Fwd: Biggest Common Voice dataset yet!
6 views
Skip to first unread message

Muthu A
May 1, 2022, 2:29:00 PM5/1/22
to ThamiZha! - Free Tamil Computing(FTC)
வணக்கம்:
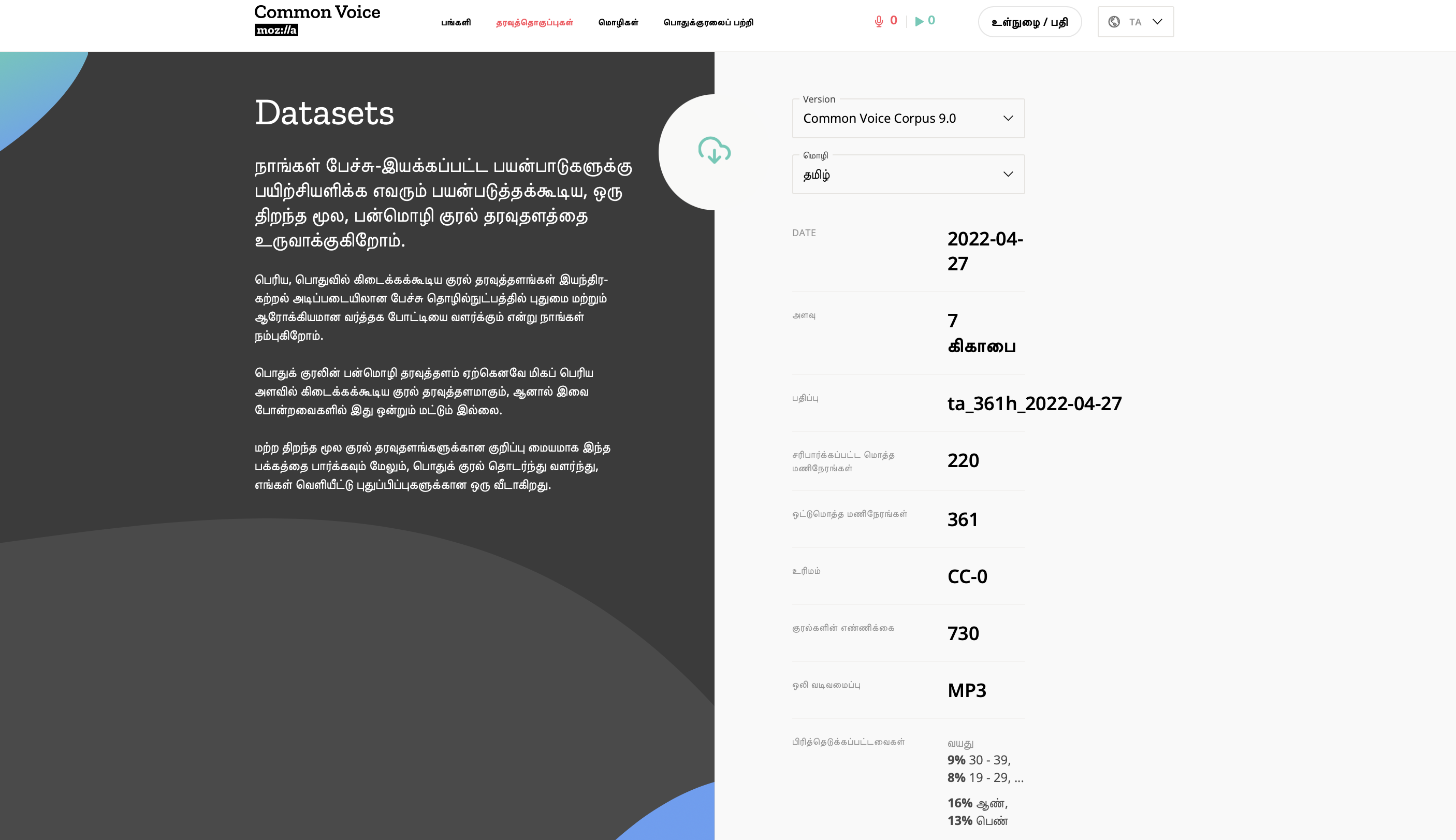
மொசில்லா நிறுவனம், நமது தமிழ் தன்னார்வலர்கள், விக்கி/கணியம், மொசில்லா தமிழ் நாடு நண்பர்கள் பணியின்பால், 700GB மேலான தமிழ் தகவல் ஒலி-உரை தரவமைப்புகள் இங்கு பொது உரிமத்தில் / வெளியில் தரப்பட்டுள்ளன https://commonvoice.mozilla.org/ta/datasets
இதனை பயன்செய்து செயற்கையறிவு / கற்கும் கருவிகள் உறுவாககலாம்.
நன்றி
-முத்து
---------- Forwarded message ---------
அனுப்புநர்: Hillary Juma, Mozilla <moz...@email.mozilla.org>
Date: வியா., 28 ஏப்., 2022, முற்பகல் 10:28
Subject: Biggest Common Voice dataset yet!
To: <ezhi...@gmail.com>
அனுப்புநர்: Hillary Juma, Mozilla <moz...@email.mozilla.org>
Date: வியா., 28 ஏப்., 2022, முற்பகல் 10:28
Subject: Biggest Common Voice dataset yet!
To: <ezhi...@gmail.com>
|
||||||||||||||||||||||||||



Reply all
Reply to author
Forward
0 new messages