Can I mix use 10Gbps Ethernet with 100Gbps IB in a single beegfs file system?
128 views
Skip to first unread message

Z L
May 3, 2023, 11:54:57 AM5/3/23
to beegfs-user
Hi guys,
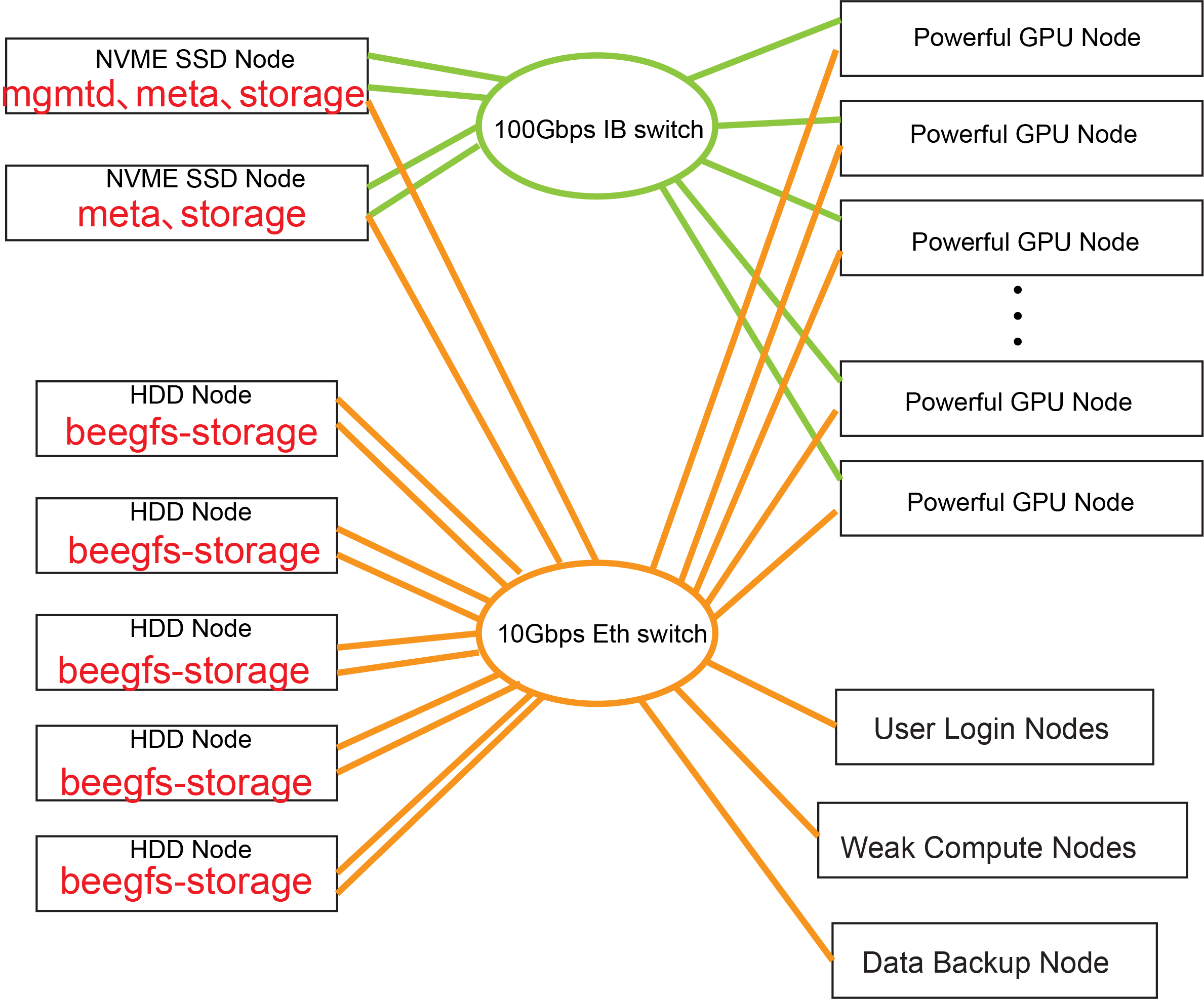
We are planning on upgrading our HPC cluster. Our plan is to deoply beegfs parallel filesystem with 1 100Gbps IB switch, 2 NVME nodes, and 5 HDD nodes. One one hand, we would like to make full use of our existing equipement, including a 10Gbps switch and some weak computer nodes. On the other hands, we feel quite a waste to add 100G NIC cards to these weak nodes. Also, we would like to save the IB switch ports for those powerful GPU nodes.
I am writing to ask if I can mix use 10Gbps Ethernet with 100Gbps IB in a single beegfs file system. Please see the attach image for our plan. We would like to save active project in NVME nodes to feed the GPU node, and put finished project in HDD nodes, and we also would like to mount beegfs on all the nodes.
Any input is very much appreciated.
Zhuang

Tore Heide Larsen
May 3, 2023, 3:38:04 PM5/3/23
to beegfs-user
Hi Zhuang,
Personally, I would do two BeeGFS filesystems. Don't think you can separate IO effectively unless you separate it into two filesystems. I would do high-performance NVMe storage and one with HDD storage (scaleout). And you need to be careful when separating them, separating services ports and using flags sysAllowNewServers and sysAllowNewTargets to false once NVMe BeeGFS filesystem has been created, and then create the second "scaleout" filesystem on the "NAS" servers, and set flags to false. Later you can introduce new nodes to either, but setting appropriate ports and setting the above flags to true temporarily.
You sure can mix NIC speeds. I mix 1/10/100/200Gbps ethernet, DIS (IPoPCIe), EDR and HDR IB, dependent on node capacity. I recommend investing in EDR IB HCAs and 10Gbps on all StorageServers and Metadata servers. My MDSs and storage servers "live" in all topologies, but clients access vart. The below node has HDR IB (RDMA and IPoIB), IPoPCIe (dis0), and 25Gbps ethernet (Cx4LX). If the IB RDMA interface fails, it will failover to IPoIB, then IP over PCIe network, and then ethernet.
Iow. clients' "access" speed to BeeGFS depends on nodes' HCA capabilities. I also use an "edge server" to export BeeGFS to remote nodes over both NFS and sshfs (WAN).
root@n001:~# cat /etc/beegfs/connInterfacesFile.txt
ib2
dis0
enp113s0f0
ib2
dis0
enp113s0f0
root@srl-mds1:~# cat /etc/beegfs/connInterfacesFile.txt
ib2
ib2
ib3
dis0
enp134s0f0
dis0
enp134s0f0
--Tore

{kind=link}
Guan Xin
May 3, 2023, 7:59:21 PM5/3/23
to beegfs-user
Hi,
If you can use your IB switch in another project then
get a 100Gb/s Ethernet switch with x4 split cables.
This might serve your purpose better.
Regards,
Guan
Z L
May 4, 2023, 12:12:11 AM5/4/23
to beegfs-user
Hi Tore,
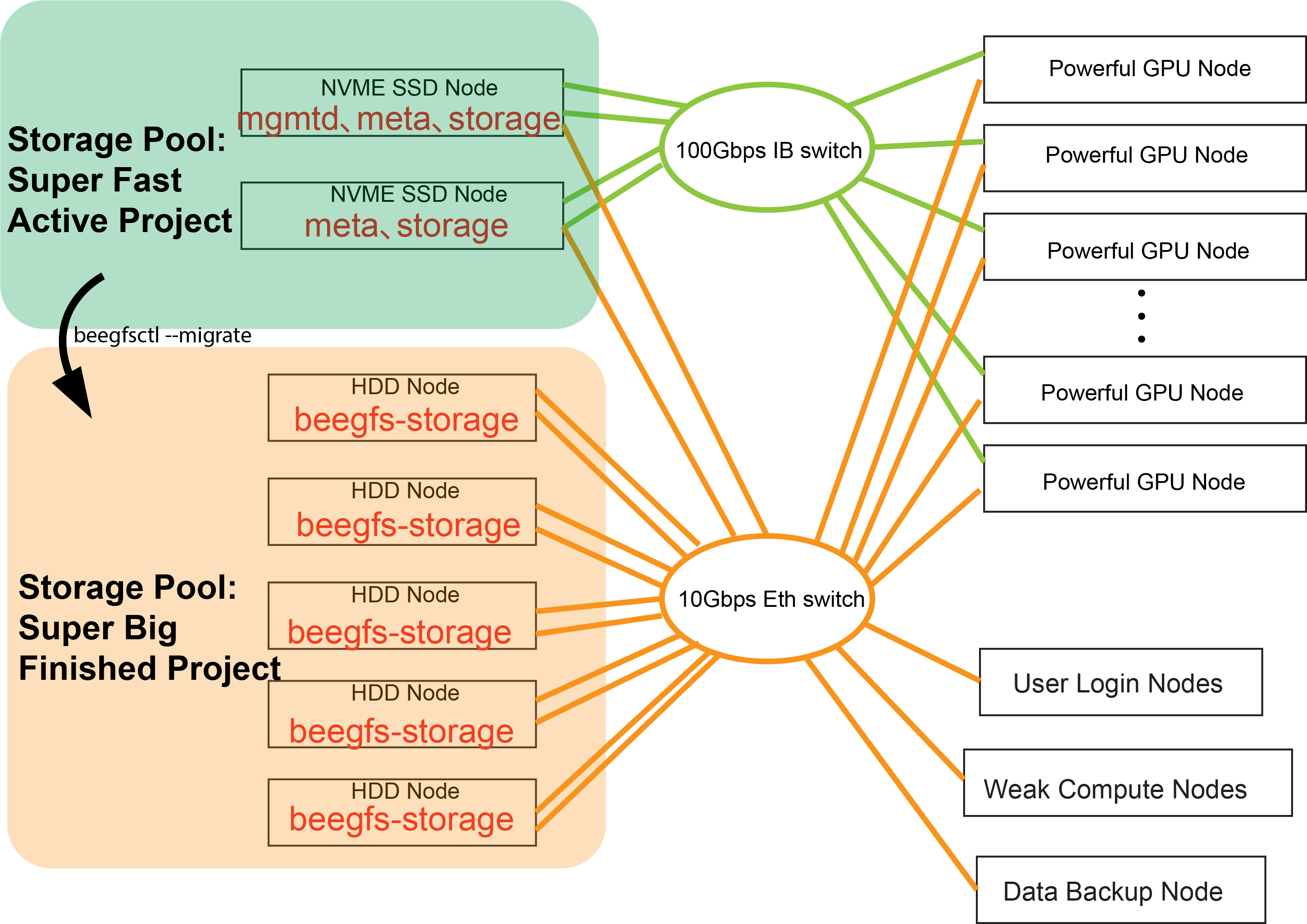
Thank you for the thoughtful and detailed suggestions. We don't have a existing beegfs filesystem for now, and we are trying to build a whole new one. As shown in the attached image, my original idea was to take advantage of the concept of storage pool, so we can offload old data from NVME to HDD with "beegfs-ctl --migrate" command.
Per your suggestion, do I need two mgmtd services or just one? Since we are build this on Centos7, the newest beegf version we can use is 7.2.9. Are the features discussed supported?
Also, we are planning to build our all-NVME node on RAID-0 and do incremental backup on a independent HDD node to prevent disaster. Would this be a reasonable plan ?
Thank you again.
Zhuang
{kind=link}
Z L
May 4, 2023, 1:06:33 AM5/4/23
to beegfs-user
Hi Guan,
We haven't placed the order to buy Mellanox switch, cable and adaptors yet.
If I understand you correctly, you suggested that we give up on IB network and connect all nodes with 100Gbps Ethernet switch, assign differnet bandwith to nodes differetially, use RoCE protocol. Therefore, we don't need to buy cables and NIC cards for weak nodes buy only buy cables and NIC cards for powerful nodes. That would be a neat and elegant solution.
Thank you for your suggestion.
Zhuang
Tore H. Larsen
May 4, 2023, 5:11:32 AM5/4/23
to fhgfs...@googlegroups.com
Zhuang,
> We don't have an existing beegfs filesystem for now, and we are trying to build a whole new one.
Not sure if beegfs-migrate works with separate filesystems, but if it does, then it would probably be elegant. Personally, I wouldn't mix the performance (NVMe) and the "scaleout" BeeGFS.
@Philip Falk, can you beegfs-migrate across separate filesystems?
> As shown in the attached image, my original idea was to take advantage of the concept of storage pool, so we can offload old data from NVME to HDD with "beegfs-ctl --migrate" command.
Sounds like a reasonable plan, although I do asynchronous replication using rsync-like tool. Alternatively borgbackup etc. for archiving. Not exactly tiering such as Cray/SGI/HPE DMF, but it gets the job done.
There are some details in https://doc.beegfs.io/latest/advanced_topics/data_migration.html wrt new files. Maybe rsyncd is better for you. I have a similar setup, except the NAS uses teamed 25Gbps, and I do rsync. My NAS is not a separate BeeGFS filesystem, but it could be. I've done this mix in the past (performance (NVMe) and scaleout (typically SMC NAS servers with 36 or more HDDs) all with BeeGFS/FhGFS, but for my current setup I only have a single NAS, and then it doesn't make sense as I use reflinked XFS to save space. Could be ZFS with dedup, but I trust XFS more than any other filesystem.
I would still prioritize a few EDR HCAs and 5 cables for the "scale out" HDD storage nodes to get performance.
Yes.
> Since we are build this on Centos7, the newest beegf version we can use is 7.2.9. Are the features discussed supported?
Yes, they are. In fact, it has been around for a long time, pre-beegfs. Using 7.2.5, but will migrate to 7.3.x soon.
I'd really like to hear your endpoint.
--
Kind Regards / Mvh,
Tore H. Larsen
Chief Research Engineer HPC Email: to...@simula.no
Simula Research Laboratory - HPC department Mobile: +47 918 33 670
Kristian Augusts gate 23, 0164 Oslo, Norway
--
You received this message because you are subscribed to the Google Groups "beegfs-user" group.
To unsubscribe from this group and stop receiving emails from it, send an email to fhgfs-user+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/fhgfs-user/d4e4458f-9053-48f9-8ede-86ca9bafcaben%40googlegroups.com.
Tore H. Larsen
May 4, 2023, 5:24:18 AM5/4/23
to fhgfs...@googlegroups.com
My experience with NVMe over the past five years is that it is reliable, with hardly any failures, more so than enterprise SAS HDDs. I would avoid raid0; using swraid (MD) raid5 for added protection. Even have converted Nvidia DGXs scratch to raid5 as they ship it standard with raid0. Just being cautious.
--
Kind Regards / Mvh,
Tore H. Larsen
Chief Research Engineer HPC Email: to...@simula.no
Simula Research Laboratory - HPC department Mobile: +47 918 33 670
Kristian Augusts gate 23, 0164 Oslo, Norway
On Thu, 4 May 2023 at 06:12, Z L <zhuan...@gmail.com> wrote:
Z L
May 4, 2023, 5:53:46 AM5/4/23
to beegfs-user
Hi Tore,
>Personally, I would do two BeeGFS filesystems. Don't think you can separate IO effectively unless you separate it into two filesystems.
Thank you for the prompt reply.
>Personally, I would do two BeeGFS filesystems. Don't think you can separate IO effectively unless you separate it into two filesystems.
I guess I was too much fanscinated by the idea of "storage pool", through which the directory structure keeps unchanged despite the underlying data block has been transferred. I am wondering if I used the plan I proposed, will the client node get confused to find the NVME node or HDD storage node?
Let's say,
NVME node
hostname: node 01
192.168.100.1 node01-ib (IB interface)
192.168.200.1 node01 (Eth interface)
HDD node
hostname: node02
192.168.200.2 node02 (Eth interface)
GPU client node
hostname: node03
192.168.100.3 node03-ib (IB interface)
192.168.200.3 node03 (Eth interface)
If I setup the client node03 with /opt/beegfs/sbin/beegfs-setup-client -m node01-ib, Is it possible/efficient for node03 to communicate data with node02?
I am less experienced in the network configuration. I do apologize if I was actually asking a silly question.
Zhuang
On Thursday, May 4, 2023 at 3:38:04 AM UTC+8 Tore Heide Larsen wrote:
Guan Xin
May 4, 2023, 9:08:39 AM5/4/23
to beegfs-user
Hi Zhuang,
Yes you are right,
100G RoCE direct connection for fast nodes, and, via x4 split cables,
25G for slow nodes (more chance of supporting RoCE)
or 10G for slow nodes (mode chance to use old existing network interface cards).
On small clusters, RoCE is not more complicated to manage than Infiniband.
Infiniband might show its advantage starting from medium sized clusters.
Regards,
Guan
Z L
May 4, 2023, 10:22:28 PM5/4/23
to beegfs-user
Hi Guan,
Thank you for your advice. Will do some research on it.
Zhuang
Z L
May 5, 2023, 1:39:50 AM5/5/23
to beegfs-user
Hi Guan,
We have 50 nodes containing 3000+ CPU cores, 100+ A100 GPU cards, ~250T NVMe, and ~3P storage. Do you think it is worth in investing in IB network?
Zhuang
On Thursday, May 4, 2023 at 9:08:39 PM UTC+8 Guan Xin wrote:
Z L
May 5, 2023, 1:51:54 AM5/5/23
to beegfs-user
I also have some questions on hardware setup. Any input is very much appreciated.
We are planning on building on 4 all-NVMe beegfs nodes, each with 2*Intel 5317 processors, 256G DDR4 ECC memory, 2*2T NVMe(for metadata), 8*8T NVMe(for storage), and 2 Mellanox 100Gbps CX-5 NIC adaptors.
My question is,
Should I distribute metadata targets across four nodes? Or should I put all metadata targets on one node?
If I enable RDMA, how much memory is actually needed for production envionment?
Is Intel 5317 good enough in this setup?
Should I assign two NIC adaptors to two NUMA nodes?
Thank you!
Zhuang
On Thursday, May 4, 2023 at 9:08:39 PM UTC+8 Guan Xin wrote:
Guan Xin
May 5, 2023, 6:50:25 AM5/5/23
to beegfs-user
Hi Zhuang,
Please see below:
On Friday, May 5, 2023 at 1:39:50 PM UTC+8 Z L wrote:
Hi Guan,
We have 50 nodes containing 3000+ CPU cores, 100+ A100 GPU cards, ~250T NVMe, and ~3P storage. Do you think it is worth in investing in IB network?Zhuang
Depends on your future plans (will add more nodes or not).
I think both IB and Eth are ok for this currently "one switch can hold all" cluster.
IB does provide some convenience, but 400GbE switches are as inexpensive as 200G HDR IB SW.
IB HDR-2xHDR100 and Ethernet 400G-4x100G split cables are equally expensive.
Network cost is a tiny part of this cluster anyway, so this only makes a difference when the cluster scales out.
Both protocols are compatible with MLNX VPI cards.
There will be no need to alter server hardware configuration
when link layer changes from Infiniband to Ethernet.
On Friday, May 5, 2023 at 1:51:54 PM UTC+8 Z L wrote:
I also have some questions on hardware setup. Any input is very much appreciated.We are planning on building on 4 all-NVMe beegfs nodes, each with 2*Intel 5317 processors, 256G DDR4 ECC memory, 2*2T NVMe(for metadata), 8*8T NVMe(for storage), and 2 Mellanox 100Gbps CX-5 NIC adaptors.My question is,Should I distribute metadata targets across four nodes? Or should I put all metadata targets on one node?If I enable RDMA, how much memory is actually needed for production envionment?Is Intel 5317 good enough in this setup?Should I assign two NIC adaptors to two NUMA nodes?Thank you!Zhuang
All meta on one devoted meta node for low latency.
Distributed meta improves total throughput but users need to keep in mind
to create different directory trees on different meta servers,
or latency will be sacrificed.
Choice of hardware depends on type if service --
1) Meta nodes we are using
CPU: Xeon 5315Y (if not enough, the next is 6326, still not enough, guess probably EPYC+DDR5)
Memory: Fill all channels with modules of lowest capacity one can get (usually 16GB).
Storage: md-raid1 on (interlaced PMem + write-mostly (md-raid1 on SSD))
Service configuration: bind to the same NUMA node where the meta-storage is attached.
2) Storage nodes
Xeon 4314 is more than sufficient to manage 24-NVMe SSD zfs with zstd-1 compression.
Just fill up all memory channels.
3) Each NUMA node with its own NIC
This of course improves latency, but the native beegfs support seems cumbersome.
I'd run beegfs and compute tasks in virtualized environment in this case to make use of
the local NIC but I'll check if my salary matches the added trouble.
4) Memory capacity is rarely a problem when all channels are filled, which means
at least 128GB per NUMA node.
Just tune the sysctl parameters under the vm subdirectory to reserve more memory
for administrator and defragment memory more actively -- most probably needed
on compute nodes where a compute task can inflate so much to push RDMA out.
Hope that helps.
Guan
Z L
May 5, 2023, 7:53:31 AM5/5/23
to beegfs-user
Hi Guan,
Thank you for all the helpful info. Have a nice weekend!
Zhuang
Reply all
Reply to author
Forward
0 new messages