Some more real-world low-traffic scheduling data -- and a diagnosis
155 views
Skip to first unread message

Joshua Smith
Sep 2, 2011, 3:55:23 PM9/2/11
to google-a...@googlegroups.com
My app gets hit by a kiosk about every 3 minutes, and that chews up about 1sec of CPU, and kicks off a task that eats another 250ms. Users come and go now and then. Today I tried 3 different settings:
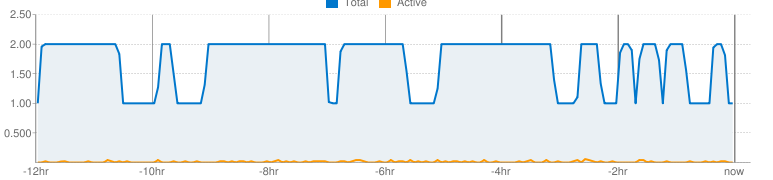
< 9am: Max idle = 1, max latency = 1s
9am - 1pm: Max idle = auto, max latency = 1s
1pm - now: Max idle = 1, max latency = 5s
For low-traffic, it appears that max idle = 1 is the same as "auto". That makes sense. I'm going to leave it at auto, since I'd like to be able to handle spikes well.
It looks like when I set the max latency way up, it sometimes lets the second instance die, but never for very long.
When I've looked at the instances they never seem to have been alive all that long. So I think the scheduler is spinning up one, adding another, letting the first die, adding another, and so on.
Right now I'm in one of those 1 instance troughs. The site is quite responsive, while I poke around, and it isn't starting another instance. So here in the trough, I'm getting the same behavior that was reported by the person who tried a "hello world" test. Yet the above graph is what it is.
As I'm writing this, the number of instances just jumped up to 2! So now I can see what caused it:
The kiosk hits the URL with an XMLHttp request to make sure it's alive, and if that works OK, then it refreshes itself. This bit of nastiness is there because it's impossible to get a browser to handle failed page loads 100% consistently well.
When the kiosk hits the URL, a task is launched to do some background processing recording that the heartbeat happened. The two hits therefore lead to two tasks. I'm using countdown = 1.
These two tasks are bunching up in the queue, and being processed essentially at the same time. That requires, you guessed it, two instances!
I have been thinking of task queues as sort of a background process, and I certainly wouldn't expect the system to spin up an instance just to handle a queued task. But that thinking isn't really right, since the docs explicitly suggest that spawning a lot of tasks is a good way to get a bunch of instances to munch your hard problem in parallel.
So my fix is actually not so hard. I just need to pass a param with the "just checking" initial kiosk request and use that to avoid spawning the task. That way I'll get hit-hit-task, not hit-hit-task-task, and presumably the system won't feel compelling to crank up a new instance.
If we get two kiosks going and they happen to get synchronized (as such things tend to do), then I'll be screwed. But for now, I think I've got my fix...
If you're still reading, I'll give you a reward: If you are trying to diagnose why you have 2 instances when you have the sliders set to 1/15, go to your log, view with Info and find the requests that are spinning up a new instance. Now look at all requests and find that one that spun up the evil second instance. Was it right on the heels of another request? I bet it was. Is it your fault? (In my case, it certainly was my fault.) Regardless, if you want to avoid that second instance, you need to find a way to get those requests to be farther apart.
-Joshua

Gregory D'alesandre
Sep 2, 2011, 10:45:53 PM9/2/11
to google-a...@googlegroups.com
Hey Joshua,
This might be crazy, but with free apps you get 9 hours of backends per day for free as well. Could you have the kiosk hit a dynamic backend and only users go through the frontends?
Greg
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.
Joshua Smith
Sep 3, 2011, 7:35:40 AM9/3/11
to google-a...@googlegroups.com
Someone else suggested that as well. I don't grok backends yet, so I don't know.
But the fix I described in this message seems to have solved my issue:
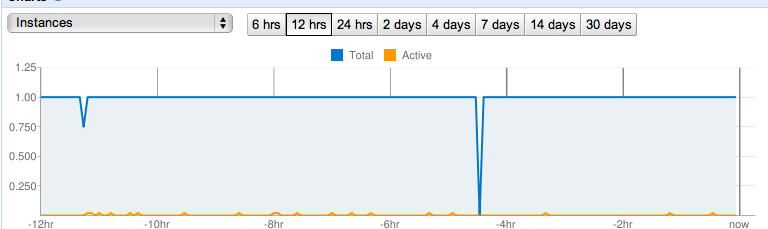
In fact, since I'm optimizing for the one-instance case, I actually just implemented a trivial cache. The first hit from the kiosk generates the page and returns it, and saves the page in memory. The second hit gets the saved page from memory. It's actually better than my original solution because I'm protected from generating any exceptions when the kiosk does the page reload.
My plan now is to port to HR so that when multi-threaded python becomes available, I'll be able to scale within a single instance.
You guys should look at the way task queues interact with the scheduler, though. It appears that the tendency of task queues to bunch up tasks and fire them in parallel leads to a tendency for the scheduler to spin up new instances.
I'd suggest that you consider the number of pending tasks in the queue before spinning up an instance just to handle the queue. If there are only a couple ready to go, then just make them wait a little longer. (Of course, giving the users control of this would be best, by having a "priority" setting per-task.)
-Joshua
On Sep 2, 2011, at 10:45 PM, Gregory D'alesandre wrote:
Hey Joshua,This might be crazy, but with free apps you get 9 hours of backends per day for free as well. Could you have the kiosk hit a dynamic backend and only users go through the frontends?
Greg
On Fri, Sep 2, 2011 at 12:55 PM, Joshua Smith <Joshua...@charter.net> wrote:
My app gets hit by a kiosk about every 3 minutes, and that chews up about 1sec of CPU, and kicks off a task that eats another 250ms. Users come and go now and then. Today I tried 3 different settings:
< 9am: Max idle = 1, max latency = 1s9am - 1pm: Max idle = auto, max latency = 1s1pm - now: Max idle = 1, max latency = 5s
<PastedGraphic-10.png>
For low-traffic, it appears that max idle = 1 is the same as "auto". That makes sense. I'm going to leave it at auto, since I'd like to be able to handle spikes well.It looks like when I set the max latency way up, it sometimes lets the second instance die, but never for very long.When I've looked at the instances they never seem to have been alive all that long. So I think the scheduler is spinning up one, adding another, letting the first die, adding another, and so on.Right now I'm in one of those 1 instance troughs. The site is quite responsive, while I poke around, and it isn't starting another instance. So here in the trough, I'm getting the same behavior that was reported by the person who tried a "hello world" test. Yet the above graph is what it is.As I'm writing this, the number of instances just jumped up to 2! So now I can see what caused it:The kiosk hits the URL with an XMLHttp request to make sure it's alive, and if that works OK, then it refreshes itself. This bit of nastiness is there because it's impossible to get a browser to handle failed page loads 100% consistently well.When the kiosk hits the URL, a task is launched to do some background processing recording that the heartbeat happened. The two hits therefore lead to two tasks. I'm using countdown = 1.These two tasks are bunching up in the queue, and being processed essentially at the same time. That requires, you guessed it, two instances!I have been thinking of task queues as sort of a background process, and I certainly wouldn't expect the system to spin up an instance just to handle a queued task. But that thinking isn't really right, since the docs explicitly suggest that spawning a lot of tasks is a good way to get a bunch of instances to munch your hard problem in parallel.So my fix is actually not so hard. I just need to pass a param with the "just checking" initial kiosk request and use that to avoid spawning the task. That way I'll get hit-hit-task, not hit-hit-task-task, and presumably the system won't feel compelling to crank up a new instance.If we get two kiosks going and they happen to get synchronized (as such things tend to do), then I'll be screwed. But for now, I think I've got my fix...If you're still reading, I'll give you a reward: If you are trying to diagnose why you have 2 instances when you have the sliders set to 1/15, go to your log, view with Info and find the requests that are spinning up a new instance. Now look at all requests and find that one that spun up the evil second instance. Was it right on the heels of another request? I bet it was. Is it your fault? (In my case, it certainly was my fault.) Regardless, if you want to avoid that second instance, you need to find a way to get those requests to be farther apart.-Joshua
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.

{kind=link}
Gregory D'alesandre
Sep 6, 2011, 6:22:27 PM9/6/11
to google-a...@googlegroups.com
Dynamic backends are only spawned for as long as you need them, but do have the 15 minute idle charge. So, if you wanted to use backends 24 times a day each use being only 5 minutes, you could definitely do so.
Greg
Reply all
Reply to author
Forward
0 new messages