LLL merge
178 views
Skip to first unread message

Bill Hart
Sep 21, 2014, 7:39:03 PM9/21/14
to flint-devel, Claus Fieker
Hi all,
I've been busy merging Abhinav's LLL code. There's still a small amount of refactoring to be done, and I haven't done a final check of a few of the algorithms against the literature, but the code is at least in good shape and seems to work well. It's usable now (the refactoring won't affect the user interface).
I have re-timed the benchmark against fpLLL. I noticed one small bug in the profiling code (to do with the delta-eta pair), which I've fixed. Otherwise I think the timings are ok now.
The benchmark uses random integer relations matrices of various dimensions and entry sizes. The exact same matrices are used for both fplll and flint.
fplll-4.0.4 flint-2.5
========= =========
d = 32 d = 32
bits = 320 bits = 320
cpu(s) : 0.06 cpu(s) : 0.04
bits = 640 bits = 640
cpu(s) : 0.13 cpu(s) : 0.1
bits = 960 bits = 960
cpu(s) : 0.19 cpu(s) : 0.16
bits = 1280 bits = 1280
cpu(s) : 0.24 cpu(s) : 0.22
d = 64 d = 64
bits = 640 bits = 640
cpu(s) : 1.02 cpu(s) : 0.84
bits = 1280 bits = 1280
cpu(s) : 2.12 cpu(s) : 1.82
bits = 1920 bits = 1920
cpu(s) : 3.3 cpu(s) : 2.97
bits = 2560 bits = 2560
cpu(s) : 4.5 cpu(s) : 4.48
d = 96 d = 96
bits = 960 bits = 960
cpu(s) : 5.24 cpu(s) : 4.69
bits = 1920 bits = 1920
cpu(s) : 11.68 cpu(s) : 10.78
bits = 2880 bits = 2880
cpu(s) : 18.75 cpu(s) : 17.77
bits = 3840 bits = 3840
cpu(s) : 26.01 cpu(s) : 27.64
d = 128 d = 128
bits = 1280 bits = 1280
cpu(s) : 17.8 cpu(s) : 16.27
bits = 2560 bits = 2560
cpu(s) : 42.57 cpu(s) : 38.32
bits = 3840 bits = 3840
cpu(s) : 70.44 cpu(s) : 66.07
bits = 5120 bits = 5120
cpu(s) : 101.36 cpu(s) : 108.37
d = 160 d = 160
bits = 1600 bits = 1600
cpu(s) : 46.56 cpu(s) : 42.33
bits = 3200 bits = 3200
cpu(s) : 120.72 cpu(s) : 109.62
bits = 4800 bits = 4800
cpu(s) : 199.08 cpu(s) : 196
So the times seem very comparable indeed.
Our ULLL doesn't really do anything for these timings, since that is designed for knapsack lattices where the target lattice is very small compared to the input lattice.
But it is nice to know our LLL wrapper function is comparable with fplll (which I would consider the gold standard) over a wide range of input.
I think it should take at most 1-2 more days to finalise everything. But it is there in my repo right now and can be used.
The functions you want to call are either fmpz_lll or fmpz_lll_wrapper (the former uses ULLL).
If you have a basis and just want to use default parameters, just call fmpz_lll_context_init_default to initialise an fmpz_lll_t context object. It will cause LLL to reduce with parameters (delta, eta) = (0.51, 0.99).
Congratulations again to Abhinav Baid for his amazing effort over the summer. In total there's 17,000 lines of code in the LLL implementation.
Bill.
Bill Hart
Sep 23, 2014, 10:12:54 AM9/23/14
to flint-devel, Claus Fieker, Wolfram Decker, Burcin Erocal
I've now finished reviewing the new LLL code for flint, written by Abhinav Baid, our GSoC scholar.
I now consider it to be in a complete state. Mostly this just came down to adding links to the appropriate papers, especially the reducedness testing of Villard, the three times working precision dot product of Ogita, Rump, Oishi, the GSO and QR algorithms of Schwarz-Rutishauser and some refactoring (renaming fmpz_mat_lll to fmpz_mat_lll_original and removing the fmpq_lll_t which might get confused with the ordinary fmpz_lll_t) and making some very small code cleanup changes.
Given that there's 17,000 lines of code, it required remarkably little work to merge it!
As Abhinav points out, our wrapper function (which automatically chooses a LLL strategy) could be improved somewhat. It's pretty basic compared to the one in fplll. But it is certainly sufficient.
At this point I think the LLL is ready for some serious work.
Some people might be interested to know what the LLL strategy is. So I summarise it here as best I can:
* The user first picks a (delta, eta) pair for reduction (using fmpz_lll_context_init), or uses the default (delta, eta) = (0.51, 0.99) (using fmpz_lll_context_init_default). Similarly the user picks a representation type Z_BASIS or GRAM which says how their input lattice is represented. If Z_BASIS is selected, one can choose how the internal gram matrix will be represented, either exactly or approximately, by specifying a gram type of either EXACT or APPROX.
* The user then calls fmpz_lll, or if they want to remove vectors the square of whose Gram-Schmidt length exceeds a certain bound, they call fmpz_lll_with_removal.
* The main LLL algorithm used by fmpz_lll is the ULLL algorithm (fmpz_lll_with_removal_ulll). This works by truncating the input entries so only the high bits remain. An identity matrix is then adjoined. The fmpz_lll_wrapper(_with_removal_knapsack) function is then called on this adjusted data. The identity matrix will now contain the transformations that were applied by LLL to the truncated data. We now use matrix multiplication to apply these transformations to the original data. This strategy works very well if the target lattice is very small compared to the input data.
Note: if the user is not interested in ULLL or removals, they can call directly into the fmpz_lll_wrapper function. From this point we describe this function, however note that ULLL actually calls specially modified versions of the following for knapsack lattices.
* The fmpz_lll_wrapper function tries to LLL reduce the input lattice using increasing precision. The first attempt is with fmpz_lll_d which by default uses a double precision approximation to the GSO but applies any updates to exact lattice basis vectors. This is the same strategy used by the fplll library, from which some of the code is derived.
* The wrapper then checks to see if the lattice is reduced, using fmpz_lll_is_reduced. This first tries to prove reduction using doubles by applying Villard's algorithm for LLL certification. If it works, this algorithm can quickly check reduction. If the version using doubles fails, a version using mpfr's is used. And if that fails, a fallback version which uses exact arithmetic is employed. The algorithm works by computing various things with the rounding mode set in one direction, then with the rounding mode set in the other direction, to bound the error on terms. According to Villard's paper the double precision version works up to about dimension 200 or so.
* If the lattice is not reduced, a heuristic LLL is used (fmpz_lll_d_heuristic), which makes use of a heuristic dot product in double precision. If cancellation is detected at double precision, a full precision dot product is done.
* The lattice is again checked to see if it is reduced, using fmpz_lll_is_reduced.
* If the lattice is still not reduced, a proven version of the L^2 algorithm is employed (fmpz_lll_mpf), which steadily increases precision for a while and then starts doubling precision until full reduction is achieved. Hopefully, for a majority of cases, this algorithm is never called, or if it is, very few reduction steps actually remain. This is still a floating point LLL, but with proven complexity bounds. It makes use of GMP's mpf arithmetic for arbitrary precision floating point.
* Eventually fmpz_lll_is_reduced will certify that the basis is reduced and we are done.
Note that an implementation of the original rational LLL algorithm of Lenstra-Lenstra-Lovasz is provided (fmpz_mat_lll_original). Also an implementation of the Storjohann LLL, which also uses exact arithmetic, but has lower complexity in terms of the dimension than other LLL algorithms, is supplied (fmpz_mat_lll_storjohann). There is also a version of this which attempts to also reduce the complexity with respect to entry size (fmpz_lll_storjohann_ulll), but it is not expected to be useful in practice. These implementations are mainly provided for experimental and theoretical reasons only.
Thanks again to Abhinav for implementing all of these algorithms. Some of the really novel features of his implementation over what is available elsewhere include:
* a selection of different heuristic dot products (in d_vec/mpf_vec), including the Ogita, Rump, Oishi algorithm.
* implementations of the Schwarz-Rutishauser algorithms for GSO and QR-decomposition (including reorthogonalisation)
* an implementation of Villard algorithm for LLL certification
* an implementation of LLL variants using the GMP mpf layer
* the ability to supply the input to LLL as a Gram matrix or lattice basis
* an implementation of the Storjohann LLL, including a ULLL variant
Thanks very much to Google Summer of Code for funding the work and to Lmonade for supporting the project!
Bill.
Bill Hart
Sep 23, 2014, 10:28:03 AM9/23/14
to flint-devel
If anyone has an interest in improving the LLL in flint, here are some things we haven't worked on:
* Givens rotations and Householder transformations
* Supplying BKZ reduction
* Trying to optimise the combined ULLL/Storjohann approach to make it practical (currently only useful for *massive* lattices)
* Improve the wrapper strategy for LLL in flint
* Try using Arb arf_t type instead of the GMP mpf type
* Hermite reduction (historical/demonstration purposes only)
* LLL applications, e.g. the van Hoeij algorithm, integer relations finding, etc.
Bill Hart
Sep 23, 2014, 10:38:13 AM9/23/14
to flint-devel, Claus Fieker, Wolfram Decker, Burcin Erocal, Curtis Bright
Also a very big thanks to Curtis Bright (the other GSoC mentor for the project and all-round LLL expert) who tirelessly checked the implementation as it was being developed and answered a huge number of questions.
In a few minutes, I'll update the author information both on the website and in the AUTHORS file and documentation.
On 23 September 2014 16:12, Bill Hart <goodwi...@googlemail.com> wrote:

Fredrik Johansson
Sep 23, 2014, 12:37:02 PM9/23/14
to flint-devel
On Tue, Sep 23, 2014 at 4:12 PM, Bill Hart <goodwi...@googlemail.com> wrote:
> I've now finished reviewing the new LLL code for flint, written by Abhinav
> Baid, our GSoC scholar.
>
This is excellent.
> I've now finished reviewing the new LLL code for flint, written by Abhinav
> Baid, our GSoC scholar.
>
Two more remarks about the code:
Shouldn't fmpz_mat_lll_original and fmpz_mat_lll_storjohann be moved
to the LLL module?
Do any of the double precision functions require strict IEEE 754
double precision arithmetic? In dot_thrice for example, the
expressions are presumably meant to be evaluated exactly as written.
However, this is not guaranteed by default.
Firstly, on x87, some partial results will likely be evaluated in
registers using extended precision. Rounding back to a double can then
result in worse accuracy than intended (the actual behavior is
completely unpredictable, since it depends on the way compiler does
register allocation), and this will generally break algorithms that
depend on precise cancellation.
Secondly, some compilers will rewrite floating-point operations
unsafely by default (e.g. assuming associativity). For example
b1 = c - (c - vec2[i]);
b2 = vec2[i] - b1;
(which appears in dot_thrice) will probably be "optimized" to
b1 = vec2[i];
b2 = 0.0;
From what I've read, GCC and Clang don't break your code this way
unless you ask them to, but the Intel compiler does it by default. I
don't know about MSVC.
The short story is that we should pass compiler flags that ensure
well-behaved floating-point arithmetic with any supported compilers,
and warn users that flint must be compiled this way.
Fredrik
Bill Hart
Sep 23, 2014, 12:49:51 PM9/23/14
to flint-devel
On 23 September 2014 18:37, Fredrik Johansson <fredrik....@gmail.com> wrote:
On Tue, Sep 23, 2014 at 4:12 PM, Bill Hart <goodwi...@googlemail.com> wrote:
> I've now finished reviewing the new LLL code for flint, written by Abhinav
> Baid, our GSoC scholar.
>
This is excellent.
Two more remarks about the code:
Shouldn't fmpz_mat_lll_original and fmpz_mat_lll_storjohann be moved
to the LLL module?
I think they are fine where they are. They are separated out because they are rational LLL algorithms, not floating point ones.
Do any of the double precision functions require strict IEEE 754
double precision arithmetic? In dot_thrice for example, the
expressions are presumably meant to be evaluated exactly as written.
However, this is not guaranteed by default.
Yes, also in the fmpz_lll_is_reduced_d code. Should we be supplying gcc with some compiler flags?
Firstly, on x87, some partial results will likely be evaluated in
registers using extended precision. Rounding back to a double can then
result in worse accuracy than intended (the actual behavior is
completely unpredictable, since it depends on the way compiler does
register allocation), and this will generally break algorithms that
depend on precise cancellation.
Secondly, some compilers will rewrite floating-point operations
unsafely by default (e.g. assuming associativity). For example
b1 = c - (c - vec2[i]);
b2 = vec2[i] - b1;
(which appears in dot_thrice) will probably be "optimized" to
b1 = vec2[i];
b2 = 0.0;
From what I've read, GCC and Clang don't break your code this way
unless you ask them to, but the Intel compiler does it by default. I
don't know about MSVC.
The short story is that we should pass compiler flags that ensure
well-behaved floating-point arithmetic with any supported compilers,
and warn users that flint must be compiled this way.
Yuck.

Curtis Bright
Oct 14, 2014, 5:49:01 PM10/14/14
to flint...@googlegroups.com
On Sat, Aug 30, 2014 at 7:10 AM, abhinav baid <abhin...@gmail.com> wrote:
> Here are the timings for randajtai (with alpha = 0.5):
>
> | d | FLINT | fpLLL |
> | --- | -------- | -------- |
> | 32 | 0.007192 | 0.011587 |
> | 64 | 0.02991 | 0.05805 |
> | 96 | 0.103186 | 0.156087 |
> | 128 | 0.238155 | 0.284892 |
> | 160 | 0.550085 | 0.424788 |
> | 192 | 1.10902 | 0.785056 |
> | 224 | 1.39008 | 1.79943 |
> | 256 | 2.52803 | 3.01734 |
> | 288 | 4.66249 | 5.81334 |
Sorry I didn't address this at the time, but Ajtai-type bases were
really intended to be used with alpha > 1 so that LLL exhibits
worst-case runtime behaviour. With alpha <= 1 you will get bases
which are really close to being reduced (in fact, if you use the
definition in the LLL book they will already be reduced).
To satisfy my curiosity on this, I wrote some profiling code to
compare the flint and fplll wrapper functions
[https://github.com/curtisbright/flint2/blob/p-fplll/fmpz_lll/profile/p-fplll.cpp].
(It assume this won't compile with the rest of flint's profiling code
without some extra configuration.) Here are the results with alpha =
1.5:
dim = 10 flint/fplll 26 18 (ms) ratio 1.44
dim = 20 flint/fplll 25 20 (ms) ratio 1.25
dim = 30 flint/fplll 216 188 (ms) ratio 1.15
dim = 40 flint/fplll 1233 995 (ms) ratio 1.24
dim = 50 flint/fplll 4986 3852 (ms) ratio 1.29
dim = 60 flint/fplll 17335 13014 (ms) ratio 1.33
dim = 70 flint/fplll 53970 39713 (ms) ratio 1.36
dim = 80 flint/fplll 140728 104242 (ms) ratio 1.35
dim = 90 flint/fplll 341570 253444 (ms) ratio 1.35
dim = 100 flint/fplll 729644 543317 (ms) ratio 1.34
dim = 110 flint/fplll 1504847 1087740 (ms) ratio 1.38
dim = 120 flint/fplll 3218280 2260931 (ms) ratio 1.42
dim = 130 flint/fplll 6381483 4500729 (ms) ratio 1.42
dim = 140 flint/fplll 11676957 8427307 (ms) ratio 1.39
I also timed fmpz_lll instead of the wrapper, and the result was
actually slower:
dim = 10 flint/fplll 11 22 (ms) ratio 0.50
dim = 20 flint/fplll 48 20 (ms) ratio 2.40
dim = 30 flint/fplll 360 190 (ms) ratio 1.89
dim = 40 flint/fplll 2144 990 (ms) ratio 2.17
dim = 50 flint/fplll 7681 3866 (ms) ratio 1.99
dim = 60 flint/fplll 26869 12763 (ms) ratio 2.11
dim = 70 flint/fplll 77946 39519 (ms) ratio 1.97
dim = 80 flint/fplll 201416 104367 (ms) ratio 1.93
dim = 90 flint/fplll 437253 251335 (ms) ratio 1.74
dim = 100 flint/fplll 856015 538338 (ms) ratio 1.59
dim = 110 flint/fplll 1630932 1084483 (ms) ratio 1.50
On Tue, Sep 23, 2014 at 10:12 AM, Bill Hart <goodwi...@googlemail.com> wrote:
> If the version using doubles fails, a
> version using mpfr's is used. And if that fails, a fallback version which
> uses exact arithmetic is employed.
I would avoid using exact arithmetic. I haven't done actual timings,
but in the worst case one can just run L^2 to a probably correct
precision—asymptotically this should be no worse than even just
checking a basis for reducedness using exact arithmetic.
Curtis
> Here are the timings for randajtai (with alpha = 0.5):
>
> | d | FLINT | fpLLL |
> | --- | -------- | -------- |
> | 32 | 0.007192 | 0.011587 |
> | 64 | 0.02991 | 0.05805 |
> | 96 | 0.103186 | 0.156087 |
> | 128 | 0.238155 | 0.284892 |
> | 160 | 0.550085 | 0.424788 |
> | 192 | 1.10902 | 0.785056 |
> | 224 | 1.39008 | 1.79943 |
> | 256 | 2.52803 | 3.01734 |
> | 288 | 4.66249 | 5.81334 |
Sorry I didn't address this at the time, but Ajtai-type bases were
really intended to be used with alpha > 1 so that LLL exhibits
worst-case runtime behaviour. With alpha <= 1 you will get bases
which are really close to being reduced (in fact, if you use the
definition in the LLL book they will already be reduced).
To satisfy my curiosity on this, I wrote some profiling code to
compare the flint and fplll wrapper functions
[https://github.com/curtisbright/flint2/blob/p-fplll/fmpz_lll/profile/p-fplll.cpp].
(It assume this won't compile with the rest of flint's profiling code
without some extra configuration.) Here are the results with alpha =
1.5:
dim = 10 flint/fplll 26 18 (ms) ratio 1.44
dim = 20 flint/fplll 25 20 (ms) ratio 1.25
dim = 30 flint/fplll 216 188 (ms) ratio 1.15
dim = 40 flint/fplll 1233 995 (ms) ratio 1.24
dim = 50 flint/fplll 4986 3852 (ms) ratio 1.29
dim = 60 flint/fplll 17335 13014 (ms) ratio 1.33
dim = 70 flint/fplll 53970 39713 (ms) ratio 1.36
dim = 80 flint/fplll 140728 104242 (ms) ratio 1.35
dim = 90 flint/fplll 341570 253444 (ms) ratio 1.35
dim = 100 flint/fplll 729644 543317 (ms) ratio 1.34
dim = 110 flint/fplll 1504847 1087740 (ms) ratio 1.38
dim = 120 flint/fplll 3218280 2260931 (ms) ratio 1.42
dim = 130 flint/fplll 6381483 4500729 (ms) ratio 1.42
dim = 140 flint/fplll 11676957 8427307 (ms) ratio 1.39
I also timed fmpz_lll instead of the wrapper, and the result was
actually slower:
dim = 10 flint/fplll 11 22 (ms) ratio 0.50
dim = 20 flint/fplll 48 20 (ms) ratio 2.40
dim = 30 flint/fplll 360 190 (ms) ratio 1.89
dim = 40 flint/fplll 2144 990 (ms) ratio 2.17
dim = 50 flint/fplll 7681 3866 (ms) ratio 1.99
dim = 60 flint/fplll 26869 12763 (ms) ratio 2.11
dim = 70 flint/fplll 77946 39519 (ms) ratio 1.97
dim = 80 flint/fplll 201416 104367 (ms) ratio 1.93
dim = 90 flint/fplll 437253 251335 (ms) ratio 1.74
dim = 100 flint/fplll 856015 538338 (ms) ratio 1.59
dim = 110 flint/fplll 1630932 1084483 (ms) ratio 1.50
On Tue, Sep 23, 2014 at 10:12 AM, Bill Hart <goodwi...@googlemail.com> wrote:
> If the version using doubles fails, a
> version using mpfr's is used. And if that fails, a fallback version which
> uses exact arithmetic is employed.
but in the worst case one can just run L^2 to a probably correct
precision—asymptotically this should be no worse than even just
checking a basis for reducedness using exact arithmetic.
Curtis
Bill Hart
Oct 14, 2014, 6:16:44 PM10/14/14
to flint-devel
Given how consistent the ratio is, I would suspect something low level, e.g. the arithmetic is responsible for the difference here.
We should dig down to figure out what it is at some point. Unfortunately I'm in paper writing mode at the moment, so not too focused on coding for a month or two. But I'll take a look at some point.
I also timed fmpz_lll instead of the wrapper, and the result was
actually slower:
It's very odd that for dimension 10 the time dropped so much. Something is going wrong with ULLL, but I don't think it is Abhinav's code. I looked at it carefully but didn't see any problem.
What we can do at some point is compare the flint1 timings with flint2 and hopefully with some profiling figure out if there are any easy speedups that we missed.
We should compare matrix multiplication between flint1 and flint2, as that could be an issue somehow, though I don't know how exactly.
dim = 10 flint/fplll 11 22 (ms) ratio 0.50
dim = 20 flint/fplll 48 20 (ms) ratio 2.40
dim = 30 flint/fplll 360 190 (ms) ratio 1.89
dim = 40 flint/fplll 2144 990 (ms) ratio 2.17
dim = 50 flint/fplll 7681 3866 (ms) ratio 1.99
dim = 60 flint/fplll 26869 12763 (ms) ratio 2.11
dim = 70 flint/fplll 77946 39519 (ms) ratio 1.97
dim = 80 flint/fplll 201416 104367 (ms) ratio 1.93
dim = 90 flint/fplll 437253 251335 (ms) ratio 1.74
dim = 100 flint/fplll 856015 538338 (ms) ratio 1.59
dim = 110 flint/fplll 1630932 1084483 (ms) ratio 1.50
On Tue, Sep 23, 2014 at 10:12 AM, Bill Hart <goodwi...@googlemail.com> wrote:
> If the version using doubles fails, a
> version using mpfr's is used. And if that fails, a fallback version which
> uses exact arithmetic is employed.
I would avoid using exact arithmetic. I haven't done actual timings,
but in the worst case one can just run L^2 to a probably correct
precision—asymptotically this should be no worse than even just
checking a basis for reducedness using exact arithmetic.
Curtis
--
---
You received this message because you are subscribed to the Google Groups "flint-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flint-devel...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Bill Hart
Oct 14, 2014, 6:18:20 PM10/14/14
to flint-devel
Oh and Fredrik found some cases where LLL returns the zero matrix, which probably just meets the definition of a bug. That will just be something silly. I'll sort that out before the release.
Bill.
Curtis Bright
Oct 15, 2014, 11:45:45 AM10/15/14
to flint...@googlegroups.com
On Tue, Oct 14, 2014 at 6:16 PM, Bill Hart <goodwi...@googlemail.com> wrote:
> It's very odd that for dimension 10 the time dropped so much.
I think that was due to some kind of caching anomaly. After running
> It's very odd that for dimension 10 the time dropped so much.
the program a second time, the timings for dimension 10 drop to ~1 ms.
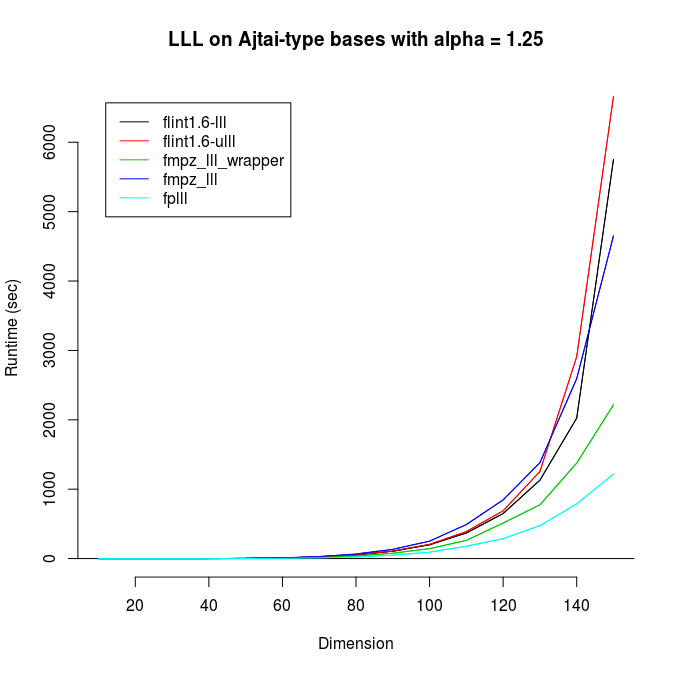
Here are both functions timed together with alpha = 1.25 (on another
machine):
dim = 10 wrapper/ulll/fplll 1 2 1 (ms) fplll-ratio 1.00 2.00
dim = 20 wrapper/ulll/fplll 15 16 12 (ms) fplll-ratio 1.25 1.33
dim = 30 wrapper/ulll/fplll 127 127 95 (ms) fplll-ratio 1.34 1.34
dim = 40 wrapper/ulll/fplll 622 608 440 (ms) fplll-ratio 1.41 1.38
dim = 50 wrapper/ulll/fplll 2340 3801 1553 (ms) fplll-ratio 1.51 2.45
dim = 60 wrapper/ulll/fplll 7147 11682 4323 (ms) fplll-ratio 1.65 2.70
dim = 70 wrapper/ulll/fplll 17753 29959 10629 (ms) fplll-ratio 1.67 2.82
dim = 80 wrapper/ulll/fplll 39802 67162 23982 (ms) fplll-ratio 1.66 2.80
dim = 90 wrapper/ulll/fplll 84492 145994 49489 (ms) fplll-ratio 1.71 2.95
dim = 100 wrapper/ulll/fplll 188285 326739 97245 (ms) fplll-ratio 1.94 3.36
dim = 110 wrapper/ulll/fplll 358256 610127 166569 (ms) fplll-ratio 2.15 3.66
dim = 120 wrapper/ulll/fplll 482703 801949 283761 (ms) fplll-ratio 1.70 2.83
dim = 130 wrapper/ulll/fplll 813417 1431492 482536 (ms) fplll-ratio 1.69 2.97
dim = 140 wrapper/ulll/fplll 1405690 2517450 753511 (ms) fplll-ratio 1.87 3.34
dim = 150 wrapper/ulll/fplll 2754544 4316940 1208443 (ms) fplll-ratio 2.28 3.57
This raises the question: should ULLL be used by default?
Curtis
Bill Hart
Oct 15, 2014, 11:55:15 AM10/15/14
to flint-devel
It doesn't look like it. But we'll have to get to the bottom of why it was faster in flint-1.6 first.
Bill.
Curtis Bright
Oct 16, 2014, 7:47:43 PM10/16/14
to flint...@googlegroups.com
On Wed, Oct 15, 2014 at 11:55 AM, Bill Hart <goodwi...@googlemail.com> wrote:
> It doesn't look like it. But we'll have to get to the bottom of why it was
> faster in flint-1.6 first.
I tried comparing the times of the LLL functions on the same type of
> It doesn't look like it. But we'll have to get to the bottom of why it was
> faster in flint-1.6 first.
bases, and found that it wasn't always faster:
dim = 10 lll/ulll 1 1 (ms) ratio 1.00
dim = 20 lll/ulll 8 7 (ms) ratio 1.14
dim = 30 lll/ulll 51 51 (ms) ratio 1.00
dim = 40 lll/ulll 243 244 (ms) ratio 1.00
dim = 50 lll/ulll 1375 882 (ms) ratio 1.56
dim = 60 lll/ulll 4125 4374 (ms) ratio 0.94
dim = 70 lll/ulll 10715 11242 (ms) ratio 0.95
dim = 80 lll/ulll 24510 24878 (ms) ratio 0.99
dim = 90 lll/ulll 49629 50721 (ms) ratio 0.98
dim = 100 lll/ulll 136204 94352 (ms) ratio 1.44
dim = 110 lll/ulll 311398 214631 (ms) ratio 1.45
dim = 120 lll/ulll 934909 999326 (ms) ratio 0.94
dim = 130 lll/ulll 1841387 1918954 (ms) ratio 0.96
dim = 140 lll/ulll 3431632 3317136 (ms) ratio 1.03
dim = 150 lll/ulll 5409226 5370512 (ms) ratio 1.01
dim = 160 lll/ulll 7768451 8361850 (ms) ratio 0.93
For the sake of a fair comparison, I reran the flint2/fplll profiling
code on the exact same bases:
dim = 10 wrapper/ulll/fplll 1 1 2 (ms) fplll-ratio 0.50 0.50
dim = 20 wrapper/ulll/fplll 16 13 12 (ms) fplll-ratio 1.33 1.08
dim = 30 wrapper/ulll/fplll 120 119 90 (ms) fplll-ratio 1.33 1.32
dim = 40 wrapper/ulll/fplll 604 603 425 (ms) fplll-ratio 1.42 1.42
dim = 50 wrapper/ulll/fplll 2243 3649 1537 (ms) fplll-ratio 1.46 2.37
dim = 60 wrapper/ulll/fplll 6548 11490 4332 (ms) fplll-ratio 1.51 2.65
dim = 70 wrapper/ulll/fplll 17375 28649 10398 (ms) fplll-ratio 1.67 2.76
dim = 80 wrapper/ulll/fplll 37799 65655 23701 (ms) fplll-ratio 1.59 2.77
dim = 90 wrapper/ulll/fplll 77324 133092 48991 (ms) fplll-ratio 1.58 2.72
dim = 100 wrapper/ulll/fplll 143001 250810 92635 (ms) fplll-ratio 1.54 2.71
dim = 110 wrapper/ulll/fplll 262635 490138 177833 (ms) fplll-ratio 1.48 2.76
dim = 120 wrapper/ulll/fplll 511813 845791 287423 (ms) fplll-ratio 1.78 2.94
dim = 130 wrapper/ulll/fplll 774831 1382292 475236 (ms) fplll-ratio 1.63 2.91
dim = 140 wrapper/ulll/fplll 1376132 2594168 787233 (ms) fplll-ratio 1.75 3.30
dim = 150 wrapper/ulll/fplll 2217452 4651566 1219603 (ms) fplll-ratio 1.82 3.81
Have you written (or are currently writing) anything on ULLL? I'm
interested in researching this area - a few years ago Andy did explain
some of the intuition to me, but as far as I know it was never written
down anywhere.
Thanks Bill,
Curtis
{kind=link}
Bill Hart
Oct 16, 2014, 8:14:56 PM10/16/14
to flint-devel
Hi Curtis,
thanks for timing these. It certainly tells a different story. The new ULLL is slower, the old one about the same.
On the other hand, assuming the timings are comparable, the new wrapper is way faster.
I had planned to write a technical report on ULLL eventually and put Andy's name on it as coauthor. I'll be very interested to see if ULLL speeds up polynomial factorisation or not.
If you want to write something on ULLL go ahead. I had not planned to submit anything to a journal. My effort will only be a technical report. You'll likely beat me anyway, as I have quite a backlog of papers to get out. I'm currently working on a very exciting q-series paper.
Bill.
Curtis
Curtis Bright
Oct 17, 2014, 11:07:03 AM10/17/14
to flint...@googlegroups.com
On Thu, Oct 16, 2014 at 8:14 PM, Bill Hart <goodwi...@googlemail.com> wrote:
> If you want to write something on ULLL go ahead. I had not planned to submit
> anything to a journal. My effort will only be a technical report.
Actually, I was hoping you had something written on ULLL, because I've
> If you want to write something on ULLL go ahead. I had not planned to submit
> anything to a journal. My effort will only be a technical report.
forgotten most of what Andy said! I believe he said it was supposed
to run faster, but I've never been able to actually observe this
behaviour, so I'm second-guessing myself.
Also, I forgot that flint1.6 used a default eta = 0.81, so I reran the
timings with eta = 0.51, and they actually improved for dimensions
120–140, though not enough to significantly alter the story.
Curtis
{kind=link}
Reply all
Reply to author
Forward
0 new messages