AppKatas using FBP

Bob
The objective is given here:
CSV Viewer first... "Iteration 0" can be posted in reply.
Paul Morrison wrote:
On Jan 20, 12:42 pm, Ralf Westphal <ral...@googlemail.com> wrote:
>
> Already iteration 1 of the CSV Viewer is interactive. You can page
> through the CSV file.
> Iteration 2 just adds an interaction (jump to page).
You're right - I read it too fast! Actually they could have specified
a batch implementation (Iteration 0)!
> I don´t expect any performance benefits from using FBP to solve this
> problem.
> But maybe FBP shines in other ways... ;-)
you move through the iterations - you can just keep unplugging
components, and plugging in new ones. I have been saying all along
that language designers pay too little attention to maintenance - for
a variety of reasons. FBP's big strength is in how it improves
maintainability - and when you consider that over 80% of what business
programmers do is maintenance, rather than producing new code, this
becomes extremely important. The big FBP system at a Canadian bank
has been running for over 40 years, undergoing continuous maintenance, -- *evolution*
often by people who were weak on the concept! We are now talking
about literally a second generation of programmers!
For those who feel like addressing the AppKatas using JavaFBP or
C#FBP, I should point out that they already have a number of
generalized components which will prove useful - long term, we really
need to think about designing some kind of FBP tool-chest (for each
component: name, function description, ports, input and output data
stream descriptions).
Bob
Here is a FBP solution for CSV Viewer "iteration 0".
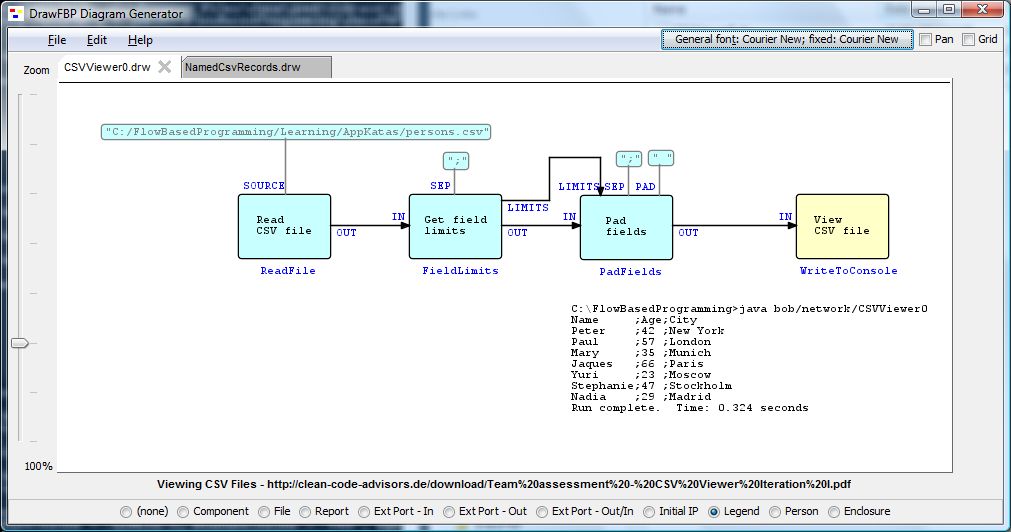
The screen shot includes evidence of the output as a "legend" on the diagram.

Ralf Westphal
Looking forward to your evolving model.
On 22 Jan., 14:59, Bob <bobcorr...@hotmail.com> wrote:
> Here is a FBP solution for CSV Viewer "iteration 0".
>

Paul Morrison
> Now add interactivity and paging. Then move on to iteration 2...
> Looking forward to your evolving model.
>
>
Here is my diagram for Iterations 1 and 2 - they seem to be
approximately the same (in my view, the requirement for the 'L' option
in Iteration 1 basically forces the same design as Iteration 2).
Iteration 3 will be a shade more complex, but I believe it is a sort of
superset, so it will actually work for 1 and 2.
I believe I can just attach my picture - here goes...
Paul Morrison
> 54KViewDownload
Forgot to say that the blue blobs represent automatic ports: as per my
book, an automatic output port automatically closes when its owning
process terminates; an automatic input port prevents its owning
process from starting until a signal is received - however, this
process does not have to do a receive to dispose of it.

Ged Byrne
Interesting. So the efffect of the automatic ports is that once the
load is complete the components involved can be closed.
We could turn this into two separate composite components: LOADER and
TABLE_NAVIGATOR and the automatic port would form a sort of "umbilical
cord" between the two.
Does that make sense?
Paul Morrison
Absolutely! Good idea!
Ralf Westphal
This looks like a solution that could work.
However let me ask a couple of questions:
1. Where do you store the formated pages?
2. Why do you format all pages? Maybe the user only views only a tiny
subset of all pages.
3. Where do you store "small" state like pageno? (Or does the pageno
flow thru the processes at the end of the network in a circle?)
4. What´s the type of data flowing thru the network? I can imagine what
´s flowing, but to actually implement a process like "Determine column
widths" I need to know exactly what data to expect.
Have you implemented your solution?
-Ralf
> 54KAnzeigenHerunterladen
Paul Morrison
1. I am planning to use a HashMap for Iterations 1 and 2, and a database for Iteration 3.
2. Since the pages are fixed size, you're right - I can store them in CSV form and format them at display time. It's a trade-off. Same component - I can just move it to the display part of the network!
3. The latter - it just flows in a circle.
4. Initially packets containing one string - for each line; later the lines will get aggregated into pages.
The first part of the code I have worked on is the Java Swing display component. as that was the part I was most unsure about. That's working, so I feel the rest should be plain sailing. (I hope)
Of course, as the code evolves, I will change the diagram.
Thanks for your feedback.
Paul
Sent from Samsung Galaxy Tab (tm) on Rogers
Paul Morrison
topologies - see Chap. 16 in both editions ( http://www.jpaulmorrison.com/fbp/deadlock.shtml
) . In fact, I got a deadlock display while testing the display loop
- shows how long it's been since I was building FBP apps! For ease of
reference, the diagram can be seen at
http://www.jpaulmorrison.com/graphicsstuff/ViewCSV-Iteration1-2.png .
As per Ralf's suggestion, I will probably move the page formatting
over into the display loop.
However, loops in FBP (network loop topologies, not loops inside
components) have a unique problem that arises when you want to close
them down. The problem is that the close-down rule for processes is
that a process only closes down when all of its upstream processes
have closed down. In a loop comprising A and B, A is upstream of B,
but B is also upstream of A. When I ran my test, I got a deadlock -
at first I thought it was a bona fide deadlock, but then I realized
that all I had to do was solve the loop problem in the usual way: have
one of the processes (the one that knows it is finished) close its
output or input port. I did this - worked like a charm! Loops are
described in Chap. 14 - http://www.jpaulmorrison.com/fbp/loop.shtml .
The display part of the network is now working - so on to the
formatting portion!

John Cowan
> However, loops in FBP (network loop topologies, not loops inside
> components) have a unique problem that arises when you want to close
> them down. The problem is that the close-down rule for processes is
> that a process only closes down when all of its upstream processes
> have closed down.
When a process closes down, the library should catch the ThreadDeath
exception and close all the ports associated with the process. This would
give more reliable semantics, though it will not break deadlocks as such.
(Note that after ThreadDeath is caught, it must be propagated to allow
Java to shut down the thread.)
--
There are three kinds of people in the world: John Cowan
those who can count, co...@ccil.org
and those who can't.
Paul Morrison
ensure that unexpected thread death will close all ports. This would
probably apply to C# as well - right?
Regards,
Paul
Paul Morrison
Exceptions (and/or Errors) throw ThreadDeath? Would you be willing to
sign on as a JavaFBP developer on SourceForge? :-)
On 25/01/2012 3:56 PM, John Cowan wrote:
> Paul Morrison scripsit:
>
>> However, loops in FBP (network loop topologies, not loops inside
>> components) have a unique problem that arises when you want to close
>> them down. The problem is that the close-down rule for processes is
>> that a process only closes down when all of its upstream processes
>> have closed down.
> When a process closes down, the library should catch the ThreadDeath
> exception and close all the ports associated with the process. This would
> give more reliable semantics, though it will not break deadlocks as such.
>
> (Note that after ThreadDeath is caught, it must be propagated to allow
> Java to shut down the thread.)
>
John Cowan
> BTW is there a generic way in Java to have different (unexpected)
> Exceptions (and/or Errors) throw ThreadDeath? Would you be willing to
> sign on as a JavaFBP developer on SourceForge? :-)
Catch Throwable and have it generate a ThreadDeath encapsulating the Throwable
and then throw it. Two caveats: you must catch Throwable as the last catch
in the try-catch statement, and you must make sure to do the same cleanup
for Throwable that you do for ThreadDeath, because the ThreadDeath will not be
caught again.
So here's the general skeleton:
try {
[code to execute the process]
} catch (ThreadDeath e) {
closeAllPorts();
} catch (Throwable e) {
closeAllPorts();
throw new ThreadDeath(e);
}
--
John Cowan co...@ccil.org http://ccil.org/~cowan
Nobody expects the RESTifarian Inquisition! Our chief weapon is
surprise ... surprise and tedium ... tedium and surprise ....
Our two weapons are tedium and surprise ... and ruthless disregard
for unpleasant facts.... Our three weapons are tedium, surprise, and
ruthless disregard ... and an almost fanatical devotion to Roy Fielding....
Paul Morrison
Paul
On 25/01/2012 6:12 PM, John Cowan wrote:
> Paul Morrison scripsit:
>
>> BTW is there a generic way in Java to have different (unexpected)
>> Exceptions (and/or Errors) throw ThreadDeath? Would you be willing to
>> sign on as a JavaFBP developer on SourceForge? :-)
> Catch Throwable and have it generate a ThreadDeath encapsulating the Throwable
> and then throw it. Two caveats: you must catch Throwable as the last catch
> in the try-catch statement, and you must make sure to do the same cleanup
> for Throwable that you do for ThreadDeath, because the ThreadDeath will not be
> caught again.
>
> So here's the general skeleton:
>
> try {
> [code to execute the process]
> } catch (ThreadDeath e) {
> closeAllPorts();
> } catch (Throwable e) {
> closeAllPorts();
> throw new ThreadDeath(e);
> }
>
Paul Morrison
suggestion. FBP networks are inherently asynchronous, so you can just
start the display portion of the diagram running earlier, allowing it to
run asynchronously with the part that stores CSV pages...
Paul Morrison
Java doesn't like it - on "throw new ThreadDeath(e)" it says
"Unhandled exception type" . Have you tried it recently? If so, can
you send me a sample of the code (I may have dropped a semi-colon)...
TIA
John Cowan
> Java doesn't like it - on "throw new ThreadDeath(e)" it says
> "Unhandled exception type" . Have you tried it recently? If so, can
> you send me a sample of the code (I may have dropped a semi-colon)...
Hmm. Apparently there is only a zero-argument constructor for ThreadDeath.
Try using "throw new ThreadDeath()" instead.
No, I didn't test it.
--
John Cowan <co...@ccil.org> http://www.ccil.org/~cowan
One time I called in to the central system and started working on a big
thick 'sed' and 'awk' heavy duty data bashing script. One of the geologists
came by, looked over my shoulder and said 'Oh, that happens to me too.
Try hanging up and phoning in again.' --Beverly Erlebacher
Paul Morrison
> Paul Morrison scripsit:
>
>> Java doesn't like it - on "throw new ThreadDeath(e)" it says
>> "Unhandled exception type" . Have you tried it recently? If so, can
>> you send me a sample of the code (I may have dropped a semi-colon)...
> Hmm. Apparently there is only a zero-argument constructor for ThreadDeath.
> Try using "throw new ThreadDeath()" instead.
>
> No, I didn't test it.
>
(ThreadDeath e) - gave the message Unreachable catch block - but I
could force a throw somewhere in the code...
I confess I am out of my depth here...
BTW are there other pronouncements of the sage Kehlog Ahlbran?
John Cowan
> Nope, didn't work either... Actually, the first line - catch
> (ThreadDeath e) - gave the message Unreachable catch block - but I
> could force a throw somewhere in the code...
That sounds like there is a more inclusive catch clause preceding it.
The ThreadDeath catch should come first, then the Throwable.
Are there any other catch blocks in the try statement?
> BTW are there other pronouncements of the sage Kehlog Ahlbran?
Oh yes, a whole book called _The Profit_.
Online at http://rsidd.online.fr/profit/ .
> --
> http://jpaulmorrison.blogspot.com/
--
After fixing the Y2K bug in an application: John Cowan
WELCOME TO <censored> co...@ccil.org
DATE: MONDAK, JANUARK 1, 1900 http://www.ccil.org/~cowan
Ralf Westphal
But what I don´t really understand: you´re storing whole pages? So you
´re literally doubling the space needed for paging through a 100 GB
CSV file? (Your page store is a copy of the original data.) (By the
way, please believe me, there are such large CSV files. A customer of
mine is dealing with them on a regular basis.)
And why do you wait when jumping to a page not loaded yet? Doesn´t
that freeze the program?
Finally: What parts of your solution benefit from parallel processing?
Since this is a FBP diagram, all processes run in parallel.
> 64KAnzeigenHerunterladen
Paul Morrison
> That sounds like there is a more inclusive catch clause preceding it.
> The ThreadDeath catch should come first, then the Throwable. Are there
> any other catch blocks in the try statement?
changing the constructor call to drop the parameter has fixed things!
Thanks a lot!
>> BTW are there other pronouncements of the sage Kehlog Ahlbran?
> Oh yes, a whole book called _The Profit_.
> Online at http://rsidd.online.fr/profit/ .
P.
Paul Morrison
On Jan 27, 5:07 am, Ralf Westphal <ralf...@googlemail.com> wrote:
> Great you moved on with the AppKata.
>
> But what I don´t really understand: you´re storing whole pages? So you
> ´re literally doubling the space needed for paging through a 100 GB
> CSV file? (Your page store is a copy of the original data.) (By the
> way, please believe me, there are such large CSV files. A customer of
> mine is dealing with them on a regular basis.)
in Iteration 3. I will assume that the database allows direct access
to a specific record, so we can multiply the requested page number by
page depth, and jump to that point in the raw file. Then we can move
the Build CSV Page function over to the display side as well. Looks
like the flow diagram is allowing some good communication between
humans :-)
> And why do you wait when jumping to a page not loaded yet? Doesn´t
> that freeze the program?
individually. In AMPS, which used green threads, I had a "future
events" queue, and the whole network only slept if no process could
proceed (and the job wasn't complete).
> Finally: What parts of your solution benefit from parallel processing?
> Since this is a FBP diagram, all processes run in parallel.
from FBP is in facilitating application design and maintainability
(evolvability). It just happens that it is also going to make it
easier to take advantage of multiple processors, grid computing, etc.,
etc. It is also in my experience a good communication vehicle between
designers, programmers, users, software types, and so on.
>
Ralf Westphal
> That's a very good point! However, the J function is still required
> in Iteration 3. I will assume that the database allows direct access
> to a specific record, so we can multiply the requested page number by
> page depth, and jump to that point in the raw file.
That would double the hard disk space needed.
But if you just stored indexes to certain records... that would take
up much less space.
E.g. store the index to every 1,000th record (independent of page
length).
Assuming a record length of 256 bytes there would be 400,000,000
records in a 100 GB file.
Keeping a 4 byte index of just every 1,000th record would result in
just a 1.6 GB index db. This could even be kept in memory :-)
> Then we can move
> the Build CSV Page function over to the display side as well.
> Looks
> like the flow diagram is allowing some good communication between
> humans :-)
> > Finally: What parts of your solution benefit from parallel processing?
> > Since this is a FBP diagram, all processes run in parallel.
>
> Not sure what this means - as I keep saying, in my view the big payoff
> from FBP is in facilitating application design and maintainability
> (evolvability). It just happens that it is also going to make it
> easier to take advantage of multiple processors, grid computing, etc.,
> etc. It is also in my experience a good communication vehicle between
> designers, programmers, users, software types, and so on.
parallel processing than usually thought.
It helps moving your thinking from sync to parallel. But its true
value is in "good communication", easier design, more flexible code
etc.
And that´s what I was trying to get across all along :-)
And that´s why I´d like to align the message of Flow-Based Programming
with the message of Flow-Design/Event-Based Components (FD/EBC).
Currently they are two approaches because FBP is rooted in parallel
programming. You libs are all about running processes on multiple
threads.
But FD/EBC come from the world of sync programming - but allowing the
developer to move into the real of parallel processing.
It might be, we´re closer in our thinking that it seems. And this
Application Kata proves it :-) There is only little parallel
processing needed to solve it. Only reading the records from the file
for indexing needs to be done in the background. Only 2 threads are
needed. Two "subflows" are running in parallel. But within each
subflow the operations (processes) run synchronously. It´s that easy.
Not even a framework is needed. You can very easily set that up in
plain Java/C#.
But what is of tremendous help is the "flow thinking": wiring together
small operational units into data flows.
John Cowan
> And that�s why I�d like to align the message of Flow-Based
> Programming with the message of Flow-Design/Event-Based Components
> (FD/EBC). Currently they are two approaches because FBP is rooted
> in parallel programming. You libs are all about running processes on
> multiple threads.
FBP isn't actually parallel, it's concurrent. It does not matter
whether the processes execute in separate threads, separate OS
processes, separate cores, or separate machines connected over the
Internet. There may be any amount of parallelism or none in the
implementation. Parallelism is a speed hack; concurrency is a way of
life.
Indeed, Hoare's CSP model ("communicating sequential processes") is
equivalent to FBP, except that FBP processes do not have explicit
knowledge of their neighbors in normal cases.
> But FD/EBC come from the world of sync programming - but allowing the
> developer to move into the real of parallel processing.
A Sufficiently Smart Compiler could take an FBP program and squeeze out
unnecessary concurrency to run it on as few threads as possible. It's
a hard problem, and threads are normally efficient enough, but it's
possible in principle.
--
Values of beeta will give rise to dom! John Cowan
(5th/6th edition 'mv' said this if you tried http://www.ccil.org/~cowan
to rename '.' or '..' entries; see co...@ccil.org
http://cm.bell-labs.com/cm/cs/who/dmr/odd.html)
Paul Morrison
> FBP isn't actually parallel, it's concurrent. It does not matter
> whether the processes execute in separate threads, separate OS
> processes, separate cores, or separate machines connected over the
> Internet. There may be any amount of parallelism or none in the
> implementation. Parallelism is a speed hack; concurrency is a way of
> life.
interchangeably - thereby no doubt adding to the confusion! Care to
expand on this, John?
Paul Morrison
> But if you just stored indexes to certain records... that would take
> up much less space.
> E.g. store the index to every 1,000th record (independent of page
> length).
> Assuming a record length of 256 bytes there would be 400,000,000
> records in a 100 GB file.
> Keeping a 4 byte index of just every 1,000th record would result in
> just a 1.6 GB index db. This could even be kept in memory:-)
so that sounds like a good idea. However, since UTF-8 encoding doesn't
guarantee how many bytes make a character, in that case we will still
have to read through the file building your index, which means we still
have to allow for the possibility that the requested page number is
ahead of the point up to which we have scanned (excuse the convoluted
sentence!). If we could assume some kind of encoding where a character
takes a fixed number of bytes, we could do direct accessing. Would this
be better?
Ralf Westphal
> so that sounds like a good idea.
way to do random access to files through positionable streams.
>However, since UTF-8 encoding doesn't
> guarantee how many bytes make a character, in that case we will still
> have to read through the file building your index,
differing lengths. (256 bytes were just a simple assumption to
calculate a rough index size.)
The program needs to read in all lines at least once to build the
index.
>which means we still
> have to allow for the possibility that the requested page number is
> ahead of the point up to which we have scanned (excuse the convoluted
> sentence!). If we could assume some kind of encoding where a character
> takes a fixed number of bytes, we could do direct accessing. Would this
> be better?
Read_all_lines_sequentially -> Buffer_page_indexes ->
#GetPage:Get_page_index_from_buffer -> Read_page_lines ->
Format_page_lines -> Display -> Show_menue -> Calc_page_number ->
#GetPage.
I would not wait for a page to become available. That would freeze the
program. Goto last/specific page just shows the page requested if it
has been read or the currently last page. The text message from
Iteration 2 tells whether all pages have been read yet, e.g. "Page 4
of 10" or "Page 17 of ?".
Ralf Westphal
> FBP isn't actually parallel, it's concurrent. It does not matter
> whether the processes execute in separate threads, separate OS
> processes, separate cores, or separate machines connected over the
> Internet. There may be any amount of parallelism or none in the
> implementation. Parallelism is a speed hack; concurrency is a way of
> life.
"concurrent".
Maybe you want to point to a description of the differences.
That there may be any amount of parallelism in a FBP network... I did
not read that from Paul´s book. Sorry.
To me it made very clear it´s about parallel/concurrent execution of
programs in a certain way: by describing them as data flow networks.
(As opposed, for example, to actors.)
I´m perfectly fine with "there need not be any parallelism in a FBP
network". That´s great. I even would start with that by default and
add parallelism just as needed.
And I agree with this way of describing software it´s easy to run a
network locally or distribute it across OS processes.
Paul Morrison
> I would not wait for a page to become available. That would freeze the
> program. Goto last/specific page just shows the page requested if it
> has been read or the currently last page. The text message from
> Iteration 2 tells whether all pages have been read yet, e.g. "Page 4
> of 10" or "Page 17 of ?".
should be given the choice: wait for the requested page number or reject
request?
John Cowan
> That there may be any amount of parallelism in a FBP network... I did
> not read that from Paul�s book. Sorry.
I didn't mean "any amount" literally, only at the level of components.
Each component executes serially. In addition, some components
("sponges") may defeat parallelims by buffering their entire input before
producing any output. A sort component is a good example of this.
--
John Cowan co...@ccil.org http://ccil.org/~cowan
There was an old man Said with a laugh, "I
From Peru, whose lim'ricks all Cut them in half, the pay is
Look'd like haiku. He Much better for two."
--Emmet O'Brien
John Cowan
> Interesting distinction! I confess I have tended to use these terms
> interchangeably - thereby no doubt adding to the confusion! Care to
> expand on this, John?
Parallelism refers to physically simultaneous execution. When you raise
both arms above your head, you do so in parallel. Nothing can be more
parallel than the number of execution agents simultaneously available:
on an 8-core system, you can add up 8 rows of a matrix in parallel,
but not 16 rows. Furthermore (as I just posted) some problems cannot
be parallelized, whereas others can be executed entirely in parallel.
Concurrency refers to conceptually simultaneous execution. When you
juggle balls, you are executing a concurrent program: despite appearances,
jugglers only throw or catch one ball at a time. A concurrent program
can execute on a single execution agent, on as many agents as it has
concurrent components, or anything in between, so concurrency does not
depend on parallelism. We usually speak of concurrency when there is
interaction between the concurrent components.
Flow-based programming is based on the concurrent execution of mostly
isolated processes that communicate via flows. Because the components
are isolated, they may be executed in parallel or not. Because there
are no constraints on what components may do with their inputs, parallel
execution may or may not actually speed up the computation.
--
And through this revolting graveyard of the universe the muffled, maddening
beating of drums, and thin, monotonous whine of blasphemous flutes from
inconceivable, unlighted chambers beyond Time; the detestable pounding
and piping whereunto dance slowly, awkwardly, and absurdly the gigantic
tenebrous ultimate gods --the blind, voiceless, mindless gargoyles whose soul
is Nyarlathotep. (Lovecraft) John Cowan co...@ccil.org
Bob
[PS is there a better place to post this, instead of in a discussion thread? I did not realize that the title could change...]
Ralf Westphal
> I didn't know from the spec that this was an option! Maybe the user
> should be given the choice: wait for the requested page number or reject
> request?
supposed to be close to real projects ;-) So it needs to be fuzzy here
and there.)
But if you ask me as the "customer" (since I wrote the AppKata spec),
I tell you, I don´t want any further choices. Keep the UI clean and
simple. No freezing.
Ralf Westphal
> Flow-based programming is based on the concurrent execution
execution is possible, viewed as a "degeneration" :-)
Flow-Design (FD) on the other hand starts from synchronous execution.
By default all functional units in a FD network communicate in sync
fashion. No concurrent execution. See here for a very concise
description of FD notation and translation into C#:
http://geekswithblogs.net/theArchitectsNapkin/archive/2011/03/19/flow-design-cheat-sheet-ndash-part-i-notation.aspx
http://geekswithblogs.net/theArchitectsNapkin/archive/2011/03/20/flow-design-cheat-sheet-ndash-part-ii-translation.aspx
Here´s the solution to a Coding Kata done with FD:
http://geekswithblogs.net/theArchitectsNapkin/archive/2011/07/05/flowing-bowling-game-kata-i.aspx
(Using FD for this kind of problem might be a bit overkill, though.)
As you can see: FD looks pretty much like FBP - without the
concurrency.
But FD can scale up to concurrent and distributed programming. It
shares data flows with FBP. But it favors a more explicit switch to
concurrency by marking certain functional units as "running on their
own" (i.e. being executed on one or more separate threads). Also FD
does not require concurrent functional units to "own" their threads.
And it does not pose limitations of the processing of data by
concurrent nodes: it can be processed sequentially or in parallel.
I´m working on an execution engine for FD networks where you switch
between sync, concurrent sequential, concurrent parallel execution by
marking up ports (http://npantarhei.codeplex.com/). Take this simple
network for exeample:
.in -> Traverse_directory_tree -> Select_text_files ->
Count_words_in_file -> Sum_word_counts ->
Output_total_number_of_words.
FD starts by assuming this network to run synchronously. And why not?
Concurrent execution is an optimization which might not be needed.
But if you want to run some nodes concurrently you just some markup:
.in ->* Traverse_directory_tree -> Select_text_files ->**
Count_words_in_file ->* Sum_word_counts ->
Output_total_number_of_words.
->* means the consuming node (to its right) executes messages
sequentially but on another thread than the producing node (to its
left). There is only a single data item being worked by the node at a
time.
->** means the consuming node executes messages in parallel. Many data
items can be worked on at the same time.
The above example decouples the processing of the network from its
environment by making Traverse_directory_tree a sequential node. The
next node, though, - Select_text_files - runs on the same thread as
Traverse_directory. Processing continues synchronously by default.
Then all text files found are processed in parallel by
Count_words_in_file.
The next node, which calculates the sum of the word counts, again runs
on its own - but sequentially. It processes the word counts one by
one. At the end the output is synchronous with regard to summation.
Here´s a diagram for this scenario:
https://cacoo.com/diagrams/2sGvmImQCtgixAyS
View the small circles as "hearts" of functional units ;-) Some are
passive/dead, living on the heart beat of others. Some have a single
heart (sequential processing), some have multiple (parallel
processing).
-Ralf
PS: I like your quote by Lovecraft. Reminded me of some 30 years ago
when I read all his books. [sigh]
Is the quote from "The Dream-Quest of Unknown Kadath"?
John Cowan
> But FD can scale up to concurrent and distributed programming. It
> shares data flows with FBP. But it favors a more explicit switch to
> concurrency by marking certain functional units as "running on their
> own" (i.e. being executed on one or more separate threads). Also FD
> does not require concurrent functional units to "own" their threads.
FBP does not require it either; it's just the simplest implementation.
If it's efficient enough, then fine. If it's not, you may have to do
something quite complex to figure out which components can share threads.
Do you know about the Faust programming language? It too is synchronous
data flow, and it compiles down to C++.
> PS: I like your quote by Lovecraft. Reminded me of some 30 years ago
> when I read all his books. [sigh] Is the quote from "The Dream-Quest
> of Unknown Kadath"?
Lovecraft actually uses the sentence in two different stories:
"Nyarlathotep" and "The Dream-Quest of Unknown Kadath." The wording is
slightly different, however. I don't remember offhand which one this is.
--
But you, Wormtongue, you have done what you could for your true master. Some
reward you have earned at least. Yet Saruman is apt to overlook his bargains.
I should advise you to go quickly and remind him, lest he forget your faithful
service. --Gandalf John Cowan <co...@ccil.org>
Ralf Westphal
> FBP does not require it either; it's just the simplest implementation.
I just wanted to underline the default: FBP=async/concurrent,
FD=synchronous
> If it's efficient enough, then fine. If it's not, you may have to do
> something quite complex to figure out which components can share threads.
>
> Do you know about the Faust programming language? It too is synchronous
> data flow, and it compiles down to C++.
http://en.wikipedia.org/wiki/FAUST_(programming_language)
Paul Morrison
> But if you ask me as the "customer" (since I wrote the AppKata spec),
> I tell you, I don�t want any further choices. Keep the UI clean and
> simple. No freezing.
Didn't realize you wrote the AppKata spec - it's a pretty neat idea!
Thanks for doing this! However... as a user I think I would want to at
least be told if my request could not be satisfied *at this time*! So,
even if we don't hang the app, we could have a message like "Working on
it - come back later". From there, it's a small step to giving the user
a choice. So... here is my diagram - all you have to do is remove the
blocks marked with 2 asterisks if you don't want to give the user a choice.
Ralf Westphal
> Didn't realize you wrote the AppKata spec - it's a pretty neat idea!
> Thanks for doing this! However... as a user I think I would want to at
> least be told if my request could not be satisfied *at this time*! So,
> even if we don't hang the app, we could have a message like "Working on
> it - come back later". From there, it's a small step to giving the user
> a choice. So... here is my diagram - all you have to do is remove the
> blocks marked with 2 asterisks if you don't want to give the user a choice.
functionality the spec isn´t talking about, smells like YAGNI.
If in doubt do whatever is most simple. Which in this case would be -
I presume - to just jump to the currently last page.
In case the user does not like this behavior, she´ll tell you upon
acceptance review.
What I still find strange, though, is the lack of visibility of shared
state.
The model does not show, which processes share state, like "Build
index" and "Locate reqd page".
This makes it harder for a new dev on the project to understand how
the FBP network solves the problem. Especially since the processes
sharing state don´t even tell about this through their names, e.g.
"Build index of page tops" and "Retrieve page top from index".
Bob Corrick
Re: my post in this thread "Idea for AppKata CSV Viewer solution after reading people - especially Paul and Ralf - in conversation"
I was trying for a solution with zero intermediate storage. File positions are carried with the data records, and used to navigate in the file depending on the user's selection. As with any solution, all aspects would have to be evaluated in use.
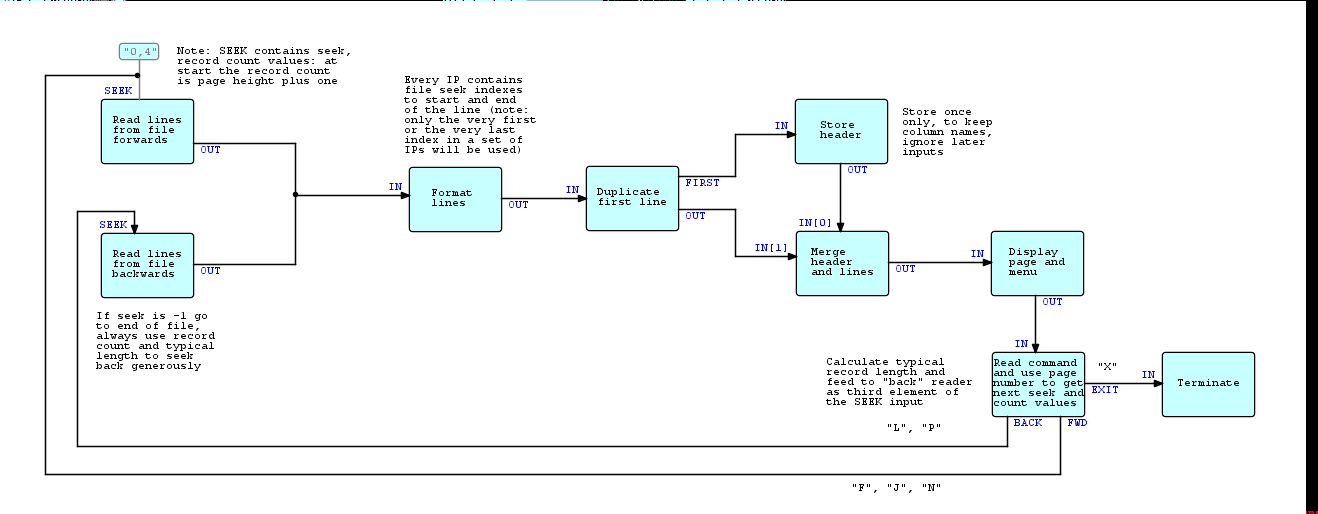
I agree with Ralf that using pictures and simple process names does not convey enough about the low level details. In DrawFBP you can Display Port Info to get a description of the component, which helps but does not reveal the data structure of the "IP"s in the flow. I added comments onto the diagram in my post (also attached to this email as a DrawFBP file) to try to convey my thinking, and assist with maintenance.
Does this make sense? What would be better?
Regards,
Bob
> Subject: Re: AppKatas using FBP
> From: ral...@googlemail.com
> To: flow-based-...@googlegroups.com
Paul Morrison
I agree with Bob's last note and Ralf's point about state - in the
old, old days, we put the diagram up on a very large sheet of paper,
pinned it up on the partition walls, and then proceeded to mark it up
with all sorts of informal comments. Of course it got pretty messy
over the course of a project - not to mention wear and tear from
erasers! Conversely, at the other extreme, in DrawFBP I wanted to
restrict the blocks and connections to the data that would actually be
used to generate a running application. I think Bob's suggestion is a
good compromise: as in his examples, use the "legend" construct to
convey information that humans can use, but that won't actually be
used when generating a running network. We could also add "meta"
levels to the diagram which would be stored but not generate code,
e.g. formal descriptions of data streams - if we can figure out how to
do that...
On Feb 1, 4:06 pm, Bob Corrick <bobcorr...@hotmail.com> wrote:
> Hi Ralf, Paul
>
> Re: my post in this thread "Idea for AppKata CSV Viewer solution after reading people - especially Paul and Ralf - in conversation"
>
> I was trying for a solution
> with zero intermediate storage. File positions are carried with the data records, and used to navigate in the file depending on the user's selection. As with any solution, all aspects would have to be evaluated in use.
>
> I agree with Ralf that using pictures and simple process names does not convey enough about the low level details. In DrawFBP you can Display Port Info to get a description of the component, which helps but does not reveal the data structure of the "IP"s in the flow. I added comments onto the diagram in my post (also attached to this email as a DrawFBP file) to try to convey my thinking, and assist with maintenance.
>
> Does this make sense? What would be better?
>
> Regards,
> Bob
>
>
>
>
>
>
>
> > Date: Tue, 31 Jan 2012 14:55:23 -0800
> > Subject: Re: AppKatas using FBP
>
> > On 31 Jan., 17:54, Paul Morrison <paul.morri...@rogers.com> wrote:
> > > Didn't realize you wrote the AppKata spec - it's a pretty neat idea!
> > > Thanks for doing this! However... as a user I think I would want to at
> > > least be told if my request could not be satisfied *at this time*! So,
> > > even if we don't hang the app, we could have a message like "Working on
> > > it - come back later". From there, it's a small step to giving the user
> > > a choice. So... here is my diagram - all you have to do is remove the
> > > blocks marked with 2 asterisks if you don't want to give the user a choice.
>
> > I don´t want to linger too long on this point, but adding some
> > functionality the spec isn´t talking about, smells like YAGNI.
> > If in doubt do whatever is most simple. Which in this case would be -
> > I presume - to just jump to the currently last page.
> > In case the user does not like this behavior, she´ll tell you upon
> > acceptance review.
>
> > What I still find strange, though, is the lack of visibility of shared
> > state.
> > The model does not show, which processes share state, like "Build
> > index" and "Locate reqd page".
> > This makes it harder for a new dev on the project to understand how
> > the FBP network solves the problem. Especially since the processes
> > sharing state don´t even tell about this through their names, e.g.
> > "Build index of page tops" and "Retrieve page top from index".
>
>
>
> 9KViewDownload
>
> CSVViewerIdea.jpg
> 140KViewDownload
Ralf Westphal
about data.
They are data flow diagrams - but there is not data to see. Isn´t that
strange?
So what we do in Flow-Design is we annotate connections with info on
what data is flowing. Sometimes it´s just a data type:
producer -(int)-> consumer
sometimes it´s a desciption of whats flowing (with an optional data
type):
read_file -(line:string)-> process_line
if the data type is not that simple, a separate data type description
is added to the model. that could be a class diagram or a crow foot
diagram.
flow-design or FBP should not be viewed as the only way to model
software.
class diagrams have their value. state machines have their value, too.
Paul Morrison
The idea of annotating the diagram with data descriptions is a very
attractive one, and one that I've wrestled with over the years -
although I should point out that in CSV Viewer Iteration 3, you have two
processes accessing a shared database asynchronously, which is not
really a "flow".
However, I take your general point - the problem in my view is the wide
variety of data types flowing between processes. I would love to be
able to check compatibility between what one process emits and what the
next one accepts - at design time, ideally. I did try in DrawFBP to use
the isAssignableFrom() method, but this only works with a Java
description of data types, and anyway it's not general enough.
If you look at Fig 10.3 in my book -
http://www.jpaulmorrison.com/fbp/simpapp3.shtml (same Fig number in the
new edition), you will see a diagram of the data stream coming out of
Collate. The column headed IPs are basically class instances, so the
overall stream is a nested structure of class instances. As I say later
in the book, you could in fact use a form of regular expression notation
to describe this structure (see chapters 24 and 25 in the online version
- 23 and 24 in the new edition).
You also have some components that have no constraints on the classes
they accept or the classes they generate, e.g. the JavaFBP component
Concatenate, which takes all the IPs coming into element 0 of input port
array IN, followed by those coming into element 1, and so on, up to
whatever size the array port is defined as. So, if I want to put
Concatenate between a process emitting A's and a process accepting A's,
but Concatenate can accept and emit anything, how do I express this?
So, while I am very open to suggestions about formal encoding of data
stream properties, I see no reason to hold my breath waiting for one to
come along! We built a whole banking system (at least the batch part)
without ever having, or needing, a formal notation...
Regards,
Paul
John Cowan
> However, I take your general point - the problem in my view is the
> wide variety of data types flowing between processes. I would love to
> be able to check compatibility between what one process emits and what
> the next one accepts - at design time, ideally. I did try in DrawFBP
> to use the isAssignableFrom() method, but this only works with a Java
> description of data types, and anyway it's not general enough.
What really needs to be done (and unfortunately I don't have time/energy
to tackle it) is to update JavaFBP and C# FBP to use parameterized
classes. Thus instead of just having Packets which hold Objects, you
define Packet<Foo>, which is a Packet that holds Foos. The compiler
will check that only a Foo is put into a Packet and only a Foo emerges
from it. Various other classes would need to be parameterized as well.
Once that's done, it's possible to modify DrawFBP to allow each
component to be annotated with a type name, and then generate the
appropriate kinds of Ports.
--
John Cowan co...@ccil.org http://www.ccil.org/~cowan
Most people are much more ignorant about language than they are about
[other subjects], but they reckon that because they can talk and read and
write, their opinions about talking and reading and writing are as well
informed as anybody's. And since I have DNA, I'm entitled to carry on at
length about genetics without bothering to learn anything about it. Not.
--Mark Liberman
Paul Morrison
> Thus instead of just having Packets which hold Objects, you
> define Packet<Foo>, which is a Packet that holds Foos. The compiler
> will check that only a Foo is put into a Packet and only a Foo emerges
> from it.
reflection? It won't handle the cases I described in my previous post
(everything would be Packet<Object>), but it would still be a useful
extension...
Paul
Bob Corrick
For this you would use Generics in Java - https://www.google.com/search?q=generics+in+java
This is available in Java from version 1.5 on. From my understanding, and John Cowan's comments, this is not a trivial change for the FBP system.
Bob
> From: paul.m...@rogers.com
> To: flow-based-...@googlegroups.com
> Subject: Re: AppKatas using FBP
>
John Cowan
> For this you would use Generics in Java -
> https://www.google.com/search?q=generics+in+java
For some reason I forgot the word "generic" until I'd already posted.
But that's what I'm talking about.
> This is available in Java from version 1.5 on. From my understanding,
> and John Cowan's comments, this is not a trivial change for the
> FBP system.
No, it's not, but it's long overdue. Generics have been in Java for eight
years now, and I'd say they are a well-accepted part of a programmer's
toolkit, supported by all current versions of Java (6 and 7).
--
Well, I have news for our current leaders John Cowan
and the leaders of tomorrow: the Bill of co...@ccil.org
Rights is not a frivolous luxury, in force http://www.ccil.org/~cowan
only during times of peace and prosperity.
We don't just push it to the side when the going gets tough. --Molly Ivins
Paul Morrison
On Feb 5, 3:15 pm, John Cowan <co...@mercury.ccil.org> wrote:
> Generics have been in Java for eight
> years now, and I'd say they are a well-accepted part of a programmer's
> toolkit, supported by all current versions of Java (6 and 7).
understand it, generics are compile-time, but it sounds like people
are talking about using reflection, as we have to do run-time
checking. We should be able to get type information from the
annotations, but much of the JavaFBP and C#FBP code will become much
more complex - and we still won't be able to handle cases like the
one I put up earlier in my reply to Ralf. I would appreciate it very
much if someone could put up a sketch of what they have in mind - or
even sign up as a co-developer :-)
Paul Morrison
> We should be able to get type information from the annotations, but
> much of the JavaFBP and C#FBP code will become much more complex - and
> we still won't be able to handle cases like the one I put up earlier
> in my reply to Ralf.
check that the data in an incoming packet is of the class specified in
the component annotations - and similarly for a "send", but this does
not make use of generics. What I am having trouble visualizing is a
compile-time test - I agree it would be nice if we could somehow test
compatibility between neighbouring components at compile (or design)
time, but I have no idea how you would go about this, given the fact
that components are, or should be, black boxes - except via what I am
already partially doing, namely do the checking in the diagramming
tool. Can someone clarify what they have in mind?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Aristophanes
the approach I have taken to be interesting. Briefly, instead of
using named ports I use named connectors where the names are type
names. Ports are specified by the connector type to which they
connect. For example the predefined auton for reading a line from a
file looks something like this:
(in_stream)------>|X|--------->(text_string)
(next)------------->|X|---------->(fail)
where in_stream is a file pointer (my code is in C), text_string is a
line of text from a file, next is a trigger to tell the auton to read
a new line, and fail is a signal that the file could not be read
(presumably by EOF). When two autons are connected they must match in
type. Thus connecting the auton that opens the file to the auton that
reads the file looks something like this:
[file opener]----(in_stream)---->[file reader]
which looks much like Ralf's fd. An important point here is that
type checking really should happen in the draw tool if you are using
one. One difference from fd is that the types aren't raw types; they
are application meaningful types.
The whole scheme works a lot better if you are maintaining a catalog
of autons and connectors.
There are several gotchas and complications. Sometimes you want more
that one port with a given type. My solution is to make the connector
a three part entity. The main part is the message type. There can
also be distinct outport and inport numbers. This happens when there
is more than one outport sending messages with the same message type
or more than one inport receiving messages with the same message
type. This actually is a fairly rare circumstance but it has to be
provided for.
A more common problem is that different autons can be defined with
different names. A simple example is a binary switch. It has two
states, on and off. It has an input to set the state, and one to
command it to send a message. It has two outports, one used when the
state is on and one used when the state is off.
The problem is that the natural names for the outport connectors are
things like "on" and "off" which probably don't match the names at the
receiving end. There are various things that can be done. For each
instance of a switch we can redfine the port names to match the
intended destinations. We can have special type changing autons. We
can have something like a cast, e.g. connectors that have a receiving
type and a delivery type. An important point is that these issues
mostly arise when we are not actually sending data or an IP but
instead are sending a signal.
Paul Morrison
would tackle the 2nd one (the Questionnaire). It doesn't specify
whether it is a one-user network, or a multi-user network, so I am
assuming the former - very easy to change this design to the latter if
desired. So here is my first iteration - hope it is clear! Feel free
to throw brickbats!
{kind=link}
Bob
It would be interesting to descend a level and describe the Model and
the various components.
What occurs to me is the possibility of generic components, working on
a simplified Model.
For example, transform the given questionnaire.txt text into a
"denormalized" Model such as:
?Which of these animals is a mammal;N;Ant
?Which of these animals is a mammal;N;Bee
?Which of these animals is a mammal;Y;Cat
?What is the sum of 2+3;N;2
?What is the sum of 2+3;Y;5
?What is the sum of 2+3;N;6
> 5KViewDownload
Paul Morrison
Sent from Samsung Galaxy Tab (tm) on Rogers
Bob Corrick
I used Hashmap in the other App Kata as it is more widely available eg early Android versions. But that is unfinished, as I have been concentrating on non-technical matters outside work (eg being a school governor).
One thing that concerned me is that the keys in the map were very tied to the fact that I was reading a file, and I wanted to make an alternative that read from a database. Then I should be able to separate these aspects better.
At work I found time to work through some Codecademy examples of JavaScript, now that it is available server side as well as on browsers. No time to actually get into node.js though :-( maybe once I finish some Java fbp I will try the js path.
All the best,
Bob
-----Original Message-----
From: Paul Morrison
Sent: 29 Mar 2012 01:31:11 GMT
To: flow-based-...@googlegroups.com
Subject: Re: AppKatas using FBP