wrote:
> I looked into python multi-threading / multi-processing a bit more,
> especially with your tip that it requires python 2.7.
>
> concurrency above 1 request / instance.
> This solution copies and spawns processes which are heavier than threads.
> I'm assuming that most of the concurrency will be achieved because processes
> are datastore bound:
> they are just waiting around for the datastore to return a result.
>
> Given this type of solution (or whatever solution is used), some important
> questions are:
>
> (and thus concurrency) dependent mainly on the number of processes that can
> fit in memory?
> requests / instance be (for the simplest django app, then we can add in our
> own app's memory usage)?

Albert
have an
instance up for 5 minutes, what am I charged, $0.08 / 60*5?
A: Instances are charged for their uptime and until they are idle for
15
minutes (when the scheduler takes them down). So if you have an on-
demand
Instance only serving traffic for 5 minutes, you will pay for 5+15
minutes,
or $0.08 / 60 * 20 = 2.6 cents."
free? Technically, it's idle, and we didn't get to use it.
If that's not possible, could you allow us to configure how much idle
time is allowed before an idle instance is taken down?
Thanks!
Albert
Jeff Schnitzer
> Put some ads on it and it should get to the $9 a month. Put a donate button
> on it.
It's never that simple, and certainly isn't in this case.
That said, Google certainly doesn't owe anyone a free service layer,
nor a linear ramp-up to paid service. And apps around the limit of
the free service tier are probably something to discourage since they
actually consume resources. Still, I'm more likely to contribute
*some* money for my forlorn projects if the cost was not a
discontiguous function.
Jeff
Brandon Wirtz
have a revenue stream. Especially if you thought it was going to be a
commercial venture. And this is cold hearted but if you have loyal users
who are using the app that much and none of them will pony up $.50 a
month... That's rough.
The Reason I don't think anyone should complain about the $9 number is that
anyone should be able to put Adsense on their app and make $9.
I may be biased, but I have an App that averages a penny a day right now,
and generates $2500 a month in Adsense. There has to be some economic model
that works between my extreme and yours.
-----Original Message-----
From: google-a...@googlegroups.com
[mailto:google-a...@googlegroups.com] On Behalf Of Jeff Schnitzer
Sent: Thursday, May 19, 2011 12:10 AM
To: google-a...@googlegroups.com
Subject: Re: [google-appengine] Re: FAQ for out of preview pricing changes
Jeff
--
Jeff Schnitzer
this particular app are iPhone clients, and the developer responsible
for that code has moved on to other projects.
...and actually, there does seem to be a vast chasm between successful
apps and unsuccessful ones. I'm not entirely certain why. It may
partly be due to the fact that no payment system in the world lets you
charge $0.50/mo.
Jeff
Brandon Wirtz
It has a front end... if there is a front end you can stick ads there...
Yeah iphone sucks for ad revenue....Have you considered that "Other" mobile
OS, the one from Google?
;-)
Vinuth Madinur
Kngt
Stressing a point made here by Mike Wesner: is the memory limit on
(frontend) instances being cut down to 128mb? As far as I know, there
was no formal documentation of an instance's memory limit before, but
the "soft limit" error was usually triggered at around 180mb. Should
be expect this behavior to change?
Kind regards,
H.E.
On May 18, 7:49 am, "Gregory D'alesandre" <gr...@google.com> wrote:
> Hello All!
>
> As you've likely heard, when Google App Engine leaves Preview in the second
> half of 2011, the pricing model will change. Prices are listed here:http://www.google.com/enterprise/appengine/appengine_pricing.html. But that
> leaves a lot of questions unanswered, this FAQ is intended to help answer
> some of the frequently asked questions about the new model. We are
> interested in hearing additional thoughts and comments you have based on
> this. Once it is relatively stable I'll add it to our official docs. If
> you find there is something you want to know but it is not yet answered,
> just ask and I'll try to answer it as clearly as possible. We've made some
> changes based on the feedback we've gotten (from this group in particular),
> they are bolded below but not updated on the external pages yet. There are
> still blanks to fill in and I will be sending that information to this group
> first in order as it is available. Finally, thank you for your questions
> and bearing with us as we are ironing out details, I and the whole App
> Engine team very much appreciate it.
>
> Greg D'Alesandre
> Senior Product Manager, Google App Engine
>
> -------------------
>
> *Instance*: A small virtual environment to run your code with a reserved
> actions.
> needed.
>
> complete. This can significantly lower the number of Instances your app
> requires.
>
> Q: Will there be a solution for Python concurrency? Will this require any
> code changes?
> Python concurrency will be handled by our release of Python 2.7 on App
> Engine. We’ve heard a lot of feedback from our Python users who are worried
> that the incentive is to move to Java because of its support for concurrent
> requests, so we’ve made a change to the new pricing to account for
> providing a half-sized instance for Python (at half the price) until Python
> instance up for 5 minutes, what am I charged, $0.08 / 60*5?
> A: Instances are charged for their uptime and until they are idle for 15
> minutes (when the scheduler takes them down). So if you have an on-demand
> Instance only serving traffic for 5 minutes, you will pay for 5+15 minutes,
> or $0.08 / 60 * 20 = 2.6 cents.
>
> able to purchase Frontend Instances that use different amounts of memory?
>
> A: Yes.
>
> Q: Can the experimental Go Runtime handle concurrent requests?
> A: Not currently.
>
> *Costs*
> Q: Is the $9/app/month a fee or a minimum spend?
> A: *Based on the feedback we’ve received we are changing this $9 fee to be a
> minimum spend rather than a fee a originally listed*. In other words you
> will still have to spend $9/month in order to scale but you won’t pay an
> additional $9 for your first $9 worth of usage each month. The
> $500/account/month will still be a fee as it covers the cost of operational
> support.
>
> Q: Will most customers have to move to Paid Apps?
> A: No, we expect the majority of current active apps will still fall under
> the free quota.
>
> Q: Will existing apps be grandfathered in and continue under today’s billing
> model?
> A: No, existing apps will fall under the new billing model once App Engine
> is out of preview.
>
> Q: Will most customers’ bills increase? If so, why is Google increasing the
> price for App Engine?
> A: Yes, most paying customers will see higher bills. During the preview
> phase of App Engine we have been able to observe what it costs to run the
> product as well as what typical use patterns have been. We are changing the
> prices now because GAE is going to be a full product for Google and...
>
> read more »
Brandon Wirtz
While we may have varied from original topic of the thread, it is very relevant.
For $9 who would you run instead? How much hosting would that buy you at DreamHost? Or Amazon Or Rackspace. Same question at $50, and $500
Most solutions have sweet spots in pricing, and as one of the larger consumers of GAE, I should be one of the most irate about the price increase, and after the FAQ, and some concessions that were made with smaller instances for Python… I’m not sweating it. Would I have been happier with a pricing model that was 30% less, or charged for my memory rather than my Instance… Yeah, but I think Google did the fairest thing they could do, suck a little more out of everyone about equally. Probably me more than most because My App is so far from what the expected use case was that I was practically a free loader before this.
I don’t look to pick fights when I say “$9 is nothing you can make that back” I don’t mean that as a smack to your personal model, I mean with a sense of reality. Do you think Google Gives Chrome away for free because they are nice people? They are in it to make money. “Free samples are now limit one per customer” doesn’t seem like a bad change when so many people (me included) were making a lunch of them and not buying anything more than a pack of gum on the way out.
But Google isn’t going to make money on a $9 account, to make it work YOU have to graduate to being a $150, 300, 500, and $5000 a month account. (“There is no payment service that will let you bill $.50 a month”) the amount of time Greg and Ikai and all the Googlers put in to this forum likely costs more than our combined bills. I know that that support they have given me personally wouldn’t cover my monthly spend, and I suspect I’m in the upper 1% of spenders.
When the NPO’s say they aren’t able to come up with the $9 I feel bad for them. The rest of us. No. If we build an app it should either be “fun” and we don’t care about the $120 a year, or it should be break even or better. I know there are quite a few Berkley Grads at Google, but it aint no hippy commune. This is capitalism and that’s what drives innovation.

Paul
Thing is, people want too much for free. $9 is less than you pay for
internet at home, hosting anything at Google is cheaper than putting
old PC in the basement :)
I hope that going out of preview will mean even more tools and toys
for us. Better documentation, better plugins [how about working on
DataNucleus? current plugin is really really outdated]...
Vinuth Madinur
Vinuth Madinur
Stephen
>
> For $9 who would you run instead? How much hosting would that buy you at
> DreamHost? Or Amazon Or Rackspace. Same question at $50, and $500
At Amazon, $500 would buy $500 worth of hosting, $50 would buy $50
worth of hosting, and crucially, $5 would buy $5 worth of hosting and
$1 would buy $1 worth of hosting.
The phrase they like to use is:
"Pay for only for what you use. There is no minimum fee... We
charge less where our costs are less..."
eg. here: http://aws.amazon.com/s3/#pricing
Under the new pricing scheme $1 worth of hosting will cost $9 and $5
worth of hosting will cost $9. $100 worth of hosting will cost $100.
Established projects get full value for money and fledgling web
startups get overcharged, exactly at the point where they need the
most support.
The smaller you are the more you are overcharged. Projects who use $5
of resources are only overcharged 2x where as projects who use $1 of
resources are overcharged nearly 10x.
> Most solutions have sweet spots in pricing, and as one of the larger
> consumers of GAE, I should be one of the most irate about the price
> increase
It is just the opposite. As your project has progressed beyond using
$9 worth of resources you get full value for your spend. The $9
minimum does not affect you at all.
> Do you think Google Gives Chrome away for free because
> they are nice people? They are in it to make money.
I don't think people are saying App Engine should be free. They are
saying a strategically important group of people to Google - web
projects at a critical early stage - would like to pay $5 for $5 worth
of resources, just as enterprise users are charged $100 for $100 worth
of resources.
> But Google isn’t going to make money on a $9 account, to make it work YOU
> have to graduate to being a $150, 300, 500, and $5000 a month account.
The nature of the automated, shared-resource App Engine service is
that Google makes just as much money, percentage wise, from customers
who pay $5000/month as $150/month. That also applies to $5 and $1
spends, or at least it would if they were not overcharged 2x and 10x.
> (“There is no payment service that will let you bill $.50 a month”)
Many times in the past people have said that they would be happy to
pre-pay for service to avoid the issue where the CC charge is more
than the resources used. People are happy to pay for what they use and
keen to reduce Google's costs just as much as their own.
> When the NPO’s say they aren’t able to come up with the $9 I feel bad for
> them.
That's very kind of you, but it's not about charity. Many small
projects, for example web startups, are keen to pay for what they use
and would be affected by being overcharged up to 10x in the early
stages.
The fragility of early stage projects is widely understood - people
talk about becoming 'ramen profitable', ie. making just enough money
to continue by eating MSG flavoured noodles. Larry and Sergey got
their start by building servers out of Lego and cork floor tiles and
pinching hard drives from other departments. From there they
progressed into a garage.
It is unnecessary and counter-productive to have a regressive pricing
scheme for App Engine, and someone at Google needs to get creative and
fix this. Here's a suggestion:
Add a checkbox to the billing screen, default on, that disables the
SLA. Any self respecting MBA running Important Enterprise Projects is
unlikely to opt out of the SLA, and an SLA is useless to a startup
spending less the $9/month, thereby preserving the market segmentation
of enterprise projects and web projects.
Vinuth Madinur
--
nickmilon
This is what I also proposed :
"(Pricing policy should be) ..... start up and small business
friendly. That used to mean a smooth gradual transition path between
free and per use paying system. New policies destroy this by
drastically lowering the quota on free package and steeply raising the
entrance fee of a paying account. This gap has to be bridged somehow.
I am not talking about the $9 per month fee which is reasonable but
the accumulating costs of instances running, datastore operations
quota etc.. Perhaps a step to this direction that can be considered is
the introduction of an intermediate pricing level between free and
fully paying applications for developers who are not really ready for
prime time and do not need an SSL certificate neither an SLA
contract."
see here:
http://goo.gl/PfRZC
Nick Milon
On May 19, 2:31 pm, Stephen <sdeasey+gro...@gmail.com> wrote:
Rafael Nunes

Barry Hunter
If there is no instance running, one will have to be spun up, adding
(possibly significant) delay to the next request.
With 15 minutes Google appear to be offering a compromise. It's
probably not totally arbitrary number, but based on something like
'average time between requests' on a lowish traffic website.
Also spinning up an instance isn't free (for Google) - eg your
codebase has to be transferred to the node (unless it already has it)
- so the 15 minutes delay is in part a 'spin up fee' - to cover the
cost of instance startups.

Wendel
1 (primary) 15 minutes idle or always up.
2 (secondary instances) 5 minutes or less.
Also if the scheduler starts a secondary instance which during its lifetime only processes 1 or 2 requests then the scheduler made a misprediction.
Stephen
>
> With 15 minutes Google appear to be offering a compromise.
This is the problem: they haven't fixed anything they've merely
shifted the burden by compromising.
Under the current scheme, as Greg explained, full-fat Java Enterprise
apps which take 25 seconds just to initialize and therefore can't be
killed and restarted quickly take up memory which Google hadn't
accounted for. Under the new scheme where time is charged in blocks of
15 minutes the burden has been shifted from Google to writers of
efficient Python and Go apps -- Enterprise Java apps are still free
riding.
It can't possibly be in Google's best interest to have
the-next-big-thing scrappy startup subsidising Big Co's legacy TPS
reports.
How about this:
Expose a scheduler tuning knob, default off, which when enabled
reduces the kill-timeout from 15 mins to 20 seconds, and the
deadline-exceeded timeout to 20 seconds. This would be completely
unworkable for the average full-fat Java app so Enterprise customers
will not enable it, but an efficient Python app which starts in 100ms
or a compiled, statically linked Go app which starts in 20ms can be
started and stopped efficiently by the original scheduler algorithm
and be charged in units of 20 seconds. The new backends feature is now
available for anyone how needs more resources.
Barry Hunter
The 'old' way, pretty much promoted low cpu use, even if that came at
the expense of latency. The slow requests, would necessitate lots of
instances - costing Google.
The 'new' way promotes keeping your latency down. Quick requests gives
higher queries per second (per instance). Meaning less instances.
By charging for actual instance usage, they are promoting keeping the
number of instances down.
So the developer should aim to keep the number of instances down -
saving money.
People who need, want, (or can't be bothered to optimise to avoid),
slow requests will pay - closer to what it actully costs Google.
Google dont want you spinning up instances, and tearing them down
quickly. Its that spinning up, that 'costs'. Rather then charge you 15
minutes 'overtime' they, could just change $0.02 per instance started
(as a fee). Same result.
(And in the shorter term, there is also compensation offered for lack
of multi threading/processing in python)

Kenneth
Vinuth Madinur
As a non Google person and someone was pretty shocked about the price changes I have to say you're over-reacting.If your application has a average latency of 250ms (which is quite high imho) you can get 345,600 hits per day on the free tier, apparently forever. If you're getting that kind of traffic $9 per month shouldn't be a burden, although granted it doesn't account for traffic spikes. And for the $9 you get an extra 6 hours of instance usage per day which gives you another 86,400 hits. That doesn't even include static pages.
Stephen
> Well yes, they have shifted the 'burden' but I see it in a different way.
>
> The 'old' way, pretty much promoted low cpu use, even if that came at
> the expense of latency. The slow requests, would necessitate lots of
> instances - costing Google.
>
> The 'new' way promotes keeping your latency down. Quick requests gives
> higher queries per second (per instance). Meaning less instances.
No, the way it currently works is if your apps latency > 1000ms
(figures of 800-900ms have also been mentioned) it won't scale. The
lower the latency the more they scale it. So the incentive has always
been to write low latency apps.
The new scheme promotes low cpu usage just as much as the current
scheme, as shown in Greg's formulae.
There's no real change here.
> By charging for actual instance usage, they are promoting keeping the
> number of instances down.
Here's the change: they're not charging for instance usage, they're
charging for usage +15 mins. You can argue that the +15mins is a cost
recovery mechanism for resources used during instance startup, but
there is a large difference between a Java app which takes 25 seconds
to initialize itself and a a compiled, statically linked Go app which
is ready in a few 10s of ms.
So inefficient Java apps are being undercharged, so Google is adding
+15mins to the billing, even if you're not an inefficient Java app, so
now efficient apps are being overcharged.
> Google dont want you spinning up instances, and tearing them down
> quickly. Its that spinning up, that 'costs'.
Starting up and shutting down is the 'auto' in auto-scaling, which is
a premier feature of Google App Engine. It may 'cost' to startup, but
it doesn't cost the same for an efficient Go app as an inefficient
Java app, yet they're charged the same 15mins, and therefore modern
efficiency is subsidising legacy bloat.
Barry Hunter
> On Thu, May 19, 2011 at 4:17 PM, Barry Hunter <barryb...@gmail.com> wrote:
>> Well yes, they have shifted the 'burden' but I see it in a different way.
>>
>> The 'old' way, pretty much promoted low cpu use, even if that came at
>> the expense of latency. The slow requests, would necessitate lots of
>> instances - costing Google.
>>
>> The 'new' way promotes keeping your latency down. Quick requests gives
>> higher queries per second (per instance). Meaning less instances.
>
>
> No, the way it currently works is if your apps latency > 1000ms
> (figures of 800-900ms have also been mentioned) it won't scale. The
> lower the latency the more they scale it. So the incentive has always
> been to write low latency apps.
For practical purposes yes - to be able to scale.
But not from cost. If you where using your cpu over 10 instances,
costs roughly the same as using that cpu on two instances.
>
> The new scheme promotes low cpu usage just as much as the current
> scheme, as shown in Greg's formulae.
>
> There's no real change here.
>
>
>> By charging for actual instance usage, they are promoting keeping the
>> number of instances down.
>
>
> Here's the change: they're not charging for instance usage, they're
> charging for usage +15 mins. You can argue that the +15mins is a cost
> recovery mechanism for resources used during instance startup, but
> there is a large difference between a Java app which takes 25 seconds
> to initialize itself and a a compiled, statically linked Go app which
> is ready in a few 10s of ms.
Startup time is irrelevant. Its its ongoing usage that is important.
>
> So inefficient Java apps are being undercharged, so Google is adding
> +15mins to the billing, even if you're not an inefficient Java app, so
> now efficient apps are being overcharged.
An efficient app, doesnt even need a new instance.
inefficient apps (ie high latency) will need more instances to serve
the same traffic. So they pay for those resources.
>
>
>> Google dont want you spinning up instances, and tearing them down
>> quickly. Its that spinning up, that 'costs'.
>
>
> Starting up and shutting down is the 'auto' in auto-scaling, which is
> a premier feature of Google App Engine.
It's still there, just far less granular. Do more with less instances.
> It may 'cost' to startup, but
> it doesn't cost the same for an efficient Go app as an inefficient
> Java app, yet they're charged the same 15mins, and therefore modern
> efficiency is subsidising legacy bloat.
Its not the cost of the "application" starting in the instance itself
(which will depend on the application, and even the runtime to an
extent). The time (1-25 seconds) starting the app, is irrelevant in
the terms of a instance lifetime.
But the very cost of starting the instance itself (before any code is
run) - as mentioned getting the code to the instance (potentially 3000
files), even things like identifing a suitable node to run it on.
Maybe the scheduler has to bring online more nodes. Not details you
have to worry about, granted. So its just hidden behind the 'instance
fee'
Kenneth
Wendel
It is not free, the ones who use a paid account have to cover the costs of the free ones as well. It is how their and AWS business model works.
So if you want more for free, then the billing prices go up, not a good idea..and not fair.
Brandon Wirtz
>The 50k free database operations is a bit more nebulous since Google are still scratching their heads over it. With correct memcache usage it really should be enough, although that might be a bit of wishful thinking and obviously depends significantly on your use case.
As reference…
Datastore API Calls |
| 0% | 183,470 of Unlimited | Okay |
Memcache API Calls |
| 0% | 323,702 of Unlimited | Okay |
Twice as many memcache calls as data store. This is pretty consistent across my apps.
My average Entity is about 5k… (this says a little lower)
Entity Kind | # Entities | Avg. Size/Entity | Total Size | |
Kind1 | 627,354 | 4 Kbytes | 2 GBytes |
Every request I have uses potentially:
Configuration load: 1 memcache read OR 1 datastore read and 1 memcache write
Get Content: 1 memcache Read, OR 1 datastore Read, 1 Memcache Write, OR 1 DataStore Write, 1 Memcache write
I don’t know if this helps anyone, but I’m always interested in how apps use their quotas, so I thought I would share.
Jeff Schnitzer
> On 19 May 2011 17:31, Stephen <sdeasey...@gmail.com> wrote:
>>
>> No, the way it currently works is if your apps latency > 1000ms
>> (figures of 800-900ms have also been mentioned) it won't scale. The
>> lower the latency the more they scale it. So the incentive has always
>> been to write low latency apps.
>
> For practical purposes yes - to be able to scale.
>
> But not from cost. If you where using your cpu over 10 instances,
> costs roughly the same as using that cpu on two instances.
I think there's something that needs to be mentioned in discussions like this:
High-latency requests don't scale *on appengine* because of specific
design decisions made by Google. High-latency requests scale just
fine on other platforms - the folks running
Node.js/Tornado/EventMachine/etc have no problem whatsoever with tens
of thousands of latent requests. Even traditional java appservers
handle latency with acceptable limits - depending on what you're
doing, you can get away with hundreds or even thousands of concurrent
requests per JBoss instance.
There is a terrific amount of price signaling going on in this change.
It indicates that:
* Memory is precious, CPU time is almost irrelevant.
This is not too surprising; if you look at the rest of the cloud
industry, almost all services are priced by the amount of RAM used and
make no mention of how much CPU is allocated.
Unfortunately all past price signaling has indicated to us just the
opposite, and we have designed our applications around that. And
unfortunately it turns out that GAE is *absurdly* inefficient about
RAM usage. I have no doubt that Google will eventually address this
issue - they will have to if they want to attract & retain customers -
but in the mean time, it's going to hurt.
Jeff
Vinuth Madinur
As far as I know the Blobstore has never been available to free apps and now they're giving you 5gigs free, seems like a pretty big win to me.
The 50k free database operations is a bit more nebulous since Google are still scratching their heads over it. With correct memcache usage it really should be enough, although that might be a bit of wishful thinking and obviously depends significantly on your use case.
Stephen
>
> There is a terrific amount of price signaling going on in this change.
> It indicates that:
>
> * Memory is precious, CPU time is almost irrelevant.
>
> This is not too surprising; if you look at the rest of the cloud
> industry, almost all services are priced by the amount of RAM used and
> make no mention of how much CPU is allocated.
http://aws.amazon.com/ec2/instance-types/
CPU/RAM ratio seems pretty linear.

Calvin
Robert Kluin
Will we be able to adjust the scheduler for each version of our
application? Two use-cases come to mind: 1) different options for
Python / Go / Java versions of an app, and 2) different options for
'front-end' versions serving user traffic and processing tasks. Would
be nice so that we could insure a version servicing user-requests get
instances allocated very readily, but that a version handling backend
processing does not spin up new instances for small bursts.
Robert
On Wed, May 18, 2011 at 00:49, Gregory D'alesandre <gr...@google.com> wrote:
> Hello All!
> As you've likely heard, when Google App Engine leaves Preview in the second
> half of 2011, the pricing model will change. Prices are listed here:
> http://www.google.com/enterprise/appengine/appengine_pricing.html. But that
> leaves a lot of questions unanswered, this FAQ is intended to help answer
> some of the frequently asked questions about the new model. We are
> interested in hearing additional thoughts and comments you have based on
> this. Once it is relatively stable I'll add it to our official docs. If
> you find there is something you want to know but it is not yet answered,
> just ask and I'll try to answer it as clearly as possible. We've made some
> changes based on the feedback we've gotten (from this group in particular),
> they are bolded below but not updated on the external pages yet. There are
> still blanks to fill in and I will be sending that information to this group
> first in order as it is available. Finally, thank you for your questions
> and bearing with us as we are ironing out details, I and the whole App
> Engine team very much appreciate it.
> Greg D'Alesandre
> Senior Product Manager, Google App Engine
>
> -------------------
> Definitions
> Instance: A small virtual environment to run your code with a reserved
> amount of CPU and Memory.
> Frontend Instance: An Instance running your code and scaling dynamically
> based on the incoming requests but limited in how long a request can run.
> Backend Instance: An Instance running your code with limited scaling based
> on your settings and potentially starting and stopping based on your
> actions.
> Scheduler: Part of the App Engine infrastructure that determines which
> Instance should serve a request including whether or not a new Instance is
> needed.
>
> Serving Infrastructure
> lot of requests. Also, Java apps support concurrent requests, so it can
> handle additional requests while waiting for other requests to complete.
> This can significantly lower the number of Instances your app requires.
>
> Q: Will there be a solution for Python concurrency? Will this require any
> code changes?
> Python concurrency will be handled by our release of Python 2.7 on App
> Engine. We’ve heard a lot of feedback from our Python users who are worried
> that the incentive is to move to Java because of its support for concurrent
> requests, so we’ve made a change to the new pricing to account for that.
> While Python 2.7 support is currently in progress it is not yet done so we
> will be providing a half-sized instance for Python (at half the price) until
> Python 2.7 is released.
>
> Costs
> Q: Is the $9/app/month a fee or a minimum spend?
> A: Based on the feedback we’ve received we are changing this $9 fee to be a
> minimum spend rather than a fee a originally listed. In other words you
> will still have to spend $9/month in order to scale but you won’t pay an
> additional $9 for your first $9 worth of usage each month. The
> $500/account/month will still be a fee as it covers the cost of operational
> support.
>
> Q: Will most customers have to move to Paid Apps?
> A: No, we expect the majority of current active apps will still fall under
> the free quota.
>
> Q: Will existing apps be grandfathered in and continue under today’s billing
> model?
> A: No, existing apps will fall under the new billing model once App Engine
> is out of preview.
>
> Q: Will most customers’ bills increase? If so, why is Google increasing the
> price for App Engine?
> A: Yes, most paying customers will see higher bills. During the preview
> phase of App Engine we have been able to observe what it costs to run the
> product as well as what typical use patterns have been. We are changing the
> prices now because GAE is going to be a full product for Google and
> therefore needs to have a sustainable revenue model for years to come.
>
> APIs
> Q: How were the APIs priced?
> A: For the most part the APIs are priced similarly to what they cost today,
> but rather than charging for CPU hours we are charging for operations. For
> instance the Channel API is $0.01/100 channels. This is approximately what
> users pay today (although it would be paid as a fraction of a CPU hour).
> The datastore API is the most significantly changed and is described below.
>
> Q: For the items under APIs on the pricing page that just have a check, what
> does that mean?
> A: Those items come free with using App Engine.
>
> Q: For XMPP, how does the new model work? How much do presence messages
> cost?
> A: For XMPP we will only be charging an operation fee for outgoing stanzas.
> Incoming stanzas are just considered requests similar to any other request
> and so we’ll charge for the bandwidth used as well as whatever it takes to
> process the request in terms of Instance Hours. We don’t charge for
> presence messages other than the bandwidth it consumes. This is almost
> exactly how it works today with the exception that your bill would show CPU
> hours as opposed to Stanzas.
>
> Q: For Email, how much do incoming emails cost?
> A: Incoming emails will just be considered requests similar to any other
> request and so we’ll charge for the bandwidth used as well as whatever it
> takes to process the request in terms of Instance Hours. This is in essence
> how it works today.
>
> Q: Will the Front End Cache feature ever be formalized as an expected,
> documented part of the service offering?
> A: We are currently looking at various options, but don’t yet have any plans
> for when this would happen.
>
> Q: What is being charged for in terms of Datastore operations? What do you
> expect the ratio to be between the new pricing metric and the Datastore API
> calls metric we have today?
> A: Today we charge for the CPU consumed per entity written, index written,
> entity read, query index scanned, and query result read. Under the new
> model we will charge per operation rather than CPU, and we will no longer
> charge for query index scans. This means the cost of your queries will be
> tied exclusively to the size of your result set. We expect the cost of
> these operations will be approximately 4x the cost of the equivalent CPU
> under today’s model, but for apps that make heavy use of indexes, this will
> be somewhat offset by the fact that we will no longer be charging for query
> index scans. The admin console today shows total Datastore API Calls, but
> this is not a good gauge of how many operations you will be charged for
> under the new model. Your costs will be highly dependent on the types and
> contents of your API calls, not the number of calls themselves, which is
> what we currently display. For example a single get() API call may retrieve
> 1 Entity or 100 Entities, and a beginTransaction() API call doesn’t consume
> any billable resources.
>
> Q: Could emails sent to admins be cheaper or free?
> A: That’s a possibility that we can look into.
>
> Usage Types
> Q: What does the Premier cost of "$500/account" mean? Per Google Apps
> Account? Per Developer Account, Per Application Owner Account?
> A: It is per Organization (which would translate into per Google Apps
> account if you are currently a Google Apps customer). So, for instance if
> you are working at gregco.com and you signed up for a Premier account,
> gregco.com users will be able to create apps which are billed to the
> gregco.com account.
>
> Q: Will there be special programs for non-profit usage?
> A: Possibly, we are currently looking into this.
>
> Q: Will there be special programs for educational usage?
> A: Possibly, we are currently looking into this.
>
> Q: Will there be special programs for open-source projects?
> A: Possibly, we are currently looking into this.
>
> Usage Limits
> Q: If I migrate to HR Datastore, does that mean I have a "newly created"
> application, and will get the new, lower, free quota for email? Could you
> grandfather in migrated apps at the old 2000 limit?
> A: Yes, we can grandfather in the email quota for HRD apps that are
> migrating from M/S apps.
Dennis
lower the latency the more they scale it. So the incentive has always
been to write low latency apps.
Jeff Schnitzer
--
Dennis
Vinuth Madinur
To be clear, the 10GB of charity storage is only valid for the first 12 months for new customers.http://aws.amazon.com/free/
Dennis Fogg
--
Jeff Schnitzer
http://www.linode.com/index.cfm
http://www.rackspace.com/cloud/cloud_hosting_products/servers/pricing/
http://www.slicehost.com/
http://prgmr.com/xen/
And for kicks, here's a peformance comparison (conclusion: "EC2 sucks"):
http://journal.uggedal.com/vps-performance-comparison/
Jeff
Stephen
> On Thu, May 19, 2011 at 11:15 AM, Stephen <sdeasey...@gmail.com> wrote:
>> On Thu, May 19, 2011 at 7:04 PM, Jeff Schnitzer <je...@infohazard.org> wrote:
>>>
>>> This is not too surprising; if you look at the rest of the cloud
>>> industry, almost all services are priced by the amount of RAM used and
>>> make no mention of how much CPU is allocated.
>>
>> http://aws.amazon.com/ec2/instance-types/
>>
>> CPU/RAM ratio seems pretty linear.
>
> http://www.linode.com/index.cfm
> http://www.rackspace.com/cloud/cloud_hosting_products/servers/pricing/
> http://www.slicehost.com/
> http://prgmr.com/xen/
I wonder if the above don't mention cpu because it is ample and nobody
cares, or they are skimping and don't want to highlight it. Seems like
they divide the box according to ram, and whatever portion that is,
you get a similar portion of the box's cpu. If they're buying the same
boxes as everyone else it probably works out the same.
Anyway, if Google's primary concern is ram the new pricing scheme
still discriminates against efficiency. Sure, charging by instance
uptime accounts for large idle instances, but many Python apps manage
with 15MB where as an Enterprise Java app might need 75-100MB.
Maybe they should charge for ram? Greg:
Calvin
Brandon Wirtz
Depends on the amount of static content… I serve static out of GAE because it is faster than S3 and about the same price depending on your tier.
--

Tim
On Thursday, 19 May 2011 19:42:17 UTC+1, Jeff Schnitzer wrote:
Yeah, the people building small-scale apps shouldn't worry about the instance quota. They should worry about the "datastore operations" quota.
Vinuth Madinur
But how much would it cost to have multiple EC2 instances serving the content along with S3 hosting the content? A single micro instance running for a month would be $14.So what you could do is host static content in S3 and host the app in App Engine and save both ways.
Jeff Schnitzer
> On Thu, May 19, 2011 at 7:55 PM, Jeff Schnitzer <je...@infohazard.org> wrote:
>>
>> http://www.linode.com/index.cfm
>> http://www.rackspace.com/cloud/cloud_hosting_products/servers/pricing/
>> http://www.slicehost.com/
>> http://prgmr.com/xen/
>
> I wonder if the above don't mention cpu because it is ample and nobody
> cares, or they are skimping and don't want to highlight it. Seems like
> they divide the box according to ram, and whatever portion that is,
> you get a similar portion of the box's cpu. If they're buying the same
> boxes as everyone else it probably works out the same.
If that performance comparison is accurate, it seems that EC2 is the
one skimping. The difference in performance between Linode and EC2 is
staggering... 2-6 times the performance for cpu-bound activities.
> Anyway, if Google's primary concern is ram the new pricing scheme
> still discriminates against efficiency. Sure, charging by instance
> uptime accounts for large idle instances, but many Python apps manage
> with 15MB where as an Enterprise Java app might need 75-100MB.
Interesting point. But even if a Java appserver requires 6X the RAM,
it will be more efficient if concurrency is higher than 6 (presuming
the process isn't cpu-bound - which very few frontend apps are). And
while most python apps may stay under 30M, not all do.
> Maybe they should charge for ram? Greg:
>
> Q: You seem to be trying to account for RAM in the new model. Will I
> be able to purchase Frontend Instances that use different amounts of
> memory?
> A: We are only planning on having one size of Frontend Instance.
It is an interesting question. On the other hand, I prefer a simpler
billing and development model. I would hate to have to run a bunch of
tests to measure exactly how small an instance will fit my app... one
of the nice things about GAE is how it takes these infrastructurey
problems off of my list of concerns.
Jeff
nickmilon
I would question any comparisons that ends like "If you’re going to
buy a VPS I’d appreciate it if you used my referral page for Linode or
for Slicehost when doing so."
I would prefer a "donate button" and most probably I would contribute.
Nick Milon
On May 19, 9:55 pm, Jeff Schnitzer <j...@infohazard.org> wrote:
> On Thu, May 19, 2011 at 11:15 AM, Stephen <sdeasey+gro...@gmail.com> wrote:
>
> >> This is not too surprising; if you look at the rest of the cloud
> >> industry, almost all services are priced by the amount of RAM used and
> >> make no mention of how much CPU is allocated.
>
> >http://aws.amazon.com/ec2/instance-types/
>
> > CPU/RAM ratio seems pretty linear.
>

Will
Here is my experience:
1. I looked at GAE and AWS, GAE won hands down because of its lower price and zero system administrative overhead.
2. I put my business on it seriously.
3. In this three years, Google has got a good sense of what GAE is really like because so many people have spent time building apps on it. I would guess many are like me, lower price is a major factor.
4. Now it is making a drastic price increase.
The point is not totally about the price, it is about the magnitude of the price increase, to a point that it invalidates the original assessment that GAE being a winning platform, only after my apps and yours have been on it for a while. It is about fairness and trust, to some extend.
Does AWS or Azure have similar lengthy 'preview' phase and a big price increase at the end? I don't recall.
Best,
Will
nickmilon
AWS vs Rackspace vs any_other_VPS_service_on_earth.
There was not such big talk before, coz App Engine looked different
from those products both in terms of pricing as well as features.
Now, thanks to latest news, it managed to be transformed to
Yet_An_Other_VPS overnight and I can not blame developers for those
comparisons.
To tell you the truth I have seen that coming ever since I show SQL
databases on the roadmap.
IMHO these are signs that we are on the wrong path, but .... then
again who am I to give advice ?
Happy coding;)
Jeff Schnitzer
Slicehost performed very poorly - worse than EC2 in most tests. Most
likely, he mentions the referral page for Linode and Slicehost because
they are the only providers that offer an affiliate program.
In the absence of any reason to doubt his statistics, I'll take them
at face value. That said, they're 1.5 years old now. The hybrid part
of one of my GAE applications is CPU-intensive, and when/if it hits
scale I will be doing a fair amount of this research on my own.
Jeff
nickmilon
No bad intentions neither for his objectivity nor your findings.
I just wanted to say that product - comparison publications should not
depend on products/services compared for an income, it is a matter of
principle.
I would be grateful if you could possibly share your own tests
Nick

Raymond C.

Greg
there will still be a free tier.
So our proverbial web developer can tinker around with her app for as
long as she wants, at no cost. Once SHE decides to, she can avail
herself of scalability and an SLA for $9 a month, which seems very
reasonable to me.
If her app needs more resources and she can't afford $9 a month, then
her app is not financially sustainable and will die. A shame, but it
has to happen. Otherwise hundreds of thousands of unsustainable apps
will consume infrastructure and support resources, and increase the
cost for everyone else.
To those still bellyaching over $9, maybe you should build your own
server. Invest probably $1000 for hardware, $50 a month for internet
connection, and however many hours it takes to manage the machine. And
you can host all the other people's apps for free - or is it only
Google who should give away app hosting for free?
Or of course you could switch to AWS. Don't forget you'll need two
instances in different regions for redundancy, and the cost of
bandwidth between them to synchronise, and you still need to put in
quite a lot of time managing it all... does $9 seem reasonable now?
There is still a lot of dust in the air - we don't know how the new
scheduler will work, and it may be that Python 2.7 and multiple
threads suddenly makes everything ten times cheaper. We really don't
know what the new costs will be until we get comparison billing. But
after all is said and done, I'm still glad I built my apps on
Appengine, and I'm glad Google are making it more commercially
sustainable.
Jeff Schnitzer
1) High-level decisionmakers inside Google are reading this thread.
2) Early input has greater potential influence than later input,
especially after a ton of billing code has been written and the
"momentum" of a big ship like Google has been established.
3) We here, right now, we're the focus group. There is no better time
to speak up about your concerns. The chances of your fears
materializing are much higher if you don't ask about them. "Wait and
see" is a recipe for disappointment (in life).
We've already seen one major change (half-price Python) which is a
tacit acknowledgement that the single-threaded model may be a
significant problem. My goal by "bellyaching" is not to haggle the
lowest possible price out of appengine, but to get a competitive,
sustainable, cost-effective platform that makes both Google's
accountants and my accountants (and my clients' accountants) happy.
There are two risks - one is that Google unsustainably underprices
appengine, the other is that Google unsustainably overprices
appengine. If it turns out that because of low levels of concurrency
these two overlap, we *all* have very big problems.
In my mind, the biggest risk to the success of GAE is an architectural
issue that you and I have no control over. The new pricing model is
largely symptomatic of a deeper problem, and it won't do Google any
good if the sustainable price is so high that the market flees. An
instance on GAE may cost the same per hour as an "instance" somewhere
else, but of that other instance can do 10X the work in the same hour,
the market will eventually figure out that GAE isn't a very good deal.
By the way, I *do* run several VPS servers with non-GAE projects -
some of which predate my love affair with appengine. It's a fixed
outlay, but has the advantage that I can stack additional projects on
it for nearly no marginal cost. It won't cost me an additional $9/mo
to build another project on it.
At any rate, I place a lot of trust in the people behind appengine -
every one I've met has been super smart, engaged, and genuinely
interested in building what I still think is the coolest thing on the
internet. But they won't succeed in doing that without lots of
customer feedback, so bellyache (constructively) as loud as you can as
long as they're willing to listen...
Jeff
Jeff Schnitzer
off of Backends (formerly "servers") to a VPS host because the
finalized pricing (not hypothetical - what you pay right now) is more
than six times what it costs elsewhere. The risk of being priced off
GAE is real.
Jeff

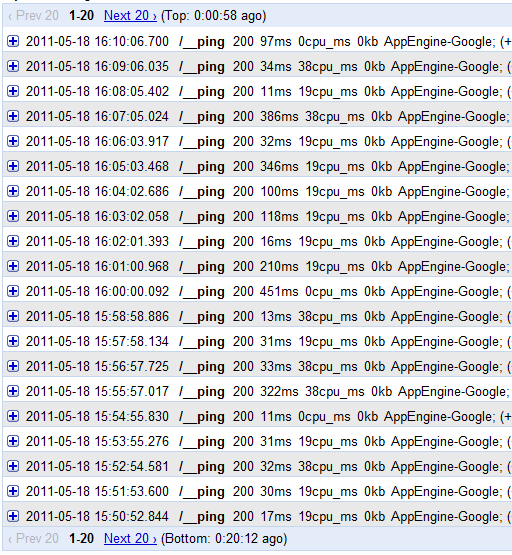{kind=link}
{kind=link}
{kind=link}