Word2Vec Anomaly
39 views
Skip to first unread message

Alfiyanto Kondolele
Aug 9, 2022, 7:59:17 PM8/9/22
to Gensim
- Desc
I use Word2Vec model to train my dataset with
1782 sentences and
1360 vocabs. Last loss is 0.0. Is this reasonable?
- Code
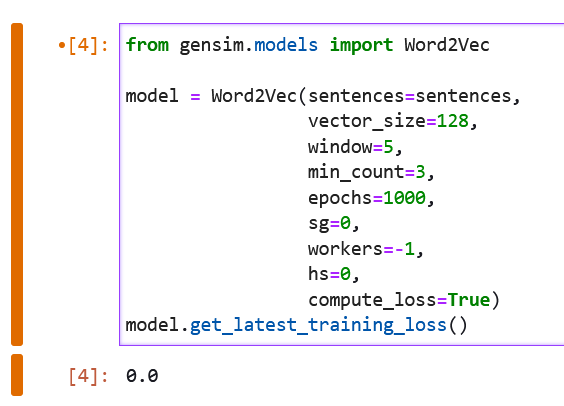
- Version
gensim: 4.2.0
numpy: 1.22.0
scipy: 1.8.1

Gordon Mohr
Aug 11, 2022, 2:19:53 PM8/11/22
to Gensim
First, keep in mind that the loss-calculation of Gensim `Word2Vec` has a number of known problems which may limit its suitability for whatever-you're-hoping-it'll-provide, or require hackish workarounds. See open-issue <https://github.com/RaRe-Technologies/gensim/issues/2617> for an overview, with links to related issues, of all that's missing.
However, there's a more foundational problem in your usage: `workers=-1` is not a supported value for Gensim. Its behavior will be undefined. (I suspect it results in no training happening, instantly. Do you have logging enabled at the INFO level to observe normal training steps happening & progressing, with sensible interim updates & internal counts reported, taking a reasonable amount of time?)
Separately, that's a pretty-small training set: even if training were happening, with a tiny 1360 unique-vocabulary (and even some of those words only having a meager `min_count=3` number of usage-examples), the final model might not be impressive in its generalizability to understanding the words' broad meanings. This algorithm really needs lots of realistic, varied data to show its most-useful benefits. (Though doing things like using a smaller `vector_size`, and more `epochs`, can manage *some* consistency/meaning out of smaller datasets, the 'ceiling' of how impressive the final model can get is still quite low with such parameter-tinkering. More varied & representative data always helps more.)
- Gordon
Alfiyanto Kondolele
Aug 11, 2022, 7:44:52 PM8/11/22
to Gensim
Thank you Gordon for your explanation. Yes, i use wrong value for workers parameter. I think gensim can use -1 to get all core.
Reply all
Reply to author
Forward
0 new messages