Nonlocal definitions + #morpho mappings + #auxfuns in gf-ud
28 views
Skip to first unread message

Inari Listenmaa
Oct 19, 2021, 6:22:02 AM10/19/21
to Grammatical Framework
Hi,
In the same document, I also saw the #change syntax:
I'm trying to use ud2gf in a project, and I'm running into some issues, as well as general questions.
Since this post is rather long, I have marked my actual questions with [QUESTION]. If you can answer just one question, it is much appreciated. (Feel free to also comment on things that are not explicitly questions, if you want to.)
0. Background: what am I trying to do?
I want to experiment with ud2gf as follows:
From a large corpus, automatically derive an abstract syntax: an embedded application grammar on top of the very core bits of the RGL.
Let me give an example. Suppose we have a UD tree like this:
4 small small ADJ 0 root
2 cat cat NOUN 4 nsubj
1 the the DET 2 det
3 is be AUX 4 cop
Now, assume that I'm running ud2gf with just the standard Lang* from the RGL. One of the intermediate steps of ud2gf is as follows:
[4] small 4 (3) ADJ root (small_A : A[4] ; ComparA small_A : AP[4])
[1,2] cat 2 (1) NOUN nsubj (DetN the_Det (UseN cat_N) : NP[1,2])
[1] the 1 (2) DET det (the_Det : Det[1])
[3] is 3 (2) AUX cop (??????)
Same step, but now I switch to using my new grammar. The UD relations become GF categories in my grammar—more details right after the example.
[4] small … root (small_A : A[4] ; … ; rootA_ (PositA small_A) : root[4])
[1,2] cat … nsubj (DetN the_Det (UseN cat_N) : NP[1,2] ; nsubj_ (DetN the_Det (UseN cat_N) : nsubj[1,2])
[1] the … det (the_Det : Det[1]) -- uninteresting, because not immediate child of root
[3] is … cop (be_cop : cop[3])
Those trees in boldface, they have the same category as the dependency label of the word in the original sentence. This is the starting point of my grammar—structures of the form "root and its immediate children".
Every UD tree that I find in my corpus, that differs on the level of root's immediate children, will become the type signature of a corresponding GF function. If my corpus contains "the cat is small", or "the black cat is small", that structure will become the following GF function:
root_nsubj_cop : root -> nsubj -> cop -> UDS ;
In addition, I will have a (manual?) list of coercions and (language-specific) function words, that could look like this:
root_nsubj_cop : AP -> root ; -- same for rootV, rootN_ …
nsubj_ : NP -> nsubj ;
be_cop : cop ;
have_aux : aux ;
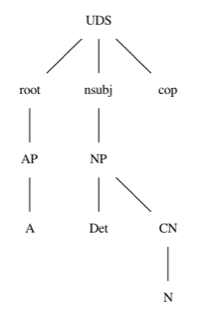
I would like to use the core RGL as much as possible, so I don't need to have different "UD layer" functions for "a cat", "my three cats" and whatnot. In the picture below is the AST (-nofuns) for "the cat is small", and I would like to ignore everything under the line "root nsubj cop".
1. Nonlocal definitions
My initial idea was to copy the mappings from Lang.labels, and only add new mappings for the custom functions (root_nsubj_cop, rootA_, nsubj_, …). I then noticed the Lang labels were somewhat outdated, so I switched to https://github.com/GrammaticalFramework/gf-ud/blob/master/grammars/Parse.labels instead.
Adding labels for my custom funs was trivial (root_nsubj_cop has the labels "head nsubj cop"), so I started parsing happily. It could parse "the cat is small", but it couldn't do "my hovercraft is full of eels". I found out why: DetCN had the following annotation
#fun DetCN det head -- Det -> CN -> NP
And "my" is not a det, but an nmod:poss.
Looking at the documentation, I found 3 ways of getting around this, none of which worked. The first one is here: https://github.com/GrammaticalFramework/gf-ud/blob/master/doc/annotations.md#abstract-annotations
A generalized form of this is a **nonlocal annotation**, such as#fun AdvVP _ PrepNP > head obl
I wrote this in my labels file, but no luck.
#fun DetCN _ PossPron > nmod:poss head -- my hovercraft
#fun DetCN det head
#change det > nmod:poss features Poss=Yes|PronType=Prs
That didn't work either, and gfud check-annotations even complained about bad syntax.
The third one I saw was the #altfun syntax at https://github.com/GrammaticalFramework/gf-ud/blob/master/doc/annotations.md#special-concrete-annotations-for-ud2gf :
Alternative function: #altfun#altfun ComplV2 head oblThis is needed in ud2gf for reading normal UD, because the complement of a V2 verb can be labelled either obj of obl depending on the case governed by the verb.
So I tried putting this in my labels file:
#fun DetCN det head
#altfun DetCN nmod:poss head
But nothing happens, and gfud check-annotations gives "unknown function '#altfun'".
[QUESTION]
* What is the current syntax for doing nonlocal abstract mappings?
* Are some/all of the syntaxes correct, but ud2gf just doesn't support nonlocal abstract mappings?
2. Do I need #morpho mappings?
When I run check-annotations, I get a long list of missing #morpho mappings. I don't have any of them currently, and the grammar still works fine (for those structures it covers–not "my hovercraft"!). I have read the documentation here https://github.com/GrammaticalFramework/gf-ud/blob/master/doc/annotations.md#concrete-annotations , but I'm afraid that it's still a bit cryptic to me what the #morpho mappings do. So my questions are, in order of priority:
[QUESTION]
a) Do I need to add #morpho mappings?
b) If so, can it be automated?
…
z) Why are they important?
3. Do I need #auxfun?
My hope was that I could get away with as few "weird" extra functions as possible. I will add aux, cop and such closed classes into my grammar, but I would ideally not want to deal with specialised versions of syntactic functions. My goal is not to produce RGL trees, so all those extra clutter of closed classes may stay in my trees.
Suppose that I'm parsing a sentence like "knowing that you didn't drink tea"–I don't even care if I lose the gerund in know, and the tense and polarity in you drink tea. If I have a subtree as a RGL Cl or VP, I can always re-introduce whatever inflections I need later.
(One thing I do care about is that my APs don't have superfluous ComparA or OrdSuperl–I don't want "full of eels" to be randomly changed into "fullest of eels".)
With this information about my needs, [QUESTION] do you think I need to figure out how to use #auxfun?
Sorry about the long post—if there is documentation somewhere that I have missed, please direct me to it. If there is no such documentation, I'll be glad to contribute to improving the current docs.
Cheers,
Inari

Aarne Ranta
Oct 19, 2021, 7:06:30 AM10/19/21
to gf-...@googlegroups.com
Hi Inari,
Thanks for all the pertinent questions!
I am ashamed to say that the ud2gf part in gf-ud is mainly work in progress - with no progress for a long time. Probably this is the first thing that should be said in the documentation.
The main reason is that the ud2gf direction has not been used that much, which means that its development has not been a priority. The main exception is Arianna's concept alignment algorithm https://github.com/harisont/concept-alignment , which uses ud2gf on a very small grammar (grammars/Extract.gf), where all the issues have been fixed or worked around. The goal is similar to yours: to extract abstract syntax from UD trees. But the target is limited to small subtrees.
Your work is a welcome stimulus to work more on this. I'm not sure when I will have time, and I'm also afraid that the current code (in "progress") is difficult for anyone else to penetrate - but contributions are welcome as always.
Fortunately, I can answer some of your questions:
* What is the current syntax for doing nonlocal abstract mappings?
- in gf2ud: #fun AdvVP _ PrepNP > head obl
- in ud2gf: #altfun and #auxfun should do the job - but as you notice, there is something that doesn't work
* Are some/all of the syntaxes correct, but ud2gf just doesn't support nonlocal abstract mappings?
- the syntax is as specified, therefore by definition correct, but there is something wrong in the implementation. We should also aim at a uniform treatment in both directions, so maybe some of the current annotation formats will become obsolete.
a) Do I need to add #morpho mappings?
- they are definitely needed in gf2ud, to guarantee well-formed UD output. In ud2gf, they can also be useful if you want to exploit conditions on morphological analysis
b) If so, can it be automated?
- to some extent, but not always, because the naming of features and their values is not consistent across the RGL. The main help is 'gfud check-annotations'
…
z) Why are they important?
- see (a) above
Regards
Aarne
--
---
You received this message because you are subscribed to the Google Groups "Grammatical Framework" group.
To unsubscribe from this group and stop receiving emails from it, send an email to gf-dev+un...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gf-dev/CFBB07DA-DBA1-4DF9-A38F-7838DF15D853%40gmail.com.
Inari Listenmaa
Oct 19, 2021, 7:32:41 PM10/19/21
to Grammatical Framework
Hi Aarne,
Thank you for the answers! We are exploring using ud2gf at CCLAW, so we have some resources to put into improving it. Andreas has been experimenting on improving the speed here https://github.com/anka-213/gf-ud/commits/misc-experiments , we can also look into other improvements (including documentation).
Inari
<cat_is_small_nofun.png>
To view this discussion on the web visit https://groups.google.com/d/msgid/gf-dev/CAH881EHGejX-_R9Th262k-35iNNdXf-qpVmvCe6L%2BoD2J4-CKA%40mail.gmail.com.
Aarne Ranta
Oct 20, 2021, 4:20:28 AM10/20/21
to gf-...@googlegroups.com
Inari,
It is great to see that you and Andreas are working on this! As ud2gf has had low priority it has been a bit beyond my time budget ever since Prasanth left.
I am not completely happy with the annotation language, as it has grown complicated and is not yet stable. Maybe a Haskell API for the same functions would be easier to handle. But on the other hand, I was not expecting the typical users to know Haskell, which is why I went for an ad hoc notation. But you should feel free to change it if you find anything better in the process!
Regards
Aarne
To view this discussion on the web visit https://groups.google.com/d/msgid/gf-dev/67D4D903-5673-4FE7-94E4-5D2B96404C58%40gmail.com.
Inari Listenmaa
Oct 29, 2021, 2:06:34 AM10/29/21
to Grammatical Framework
I have discovered the joys of #auxfuns—they are delightful to write, at least for those of us who can write RGL abstract syntax trees off the top of their head. :-D
I am not completely happy with the annotation language, as it has grown complicated and is not yet stable. Maybe a Haskell API for the same functions would be easier to handle. But on the other hand, I was not expecting the typical users to know Haskell, which is why I went for an ad hoc notation. But you should feel free to change it if you find anything better in the process!
Unfortunately, I'm leaning towards more complexity rather than less. :-P For example, a full-blown pattern matching on the left-hand side would be nice, in the style of def syntax.
I find I need something like that for the cases where UD structure differs from the RGL structure. An example would be lists, let's take an example "fluffy and cute".
In GF:
ConjAP and(BaseAP fluffy cute)
In UD:
1 fluffy root3 cute conj2 and cc
And if I understand correctly, one #auxfun macro can just look at a single level, one head and its child(ren). This makes total sense, I can't think of a comprehensible syntax to say that in one pass, we need to do like (head conj):head cc.
So what I'd like to do: in the first step, create a macro for "cute and", and map it to a function that returns AP -> AP. This doesn't work, but something like this:
#auxfun AndCutePartial_ and cute : Conj -> AP -> AP -> AP = \fluffy -> ConjAP and (BaseAP fluffy cute) ; cc head
This doesn't work in multiple ways—even GF shell can't understand the function:
Lang> ai \ap -> ConjAP and_Conj (BaseAP ap (PositA small_A))Cannot infer the type of expression \ap -> ConjAP and_Conj (BaseAP ap (PositA small_A))-- Trying to apply it to an APUDApp> ai (\ap -> ConjAP and_Conj (BaseAP ap (PositA small_A))) (PositA big_A)Cannot infer the type of expression \ap -> ConjAP and_Conj (BaseAP ap (PositA small_A))
So I could make a macro with a nonexisting type AP2AP, with a nonexisting constructor MkAP2AP : Conj -> AP -> AP2AP. The only point of AP2AP is to store the conjunction and the last AP for later use.
#auxfun AndCutePatternMatch_ and cute : Conj -> AP -> AP2AP = MkAP2AP and cute ; cc head
Next, I make a new macro, where I pattern match the dummy MkAP2AP constructor on the LHS. Then on the RHS, I use the actual values and & cute, now as arguments to real functions.
#auxfun FluffyAndCute_ fluffy (MkAP2AP and cute) : AP -> AP2AP -> AP = ConjAP and (BaseAP fluffy cute) ; head conj
Obviously this doesn't work at the moment—just looking at the code for parsing auxfuns, there's no understanding of parentheses or constructors. :-P But this is the direction I'd like to go towards. Or something similar, but less confusing for users?
So here comes a [QUESTION]: did you have to solve similar issues yourself? As in, different structure in GF vs. UD, and no way of mapping the structure in one pass. If so, did you have a solution that is simpler than introducing yet another feature to the auxfuns?
Inari
Aarne Ranta
Nov 1, 2021, 4:08:41 AM11/1/21
to gf-...@googlegroups.com
It sounds indeed like a natural extension of the auxfun syntax to introduce deeper patterns. And as you suggest, such patterns have always been there for GF's abstract syntax "def" definitions. So the existing machinery might well be the solution.
As you notice, the annotations are not properly parsed, which is the reason why nested patterns are not possible. To reuse the syntax of GF itself would even for this reason be a solution that avoids reinventing the wheel.
The problem you show from the GF shell is due to the failure of type inference for lambda expressions. This in turn is because, for a monomorphic type theory, type inference for lambda is not available in general. The term (\x -> x) is a minimal example.
In GF's defs, this problem is solved by explicitly declaring the types of all functions in 'fun' declarations (and of constructors in 'data' declarations). I guess this would solve the problem in auxfuns as well.
---------
A related approach to annotations, using existing GF more generally, would be to generate UD trees with a concrete syntax. Then gf2ud would be linearization, and ud2gf would then be parsing with the same grammar. I have not tested this myself, and there might be things that make it impossible. For example, it would be difficult to maintain the numbering of tokens. But this is of course not necessary, because one could represent the UD trees with nested trees, as is already done internally in gf-ud.
Regards
Aarne
--
---
You received this message because you are subscribed to the Google Groups "Grammatical Framework" group.
To unsubscribe from this group and stop receiving emails from it, send an email to gf-dev+un...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gf-dev/86C3ABA7-9B4E-42BB-9B4C-DF14F0C5F1EF%40gmail.com.
Reply all
Reply to author
Forward
0 new messages