Multiple spawn of Tasks running on a pipeline issue
26 views
Skip to first unread message

Sifu Tian
Apr 12, 2022, 9:32:50 AM4/12/22
to go-cd
 Hi all,
Hi all,I have some unusual behavior that is happening on random pipelines.
When the pipeline runs, it will run fine but the job will get to a certain point and start all over again pulling materials and running the same task. The first task appears to hang or just stops and a new but same job is run. The pipeline never fails it just continues to run and it will spawn the same job over and over. On the K8 cluster status page, it will only show one pod but in the console, it will show a new pod was issued.
I am using the Kubernetes elastic agent plugin
GoCD Server and agent are at 22.1
Any thoughts or help would be greatly appreciated.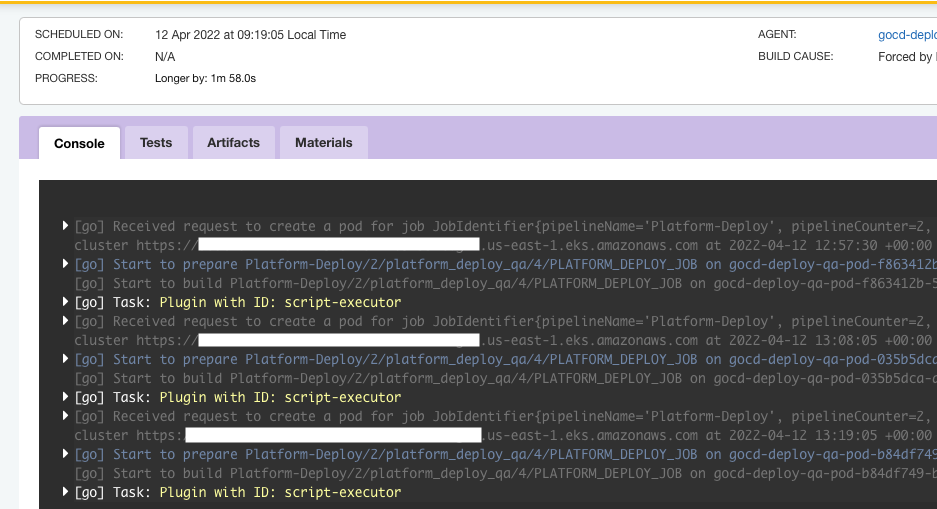

Ashwanth Kumar
Apr 12, 2022, 9:41:12 AM4/12/22
to go...@googlegroups.com
This behaviour of GoCD usually points to Agent process dying mid-way and GoCD automatically re-assign the work to another agent and they would start from scratch. Can you check the agent process logs for the earlier runs to see if there are any exceptions that might have caused the GoCD Server to reassign the process to another agent?
Sometimes it could be the pipeline itself that's killing the agent process for a variety of reasons.
--
You received this message because you are subscribed to the Google Groups "go-cd" group.
To unsubscribe from this group and stop receiving emails from it, send an email to go-cd+un...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/go-cd/3bf59b24-31f1-4445-be9e-a2ba6606d396n%40googlegroups.com.
Sifu Tian
Apr 12, 2022, 10:37:41 AM4/12/22
to go-cd
Hi Ash,
Forgive me but can you tell me where I can find the agent process logs? When the agent dies and a new one is spun up, I cant access the agent status page...its only for the new one that spun up.
In the server logs I see this: Doesnt give me any reason on why it hung and ultimately started a new pod. I want to stress that this is random though. I have 30 pipelines and all are using the same agent profile I have defined for each stage.
Some keep spawning in various stages and there is no predictive reason why. When I check the Cluster, memory is low and CPU is low.
I'm using C6i.2xlarge in a 5 node cluster. I was using R4.xlarge and didn't see this issue but can attribute any of these issues to the instance change which I did a few weeks ago.
2022-04-12 13:57:05,540 WARN [ThreadPoolTaskScheduler-1] ScheduleService:611 - Found hung job[id=JobInstance{stageId=184, name='PLATFORM_DEPLOY_JOB', state=Building, result=Unknown, agentUuid='3ff453d7-6a6b-413f-a845-728d96eec351', stateTransitions=[], scheduledDate
=Tue Apr 12 13:46:05 UTC 2022, timeProvider=com.thoughtworks.go.util.TimeProvider@715bdc39, ignored=false, identifier=JobIdentifier[Platform-Deploy, 2, 2, platform_deploy_qa, 5, PLATFORM_DEPLOY_JOB, 353], plan=null, runOnAllAgents=false, runMultipleInstance=false}],
rescheduling it
=Tue Apr 12 13:46:05 UTC 2022, timeProvider=com.thoughtworks.go.util.TimeProvider@715bdc39, ignored=false, identifier=JobIdentifier[Platform-Deploy, 2, 2, platform_deploy_qa, 5, PLATFORM_DEPLOY_JOB, 353], plan=null, runOnAllAgents=false, runMultipleInstance=false}],
rescheduling it
Sifu Tian
Apr 12, 2022, 10:50:08 PM4/12/22
to go-cd
Hi Ash,

I wanted to provide a follow-up response and say that I found the root cause of the issue.
What I discovered is that during each stage, depending on the scripts our code is running, will spike in memory and CPU. These spikes could last a few seconds, up to 30 sec.
Within our Kubernetes Elastic agent profiles YAML files, I defined memory and CPU requests and limits. The reason I did this was when running multiple pipelines, the pods would only saturate one node while the other nodes stayed idle.
This was the cause of the Pods either hanging or Kubernetes killing them. It was an oversight because I would continue to play with the CPU and Mem allocation in the file with no improvement.
(e.g. memory 1Gi - 4Gi and CPU 1.0 - 4.0.).
Once I removed the specified memory and CPU in the YAML file, and allow Kubernetes to handle the distribution, none of the pods died. I did notice 1 or 2 pipelines that handle our very heavy cpu and memory build hang but I can adjust different instances to accommodate the load on the cluster.
On Tuesday, April 12, 2022 at 9:41:12 AM UTC-4 ashwant...@gmail.com wrote:
Ashwanth Kumar
Apr 12, 2022, 11:44:08 PM4/12/22
to go...@googlegroups.com
Great that you were able to figure out the root cause.
Cheers.
To view this discussion on the web visit https://groups.google.com/d/msgid/go-cd/d3a5b605-130a-40d3-a70f-542a2878927dn%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages