Flink
236 views
Skip to first unread message

Paul Morrison
Jul 12, 2020, 10:55:27 AM7/12/20
to Flow Based Programming
Thanks, Felipe, for sending this: https://www.ververica.com/blog/presenting-our-streaming-concepts-introduction-to-flink-video-series
Just wondering if there are any Flink aficionados watching this group...? If so, any comments?
Apache seems to be a hotbed of flow-based stuff: NiFi, and also Kafka (?), and now Flink... Some kind of dialog would be neat!
Stay safe, everybody!
Paul M.
Paul Morrison
Jul 12, 2020, 2:11:58 PM7/12/20
to Flow Based Programming
Just noticed that one of the main selling points of Flink seems to be streaming ETL! Of course this is what FBP-ETL provides (will provide when the Load is built).
Does this mean that most ETL solutions read the whole database in first, and then do the Transform?
TIA

Niclas Hedhman
Jul 12, 2020, 10:36:54 PM7/12/20
to flow-based-...@googlegroups.com
I am a Member of the Apache Software Foundation, currently a serving board member and have some personal experience with Apache Flink and Apache Storm, although never been actively contributing to those projects.
First of all, the main difference between Flink and Apache Spark is that Flink started out with a model of "endless stream" and Spark started out with a model of "batches". However, over the years they have converged a bit, so Flink has a concept of batch/window and Spark is nowadays ok (but I would say not excellent) with really tiny batches.
Flink itself has the primitives to build the topology. That means how flows/nodes should be linked, split, merged, batched and so on. That is operated in a distributed fashion and the topology rules will adapt to the hardware cluster available. The programmer/operator does not need to figure out how things is actually scheduled on the cluster, only the logical breakdown of what the cluster could look like. The programmer then provides "functions" for each node, and "starting execution" means that the topology is uploaded to the Flink cluster, which may run any other number of topologies at the same time.
The message packets are of arbitrary type/format and up to programmer to get that right. In my particular application, I was primarily sending tiny strings, but any object could be sent, provided that the serialization system used could handle the type. IIRC, the serialization is pluggable into the cluster, and each topology shouldn't need to worry about it. And my particular cluster ran a handful of overhead topologies, and then 2 topologies per customer. Exchange between topologies is/was not built into Flink and I used Apache Kafka for that, again a highly scalable system (for message queuing).
I didn't do ETL, but it is a popular field, since it is where horizontally scalable systems can really shine. Creating the load on online systems is often quite hard and you don't reap the benefit until much later when/if your system gets heavily utilized. For ETL, you get immediate benefit by simply faster loading times.
As I mentioned, Flink was originally about "process one message at a time", but as people did more and more complex stuff, batch/window features were added, so that Flink handled the state within a window, and ensured that all messages belonging to the same window would arrive at the same CPU, and if there is a machine crash that this state is re-established on the new home for that window. IIUIC, windows can be time or size constrained, or run for the entire execution, so "load the entire batch" is dependent on that, i.e. "it depends". If the ETL Is simply reading rows and storing in SQL, then it is not loading the whole batch.
HTH
Niclas
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/5382ff49-3c1f-45c8-ae92-71d11d9e136ao%40googlegroups.com.
Paul Morrison
Jul 14, 2020, 11:43:26 AM7/14/20
to flow-based-...@googlegroups.com, Felipe Valdes, Bob Corrick, Joe Witt, Vladimir Sibirov, Tom Young
Hi Niclas,
There seem to be all sorts of flow-based products showing up, some being incubated by Apache, many not... Given the number of FBP-ish projects under Apache, is there any kind of "Apache-wide" attempt to consolidate them - and acknowledge prior art? And I believe NiFi was incubated under Apache (right terminology, Joe?).
As my late mentor, Wayne Stevens, used to say, when it's time for the hula hoop to be invented, it will show up all over!
One of the problems seems to be terminology - for instance, your term "topology" seems to correspond to FBP's "network", whereas I use the term "topology" to refer to the general shape of a network... These language issues are going to pop up increasingly - especially now that flow-based programming is becoming an international movement!
I ran into a similar problem for my book, trying to find a general term for "unit of concurrency": on page ix of the Preface to the 2nd ed. of my book, I list 11, found just by Googling "unit of concurrency" - the weirdest IMO is "vat"! I finally settled on "process" - I think this corresponds to what Flink calls "stateful computation"...?
Flink and Spark seem to use "batch" slightly differently from the conventional usage - "batch" is what programming was in the first few decades of my career! That was all we did in those days! Of course, what I think you would call "a batch" would in those days normally be a whole file: the first flow-based application to go live (mid-'70s) was processing millions of transactions and/or records every night, as a single batch! Now, of course, FBP supports interactive patterns comfortably - Facebook's Flux is a flow-based technology - see https://www.youtube.com/embed/i__969noyAM . Again, in the old days, there was a hard and fast distinction between "batch" and "online", with different software packages supporting them - FBP removes that distinction: in the FBP e-Brokerage app I worked on a few years ago (briefly described on pp. 205-207 of the 2nd ed.), it was interactive, but trades were sent to remote processing sites, called “back-ends”, where choice of back-end sites depended not only on the type of trade, but also even on the time of day. The remote processing sites could batch up trades as they saw fit, and respond asynchronously.
In FBP potentially all streams are "endless", but, since we have never implemented hot switching of components (yet, AFAIK), streams normally have a beginning and an end... In FBP, we also have the capability of grouping IPs into nested batches, called "substreams", by using bracket IPs. The concepts of substreams and substream-sensitive ports are very powerful, and play well with checkpointing. You might find interesting the chapter on checkpointing in my book - Chap. 19 of the 2nd edition.
Given all the Apache projects that seem to involve flow-based programming in some way, I am curious whether there is an ongoing effort to establish common ground between them, and maybe converge them. A number of people working in the FBP field over the years have tried to extract and highlight common concepts and develop categorizations for FBP and FBP-like projects: one such effort is https://github.com/flowbased/flowbased.org/wiki by Vladimir Sibirov; another is a spreadsheet developed by Tom Young, but I don't know how far he got with it... For a rough list (not up to date) of FBP-ish projects, see also https://jpaulm.github.io/fbp/links_external.html ...
One last comment: I know my book is TLDR, but I got tired writing innumerable papers (which usually got rejected), where the first 3/4 would be an attempt to distill about 50 years (as of now) of experience with FBP technology (and I couldn't just assume that the reader already understood FBP), so I decided to just write a big book, and later a 2nd. edition. And yes, I know I talk about technologies that very few of today's programmers even know about... but they are almost certainly still in use somewhere! As witness the recent call for COBOL programmers (and, yes, I did write one COBOL program in my 60 years of programming, and, no, I don't want to write another one !).
This post is probably also TLDR, so I'll stop here!
Best regards, and thanks for your interest,
Paul M.
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CADmm%2BKcY5qFEQfch_Ywa5Z3s7Uk1NV1FBE%3D9Se8M4U2r%2BLAjAA%40mail.gmail.com.

Joe Witt
Jul 14, 2020, 12:09:07 PM7/14/20
to Paul Morrison, flow-based-...@googlegroups.com, Felipe Valdes, Bob Corrick, Vladimir Sibirov, Tom Young
Paul,
Yep NiFi, just like Flink and Storm and other projects mentioned at the ASF went through the Incubator. That is just the ASF's primary means of establishing communities.
Generally speaking I think the reason why things look more and more like FBP over time is that the core concepts/abstractions of FBP are pretty naturally what one arrives at when thinking how data flows through a series of steps. You end up with networks/subnets, black boxes, information packets. These core elements would not change much. Flink uses aspects of these concepts to focus on the data processing problem. NiFi uses these concepts to focus on the flow management problems. ...and so on as with Storm and others. Niclas' summary was quite good.
I think it was in a youtube video you spoke in but you mentioned that for many people FBP is not something you read about to learn but rather it is something you discover as you think about how to design a system that deals with the continuous flow of data. I completely agree with this sentiment. What *I* feel is most important and most successful about FBP is that you've faithfully codified and documented a range of patterns and concepts that one will run into in this space. This means you've accelerated that discovery process and once someone starts it you'll have saved them tremendous time. In my view it isn't any implementation that matters. It is the concepts.
I dont know what others' experiences have been like. In my case I started that discovery journey. Only when I wanted to tell others about it did I find FBP. As soon as I did I learned a range of things I had not thought of which then influenced what I was doing/building with what became Apache NiFi. Therefore and put quite simply, your efforts with FBP then have changed my life and helped influence what has become a pretty useful project/product/community.
FBP is a huge success I suspect. It just might be that the way in which it has succeeded differs from what you were thinking.
In any event - thank you for documenting it all and for so faithfully fanning the flames of the FBP community and providing reference implementations and such.
Joe

Tom Young
Jul 14, 2020, 12:17:30 PM7/14/20
to flow-based-...@googlegroups.com, Felipe Valdes, Bob Corrick, Joe Witt, Vladimir Sibirov, Tom Young
Hi All,
FWIW, the FBP implementation spreadsheet list that JPM mentions is online at
https://docs.google.com/spreadsheets/d/1n_wc2OoX4IOAACi5Iyt5HORs4nVhuTcYLxQkMK0u_08/edit
.
I regret not having updated this list in many years. As this is a Google Sheets application, anyone can suggest additions and changes or become and editor.
If interested, feel free to email me direct at f...@twyoung.com.
Cheers,
twy
On Jul 14, 2020, at 11:43 AM, Paul Morrison <jpau...@gmail.com> wrote:
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAHttgx7Uk9V_DkxQ535aPrtMqGgVzEJj4T2g4908_oBeULA_Vg%40mail.gmail.com.
Paul Morrison
Jul 14, 2020, 3:02:42 PM7/14/20
to flow-based-...@googlegroups.com
Thanks, Tom, that's amazing! I had no idea you had carried it so far!
Hope everything is going well with you,
Paul
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/147B67BD-961A-491A-A1FE-EA0B8F6BF013%40gmail.com.

Marjan Petkovski
Jul 14, 2020, 3:19:47 PM7/14/20
to flow-based-...@googlegroups.com
Hi Tom,
could you add www.easybots.net to the list?
I started it as a pet project for "FBP-like-helper" for
.NET
dev tasks, and it recently grew to a couple of hundred active users. Still in Beta, and only for windows, but I think might be helpful for fast automation of some dev tasks...
Regards,
Marjan.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAHttgx6ttk2teA79H0bZT0DhO0C6gYNkNK6Xhi%2BVhDzOLABtBw%40mail.gmail.com.

Tom Young
Jul 14, 2020, 4:01:27 PM7/14/20
to Flow Based Programming
If you go to:
you should be able to answer a few questions and add EasyBots to the list. Let me know if you have any problems.
twy <f...@twyoung.com>
Tom
Young
47 MITCHELL ST.
STAMFORD, CT 06902
When
bad men combine, the good must associate; ...
-Edmund
Burke 'Thoughts on the cause of the present discontents' , 1770
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAFw6Ow-Y4UhXy39tZ6q1oGygWLGJp6LZMbZfr0rW9kjiJThYSA%40mail.gmail.com.
Paul Morrison
Jul 14, 2020, 4:26:26 PM7/14/20
to Joe Witt, flow-based-...@googlegroups.com
Thanks for the kind words, Joe! Good way of looking at things!
I was beginning to think that there were two layers to FBP (at least): the basic concepts in FBP, and then other things which expand it, but other products might pick other extensions...
For instance, my first paper (the TDB, which I don't have a copy of, but would love to get one) stressed data-triggered asynchronous processes, but didn't stress enough the idea of IPs with well-defined lifetimes and unique ownership, which makes data behave more like things. I'm pretty sure NiFi's immutable IPs are another solution to the latter, but I think you have to have one or the other, as otherwise data becomes all mushy and hard to manage... 😉
Cheers,
Paul
Niclas Hedhman
Jul 14, 2020, 9:30:49 PM7/14/20
to flow-based-...@googlegroups.com
On Tue, Jul 14, 2020 at 11:43 PM Paul Morrison <jpau...@gmail.com> wrote:
There seem to be all sorts of flow-based products showing up, some being incubated by Apache, many not... Given the number of FBP-ish projects under Apache, is there any kind of "Apache-wide" attempt to consolidate them - and acknowledge prior art? And I believe NiFi was incubated under Apache (right terminology, Joe?).
Incubation in Apache = The process of bringing an external project into the Apache Software Foundation and teaching the community members how Apache projects operate, policies to follow, how to cut releases and so on. Most projects have been under Incubation at some point.
As for acknowledgement of prior art; I think that all these projects are unaware, and in fact would probably claim that they are not really FBP as such. Feel free to engage with these communities about this.
One of the problems seems to be terminology - for instance, your term "topology" seems to correspond to FBP's "network", whereas I use the term "topology" to refer to the general shape of a network... These language issues are going to pop up increasingly - especially now that flow-based programming is becoming an international movement!
So, I might have used terminology slightly wrong, not sure. But for Flink (which is my main experience), the "topology" is the logical view of the processing. Since "network" in most environments using Apache software would refer to the system that connects things physically, I suspect that "network" as a term for the shape of the processing will be a hard sell, because context has the term already.
I ran into a similar problem for my book, trying to find a general term for "unit of concurrency": on page ix of the Preface to the 2nd ed. of my book, I list 11, found just by Googling "unit of concurrency" - the weirdest IMO is "vat"! I finally settled on "process" - I think this corresponds to what Flink calls "stateful computation"...?
Sorry, I don't grasp what "unit of concurrency" is actually referring to. Flink is not capable of auto-detecting what can be parallelized, but once the programmer provides the information, the scale of parallelism (number of parallel paths) can be set in runtime, by human operators or algorithms.
Flink and Spark seem to use "batch" slightly differently from the conventional usage - "batch" is what programming was in the first few decades of my career! That was all we did in those days! Of course, what I think you would call "a batch" would in those days normally be a whole file: the first flow-based application to go live (mid-'70s) was processing millions of transactions and/or records every night, as a single batch! Now, of course, FBP supports interactive patterns comfortably - Facebook's Flux is a flow-based technology - see https://www.youtube.com/embed/i__969noyAM . Again, in the old days, there was a hard and fast distinction between "batch" and "online", with different software packages supporting them - FBP removes that distinction: in the FBP e-Brokerage app I worked on a few years ago (briefly described on pp. 205-207 of the 2nd ed.), it was interactive, but trades were sent to remote processing sites, called “back-ends”, where choice of back-end sites depended not only on the type of trade, but also even on the time of day. The remote processing sites could batch up trades as they saw fit, and respond asynchronously.
Yes, and Cobol had "jobs" as descriptions of which programs should be executed against which files/data, in what order at what times. Batch has somewhat survived in the Big Data eco-system, i.e. the Hadoop derived eco-system in Apache. Hadoop is, under the hood, a distributed, append-only file system (called HDFS), and "jobs" are run on such files, and the execution of the job is brought to the computer where the data is stored. Hadoop itself is a Map-Reduce system on top of the HDFS. Many other projects build on top of this paradigm, and I think that is how Spark started, you build an execution topology/network and in runtime give it one or more files, where each is a "batch".
Apache Storm was built (I think at Twitter) to solve the "batch latency", in that running the Hadoop jobs on the entire dataset each time took hours/days and Storm executed the same "function" as the map-reduce jobs, but did it on a continuous stream. At that company, this was combined into "Lambda Architecture", where the map-reduce Hadoop jobs were canonical and the Storm provided the delta since last MR job. The advantage, it was said, was that any bugs in the software would not corrupt the derived data, as the full transformation on the raw original data happened regularly, and without sacrificing latency.
In FBP potentially all streams are "endless", but, since we have never implemented hot switching of components (yet, AFAIK), streams normally have a beginning and an end... In FBP, we also have the capability of grouping IPs into nested batches, called "substreams", by using bracket IPs. The concepts of substreams and substream-sensitive ports are very powerful, and play well with checkpointing. You might find interesting the chapter on checkpointing in my book - Chap. 19 of the 2nd edition.
Hot Switching of components is not necessarily required. In Flink, one relies on a queueing system for inputs and outputs, so that from the topology/network point of view, the stream 'finished' and it is unloaded from memory, and the upgraded version will continue where the previous version left off. For stateful topologies/networks, the programmer is required to implement methods for saving/restoring state, and this is utilized for upgrades (but also for recovering from machine failures, rebalancing and other scenarios)
I don't think IPs have a central definition/meaning in the streaming projects at Apache.
Given all the Apache projects that seem to involve flow-based programming in some way, I am curious whether there is an ongoing effort to establish common ground between them, and maybe converge them. A number of people working in the FBP field over the years have tried to extract and highlight common concepts and develop categorizations for FBP and FBP-like projects: one such effort is https://github.com/flowbased/flowbased.org/wiki by Vladimir Sibirov; another is a spreadsheet developed by Tom Young, but I don't know how far he got with it... For a rough list (not up to date) of FBP-ish projects, see also https://jpaulm.github.io/fbp/links_external.html ...
Apache is not one codebase or even one community. It is a community of communities, where each project has full autonomy over its own destiny. Consolidation between similar projects are rare, albeit has happened a handful of times. I don't see that happen with Spark, Storm, Flink, NiFi and whatever other projects are in this space.
One last comment: I know my book is TLDR, but I got tired writing innumerable papers (which usually got rejected), where the first 3/4 would be an attempt to distill about 50 years (as of now) of experience with FBP technology (and I couldn't just assume that the reader already understood FBP), so I decided to just write a big book, and later a 2nd. edition. And yes, I know I talk about technologies that very few of today's programmers even know about... but they are almost certainly still in use somewhere! As witness the recent call for COBOL programmers (and, yes, I did write one COBOL program in my 60 years of programming, and, no, I don't want to write another one !).
:-) As recently as 2015, I was brought in to Deutsche Bank to help sort out the shutting down of a mainframe, to be replaced by commodity hardware and more modern software architectures. The problem at hand; 195,000 Cobol jobs and ~15-20,000 programs. And no one knew what these were doing at all. A team of ~10 Indians were responsible for maintenance, and my job was to establish dependency order between jobs, data inputs/outputs and intermediary files. And there was a modern tool from an Israeli company that built views of this mess. 100s of programs and data files missing... well... I hope I won't see anything like it again.
This post is probably also TLDR, so I'll stop here!Best regards, and thanks for your interest,
No problem, I can't engage fulltime, but I try to help out where I see I can provide information.
// Niclas
Niclas Hedhman
Jul 14, 2020, 9:42:36 PM7/14/20
to flow-based-...@googlegroups.com
Another resource in the IP space is the book "Enterprise Integration Patterns" [1] and Apache Camel is an (non-distributed) implementation of the concepts therein. The integration patterns[2] are many decades old.
I saw Talend in the list of FBP products/projects, and their ETL offering has Camel as the center building block, together with many other Apache, other open source and proprietary components.
[1] A rather seminal book in enterprise computing; https://en.wikipedia.org/wiki/Enterprise_Integration_Patterns
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAHttgx7-wBv5WPe%3Dt6_cjD6DRrWL4pVktx8%2BLgwpTkWQ0aUqCw%40mail.gmail.com.
Paul Morrison
Jul 15, 2020, 1:42:17 PM7/15/20
to flow-based-...@googlegroups.com
Thanks, Niclas, for a very complete answer! I can sense my head starting to explode! It will take a younger/smarter person than me to organize the concepts behind all these threads!
FBP has tended to develop organically, in the context of real applications, and it sounds like this is what happens in Apache, but usually we were under less pressure, starting with small teams. Plus we had an overarching architecture, so usually development did not involve infrastructure changes - just applications and componentry. If we were lucky, general components would sort of "fall out", benefiting everybody!
You're right, I just realized that "network" is another term with many different usages... I guess "diagram" might work, but "running a diagram" seems odd! There is/was a school of thought that suggested the industry use completely made-up terms to avoid any previous associations. I thought of "DPN" for "data process network", but turns out this is a skin condition... Suggestions, anyone?!
By "unit of concurrency", I meant that, if Flink is running streams of data through stateful computations, the latter have to be running asynchronously, so each stateful computation has to be a separate "process" or at least "thread"...
In my book, I reference something called "Apache Pig", and also "Cascading" in connection with Hadoop - don't know if they still exist...?
I don't understand how you can have "streaming" without IPs...?! I know IP could be "Intellectual Property".. but assuming that's not the problem, IMO streaming has to involve data in "chunks" - the von Neumann concept as data being something passive in a storage area doesn't cut it! FBP IPs have also gone through some name changes: the first name was "entity", but we realized that this conflicted with "entity" in Data-Driven Design, although of course they map onto each other...
I can relate to your story about Deutsche Bank... Some years ago, the US Navy (I think) found that many or most of their magnetic tapes were unreadable - not because they had deteriorated, but because the formats were defined in application programs, and nobody knew which tapes were read or written by which programs!
Thanks for the feedback! Maybe there will be a great convergence! Have I told you about Steven Traugott's 2006 article, called "The Convergence" - I think it was prescient! http://www.jpaulmorrison.com/cgi-bin/wiki.pl?TheConvergence . This is on my old C2-style wiki, so it's sort of a conversation...
Best regards,
Paul M.
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CADmm%2BKcYXE5tEWqBvG7McuNdhRcu%3D%3DMk6Ab%2BaY86D8KONcb0Xw%40mail.gmail.com.
Tom Young
Jul 15, 2020, 3:21:17 PM7/15/20
to Flow Based Programming
You're right, I just realized that "network" is another term with many different usages... I guess "diagram" might work, but "running a diagram" seems odd! There is/was a school of thought that suggested the industry use completely made-up terms to avoid any previous associations. I thought of "DPN" for "data process network", but turns out this is a skin condition... Suggestions, anyone?!
Some thought starters:
mesh flowmesh meshwork datashed[ala watershed] streamshed datagraph streamgraph datamesh datanet flowmatrix matrixflow flowmap cybernet cybergraph dataplexus(Dataplex is a co.)
My feeling is it would be impossible to arrange for consistent terminology across all FBP projects or even the say the top ten FBP projects. Therefore, I think you would need to have some compelling reason to change terminology mid-stream(so to speak). It is more important, I feel, that we authors do our best to be consistent within our projects, avoid aliases, provide clear definitions, etc..
Cheers,
twy

Sam Watkins
Jul 16, 2020, 12:54:27 AM7/16/20
to 'Alex Kelley' via Flow Based Programming
I like the idea to use short words, preferably one syllable.
So I was thinking to use these terms:
net a network proc a process tool a type of component, or class of proc (part?) pipe a connector port a file descriptor (in this implementation) thing an object pack an information packet type class of an object, a tool is the type of a proc flow a stream of packets bit the boolean type rel a relation
--You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CABv%3DvUf2OdbA6ghqC77veY8%3DTwdO-fVfPQV-Dwu7eEV_ijA6eQ%40mail.gmail.com.
Niclas Hedhman
Jul 16, 2020, 2:21:12 AM7/16/20
to flow-based-...@googlegroups.com
What I meant that IPs are not in focus is that they are more often than not just a packet of opaque content/bytes, where there is no "meaning" or "behavior" involved. Each consumer is somehow aware of the format and any implied behavior assigned.
I haven't read your book, but I get the impression on this list that IPs have a more central role...
As for concurrency in Flink; you can define ways to split the stream and they will be handled by a dynamic set of pipelines (possibly set at runtime), and the programmer provides the algorithm for how to determine which message goes to which split. For stateful systems, it is normally done by extracting some key and same key is guaranteed to go the same path each time. A large degree of freedom is provided.
Also, the programmer's logical view contains handing messages from node to node, but in the physical world, that can be in-process, inter-process on the same host or across the network. I think the idea is that Flink will try to optimize that, and for small topologies/nets/diagrams, they tend to end up in the same process.
Another interesting project is Wallaroo... Here the platform is written in Pony, which is a programming language with very interesting concurrency properties (worth a long post in itself, and the language I have written a back end with noflo protocol), but in Wallaroo each processing node is in the more "friendly" language Python. The platform probably qualifies for FBP classification, but I doubt that the developers are aware of it ...
Niclas
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAHttgx5K3yCDkwF2-e%3DA-8WmhpHoaHfrK0hsm-0srP6vS6fKgQ%40mail.gmail.com.
Niclas Hedhman
Jul 16, 2020, 2:24:58 AM7/16/20
to flow-based-...@googlegroups.com
Apache Pig is (IIRC) a query language for datasets in HDFS files. Batch processing in its finest. Apache Hive is similar thing, but with a more SQL like language structure.
I think both are intended for more of "discovery" type of workflows, possibly somewhat interactive.
In both cases, they basically construct MapReduce jobs and run those.
Niclas
On Thu, Jul 16, 2020, 01:42 Paul Morrison <jpau...@gmail.com> wrote:
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAHttgx5K3yCDkwF2-e%3DA-8WmhpHoaHfrK0hsm-0srP6vS6fKgQ%40mail.gmail.com.
Paul Morrison
Jul 16, 2020, 3:16:23 PM7/16/20
to flow-based-...@googlegroups.com
Hi Niclas,
Yes, we do think of IPs as "packets", but you are introducing another dimension which is interesting, but I think orthogonal to FBP concepts... This seems related to Denis Garneau's and my work on Business Data Types during my last stint at IBM - see https://jpaulm.github.io/busdtyps.html . This has in fact been a hot button of mine for years, but FBP's success is in large part due to our drawing definite boundaries around it!
So... IPs are only central in the sense that IMO FBP wouldn't work without that concept. I think there are two possible paths: 1) have IPs with defined lifetimes, and unique ownership at any point in time, or 2) make them immutable,
à
la NiFi. Ellis and Gibbs, in their 1989 paper, in the early days of OO, distinguished between "active objects" and "passive objects": the former are our processes, and the latter are IPs. They felt this distinction was necessary to ensure OO's usability in the long term...
Re concurrency, I would again argue that this concept is central to FBP, but at a logical level - the actual software and hardware mechanism can vary widely between implementations... e.g. green threads, red threads, and various hybrids...
Sorry for running on!
Cheers,
Paul
On Thu, Jul 16, 2020 at 2:21 AM Niclas Hedhman <nic...@hedhman.org> wrote:
What I meant that IPs are not in focus is that they are more often than not just a packet of opaque content/bytes, where there is no "meaning" or "behavior" involved. Each consumer is somehow aware of the format and any implied behavior assigned.I haven't read your book, but I get the impression on this list that IPs have a more central role...As for concurrency in Flink; you can define ways to split the stream and they will be handled by a dynamic set of pipelines (possibly set at runtime), and the programmer provides the algorithm for how to determine which message goes to which split. For stateful systems, it is normally done by extracting some key and same key is guaranteed to go the same path each time. A large degree of freedom is provided.Also, the programmer's logical view contains handing messages from node to node, but in the physical world, that can be in-process, inter-process on the same host or across the network. I think the idea is that Flink will try to optimize that, and for small topologies/nets/diagrams, they tend to end up in the same process.Another interesting project is Wallaroo... Here the platform is written in Pony, which is a programming language with very interesting concurrency properties (worth a long post in itself, and the language I have written a back end with noflo protocol), but in Wallaroo each processing node is in the more "friendly" language Python. The platform probably qualifies for FBP classification, but I doubt that the developers are aware of it ...NiclasOn Thu, Jul 16, 2020, 01:42 Paul Morrison <jpau...@gmail.com> wrote:Thanks, Niclas, for a very complete answer! I can sense my head starting to explode! It will take a younger/smarter person than me to organize the concepts behind all these threads!FBP has tended to develop organically, in the context of real applications, and it sounds like this is what happens in Apache, but usually we were under less pressure, starting with small teams. Plus we had an overarching architecture, so usually development did not involve infrastructure changes - just applications and componentry. If we were lucky, general components would sort of "fall out", benefiting everybody!You're right, I just realized that "network" is another term with many different usages... I guess "diagram" might work, but "running a diagram" seems odd! There is/was a school of thought that suggested the industry use completely made-up terms to avoid any previous associations. I thought of "DPN" for "data process network", but turns out this is a skin condition... Suggestions, anyone?!By "unit of concurrency", I meant that, if Flink is running streams of data through stateful computations, the latter have to be running asynchronously, so each stateful computation has to be a separate "process" or at least "thread"...In my book, I reference something called "Apache Pig", and also "Cascading" in connection with Hadoop - don't know if they still exist...?I don't understand how you can have "streaming" without IPs...?! I know IP could be "Intellectual Property".. but assuming that's not the problem, IMO streaming has to involve data in "chunks" - the von Neumann concept as data being something passive in a storage area doesn't cut it! FBP IPs have also gone through some name changes: the first name was "entity", but we realized that this conflicted with "entity" in Data-Driven Design, although of course they map onto each other...I can relate to your story about Deutsche Bank... Some years ago, the US Navy (I think) found that many or most of their magnetic tapes were unreadable - not because they had deteriorated, but because the formats were defined in application programs, and nobody knew which tapes were read or written by which programs!Thanks for the feedback! Maybe there will be a great convergence! Have I told you about Steven Traugott's 2006 article, called "The Convergence" - I think it was prescient! http://www.jpaulmorrison.com/cgi-bin/wiki.pl?TheConvergence . This is on my old C2-style wiki, so it's sort of a conversation...Best regards,Paul M.
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CADmm%2BKf16_-L7URRKZ-tRPkQ-2P18VKJfPcwqJt9FSPS4WVa3w%40mail.gmail.com.
Niclas Hedhman
Jul 16, 2020, 9:20:42 PM7/16/20
to flow-based-...@googlegroups.com
On Fri, Jul 17, 2020 at 3:16 AM Paul Morrison <jpau...@gmail.com> wrote:
Hi Niclas,Yes, we do think of IPs as "packets", but you are introducing another dimension which is interesting, but I think orthogonal to FBP concepts... This seems related to Denis Garneau's and my work on Business Data Types during my last stint at IBM - see https://jpaulm.github.io/busdtyps.html . This has in fact been a hot button of mine for years, but FBP's success is in large part due to our drawing definite boundaries around it!So... IPs are only central in the sense that IMO FBP wouldn't work without that concept. I think there are two possible paths: 1) have IPs with defined lifetimes, and unique ownership at any point in time, or 2) make them immutable, à la NiFi. Ellis and Gibbs, in their 1989 paper, in the early days of OO, distinguished between "active objects" and "passive objects": the former are our processes, and the latter are IPs. They felt this distinction was necessary to ensure OO's usability in the long term...Re concurrency, I would again argue that this concept is central to FBP, but at a logical level - the actual software and hardware mechanism can vary widely between implementations... e.g. green threads, red threads, and various hybrids...Sorry for running on!
No worries... I like these kinds of conversations.
The issue of "type of concurrency" is an interesting topic. And it is why I got such a strong interest in Pony. I think the language itself has the core tenets of FBP, yet allows for (without compromising data integrity or race conditions) mutable IPs to be passed as messages, and doing these guarantees at compile-time. Unfortunately, the "reference capabilities" that enable this are not for the faint-hearted and require some masochism to learn and to become instinctive to one's programmer nature (I am not there yet). BUT, once there, doing thread-safe, race condition free, FBP is a breeze unlike Java, C or most other languages.
I can recommend; https://www.youtube.com/watch?v=9NH4bVfbvYI
Or a whole playlist; https://www.youtube.com/playlist?list=PLd5vi9zrQ1GKSg0uqp_NN1KeKwniDjUg6

John Cowan
Jul 17, 2020, 12:56:11 PM7/17/20
to Flow Based Programming
I looked into Pony: it is an actor language, which means that there is only one input connection, unlike classical FBP which allows multiple input connections.
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CADmm%2BKch%3DnxDM%2B662_EBPShf-mxJH%3DEeMm2kr_Q87xn_%3DogzfA%40mail.gmail.com.
Niclas Hedhman
Jul 17, 2020, 9:38:24 PM7/17/20
to flow-based-...@googlegroups.com
What do you mean by "one input"?
Actors guarantee that only one message is processed at a time, but the message abstraction is the "function", called "behavior" in Pony actors. Each call to a "behavior" will queue a message in the inbox and process it in arrival order. This is somewhat different from Erlang, where the user will read each message, pattern match the content to do something. Erlang also allows messages to be processed out-of-order, as the programmer is in full control of the inbox. Not so in Pony, because the cross-actor garbage collection mechanism relies on causal (not casual) ordering.
Niclas
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAD2gp_RRfwG%2BgR0jcdLvzVR%2BkT8XeMTg0SkoRmo-XYEji8R4Pg%40mail.gmail.com.
John Cowan
Jul 17, 2020, 10:38:01 PM7/17/20
to Flow Based Programming
FBP does not have a concept of "the inbox". Rather, a single-threaded component has access to as many input connections as it has been configured for, and can read from any of them. This is exactly like the way in which a Posix or Windows process can have multiple files (or pipes) open and can choose to read from whichever one it wants to at any given moment. If no information packets are available on that particular connection, the component will stall until there is one.
Current classical FBP systems do not have a concept of reading from multiple connections at the same time, such that whichever one has data available will unblock the process, the analogue of Posix select(), but it doesn't break the model to provide such a facility.
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CADmm%2BKdfOJRbbBWRMjs3gL_p2tEPxkynKpjNjt6M4USGaUG2ag%40mail.gmail.com.
Niclas Hedhman
Jul 18, 2020, 12:59:58 AM7/18/20
to flow-based-...@googlegroups.com
I think you have just claimed that FBP is not the paradigm for most messaging systems that Paul claims are FBP derived. I don't really care about semantics, and the difference between push and pull, concurrency models, implementation details under the hood and so on. For me, the matter is that data-flow, block-centric, programming is easier to do with actor-based languages than without. You may disagree, and take a staunch position on what MUST be present for it to be called FBP. I'll let you have that battle with Paul... ;-)
Cheers
Niclas
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CAD2gp_RB%3DRiX5eKX%3DE0gaSC6fu%2B3ztHEvJBgmEXtyyAm9X3vVg%40mail.gmail.com.
Paul Morrison
Jul 18, 2020, 10:53:19 AM7/18/20
to flow-based-...@googlegroups.com
Hi Niclas, you may have misunderstood! John and I are certainly not battling - in fact, John was one of the earliest FBP supporters, and in fact wrote the first Java implementation of FBP. I totally agree with everything he has said!
I am also not sure which systems you are referring to that you say I claim are FBP-derived - I assume you are referring to Node-RED, etc., but I may be wrong... I don't actually use the term "FBP-derived".
What I think happened is that a number of people ran into the FBP concepts, and figured that they could get the same results using conventional "call" logic. This results in what Joe Witt calls "FBP-like" or "FBP-inspired" systems, and my experience is that these systems do not embody the "FBP paradigm shift", and do not give the desired results. In fact, I personally find them harder to think with, rather than easier, unlike my experience with classical FBP. If, as you say, for you "the matter is that data-flow, block-centric, programming is easier to do with actor-based languages than without", then I believe FBP should feel very comfortable for you. What I believe are the original "actors" (Hewitt, 1993) carry the concept to a level of granularity which I feel may be too fine-grained for practical use, but a FBP process could be viewed as a type of actor, in which case we are probably on roughly the same wavelength!
One last point: this restriction of only allowing one input port is characteristic of "FBP-like" systems, and IMO arises naturally out of trying to implement FBP using a call structure... Proponents of such systems that I have talked to don't seem to have run into problems that require multiple input ports, so the reaction is "Why would I need that". So they have to be challenged with a problem that does need that. I therefore did a comparison for one simple problem (Concatenate streams) using JSFBP, the JavaScript implementation of FBP (which uses node-fibers), and NoFlo, an FBP-derived system. Here is the link: https://jpaulm.github.io/fbp/concat.html . Note that the NoFlo implementation is not only more complex, but also requires all the data to be held in storage, which is not required for JSFBP or other classical FBP systems.
Cheers,
Paul
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/CADmm%2BKfQPNfHfDsQs%3D9FTXhdz_PpY6PErbDg9K2vH1RA_iUXHw%40mail.gmail.com.
Paul Morrison
Dec 16, 2020, 3:20:49 PM12/16/20
to Flow Based Programming
Hi Tom,
I just Googled "Flow-Based Programming" and I am amazed at how many references to various flavours of FBP are out there now, including two flavours of "Awesome"! I have tweeted Samuel Lampa to ask if these two can be combined...
One big split has always seemed to me to be multithreading vs. non-multithreading. Since most of the FBP flavours out there seem (I may be wrong) to be JavaScript-based, I would put them in the non-multithreading category... unless they use Thread workers. I am aware that "multithreading" is ambiguous, but what I am interested in here is whether such flavours can support multiple processors, and if so, how...? Could we add a column for this attribute, or whatever name seems appropriate to you?
Two (probably related) attributes are whether the project supports a) multiple input ports with "receive on demand", and b) back pressure...
TIA and best regards,
Paul
Tom Young
Dec 17, 2020, 2:13:21 PM12/17/20
to Flow Based Programming
Hi Paul,
I will consider adding the FBP characteristics, like multi-threading, you mentioned to the Google FBP spreadsheet, but may not be able to get to it.
It was my hope that others would help maintain the sheet and some have. It would be great to have more authors
than just you and me, also. There are now enough FBP and "FBP-derived" projects extant and emerging to keep our heads spinning indefinitely. My conclusion is that you have succeeded, directly and indirectly, in what i think is your primary goal: to bring the benefits and understanding of FBP to a significantly sized segment of the development community. This understanding should be incorporated in every Computer Science curriculum.
Enjoy the Holidays!
--twy
Tom
Young
3013 Aura Lane
Summerville, SC 29483
When
bad men combine, the good must associate; ...
-Edmund
Burke 'Thoughts on the cause of the present discontents' , 1770
To view this discussion on the web visit https://groups.google.com/d/msgid/flow-based-programming/b77429b5-ca8b-404e-8d60-7157fcf08204n%40googlegroups.com.
Paul Morrison
Dec 19, 2020, 11:12:23 AM12/19/20
to flow-based-...@googlegroups.com
Hi Tom, thanks for the kind words! FBP certainly seems to be spreading like a weed!
You're right - there are now so many FBP and "FBP-derived" projects out there that it is going to be quite daunting to figure out what are their differences and similarities/advantages and disadvantages! I think your matrix is a very good start at listing and categorizing them, and we (and other FBP aficionados) will be able to add more rows (and columns as needed) as we run into them. Many thanks for getting the ball rolling!
All the best, and stay safe!
Paul
You're right - there are now so many FBP and "FBP-derived" projects out there that it is going to be quite daunting to figure out what are their differences and similarities/advantages and disadvantages! I think your matrix is a very good start at listing and categorizing them, and we (and other FBP aficionados) will be able to add more rows (and columns as needed) as we run into them. Many thanks for getting the ball rolling!
All the best, and stay safe!
Paul
Hi All,
TIA
Paul Morrison
Dec 24, 2020, 1:32:21 PM12/24/20
to Flow Based Programming
Re Tom's post about the many FBP and FBP-related variants out there now...
The following is an attempt to bring some FBP concepts down to first principles... and to try to explain why I keep harking back to the difficulty of implementing FBP without multithreading, and why I suggested to Tom that we need to add this attribute to his FBP spreadsheet. This article may ramble a bit as my thinking changed a bit as I was writing it! :-) Feel free to come up with counterexamples!
Granted, I am only familiar with a few of the modern programming languages, but I believe that any language which supports threads can support "classical" FBP.
My contention is that there is one essential feature that is needed to support FBP, and that is multiple stacks... In multithreading languages, every thread has its own stack, so these languages aren't a problem. Although the basic requirement is multiple stacks, you need to be able to switch between them within the language, so you really need some kind of multithreading support. So, I have implementations among my GitHub repos for Java, C#, and C++ (using Boost) which in turn supports Lua, and probably there will be others in the future. What would have been nice would have been a multithreaded JavaScript: my JS FBP implementation is based on multiple-stack support for JS by Marcel Laverdet called node-fibers (now "Fiber"), but node-fibers doesn't really fit with the main thrust of JS, and may disappear before it can be widely adopted - see below.
What is rather strange is that two of the most popular *FBP-like* approaches (to use Joe Witt's suggested term) - NoFlo and Node-RED - are both based on JS, a programming language which IMHO is inappropriate for FBP. JS has Worker threads and Shared threads (?), but it seems that using them would result in prohibitively slow performance. In an article talking about Worker threads by Alberto Gimeno - https://blog.logrocket.com/node-js-multithreading-what-are-worker-threads-and-why-do-they-matter-48ab102f8b10/ - there is a section entitled "Why we will never have threads in JavaScript". There is also a longish discussion on https://github.com/jpaulm/jsfbp/issues/14 .
While I deeply appreciate Henri Bergius' proselytizing skills for putting many of the concepts of FBP on the map (something I never seemed able to do!), it bothers me that NoFlo is still so deeply rooted in the von Neumann paradigm. Without multiple threads, both systems (NoFlo and Node-RED) take a rather convoluted, von Neumann-ish approach to providing some, but not all, of the capabilities of FBP: configurable modularity, asynchronism, separation of concerns between components, but not well-defined lifetimes and ownership of data chunks... The fact that neither of these systems allow more than one input port per process, and also allow one-to-many connections, suggests that the choice of language trumped FBP thinking.
I do understand why von Neumann thinking has such a hold on the IT industry, despite its shortcomings. The thinking goes something like this: "Since the von Neumann architecture can do anything, any problems I have building or maintaining my app must have to do with my own shortcomings, not those of the architecture...", and maybe, "What other way is there to design a computer?" - I remember that, in the early days of computing, we were more open to other architecture possibilities... I would much rather have ("real") FBP be the first paradigm that people encounter when coming into the field for the first time, followed by procedural code, rather than the reverse. Our experience with FBP is that it is most readily accepted by people who are not brain-washed by traditional, von Neumann, thinking *or* people who have so much experience with it that they have become frustrated with it - this is described exactly in Kuhn's "The Structure of Scientific Revolutions". My personal experience supports this, as my first DP environment wasn't even computer-based: it was IBM's Unit Record, which was, as I say in my book, much more similar to FBP than to conventional programming. As a number of people have said, this means that you have to catch the kids young - before they have time to pick up bad von Neumann-ish habits! Maybe a Scratch-like product that is explicitly Flow-Based. At the very least, as Tom says, FBP should be part of every CS curriculum - you mean, it isn't...?!
The basic problem, as I have always viewed it, is that "real" FBP is an industrial metaphor: individual machines connected by conveyor belts, so each "machine" has to maintain its own internal context. What good would it do if the bottle capper had to share time and resources with the filling machine?! Much of the power of FBP comes from the fact that these contexts *cannot* interfere with each other. How do you ensure that? IMO the only way is to let each process have its own state, represented by its stack: in multithreaded environments, this happens automatically because each thread has its own stack, and you can switch easily between threads. Without multithreading, but with multiple stacks, you have to resort to hardware-dependent code to switch stacks - you can see an example of this in https://github.com/jpaulm/threadn/blob/master/src/services/thzsstk.asm . Without multithreading *or* multiple stacks, things get pretty convoluted! JS gurus have managed to find ways to do some FBP-like things, but they ain't easy!
On the other hand, to support multiple cores and shared storage, I admit you do need some fairly complex locking... but this happens under the covers, and is invisible to the user when using FBP, as it all happens in the infrastructure. Components in FBP just see "send"s and "receive"s. This architecture is called "red threads", and seems to lend itself naturally to "real FBP". So, my implementations of FBP on Github except for JSFBP are all "red" thread implementations - https://github.com/jpaulm .
Now, going back in time a little: We developed the first production FBP system, called AMPS, back in the early '70s, and it was in continuous production use for at least 40 years. It was written in IBM's HLASM, and, yes, it had multiple stacks. However, it used "green" threads, so context switches only occurred at service calls, rather than potentially occurring between any pair of instructions, and all I/O was asynchronous (courtesy of IBM software), so no complex locking was required. This was perfectly adequate for production, and indeed AMPS applications performed better than applications written using conventional, synchronous, technology, mainly because a non-FBP program could be held up while a single I/O request was going on (this could even happen with QSAM!), while with AMPS you could have any number of I/O requests proceeding concurrently.
So as long as you have multiple stacks, "green" threads work very well *on one core*... In this approach, you have a "future events queue", where you park contexts that are waiting to execute. This is in fact how simulation systems work...
I used this approach for my JavaScript FBP implementation - https://github.com/jpaulm/jsfbp - using Marcel Laverdet's "node-fibers" (now apparently called "Fiber"). This works very well on one core, and it's a nice simple mental model, perfectly in line with "real FBP". On the other hand, when you don't have multiple stacks, there is another restriction on FBP-like JS implementations: I think it's called the "top frame" limitation - it means that you can only send or receive in the top frame of the process. Clearly, if you allowed sends and receives from a lower level in any stack, you would have to maintain the state of all levels above it... That's a non-problem when you have multiple stacks...
However the liftetime of JSFBP is probably limited: Marcel warns that node-fibers may suddenly stop working due to the complexity of the NodeJS ecosystem. Chris Hawkes in "Why Programmers Hate the JavaScript Ecosystem" - https://www.youtube.com/watch?v=VpWJId1pKdg - has pointed out the huge number of dependencies that get dragged into a JS application. I notice that JSFBP has waaay more PRs (133) and commits (681) than any of my other implementations (very few of them due to my enhancements or bug fixes), mainly because of almost continuous enhancements to eslint, vulnerabilities in indirectly dependent JS packages, etc., etc.
On the other hand, JavaScript is still popular, possibly because it's the language du jour, and/or because it plays nicely with HTML5, and people seem to want the server and client languages to be the same... What's so difficult about learning more than one language?!!! Look at https://github.com/jpaulm/javafbp-websockets - it uses JavaScript in the client and JavaFBP in the server, so both languages play to their strengths!
If you look at TIOBE, JavaScript is still at #7, while Java is #2, having changed places with C over the last year. IMHO JavaScript is never going to make it much above #7. I was relieved to learn recently that, like me, large numbers of people cordially dislike JavaScript, so maybe we can agree to let the JS-based FBP-like systems wither away, at least with respect to long-running batch or servers, and switch to more productive threads-based "real FBP" implementations...
It may seem strange that I am saying that batch jobs (and servers) need multithreading, considering that there were handled for years by control-flow von Neumann programs... but they were (are) very hard to maintain, and couldn't take advantage of multiple cores. It starts to make more sense if you think of a program built using FBP as a *simulation* of a factory that processes data, rather than bottles... Threads are a bit of a blunt instrument - basically for FBP the basic requirement is to have multiple stacks and a way of switching between them. However, threads let us take advantage of multiple cores, which will become increasingly important over the next few years, and it also gives us multiple stacks... for free!
Because of their control-flow orientation, FBP-like implementations also usually can't handle more than one input port on a process - the originator of Node-RED told me "he hadn't run into that requirement yet"! John Cowan says the following with respect to this architecture: "...each component is controlled by its upstream partner(s) rather than being autonomous. " See the discussions in https://jpaulm.github.io/fbp/fbp-inspired-vs-real-fbp.html and https://jpaulm.github.io/fbp/concat.html . As I have said many times before, "real FBP" is a real paradigm change, and you need to leave your von Neumann habits at the door - or better still, never have learnt them! Meanwhile, we have JavaFBP, C#FBP, and CppFBP, and probably more multithreading languages to come - I know many people are working on FBP implementations, in particular for Python - see https://wiki.python.org/moin/FlowBasedProgramming , which I would expect (hope) mostly use multithreading!
The article https://en.wikipedia.org/wiki/List_of_concurrent_and_parallel_programming_languages, and especially https://en.wikipedia.org/wiki/List_of_concurrent_and_parallel_programming_languages#Multi-threaded, gives a huge list of languages supporting multithreading, so hopefully one of these will be the next JavaScript... From this list, Clojure, Go and Rust seem to be creating the most buzz! Clojure is interoperable with Java - OTOH we already have JavaFBP, so why bother with Clojure unless you want LISP-like constructs. Elixir?
Last comment: diagramming data flow is different from running it! Duh! DrawFBP could easily be extended to support any number of FBP implementations, including "FBP-like"... and presumably, with some tweaks, the diagramming tools for FBP-like systems could be extended to support "real FBP" implementations...
That is enough for now (too much, probably!) - sorry about the rant!
The following is an attempt to bring some FBP concepts down to first principles... and to try to explain why I keep harking back to the difficulty of implementing FBP without multithreading, and why I suggested to Tom that we need to add this attribute to his FBP spreadsheet. This article may ramble a bit as my thinking changed a bit as I was writing it! :-) Feel free to come up with counterexamples!
Granted, I am only familiar with a few of the modern programming languages, but I believe that any language which supports threads can support "classical" FBP.
My contention is that there is one essential feature that is needed to support FBP, and that is multiple stacks... In multithreading languages, every thread has its own stack, so these languages aren't a problem. Although the basic requirement is multiple stacks, you need to be able to switch between them within the language, so you really need some kind of multithreading support. So, I have implementations among my GitHub repos for Java, C#, and C++ (using Boost) which in turn supports Lua, and probably there will be others in the future. What would have been nice would have been a multithreaded JavaScript: my JS FBP implementation is based on multiple-stack support for JS by Marcel Laverdet called node-fibers (now "Fiber"), but node-fibers doesn't really fit with the main thrust of JS, and may disappear before it can be widely adopted - see below.
What is rather strange is that two of the most popular *FBP-like* approaches (to use Joe Witt's suggested term) - NoFlo and Node-RED - are both based on JS, a programming language which IMHO is inappropriate for FBP. JS has Worker threads and Shared threads (?), but it seems that using them would result in prohibitively slow performance. In an article talking about Worker threads by Alberto Gimeno - https://blog.logrocket.com/node-js-multithreading-what-are-worker-threads-and-why-do-they-matter-48ab102f8b10/ - there is a section entitled "Why we will never have threads in JavaScript". There is also a longish discussion on https://github.com/jpaulm/jsfbp/issues/14 .
While I deeply appreciate Henri Bergius' proselytizing skills for putting many of the concepts of FBP on the map (something I never seemed able to do!), it bothers me that NoFlo is still so deeply rooted in the von Neumann paradigm. Without multiple threads, both systems (NoFlo and Node-RED) take a rather convoluted, von Neumann-ish approach to providing some, but not all, of the capabilities of FBP: configurable modularity, asynchronism, separation of concerns between components, but not well-defined lifetimes and ownership of data chunks... The fact that neither of these systems allow more than one input port per process, and also allow one-to-many connections, suggests that the choice of language trumped FBP thinking.
I do understand why von Neumann thinking has such a hold on the IT industry, despite its shortcomings. The thinking goes something like this: "Since the von Neumann architecture can do anything, any problems I have building or maintaining my app must have to do with my own shortcomings, not those of the architecture...", and maybe, "What other way is there to design a computer?" - I remember that, in the early days of computing, we were more open to other architecture possibilities... I would much rather have ("real") FBP be the first paradigm that people encounter when coming into the field for the first time, followed by procedural code, rather than the reverse. Our experience with FBP is that it is most readily accepted by people who are not brain-washed by traditional, von Neumann, thinking *or* people who have so much experience with it that they have become frustrated with it - this is described exactly in Kuhn's "The Structure of Scientific Revolutions". My personal experience supports this, as my first DP environment wasn't even computer-based: it was IBM's Unit Record, which was, as I say in my book, much more similar to FBP than to conventional programming. As a number of people have said, this means that you have to catch the kids young - before they have time to pick up bad von Neumann-ish habits! Maybe a Scratch-like product that is explicitly Flow-Based. At the very least, as Tom says, FBP should be part of every CS curriculum - you mean, it isn't...?!
The basic problem, as I have always viewed it, is that "real" FBP is an industrial metaphor: individual machines connected by conveyor belts, so each "machine" has to maintain its own internal context. What good would it do if the bottle capper had to share time and resources with the filling machine?! Much of the power of FBP comes from the fact that these contexts *cannot* interfere with each other. How do you ensure that? IMO the only way is to let each process have its own state, represented by its stack: in multithreaded environments, this happens automatically because each thread has its own stack, and you can switch easily between threads. Without multithreading, but with multiple stacks, you have to resort to hardware-dependent code to switch stacks - you can see an example of this in https://github.com/jpaulm/threadn/blob/master/src/services/thzsstk.asm . Without multithreading *or* multiple stacks, things get pretty convoluted! JS gurus have managed to find ways to do some FBP-like things, but they ain't easy!
On the other hand, to support multiple cores and shared storage, I admit you do need some fairly complex locking... but this happens under the covers, and is invisible to the user when using FBP, as it all happens in the infrastructure. Components in FBP just see "send"s and "receive"s. This architecture is called "red threads", and seems to lend itself naturally to "real FBP". So, my implementations of FBP on Github except for JSFBP are all "red" thread implementations - https://github.com/jpaulm .
Now, going back in time a little: We developed the first production FBP system, called AMPS, back in the early '70s, and it was in continuous production use for at least 40 years. It was written in IBM's HLASM, and, yes, it had multiple stacks. However, it used "green" threads, so context switches only occurred at service calls, rather than potentially occurring between any pair of instructions, and all I/O was asynchronous (courtesy of IBM software), so no complex locking was required. This was perfectly adequate for production, and indeed AMPS applications performed better than applications written using conventional, synchronous, technology, mainly because a non-FBP program could be held up while a single I/O request was going on (this could even happen with QSAM!), while with AMPS you could have any number of I/O requests proceeding concurrently.
So as long as you have multiple stacks, "green" threads work very well *on one core*... In this approach, you have a "future events queue", where you park contexts that are waiting to execute. This is in fact how simulation systems work...
I used this approach for my JavaScript FBP implementation - https://github.com/jpaulm/jsfbp - using Marcel Laverdet's "node-fibers" (now apparently called "Fiber"). This works very well on one core, and it's a nice simple mental model, perfectly in line with "real FBP". On the other hand, when you don't have multiple stacks, there is another restriction on FBP-like JS implementations: I think it's called the "top frame" limitation - it means that you can only send or receive in the top frame of the process. Clearly, if you allowed sends and receives from a lower level in any stack, you would have to maintain the state of all levels above it... That's a non-problem when you have multiple stacks...
However the liftetime of JSFBP is probably limited: Marcel warns that node-fibers may suddenly stop working due to the complexity of the NodeJS ecosystem. Chris Hawkes in "Why Programmers Hate the JavaScript Ecosystem" - https://www.youtube.com/watch?v=VpWJId1pKdg - has pointed out the huge number of dependencies that get dragged into a JS application. I notice that JSFBP has waaay more PRs (133) and commits (681) than any of my other implementations (very few of them due to my enhancements or bug fixes), mainly because of almost continuous enhancements to eslint, vulnerabilities in indirectly dependent JS packages, etc., etc.
On the other hand, JavaScript is still popular, possibly because it's the language du jour, and/or because it plays nicely with HTML5, and people seem to want the server and client languages to be the same... What's so difficult about learning more than one language?!!! Look at https://github.com/jpaulm/javafbp-websockets - it uses JavaScript in the client and JavaFBP in the server, so both languages play to their strengths!
If you look at TIOBE, JavaScript is still at #7, while Java is #2, having changed places with C over the last year. IMHO JavaScript is never going to make it much above #7. I was relieved to learn recently that, like me, large numbers of people cordially dislike JavaScript, so maybe we can agree to let the JS-based FBP-like systems wither away, at least with respect to long-running batch or servers, and switch to more productive threads-based "real FBP" implementations...
It may seem strange that I am saying that batch jobs (and servers) need multithreading, considering that there were handled for years by control-flow von Neumann programs... but they were (are) very hard to maintain, and couldn't take advantage of multiple cores. It starts to make more sense if you think of a program built using FBP as a *simulation* of a factory that processes data, rather than bottles... Threads are a bit of a blunt instrument - basically for FBP the basic requirement is to have multiple stacks and a way of switching between them. However, threads let us take advantage of multiple cores, which will become increasingly important over the next few years, and it also gives us multiple stacks... for free!
Because of their control-flow orientation, FBP-like implementations also usually can't handle more than one input port on a process - the originator of Node-RED told me "he hadn't run into that requirement yet"! John Cowan says the following with respect to this architecture: "...each component is controlled by its upstream partner(s) rather than being autonomous. " See the discussions in https://jpaulm.github.io/fbp/fbp-inspired-vs-real-fbp.html and https://jpaulm.github.io/fbp/concat.html . As I have said many times before, "real FBP" is a real paradigm change, and you need to leave your von Neumann habits at the door - or better still, never have learnt them! Meanwhile, we have JavaFBP, C#FBP, and CppFBP, and probably more multithreading languages to come - I know many people are working on FBP implementations, in particular for Python - see https://wiki.python.org/moin/FlowBasedProgramming , which I would expect (hope) mostly use multithreading!
The article https://en.wikipedia.org/wiki/List_of_concurrent_and_parallel_programming_languages, and especially https://en.wikipedia.org/wiki/List_of_concurrent_and_parallel_programming_languages#Multi-threaded, gives a huge list of languages supporting multithreading, so hopefully one of these will be the next JavaScript... From this list, Clojure, Go and Rust seem to be creating the most buzz! Clojure is interoperable with Java - OTOH we already have JavaFBP, so why bother with Clojure unless you want LISP-like constructs. Elixir?
Last comment: diagramming data flow is different from running it! Duh! DrawFBP could easily be extended to support any number of FBP implementations, including "FBP-like"... and presumably, with some tweaks, the diagramming tools for FBP-like systems could be extended to support "real FBP" implementations...
That is enough for now (too much, probably!) - sorry about the rant!
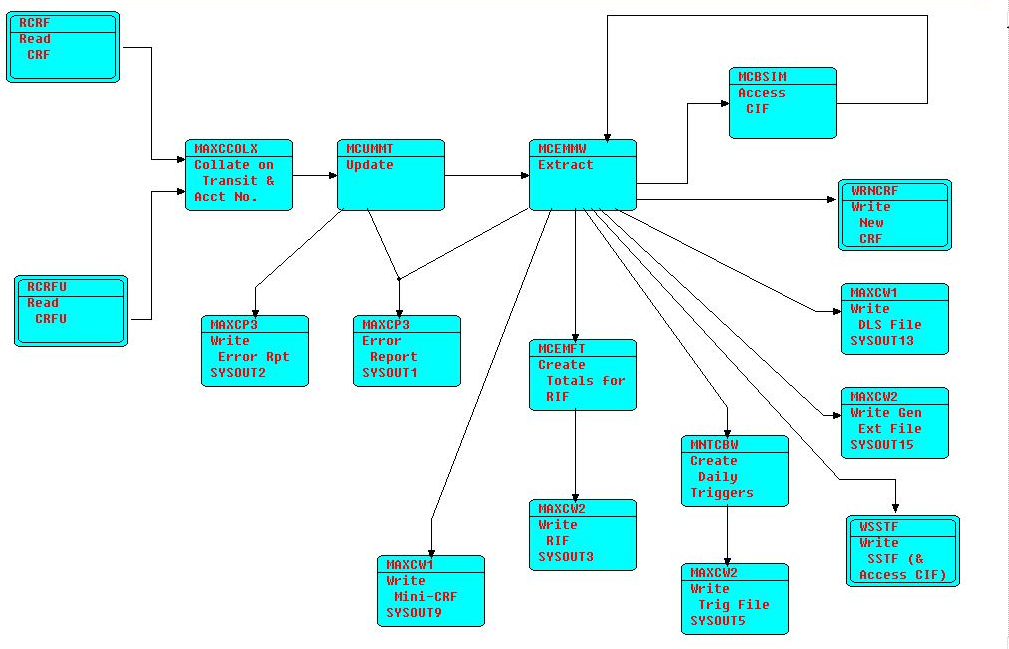
Here is a picture of *one third* of an AMPS production application, coded in the '70s, and processing millions of transactions every night for 40 years - worked like a charm, and was continuously maintained to support changing requirements during all of that time, in many cases by kids who weren't even born when it went into production! Any FBP implementation should be able to run this diagram - that could be a litmus test!
Reply all
Reply to author
Forward
0 new messages