Offline Mode: "lpad detect_lostruns" and "lpad recover_offline" issues
91 views
Skip to first unread message

Johannes Hörmann
May 31, 2019, 8:30:07 AM5/31/19
to fireworkflows
Dear Fireworks Team,
In the course of my PhD, I have been using Fireworks since about a year for managing work flows on different computing resources, most importantly on the supercomputers NEMO in Freiburg and the Jülich machine JUWELS. While NEMO is using the queueing system MOAB/Torque, JUWELS employs SLURM. On both machines, I submit jobs vial Firework's offline mode in order to be independent from a stable connection between computing nodes and MongoDB (which would have to be tunneled via the login nodes, not reliable). On the login nodes, usually have an infinite loop running the command
lpad -l "${FW_CONFIG_PREFIX}/fireworks_mongodb_auth.yaml" recover_offline -w "${QLAUNCH_FWORKER_FILE}"
every couple of minutes checking for job state updates.
What I became aware of over the time is that on the JUWELS/SLURM machine, offline jobs fizzle properly, even when the are cancelled due to the walltime running out. I assume that SLURM sends a proper signal to rlaunch and allows some clean-up work to be done before forcefully killing.
On the NEMO/MOAB machine, however, it seems the job is killed immediately if walltime expires, and its stays marked as "running" indefinitely. I have to manually use "lpad detect_lostruns" to fizzle the Firework and here I want to point out two issues:
The first issue is that selecting the "dead" runs by the "--time" options of "lpad detect_lostruns" oftentimes does not work as expected. Even if the runs has been "dead" for days, it might happen that "detect_lostruns" does not recognize it as "lost" and I have to go down to a few seconds with the expiration time to have the lost run(s) show up. But then, of course, also other healthy runs appear in the list. Here I would like to ask whether this behavior might be related to the the "recover" loop running in background continuously, as described above?
The second, related issue is that even if i mark a lost run on the NEMO/MOAB machine as "fizzled" by "lpad detect_lostruns --fizzle" (and maybe a suitable --query in order to narrow the selection), it will get marked as "running" again by the next call of "lpad recover_offline" as shown above. The only way I can avoid that behavior is stopping the automized recovery loop and executing the python command "lp.forget_offline(accordingFireWorksID,launch_mode=False)". Only then the next "recover_offline" will leave the run in question marked as "fizzled".
I have observed these issues mostly for Fireworks 1.8.7, but a few days ago I updated to 1.9.1 and I believe they still persist. Would you have an idea about the source of those two (probably related?) issues?
Best regars,
Johannes Hörmann

Anubhav Jain
Jun 4, 2019, 9:02:51 PM6/4/19
to fireworkflows
Hi Johannes,
Thanks for reporting these issues. We do not run offline mode ourselves, so sometimes there are issues that we are unaware of.
Regarding issue 1:
For jobs that are stuck in the RUNNING state, the crucial thing that needs to be correct in order for "detect_lostruns" to work properly is the timestamp on the last ping of the launch. Could you try to check the following (let me know if you need help with this process):
1. Identify a job that has this problem, and where you've already run the recover_offline() command on it
2. Go to the directory where that job ran
3. There should be a file called FW_ping.json. Look inside and note down the "ping_time" of that file
4. There should also be a file called FW_offline.json. Look inside and note down the "launch_id" in that file
5. Next, we want to check the database for consistency. You want to search your "launches" collection (either through MongoDB itself, or through pymongo, or through the "launches" collection in the LaunchPad object) for the launch id that you noted in #4. In that document for that launch id, you should see a key called "state_history". In there should be an entry where you see "updated_on". See screenshot for example ...
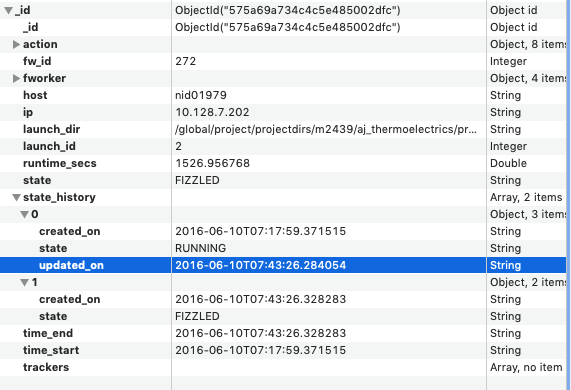
6) Now the two things for you to confirm:
A: does the updated_on timestamp mach the FW_ping.json "ping_time" that you noted earlier? If not, is the timestamp later or earlier?
B: is the type of the updated_on timestamp a String type (as opposed to a datetime type)?
Regarding issue 2:
I think this is a separate issue. When you run "lpad detect_lostruns --fizzle" the *database* knows that the job is FIZZLED, but the filesystem information in FW_offline.json still thinks the job is running / completed / etc. Thus when running recover_offline() again, the file system information overrides the DB information and you end up forgetting that you decided to fizzle the job.
Unfortunately, this does mean that at the current stage you need to manually "forget" about the information on the filesystem any time you want to change the state of an offline Firework using one of the Launchpad commands. I've added an issue about this on Github (https://github.com/materialsproject/fireworks/issues/326), but unfortunately don't have a quick fix at the moment.
Johannes Hörmann
Jul 24, 2019, 8:26:34 AM7/24/19
to fireworkflows
Hello Anubhav,
thanks for the answer. Finally, I found some opportunity & time to do as suggested on a job that actually got killed a few days ago after exceeding the maximum walltime of 4 days.
Issue 1:
Here the MOAB job log (/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/block_2019-06-30-13-07-21-802466/launcher_2019-07-13-22-54-14-628683/NEMO_AU_111_r__25_An.e6012657)
+ cd /work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/block_2019-06-30-13-07-21-802466/launcher_2019-07-13-22-54-14-628683
+ rlaunch -w /home/fr/fr_fr/fr_jh1130/.fireworks/nemo_queue_worker.yaml -l /home/fr/fr_fr/fr_jh1130/.fireworks/fireworks_mongodb_auth.yaml singleshot --offline --fw_id 15514
=>> PBS: job killed: walltime 345642 exceeded limit 345600
+ rlaunch -w /home/fr/fr_fr/fr_jh1130/.fireworks/nemo_queue_worker.yaml -l /home/fr/fr_fr/fr_jh1130/.fireworks/fireworks_mongodb_auth.yaml singleshot --offline --fw_id 15514
=>> PBS: job killed: walltime 345642 exceeded limit 345600
{"ping_time": "2019-07-17T22:54:51.000760"}
That being the last update agrees very well with the maximum walltime. /work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/block_2019-06-30-13-07-21-802466/launcher_2019-07-13-22-54-14-628683/FW_offline.json shows that the run started exactly four days earlier:
{"launch_id": 11789, "started_on": "2019-07-13T22:54:49.124427", "checkpoint": {"_task_n": 0, "_all_stored_data": {}, "_all_update_spec": {}, "_all_mod_spec": []}}
A manual check shows no other files in this launchdir have been touched afterwards:
$ ls -lht
total 8,0G
-rw------- 1 fr_jh1130 fr_fr 28K 18. Jul 00:55 NEMO_AU_111_r__25_An.e6012657
-rw------- 1 fr_jh1130 fr_fr 43 18. Jul 00:54 FW_ping.json
-rw------- 1 fr_jh1130 fr_fr 663K 18. Jul 00:52 log.lammps
-rw------- 1 fr_jh1130 fr_fr 83M 18. Jul 00:52 default.mpiio.restart1
total 8,0G
-rw------- 1 fr_jh1130 fr_fr 28K 18. Jul 00:55 NEMO_AU_111_r__25_An.e6012657
-rw------- 1 fr_jh1130 fr_fr 43 18. Jul 00:54 FW_ping.json
-rw------- 1 fr_jh1130 fr_fr 663K 18. Jul 00:52 log.lammps
-rw------- 1 fr_jh1130 fr_fr 83M 18. Jul 00:52 default.mpiio.restart1
...
However, the update state in the "launch" collection just corresponds to the current time (see state_history[1]: updated_on):
Am I correct in assuming that the repeatedly running lpad recover_offline updates this time after reading FW_offline.json?
That I read from the recover_offline code https://github.com/materialsproject/fireworks/blob/df8374bc3358a826eaa258de333ff6a46d4f54fa/fireworks/core/launchpad.py#L1728-L1730
As you see, the type is "String", no datetime type.
Would that be the expected behavior? Or should lpad recover_offline leave the updated_on key untouched, if no update has been recorded to the FW_ping.json?
Issue 2
Wouldn't it be the quick solution to always "forget" the offline run by the already existing "lpad.forget_offline" method internally when calling "lpad detect_lostruns --fizzle / --rerun"?
I don't see any situation where one would want to keep an offline run already explicitly identified as "dead" available to the "recover_offline" functionality.
Best regards,
Johannes
For completeness, the according lpad get_fws output:
$ lpad get_fws -i 15514 -d all
{
"spec": {
"_category": "nemo_queue_offline",
"_files_in": {
"coeff_file": "coeff.input",
"data_file": "datafile.lammps",
"input_header": "lmp_header.input",
"input_production": "lmp_production.input"
},
"_files_out": {
"ave_file": "thermo_ave.out",
"data_file": "default.lammps",
"log_file": "log.lammps",
"ndx_file": "groups.ndx",
"traj_file": "default.nc"
},
"_queueadapter": {
"nodes": 16,
"ppn": 20,
"queue": null,
"walltime": "96:00:00"
},
"_tasks": [
{
"_fw_name": "CmdTask",
"cmd": "lmp",
"fizzle_bad_rc": true,
"opt": [
"-in lmp_production.input",
"-v coeffInfile coeff.input",
"-v coeffOutfile coeff.input.transient",
"-v compute_group_properties 1",
"-v compute_interactions 0",
"-v dataFile datafile.lammps",
"-v dilate_solution_only 1",
"-v freeze_substrate 0",
"-v freeze_substrate_layer 14.0",
"-v has_indenter 1",
"-v rigid_indenter_core_radius 12.0",
"-v constant_indenter_velocity -1e-06",
"-v mpiio 1",
"-v netcdf_frequency 50000",
"-v productionSteps 17500000",
"-v pressureP 1.0",
"-v pressurize_z_only 1",
"-v pressurize_solution_only 0",
"-v reinitialize_velocities 0",
"-v read_groups_from_file 0",
"-v rigid_indenter 0",
"-v restrained_indenter 0",
"-v restart_frequency 50000",
"-v store_forces 1",
"-v surfactant_name SDS",
"-v temperatureT 298.0",
"-v temper_solid_only 1",
"-v temper_substrate_only 0",
"-v thermo_frequency 5000",
"-v thermo_average_frequency 5000",
"-v use_barostat 0",
"-v use_berendsen_bstat 0",
"-v use_dpd_tstat 1",
"-v use_eam 1",
"-v use_ewald 1",
"-v write_coeff 1",
"-v write_coeff_to_datafile 0",
"-v write_groups_to_file 1",
"-v coulomb_cutoff 8.0",
"-v ewald_accuracy 0.0001",
"-v neigh_delay 2",
"-v neigh_every 1",
"-v neigh_check 1",
"-v skin_distance 3.0"
],
"stderr_file": "std.err",
"stdout_file": "std.out",
"store_stderr": true,
"store_stdout": true,
"use_shell": true
}
],
"_trackers": [
{
"filename": "log.lammps",
"nlines": 25
}
],
"metadata": {
"barostat_damping": 10000.0,
"ci_preassembly": "at polar heads",
"compute_group_properties": 1,
"constant_indenter_velocity": -1e-06,
"constant_indenter_velocity_unit": "Ang_per_fs",
"coulomb_cutoff": 8.0,
"coulomb_cutoff_unit": "Ang",
"counterion": "NA",
"ewald_accuracy": 0.0001,
"force_field": {
"solution_solution": "charmm36-jul2017",
"substrate_solution": "interface_ff_1_5",
"substrate_substrate": "Au-Grochola-JCP05-units-real.eam.alloy"
},
"frozen_sb_layer_thickness": 14.0,
"frozen_sb_layer_thickness_unit": "Ang",
"indenter": {
"crystal_plane": 111,
"equilibration_time_span": 50,
"equilibration_time_span_unit": "ps",
"initial_radius": 25,
"initial_radius_unit": "Ang",
"initial_shape": "sphere",
"lammps_units": "real",
"melting_final_temperature": 1800,
"melting_time_span": 10,
"melting_time_span_unit": "ns",
"minimization_ftol": 1e-05,
"minimization_ftol_unit": "kcal",
"natoms": 3873,
"orientation": "111 facet facing negative z",
"potential": "Au-Grochola-JCP05-units-real.eam.alloy",
"quenching_time_span": 100,
"quenching_time_span_unit": "ns",
"quenching_time_step": 5,
"quenching_time_step_unit": "fs",
"substrate": "AU",
"temperature": 298,
"temperature_unit": "K",
"time_step": 2,
"time_step_unit": "fs",
"type": "AFM tip"
},
"langevin_damping": 1000.0,
"machine": "NEMO",
"mode": "TRIAL",
"mpiio": 1,
"neigh_check": 1,
"neigh_delay": 2,
"neigh_every": 1,
"netcdf_frequency": 50000,
"pbc": 111,
"pressure": 1,
"pressure_unit": "atm",
"production_steps": 17500000,
"restrained_sb_layer_thickness": null,
"restrained_sb_layer_thickness_unit": null,
"sb_area": 2.25e-16,
"sb_area_unit": "m^2",
"sb_base_length": 150,
"sb_base_length_unit": "Ang",
"sb_crystal_plane": 111,
"sb_crystal_plane_multiples": [
52,
90,
63
],
"sb_in_dist": 30.0,
"sb_in_dist_unit": "Ang",
"sb_lattice_constant": 4.075,
"sb_lattice_constant_unit": "Ang",
"sb_measures": [
1.49836e-08,
1.49725e-08,
1.47828e-08
],
"sb_measures_unit": "m",
"sb_multiples": [
52,
30,
21
],
"sb_name": "AU_111_150Ang_cube",
"sb_natoms": 196560,
"sb_normal": 2,
"sb_shape": "cube",
"sb_thickness": 1.5e-08,
"sb_thickness_unit": "m",
"sb_volume": 3.375e-23,
"sb_volume_unit": "m^3",
"sf_concentration": 0.0068,
"sf_concentration_unit": "M",
"sf_nmolecules": 646,
"sf_preassembly": "monolayer",
"skin_distance": 3.0,
"skin_distance_unit": "Ang",
"solvent": "H2O",
"state": "production",
"step": "production_nemo_trial_with_dpd_tstat",
"substrate": "AU",
"surfactant": "SDS",
"sv_density": 997,
"sv_density_unit": "kg m^-3",
"sv_preassembly": "random",
"system_name": "646_SDS_monolayer_on_AU_111_150Ang_cube_with_AU_111_r_25Ang_indenter_at_-1e-06_Ang_per_fs_approach_velocity",
"temperature": 298,
"temperature_unit": "K",
"thermo_average_frequency": 5000,
"thermo_frequency": 5000,
"type": "AFM",
"use_barostat": 0,
"use_dpd_tstat": 1,
"use_eam": 1,
"use_ewald": 1,
"workflow_creation_date": "2019-07-13-22:53"
},
"_files_prev": {
"coeff_file": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-53-59-844042/coeff_hybrid.input",
"input_header": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-53-59-844042/lmp_header.input",
"input_production": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-53-59-844042/lmp_production.input",
"data_file": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-54-00-115840/default.lammps",
"ndx_file": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-54-00-115840/groups.ndx"
}
},
"fw_id": 15514,
"created_on": "2019-07-13T22:53:09.213733",
"updated_on": "2019-07-24T12:01:26.321000",
"launches": [
{
"fworker": {
"name": "nemo_queue_worker",
"category": [
"nemo_queue_offline"
],
"query": "{}",
"env": {
"lmp": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load lammps/16Mar18-gnu-7.3-openmpi-3.1-colvars-09Feb19; mpirun ${MPIRUN_OPTIONS} lmp",
"exchange_substrate.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools ovitos; exchange_substrate.py",
"extract_bb.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; extract_bb.py",
"extract_indenter_nonindenter_forces_from_netcdf.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/11Jul19; extract_indenter_nonindenter_forces_from_netcdf.py",
"extract_property.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools ovitos; extract_property.py",
"extract_thermo.sh": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; extract_thermo.sh",
"join_thermo.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; join_thermo.py",
"merge.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; merge.py",
"ncfilter.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/11Jul19; mpirun ${MPIRUN_OPTIONS} ncfilter.py",
"ncjoin.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; ncjoin.py",
"pizza.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; pizza.py",
"strip_comments.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; strip_comments.py",
"to_hybrid.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; to_hybrid.py",
"vmd": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load vmd/1.9.3-text; vmd",
"smbsync.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; smbsync.py"
}
},
"fw_id": 15514,
"launch_dir": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/block_2019-06-30-13-07-21-802466/launcher_2019-07-13-22-54-14-628683",
"host": "login2.nemo.privat",
"ip": "10.16.44.2",
"trackers": [
{
"filename": "log.lammps",
"nlines": 25,
"allow_zipped": false
}
],
"action": null,
"state": "RUNNING",
"state_history": [
{
"state": "RESERVED",
"created_on": "2019-07-13T22:54:14.596648",
"updated_on": "2019-07-13T22:54:14.596655",
"reservation_id": "6012657"
},
{
"state": "RUNNING",
"created_on": "2019-07-13T22:54:49.124427",
"updated_on": "2019-07-24T12:01:26.363237",
"checkpoint": {
"_task_n": 0,
"_all_stored_data": {},
"_all_update_spec": {},
"_all_mod_spec": []
}
}
],
"launch_id": 11789
}
],
"state": "RUNNING",
"name": "NEMO, AU 111 r = 25 Ang indenter at -1e-06 Ang_per_fs approach velocity on 646 SDS monolayer on AU 111 150 Ang cube substrate, LAMMPS production"
}
{
"spec": {
"_category": "nemo_queue_offline",
"_files_in": {
"coeff_file": "coeff.input",
"data_file": "datafile.lammps",
"input_header": "lmp_header.input",
"input_production": "lmp_production.input"
},
"_files_out": {
"ave_file": "thermo_ave.out",
"data_file": "default.lammps",
"log_file": "log.lammps",
"ndx_file": "groups.ndx",
"traj_file": "default.nc"
},
"_queueadapter": {
"nodes": 16,
"ppn": 20,
"queue": null,
"walltime": "96:00:00"
},
"_tasks": [
{
"_fw_name": "CmdTask",
"cmd": "lmp",
"fizzle_bad_rc": true,
"opt": [
"-in lmp_production.input",
"-v coeffInfile coeff.input",
"-v coeffOutfile coeff.input.transient",
"-v compute_group_properties 1",
"-v compute_interactions 0",
"-v dataFile datafile.lammps",
"-v dilate_solution_only 1",
"-v freeze_substrate 0",
"-v freeze_substrate_layer 14.0",
"-v has_indenter 1",
"-v rigid_indenter_core_radius 12.0",
"-v constant_indenter_velocity -1e-06",
"-v mpiio 1",
"-v netcdf_frequency 50000",
"-v productionSteps 17500000",
"-v pressureP 1.0",
"-v pressurize_z_only 1",
"-v pressurize_solution_only 0",
"-v reinitialize_velocities 0",
"-v read_groups_from_file 0",
"-v rigid_indenter 0",
"-v restrained_indenter 0",
"-v restart_frequency 50000",
"-v store_forces 1",
"-v surfactant_name SDS",
"-v temperatureT 298.0",
"-v temper_solid_only 1",
"-v temper_substrate_only 0",
"-v thermo_frequency 5000",
"-v thermo_average_frequency 5000",
"-v use_barostat 0",
"-v use_berendsen_bstat 0",
"-v use_dpd_tstat 1",
"-v use_eam 1",
"-v use_ewald 1",
"-v write_coeff 1",
"-v write_coeff_to_datafile 0",
"-v write_groups_to_file 1",
"-v coulomb_cutoff 8.0",
"-v ewald_accuracy 0.0001",
"-v neigh_delay 2",
"-v neigh_every 1",
"-v neigh_check 1",
"-v skin_distance 3.0"
],
"stderr_file": "std.err",
"stdout_file": "std.out",
"store_stderr": true,
"store_stdout": true,
"use_shell": true
}
],
"_trackers": [
{
"filename": "log.lammps",
"nlines": 25
}
],
"metadata": {
"barostat_damping": 10000.0,
"ci_preassembly": "at polar heads",
"compute_group_properties": 1,
"constant_indenter_velocity": -1e-06,
"constant_indenter_velocity_unit": "Ang_per_fs",
"coulomb_cutoff": 8.0,
"coulomb_cutoff_unit": "Ang",
"counterion": "NA",
"ewald_accuracy": 0.0001,
"force_field": {
"solution_solution": "charmm36-jul2017",
"substrate_solution": "interface_ff_1_5",
"substrate_substrate": "Au-Grochola-JCP05-units-real.eam.alloy"
},
"frozen_sb_layer_thickness": 14.0,
"frozen_sb_layer_thickness_unit": "Ang",
"indenter": {
"crystal_plane": 111,
"equilibration_time_span": 50,
"equilibration_time_span_unit": "ps",
"initial_radius": 25,
"initial_radius_unit": "Ang",
"initial_shape": "sphere",
"lammps_units": "real",
"melting_final_temperature": 1800,
"melting_time_span": 10,
"melting_time_span_unit": "ns",
"minimization_ftol": 1e-05,
"minimization_ftol_unit": "kcal",
"natoms": 3873,
"orientation": "111 facet facing negative z",
"potential": "Au-Grochola-JCP05-units-real.eam.alloy",
"quenching_time_span": 100,
"quenching_time_span_unit": "ns",
"quenching_time_step": 5,
"quenching_time_step_unit": "fs",
"substrate": "AU",
"temperature": 298,
"temperature_unit": "K",
"time_step": 2,
"time_step_unit": "fs",
"type": "AFM tip"
},
"langevin_damping": 1000.0,
"machine": "NEMO",
"mode": "TRIAL",
"mpiio": 1,
"neigh_check": 1,
"neigh_delay": 2,
"neigh_every": 1,
"netcdf_frequency": 50000,
"pbc": 111,
"pressure": 1,
"pressure_unit": "atm",
"production_steps": 17500000,
"restrained_sb_layer_thickness": null,
"restrained_sb_layer_thickness_unit": null,
"sb_area": 2.25e-16,
"sb_area_unit": "m^2",
"sb_base_length": 150,
"sb_base_length_unit": "Ang",
"sb_crystal_plane": 111,
"sb_crystal_plane_multiples": [
52,
90,
63
],
"sb_in_dist": 30.0,
"sb_in_dist_unit": "Ang",
"sb_lattice_constant": 4.075,
"sb_lattice_constant_unit": "Ang",
"sb_measures": [
1.49836e-08,
1.49725e-08,
1.47828e-08
],
"sb_measures_unit": "m",
"sb_multiples": [
52,
30,
21
],
"sb_name": "AU_111_150Ang_cube",
"sb_natoms": 196560,
"sb_normal": 2,
"sb_shape": "cube",
"sb_thickness": 1.5e-08,
"sb_thickness_unit": "m",
"sb_volume": 3.375e-23,
"sb_volume_unit": "m^3",
"sf_concentration": 0.0068,
"sf_concentration_unit": "M",
"sf_nmolecules": 646,
"sf_preassembly": "monolayer",
"skin_distance": 3.0,
"skin_distance_unit": "Ang",
"solvent": "H2O",
"state": "production",
"step": "production_nemo_trial_with_dpd_tstat",
"substrate": "AU",
"surfactant": "SDS",
"sv_density": 997,
"sv_density_unit": "kg m^-3",
"sv_preassembly": "random",
"system_name": "646_SDS_monolayer_on_AU_111_150Ang_cube_with_AU_111_r_25Ang_indenter_at_-1e-06_Ang_per_fs_approach_velocity",
"temperature": 298,
"temperature_unit": "K",
"thermo_average_frequency": 5000,
"thermo_frequency": 5000,
"type": "AFM",
"use_barostat": 0,
"use_dpd_tstat": 1,
"use_eam": 1,
"use_ewald": 1,
"workflow_creation_date": "2019-07-13-22:53"
},
"_files_prev": {
"coeff_file": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-53-59-844042/coeff_hybrid.input",
"input_header": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-53-59-844042/lmp_header.input",
"input_production": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-53-59-844042/lmp_production.input",
"data_file": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-54-00-115840/default.lammps",
"ndx_file": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/launcher_2019-07-13-22-54-00-115840/groups.ndx"
}
},
"fw_id": 15514,
"created_on": "2019-07-13T22:53:09.213733",
"updated_on": "2019-07-24T12:01:26.321000",
"launches": [
{
"fworker": {
"name": "nemo_queue_worker",
"category": [
"nemo_queue_offline"
],
"query": "{}",
"env": {
"lmp": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load lammps/16Mar18-gnu-7.3-openmpi-3.1-colvars-09Feb19; mpirun ${MPIRUN_OPTIONS} lmp",
"exchange_substrate.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools ovitos; exchange_substrate.py",
"extract_bb.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; extract_bb.py",
"extract_indenter_nonindenter_forces_from_netcdf.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/11Jul19; extract_indenter_nonindenter_forces_from_netcdf.py",
"extract_property.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools ovitos; extract_property.py",
"extract_thermo.sh": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; extract_thermo.sh",
"join_thermo.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; join_thermo.py",
"merge.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; merge.py",
"ncfilter.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/11Jul19; mpirun ${MPIRUN_OPTIONS} ncfilter.py",
"ncjoin.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; ncjoin.py",
"pizza.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; pizza.py",
"strip_comments.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools/12Mar19-python-2.7; strip_comments.py",
"to_hybrid.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; to_hybrid.py",
"vmd": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load vmd/1.9.3-text; vmd",
"smbsync.py": "module purge; module use /work/ws/nemo/fr_lp1029-IMTEK_SIMULATION-0/modulefiles; module load mdtools; smbsync.py"
}
},
"fw_id": 15514,
"launch_dir": "/work/ws/nemo/fr_jh1130-fw_ws_20190311-0/launchpad/block_2019-06-30-13-07-21-802466/launcher_2019-07-13-22-54-14-628683",
"host": "login2.nemo.privat",
"ip": "10.16.44.2",
"trackers": [
{
"filename": "log.lammps",
"nlines": 25,
"allow_zipped": false
}
],
"action": null,
"state": "RUNNING",
"state_history": [
{
"state": "RESERVED",
"created_on": "2019-07-13T22:54:14.596648",
"updated_on": "2019-07-13T22:54:14.596655",
"reservation_id": "6012657"
},
{
"state": "RUNNING",
"created_on": "2019-07-13T22:54:49.124427",
"updated_on": "2019-07-24T12:01:26.363237",
"checkpoint": {
"_task_n": 0,
"_all_stored_data": {},
"_all_update_spec": {},
"_all_mod_spec": []
}
}
],
"launch_id": 11789
}
],
"state": "RUNNING",
"name": "NEMO, AU 111 r = 25 Ang indenter at -1e-06 Ang_per_fs approach velocity on 646 SDS monolayer on AU 111 150 Ang cube substrate, LAMMPS production"
}
Johannes Hörmann
Aug 6, 2019, 10:04:01 AM8/6/19
to fireworkflows
A related issue:
In this blurry workflow snippet
the following happens:
An initial Fireworks (1a)
runs LAMMPS until walltime expires on an HPC resource. It is then marked as "fizzled" with a suitable "lpad detect_lostruns --fizzle", as described in the first post in this thread. A subsequent recovery Firework (1b)
with {"spec._allow_fizzled_parents": true} recovers the necessary restart files, automatically appends a suitable restart run (2a)
with another subsequent recovery Fireworks (2b) as well as some post-processing Fireworks (1c)
This recovery loop then repeats (2c, 3a, 3b, ...) until the LAMMPS run finishes successfully.
What happened in the above example is that due to the issue 2 described in the previous posts here, Fireworks 1a and 2a have been marked as "running" again after they were marked as "fizzled" with "detect_lostruns" and their "allow_fizzled_parents" children 1b and 2b started to run. The dangerous point here is that if another "lpad detect_lostruns --fizzle" is applied without carefully discriminating between the "generations" of Fireworks in the tree here, 1a will be marked as fizzled again, and all its children, grandchildren, etc. will lose the information on its current state and be marked as "wating" again, with expensive computations already finished (i.e. 2a), currently running (i.e. 3a) or queued on the HPC resource 'dropping out' of the workflow management framework, without simple means to recover these.
Here, a way to fizzle these lost runs 1a, 2a again properly without affecting the state of their children is necessary to keep the workflow information in the database coherent with what is actually present on the computing resources and file systems.
Best regards,
Johannes
Anubhav Jain
Aug 6, 2019, 1:12:23 PM8/6/19
to fireworkflows
Hi Johannes,
Going back to two messages up.
For issue #1:
- It is good / correct that the type of the updated_on is String
- The line you indicated as problematic should be OK, I think. This line is updating the "updated_on" field of the *root* Launch document. This should be different than the "updated_on" in the state_history[1] field. The key is to make sure that "state_history[{x}].updated_on" contains the correct timestamp (where state_history[{x}] corresponds to the entry for "RUNNING" state).
- I am actually quite confused as to where the origin of the problem is. I would thing that state_history[1] would be updated in this line of the code: https://github.com/materialsproject/fireworks/blob/df8374bc3358a826eaa258de333ff6a46d4f54fa/fireworks/core/launchpad.py#L1684
- But the line of code above seems to respect updating the state_history.updated_on as the "ping_time" of FW_ping.json, which looks correct.
So, unfortunately, I think some more debugging is needed. e.g., to dig into the recover_offline() code and see where in the process the "state_history[{x}].updated_on" field gets corrupted to be the current time and not the ping time.
Issue 2:
Your suggestion at least seems better than the current situation. Do you want to try it out and submit a pull request if it works?
I have not been able to read the most recent message (about LAMMPS, allow_fizzled_parents, etc) in detail. However, if you were to fix issue #2 as per above, would it also fix this issue? Or is it separate?
Thanks for your help in reporting / debugging this.
Anubhav Jain
Aug 6, 2019, 1:19:27 PM8/6/19
to fireworkflows
Hi Johannes
To follow up again, for issue #1 above I think I found the offending line:
This line updates the state of the launch to "RUNNING". However, the "setter" of the state in the Launch object automatically touches the history with the current time anytime the state is modified:
I think that is what is causing the problem.
It's been awhile (i.e. years) since I've wrapped my head around the offline code. However perhaps based on this you can suggest a solution? Let me know if not. If that's the case I might ask you for some more information to help design something.
Best,
Anubhav
Johannes Hörmann
Aug 6, 2019, 4:19:27 PM8/6/19
to fireworkflows
Hello Anubhav,
thanks for your time looking at these issues. Simultaneously to your debugging, I looked at the recover_offline call by just running the commands step by step for a particular launch that has been marked as RUNNING again after being FIZZLED.
Here, I will illustrate with Database screenshots what I noticed:
As described before, "updated_on" is set to the current date every time calling "lpad recover_offline -w PATH_TO_THE_APPROPTIATE_WORKER_FILE":
Running the first few lines of the recovery code
m_launch = self.get_launch_by_id(launch_id)
try:
self.m_logger.debug("RECOVERING fw_id: {}".format(m_launch.fw_id))
# look for ping file - update the Firework if this is the case
ping_loc = os.path.join(m_launch.launch_dir, "FW_ping.json")
if os.path.exists(ping_loc):
ping_dict = loadfn(ping_loc)
self.ping_launch(launch_id, ptime=ping_dict['ping_time'])
try:
self.m_logger.debug("RECOVERING fw_id: {}".format(m_launch.fw_id))
# look for ping file - update the Firework if this is the case
ping_loc = os.path.join(m_launch.launch_dir, "FW_ping.json")
if os.path.exists(ping_loc):
ping_dict = loadfn(ping_loc)
self.ping_launch(launch_id, ptime=ping_dict['ping_time'])
on the ping file with content '{"ping_time": "2019-07-28T12:54:43.213215"}' modifies the database entry as expected:
After the first part of the few lines pointed out by you,
offline_data = loadfn(offline_loc)
if 'started_on' in offline_data:
m_launch.state = 'RUNNING'
for s in m_launch.state_history:
if s['state'] == 'RUNNING':
s['created_on'] = reconstitute_dates(offline_data['started_on'])
l = self.launches.find_one_and_replace({'launch_id': m_launch.launch_id},
m_launch.to_db_dict(), upsert=True)
if 'started_on' in offline_data:
m_launch.state = 'RUNNING'
for s in m_launch.state_history:
if s['state'] == 'RUNNING':
s['created_on'] = reconstitute_dates(offline_data['started_on'])
l = self.launches.find_one_and_replace({'launch_id': m_launch.launch_id},
m_launch.to_db_dict(), upsert=True)
, the state history is still consistent:
The Fireworks has not been touched and still looks like this
fw_id = l['fw_id']
f = self.fireworks.find_one_and_update({'fw_id': fw_id},
{'$set':
{'state': 'RUNNING',
'updated_on': datetime.datetime.utcnow()
}
})
f = self.fireworks.find_one_and_update({'fw_id': fw_id},
{'$set':
{'state': 'RUNNING',
'updated_on': datetime.datetime.utcnow()
}
})
the Fireworks is updated to the current time:
That is what yaou described. However, I do not yet understand where that state setter you mention comes into play, I will have to look at that tomorrow.
The launche's state_history is still consistent up until here.
A few lines below, https://github.com/materialsproject/fireworks/blob/df8374bc3358a826eaa258de333ff6a46d4f54fa/fireworks/core/launchpad.py#L1708-L1711
if 'checkpoint' in offline_data:
m_launch.touch_history(checkpoint=offline_data['checkpoint'])
self.launches.find_one_and_replace({'launch_id': m_launch.launch_id},
m_launch.to_db_dict(), upsert=True)
m_launch.touch_history(checkpoint=offline_data['checkpoint'])
self.launches.find_one_and_replace({'launch_id': m_launch.launch_id},
m_launch.to_db_dict(), upsert=True)
calls "touch_history" again, this time, however, without any ptime argument, and thus overrides the previous change again with the current time:
Since the FW_offline.json contains a non-empty "checkpoint" entry,
{"launch_id": 12392, "started_on": "2019-07-24T12:54:41.031150", "checkpoint": {"_task_n": 0, "_all_stored_data": {}, "_all_update_spec": {}, "_all_mod_spec": []}}
these lines are executed. That is how the current time enters state history. What is the actual purpose of a "checkpoint"? There is not much documentation on this.
Find the test protocal attached (Jupyter notebook and HTML). In the next few days, I will address the other points in your post.
Best,
Johannes

Anubhav Jain
Aug 6, 2019, 4:26:46 PM8/6/19
to Johannes Hörmann, fireworkflows
Hi Johannes
You are correct, that line about checkpointing could be the one causing problems.
The purpose of checkpointing is to allow for task-level recovery (lpad rerun_fws --task-level). The checkpoint stores which tasks have already been completed within a Firework and what their outputs were. This allows you to rerun a Firework starting at a midpoint task if you need to.
Best,
Anubhav
--
You received this message because you are subscribed to the Google Groups "fireworkflows" group.
To unsubscribe from this group and stop receiving emails from it, send an email to fireworkflow...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/fireworkflows/134ff321-1fa4-4033-8c6e-c1f895c2073c%40googlegroups.com.
Best,
Anubhav
Anubhav
Johannes Hörmann
Aug 8, 2019, 7:55:30 AM8/8/19
to fireworkflows
Hello Anubhav,
yesterday and today I took the time to look at and modify the detect_lostruns and recover_offline code in order to fix the two issues of ping time and forgetting lost offline runs when fizzling. For my workflows, the fix seems to work as expected. However, I do not use the checkpoint functionality, thus I did not test anything in relation to task level recovery after these modifications. What is more, the modified code looks pretty ugly and apparently still breaks some tests, see pull request at https://github.com/materialsproject/fireworks/pull/338 , thus should be regarded as a suggestion to build upon.
With this fix resulting in all offline Fireworks' states being marked consistently, the issue described above in my August 6 message (https://groups.google.com/d/msg/fireworkflows/oimFmE5tZ4E/Ah2jyrshEAAJ) of course should not arise at all.
With previously fizzled Fireworks inconsitsently marked as running again, I have not quick way to mark them fizzled again without affecting the state of their children. For maintainance and testing purposes, a quick way to manually toggle the state of a Firework / Launch, say from RUNNING to FIZZLED, without affecting any other children Fireworks in the workflow would be a nice feature.
Best,
Johannes
To unsubscribe from this group and stop receiving emails from it, send an email to firewo...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/fireworkflows/134ff321-1fa4-4033-8c6e-c1f895c2073c%40googlegroups.com.
--Best,
Anubhav
Anubhav Jain
Aug 9, 2019, 6:15:32 PM8/9/19
to fireworkflows
Hi Johannes,
Thanks for the PRs.
For the detect_lostruns I accepted your changes with minor cleanups, I think this should work the same as your PR.
For the recover_offline I tried to rework the code completely to be cleaner.
Could you try pulling the latest master branch of FWS and see if it works for you?
In terms of manually FIZZLING a Firework, I think you are on your own ... I understand that sometimes things need to be hacked, but typically we want "FIZZLED" to mean a problem with execution with a well-defined stack trace, etc., rather than a user intervention (which would be DEFUSED). If we make this part of FWS it will become part of the official usage which I think I want to avoid for now.
Reply all
Reply to author
Forward
0 new messages