get_document_topics giving very different results when using it on LdaModel or LdaMulticore
86 views
Skip to first unread message

T W
Aug 23, 2022, 5:35:02 AM8/23/22
to Gensim
Hi,
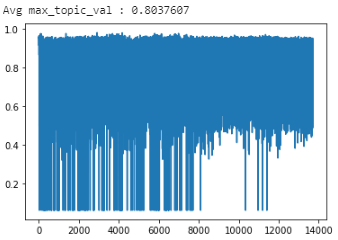
I was using the LdaMulticore class object in a Jupyter-lab project which I am currently migrating to a proper python library. When debugging the code, I have found that the multithreads call (LdaMulticore) was creating issues and I have therefore changed it to LdaModel which has resolved the problem. The thing is that it gives me completely different results. I am fitting the model on ~14,000 documents with 16 topics and to get an idea of how successful the fitting has been I am graphing the max_topic_value and its average over the 14,000 documents.
Here are the results:
When using LdaMulticore:
lda_model = gensim.models.LdaMulticore(corpus=corpus,
id2word=id2word,
num_topics=num_topics,iterations=100,random_state=seed_random)
When using LdaModel:
lda_model = gensim.models.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=num_topics,iterations=100,random_state=seed_random)
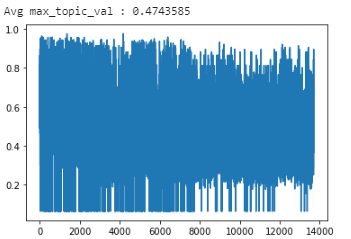
If there is a bit of randomness between calls the avg_max_topic values remain more or less the same for LdaModel (~0.47) and LdaMulticore (~0.80).
Would you have any idea of how to get similar results (i.e around 0.80) using LdaModel or alternatively of how to use LdaMulticore in a python sequential code..
Thanks for your help,
Best regards,
Thierry

Gordon Mohr
Aug 24, 2022, 1:24:04 PM8/24/22
to Gensim
LDA isn't my area of expertise, but I suspect spreading the training out over multiple processes changes the optimization process enough that results at the end can differ. Changing parameters like `passes` or `iterations` might again bring them closer - especially, giving up some of the multicore speedup to train longer.
Curious:
* What sort of "issues" did you initially have with `LdaMulticore`? Given that you're showing final results with `LdaMulticore`, & seem to prefer them, what's the difference between the results you're showing and (some other?) setup where it's unusable?
* How many processors on the system (& thus effective value of `workers` for `LdaMulticore`)?
* How much of a speedup are you seeing in `LdaMulticore`?
* What makes you prefer the higher final `avg_max_topic` value? (Is there some tangible downstream task on which the higher values give better results than the lower values?)
* That your graph shows such a big shift between 'early' and 'late' documents is a bit suspicious; clumping of similar documents in long runs during training can impair generalizable learning (as incremental batches individually don't have full range of corpus variety). What changes if you shuffle the documents, to eliminate any similar-document clumps, before training?
- Gordon
tabw...@gmail.com
Oct 13, 2022, 4:30:01 AM10/13/22
to Gensim
Hi Gordon,
Sorry I have missed your response and just came across it.
Please see my answers to your questions below.
* What sort of "issues" did you initially have with `LdaMulticore`? Given that you're showing final results with `LdaMulticore`, & seem to prefer them, what's the difference between the results you're showing and (some other?) setup where it's unusable?
==> Errors were raised in the code as it was expected to run sequential.
* How many processors on the system (& thus effective value of `workers` for `LdaMulticore`)?
==> Off the top of my head, I think 8.
* How much of a speedup are you seeing in `LdaMulticore`?
==> Speed wasn't my initial motivation. I started running a Jupyter notebook with the LdaMulticore and was satisfied with the results without thinking about testing LdaModel as well.
* What makes you prefer the higher final `avg_max_topic` value? (Is there some tangible downstream task on which the higher values give better results than the lower values?)
==> This measure tells me that the model as been relatively successful in assigning a document to a specific topic. The opposite unwanted outcome is to have equal uniform distribution for each document across all the topics.
* That your graph shows such a big shift between 'early' and 'late' documents is a bit suspicious; clumping of similar documents in long runs during training can impair generalizable learning (as incremental batches individually don't have full range of corpus variety). What changes if you shuffle the documents, to eliminate any similar-document clumps, before training?
==> This is a good point. The database is the result of the merger of 2 distinct datasets with different characteristics. Initially, it was useful to maintain the order to understand the differences in characteristics but you are right a reshuffle of the samples might help improve my model.
Thanks,
Thierry
--
You received this message because you are subscribed to the Google Groups "Gensim" group.
To unsubscribe from this group and stop receiving emails from it, send an email to gensim+un...@googlegroups.com.
To view this discussion on the web visit
https://groups.google.com/d/msgid/gensim/9e93c827-d50a-4a97-b4ad-5f8bc5cc0b35n%40googlegroups.comYou received this message because you are subscribed to the Google Groups "Gensim" group.
To unsubscribe from this group and stop receiving emails from it, send an email to gensim+un...@googlegroups.com.
To view this discussion on the web visit
.
Reply all
Reply to author
Forward
0 new messages